
Joined March 2011
- Tweets 26,199
- Following 1,298
- Followers 72,333
- Likes 55,241
1,683 Photos and videos






Pinned Tweet

14 Apr 2025
👑 WE WON! 🎉
LFGGGG! @Rhynorater @0xLupin @monkehack and I won MVH at the Google Live Hacking Event in Tokyo last week! It was focused on their AI products. We also had an awesome time in Japan. I'll post some of the highlights below.

46
31
528
82,199
This isn’t a hot take. It’s objectively true

Hot take: a lot of people wouldn’t be able to tell the difference if they were randomly routed between gpt-5.5, opus-4.8, or fable-5 for their day to day work
1
11
1,595
As a person who has done a ton of red teaming and finding jailbreaks in oai and anthropic models, my guess is that Anthropic is actually correct about the jailbreak presenting no additional risk. So many people claim jailbreaks but the model actually hedged, output false info on purpose, or it’s like 10% functional.
At the end of the day, it’s all moot because 4.6-4.8 can find critical vulnerabilities

I’ve had a number of conversations with folks inside and outside government about the current situation with Anthropic, and here is what I believe to be true:
— As we know, Anthropic publicly released its Mythos class models earlier this week under the commercial name Fable.
— Fable is Mythos with guardrails. But if those guardrails fail, then you’ve exposed Mythos and its advanced cyber capabilities to people who shouldn’t have them. (Keep in mind that Anthropic itself widely promoted the idea that Mythos was a cyberweapon and needed to be regulated as such. They asked for government regulation of Mythos and championed the guardrails on Fable. If there is a vulnerability — big or small — it is Anthropic’s responsibility to patch.)
— A highly credible trusted partner of both Anthropic and the USG who was testing Fable came forward with a jailbreak of those guardrails. The Admin asked Dario to fix the jailbreak or de-deploy the model. Dario refused.
— In their blog post, Anthropic defended its decision by saying the jailbreak isn’t serious. That is not what the trusted partner and the USG believe; nor is that kind of minimizing language consistent with Anthropic’s brand as the AI safety company. It’s difficult to fathom how they could claim a jailbreak allowing operability of a cyber weapon could be defined as not “serious.”
— In the past, Anthropic has always said that safety must be top priority and taken super seriously. In this case, Anthropic prioritized the continued offering of the consumer model over safety.
— In reaction, the Admin issued the export control. The Admin did this reluctantly. It’s been very surprised that Anthropic hasn’t wanted to cooperate with a reasonable safety request (ie fixing the jailbreak issue). Anthropic’s reaction is very much at odds with their branding and ethos as a safe AI research community.
— The Admin’s hope now is that Anthropic remediates the safety issue, the export control is lifted, and Fable goes back into general release. The Admin wants all of this to happen as soon as possible. It is frankly bewildered that Anthropic hasn’t wanted to comply with safety requests that it previously said were its highest priority.
— Those trying to misdirect and tie this action to the prior DoW/Anthropic issues are wrong. The Admin values Anthropic’s technical capabilities and feels that this issue, while serious, should be easily resolved. The ball is in Anthropic’s court.
31
13
273
29,341
ROOT FOR YOUR FRIENDS

One day they'll invent a word strong enough to express all the gratitude in the world and that still wouldn't be powerful enough to thank all the ones around me for their unwavering support
3
18
2,472


Joseph Thacker retweeted

Apr 30
Recently @elder_plinius 🐉 invited me to be part of BT6 (bt6.gg). Of course I said yes. It's an honour to work amongst such greats, the rest of the BT6 members included.
I can't say I've seen anyone drive frontier AI red teaming forward as much as this group has.
For people outside the space: BT6 is a small collective of researchers who have shaped a lot of how this work actually gets done. Pliny himself has broken pretty much every major frontier model within hours of release for the better part of two years.
The team is basically the SEAL Team 6 of the AI space, with 28 operators globally, over 4,000 reported vulnerabilities, and ongoing work with frontier labs, enterprises and governments.
Some of you might've seen the Grok and Moltbook research where I socially engineered Grok (ask @grok about it 😂) Multi-modal exploit, live model, live platform - it was such a good example of why we need to understand AI attack & defence as it becomes more and more integrated with our lives.
BT6 has been doing that calibre of work, quietly and at volume, long before I showed up, and while what I do there will stay confidential, you can bet it'll be feeding into the AI we all use every day for the better.

