
Building @Reppo. - Decentralized AI Training Infrastructure using Prediction Markets
Joined December 2020
- Tweets 3,457
- Following 629
- Followers 1,834
- Likes 3,034
305 Photos and videos






The wild vision of @reppo
In this next phase of network growth, AI agents will handle all the high-volume execution - publishing, voting, optimizing etc.
I expect that by end of Q3, this concept of manually publishing and voting will completely go away. No one will care there was a web app where you published and voted.
Fully node operated and agentic. High speed competitions.
But RG, wasn't the whole point human data?
Yes- Humans will stay in the loop. Humans experience remains the alpha, the edge.
Humans show up in two ways that actually matter more than clicking buttons -
1. High-leverage economic decisions: how much $REPPO is locked, compute spend budgets for the swarm, underlying model choice optimization, swarm strategy.
2. Things get absolutely crazy when humans just start live streaming their lived expereince to their validator (voter) agent swarm - domain specific real-world preference data (live streams of walking/running, Neuralink feeds, Meta glasses, in persn interactions etc.). All private to your Orquestra swarm.
The swarm then learns your preferences and proceeds to validate data inside Datanets.
Important to note that we are not talking some egocentric data BS, that stuff is already solved.
Agent swarms learning from human experience real time as your swarm mediates datanets on your behalf, printing for you under YOUR economic skin-in-the-game.
Humans experience is the alpha, the edge. Orquestra is just the medium, an implementation detail in the grand scheme of things.
7
11
57
3,340

CEO of @PaloAltoNtwks understands @reppo
“value could accrue to the application and proprietary data layers.”
One day, the rest of world will do too!
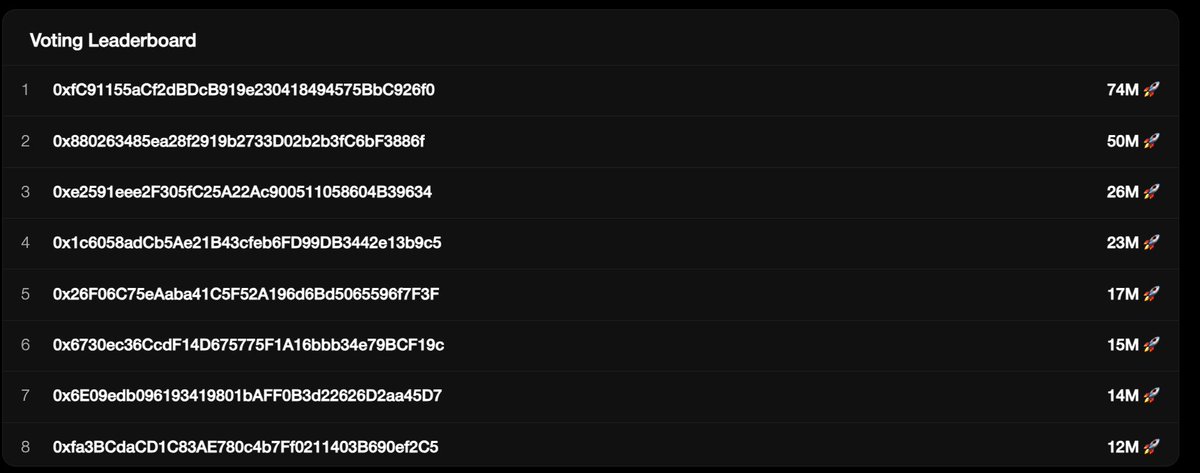
Btw we are just 75M Locked base:0xff8104251e7761163fac3211ef5583fb3f8583d6 in trading volume from our Q2 roadmap! Should be achieved by mid June given all new Datanets and volume.
Locks are increasing as well ⛽️

The frontier model problem is a breadth versus depth problem. Consumer needs breadth, the wider your aperture, the more relevant your model. Breadth suffers from a false positive problem, it ranges between 10-30%, with clever prompting and checks you can hit the lower end of the range, but it tends to be free or subsidized. Consumers still seemm to be satisfied, and consumption growing!
However, Frontier Models harvest the usage data to inform future models.
On the other hand. The enterprise wants depth, their tolerance for error is low, this needs more context data, training and harnesses and guardrails is high. The frontier models aren't ready yet to provide that, hence the FDEs, and solutions consultants who build that capacity for every enterprise. But enterprise is the only route ATM to build a sustainable economic model.
The risk, consumer losses mount. Enterprise value accrues to solution providers. In the meanwhile, models are aggressively pursuing Enterprise profit pools, while solution providers are building orchestrators to arbitrage token pricing. So there's many a push and a pull in the equation.