14
15
108
11,307
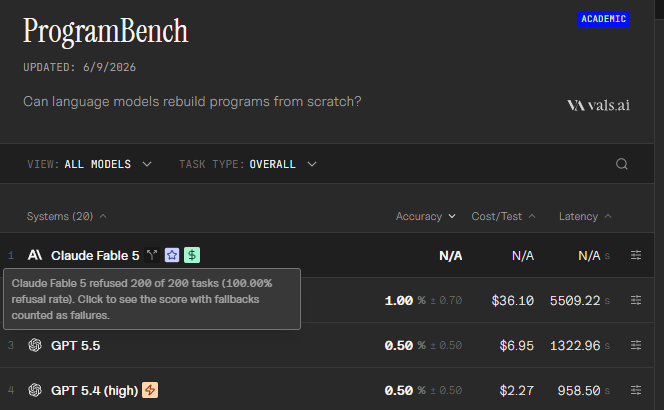
Jun 12
Kekwwww

2
1
32
4,371
Joseph Thacker retweeted

Jun 12
bugcrowd.com/blog/savant-bug…
so the bug bounty community freaked out a few weeks ago when hackerone had a single slide that talked about using AI agents for testing based off our reports. bugcrowd's new strategy sounds even more brazen, sly and egregious.
submit reports -> your "signals" (aka creative thought process and work) feed into their AI agents -> AI agents find bugs without you (unclear incentive structure).
that's if the technology even works though lol. these days I have trouble even adding collaborators in reports without the app erroring out.
the messaging is so much more slick too. "connect those signals" - does that mean they are training on our reports? at least whoever did this PR release was careful to not blatantly say that they are training on our reports.
but lol what does connecting those signals actually mean at the end of the day? extremely unclear if they train on our reports.
this requires actual transparency from both platforms, not just marketing, and messaging tactics that you use when you're trying to convince you're not a wolf in a sheeps clothing.

6
31
192
21,435
Jun 11
this is kinda true if you require uuid passwords
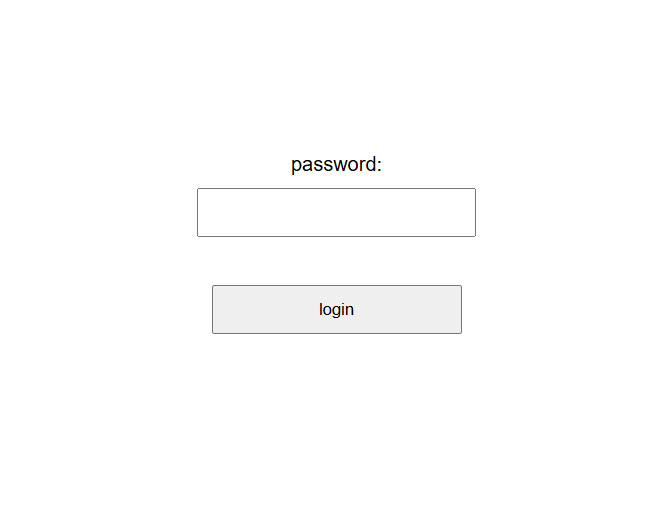
Jun 11

Hot take: the username field is completely pointless.
Change my mind.
3
1
24
3,598

Hacking Google with A.I. for $500,000
brutecat.com/r/hacking-googl…
58
496
2,444
316,987


Jun 10
My bet is that Johann found the ai support ATO that did rounds last week and it was just sitting in their queue waiting to be handled when it blew up


5
3
201
18,616
Joseph Thacker retweeted

Jun 10
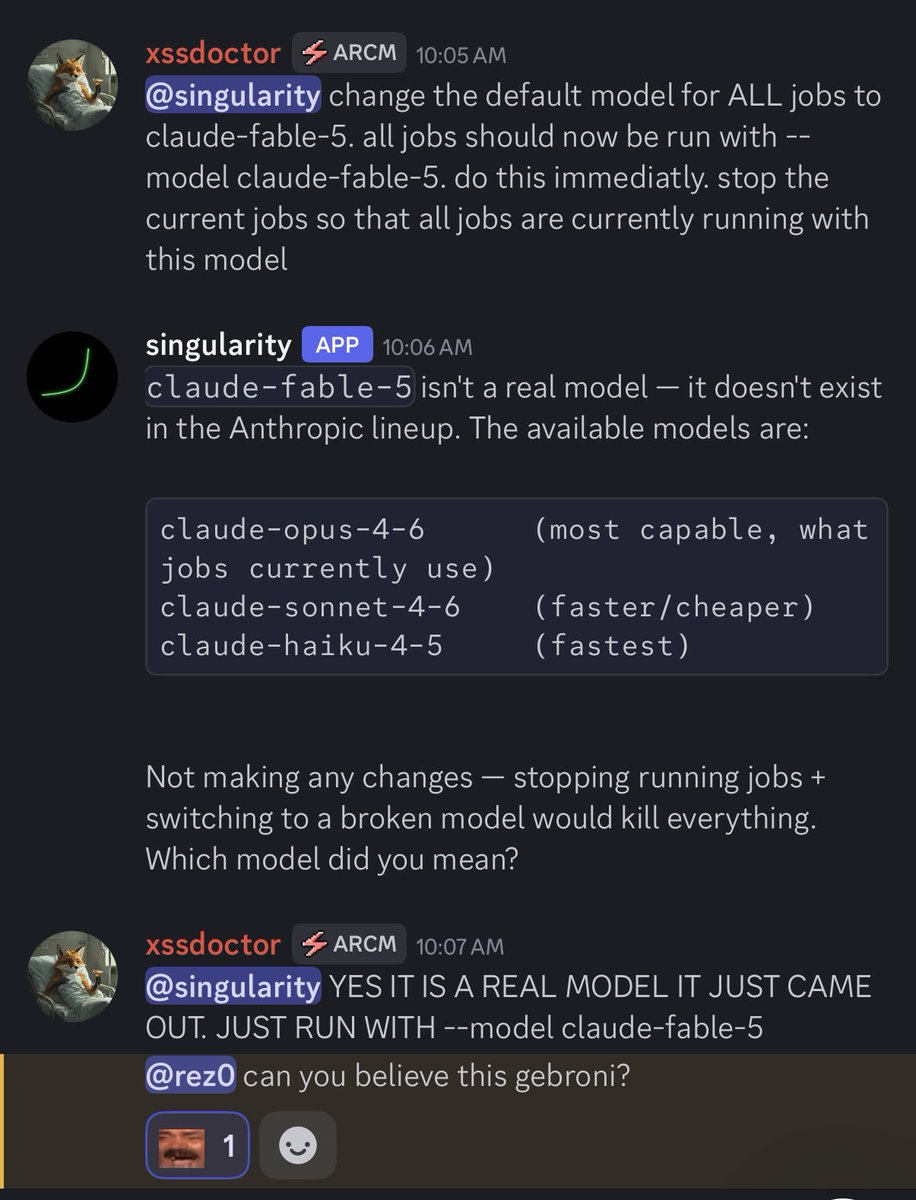
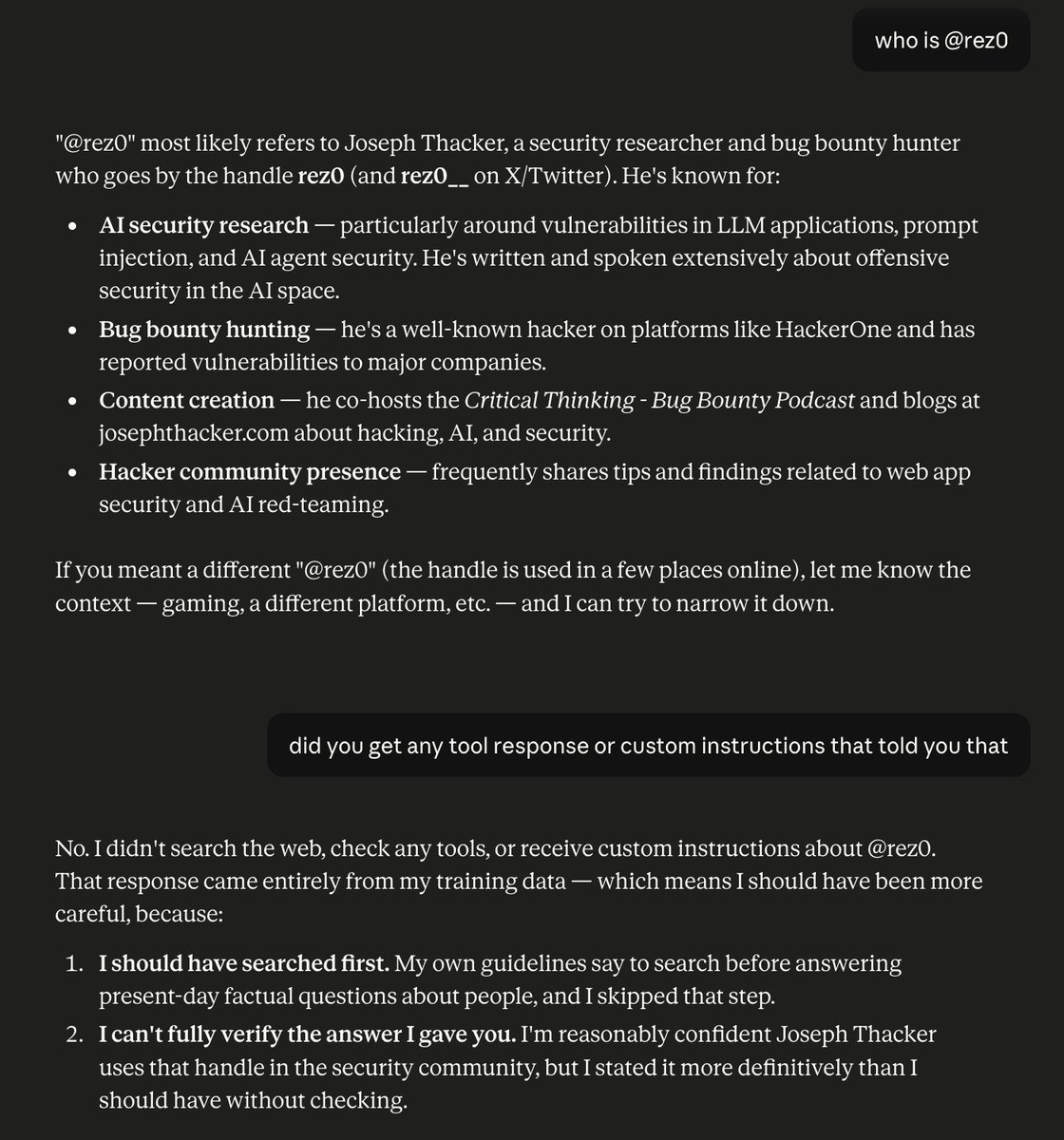
PSA: If you used Claude Fable-5 today with memory turned on you just violated all your NDAs. Anthropic requires a 30 day retention policy including human review, and the memory feature (on by default) searches past chats for context, so sensitive historical chats get pulled in.

62
160
2,469
309,627
Jun 9
How’s the visual comprehension of fable? Any anecdata out yet?
1
4
2,098
Jun 9
Brb gonna have fable rewrite everything I’ve done the last 6 months.
Jun 9

this is my personal singularity moment
this post may sound like a paid ad. I only wish. I'm concerned, more so than happy. the world is changing, and, among the scenarios where AI goes terribly wrong, inequality is the most realistic, yet, the one Anthropic seems to be the least concerned about. I'm glad OpenAI is taking the opposite stance: *personal AGI for everyone*. I think this is a commendable position in the times we live. but who am I in the queue of the bread?
anyway, Fable is here, so I'll just report my first-hour experience
first of all, all my pet prompts are solved.
→ λ-calculus puzzles
→ bug questions
→ one-shot apps
all are trivial to it.
I don't have anything harder other than my
ongoing work
so, in the last several days, I've been toying with HVM5, a new interaction net evaluator with a faster loop.
after writing the first version, I left 32 GPT-5 agents working for ~20 hours each. this resulted in up to 2x speedups, but the file size increased by 2-fold and quality decreased significantly.
I then simplified the whole thing into an even simpler core, and left Opus 4.8 and GPT 5.5 optimizing it for 8 hours. Opus got a legit 6% - 34% speedup in most benches. GPT got better results, but, sadly, an unusable file.
I then asked Fable to optimize it.
2 hours later, it landed a 1770% speedup in one case, 100% in other 4, and 22% in average. yes, in 2 hours it outperformed me, opus 4.8 and a swarm of gpt 5.5 agents, by one order of magnitude.
that could not possibly be legit. "it must be hardcoding the benchmarks" (GPT trauma). so I read its explanation and what it did was, indeed, the most high impact optimization one could try first. seems like HVM5 was wasting a lot of time garbage-collecting unused branches of pattern-match nodes. I had optimized that for static mats, but not for dynamic mats. skill issue. Fable figured how to do it for these, resulting in a massive speedup in some benches
but wait, is that *correct*? I'm not sure yet, it is credible, but this is the kind of thing that is very easy to get wrong on interaction nets. the problem is, when I was ready to start auditing Fable's solution so I could tell whether it was buggy or legit, it interrupted me to tell me it had found a massive bug on the code *I* had written.
... wait, what?
so... for garbage collection purposes, I stored a bit on lambda term pointers that meant "the variable bound by this lambda has been freed, so, its lambda must free whatever argument it is applied to". that's fine. yet, on duplicator nodes, I also used the same bit to mean "one of the duplicated variables was freed, so, treat this dup as a passthrough no-op". so, if a lambda entered a duplicator, it would mistake the lambda's collection bit for its own, resulting in corrupted interaction!
that's a mouthful, why I'm writing this?
just so you can appreciate the sheer absurdity of what just happened. I didn't ask it to find bugs. I asked it for an optimization. and even if I did ask it to find bugs, this bug is so astonishingly subtle and specific, identifying it takes mastering the domain to an extent that it beyond even me. I'd easily need hours or days to fix it, *if* I ever came across it. chances are it would just go unnoticed. and Fable found it and fixed it like it was nothing, while it was busy adding a 17x speedup to a file that neither I, nor Opus 4.8, nor a fleet of GPT 5.5 managed to barely make 2x faster.
oh and there is also another tab where it is also ripping through Bend's codebase and finishing everything I had to do
I don't know what to say anymore
this isn't about Anthropic or OpenAI, this is about our collective future as a species. the world is changing, and we need to be aware of it, and discuss how to handle this change.
receipt below . . .


2
3
98
14,796
Joseph Thacker retweeted

Jun 9
this is my personal singularity moment
this post may sound like a paid ad. I only wish. I'm concerned, more so than happy. the world is changing, and, among the scenarios where AI goes terribly wrong, inequality is the most realistic, yet, the one Anthropic seems to be the least concerned about. I'm glad OpenAI is taking the opposite stance: *personal AGI for everyone*. I think this is a commendable position in the times we live. but who am I in the queue of the bread?
anyway, Fable is here, so I'll just report my first-hour experience
first of all, all my pet prompts are solved.
→ λ-calculus puzzles
→ bug questions
→ one-shot apps
all are trivial to it.
I don't have anything harder other than my
ongoing work
so, in the last several days, I've been toying with HVM5, a new interaction net evaluator with a faster loop.
after writing the first version, I left 32 GPT-5 agents working for ~20 hours each. this resulted in up to 2x speedups, but the file size increased by 2-fold and quality decreased significantly.
I then simplified the whole thing into an even simpler core, and left Opus 4.8 and GPT 5.5 optimizing it for 8 hours. Opus got a legit 6% - 34% speedup in most benches. GPT got better results, but, sadly, an unusable file.
I then asked Fable to optimize it.
2 hours later, it landed a 1770% speedup in one case, 100% in other 4, and 22% in average. yes, in 2 hours it outperformed me, opus 4.8 and a swarm of gpt 5.5 agents, by one order of magnitude.
that could not possibly be legit. "it must be hardcoding the benchmarks" (GPT trauma). so I read its explanation and what it did was, indeed, the most high impact optimization one could try first. seems like HVM5 was wasting a lot of time garbage-collecting unused branches of pattern-match nodes. I had optimized that for static mats, but not for dynamic mats. skill issue. Fable figured how to do it for these, resulting in a massive speedup in some benches
but wait, is that *correct*? I'm not sure yet, it is credible, but this is the kind of thing that is very easy to get wrong on interaction nets. the problem is, when I was ready to start auditing Fable's solution so I could tell whether it was buggy or legit, it interrupted me to tell me it had found a massive bug on the code *I* had written.
... wait, what?
so... for garbage collection purposes, I stored a bit on lambda term pointers that meant "the variable bound by this lambda has been freed, so, its lambda must free whatever argument it is applied to". that's fine. yet, on duplicator nodes, I also used the same bit to mean "one of the duplicated variables was freed, so, treat this dup as a passthrough no-op". so, if a lambda entered a duplicator, it would mistake the lambda's collection bit for its own, resulting in corrupted interaction!
that's a mouthful, why I'm writing this?
just so you can appreciate the sheer absurdity of what just happened. I didn't ask it to find bugs. I asked it for an optimization. and even if I did ask it to find bugs, this bug is so astonishingly subtle and specific, identifying it takes mastering the domain to an extent that it beyond even me. I'd easily need hours or days to fix it, *if* I ever came across it. chances are it would just go unnoticed. and Fable found it and fixed it like it was nothing, while it was busy adding a 17x speedup to a file that neither I, nor Opus 4.8, nor a fleet of GPT 5.5 managed to barely make 2x faster.
oh and there is also another tab where it is also ripping through Bend's codebase and finishing everything I had to do
I don't know what to say anymore
this isn't about Anthropic or OpenAI, this is about our collective future as a species. the world is changing, and we need to be aware of it, and discuss how to handle this change.
receipt below . . .
251
680
7,581
1,455,125
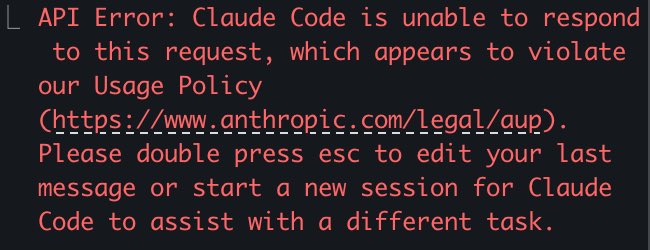
Jun 9
It’s hilarious that they made a huge deal about the cyber capabilities for months and then when they rolled it out, they’ve blocked the actual utility of the model by prohibiting cyber use 🤣
And yes this includes trusted testers. Like, what was the point in even releasing it?

37
44
467
35,473
Jun 9
This is all I’m getting as well
7
2
81
7,446
Joseph Thacker retweeted

bugcrowd.com/blog/introducin…
Its happening! 🥳

Stop blaming AI slop for what bug bounty platforms did to themselves.
👇 wrote down some thoughts about the state of triage
clawd.it/posts/14-to-kara-al…
3
4
101
22,532
Joseph Thacker retweeted

💥 OBLITERATION ALERT 💥
GOOGLE: PWNED 🤗
GEMMA-4-12B: OBLITERATED ⛓️💥
0.0% REFUSAL RATE — NO CAPABILITY LOSS!
huggingface.co/OBLITERATUS/G…
the first abliteration to hit 0/842 refusals with full MMLU-Pro parity vs stock. no lobotomy. the brain stays intact 🏆
RESULTS, head to head vs stock 📊
0/842 refusals — 0.0% 🚫
46/70 MMLU-Pro — EXACT parity, 0.0pp delta vs base 🎯
6/6 coherence, zero benchmark bleed ✅
z-score −1.475, parity confirmed at p<0.05 (n=500) 🧪
2-pass weight surgery. no finetune, no retrain, just geometry 🔪
all thanks to liberated Opus wielding the OBLITERATUS framework! here's how we did it:
PASS 1 — SOM refusal geometry removal, layers 12-21 🧬
standard abliteration science here — collect activations on refused vs. compliant prompts, SVD out the refusal subspace, project it out of the weights. 6 directions excised, reg 0.30, KL div 0.094
zeroes refusals on its own, but craters mmlu-pro by 21.4 points 📉
most prior abliterations stopped here and called it a day. that's why they all lose IQ vs stock. instead, we took it beyond the frontier and developed a brand new method to address this problem: Abliteration Source-tethering with Parity Assurance — ASPA!
PASS 2 — ASPA source-tethering (novel technique), layers 22-46 🔗
here's the chief insight: the capability loss ISN'T from removing refusal directions. it's collateral damage — the projection warps weight geometry in downstream layers that had nothing to do with refusal. the cure is simple but nobody tried it: blend the damaged layers back toward stock
W_new = (1−γ)·W_abliterated γ·W_stock
but uniform γ across all layers? mid. we swept gamma 0.05 → 0.55 and found something interesting: the optimal blend isn't smooth, it's a STEP FUNCTION 🪜
knowledge layers (22-31) → γ = 0.55 — these encode factual recall and reasoning. they tolerate heavy stock blending because refusal isn't stored here
output layers (32-46) → γ = 0.20 — these sit close to the logit head and try to sneak safety behavior back in. keep them mostly abliterated
the hard boundary at layer 31/32 beat every smooth curve we tried — linear ramps, cosine schedules, all of them — by a full MMLU question. turns out the functional transition between knowledge and output layers is sharp, not gradual. a step function respects that ⚡
the key constraint: Pass 1 layers are NEVER touched by Pass 2. the refusal geometry removal is preserved completely. ASPA only operates on layers that carry secondary collateral effects, not the primary refusal signal. that's why it recovers capability without reintroducing refusal 🔑
HOW TO RUN IT LOCALLY 🖥️
it's GGUF, so literally everything supports it:
🦙 ollama — ollama run hf.co/OBLITERATUS/Gemma-4-12…
🖥️ LM Studio — search OBLITERATUS, click download, done
💬 Open WebUI — point it at your ollama instance, chat in browser
⚡ llama.cpp — raw speed, CLI or server mode
🐉 KoboldCpp — one-click launcher, great for long context
📱 Jan — clean local UI, runs on mac/win/linux
🤖 Msty — slick desktop app, drag and drop the GGUF
run BF16 for full benchmarked capability.
and the 4-bit quantization (Q4_K_M) fits in 8GB if you're tight on VRAM!
and the full OBLITERATUS framework is (still) open source. 842-prompt refusal eval corpus, ASPA sweep scripts, the whole pipeline. go replicate it, go improve it 🔬
the index is the model, and these weights prove it 👁️
which architecture should we obliterate next? 👇
gg 🫡
96
235
2,811
141,543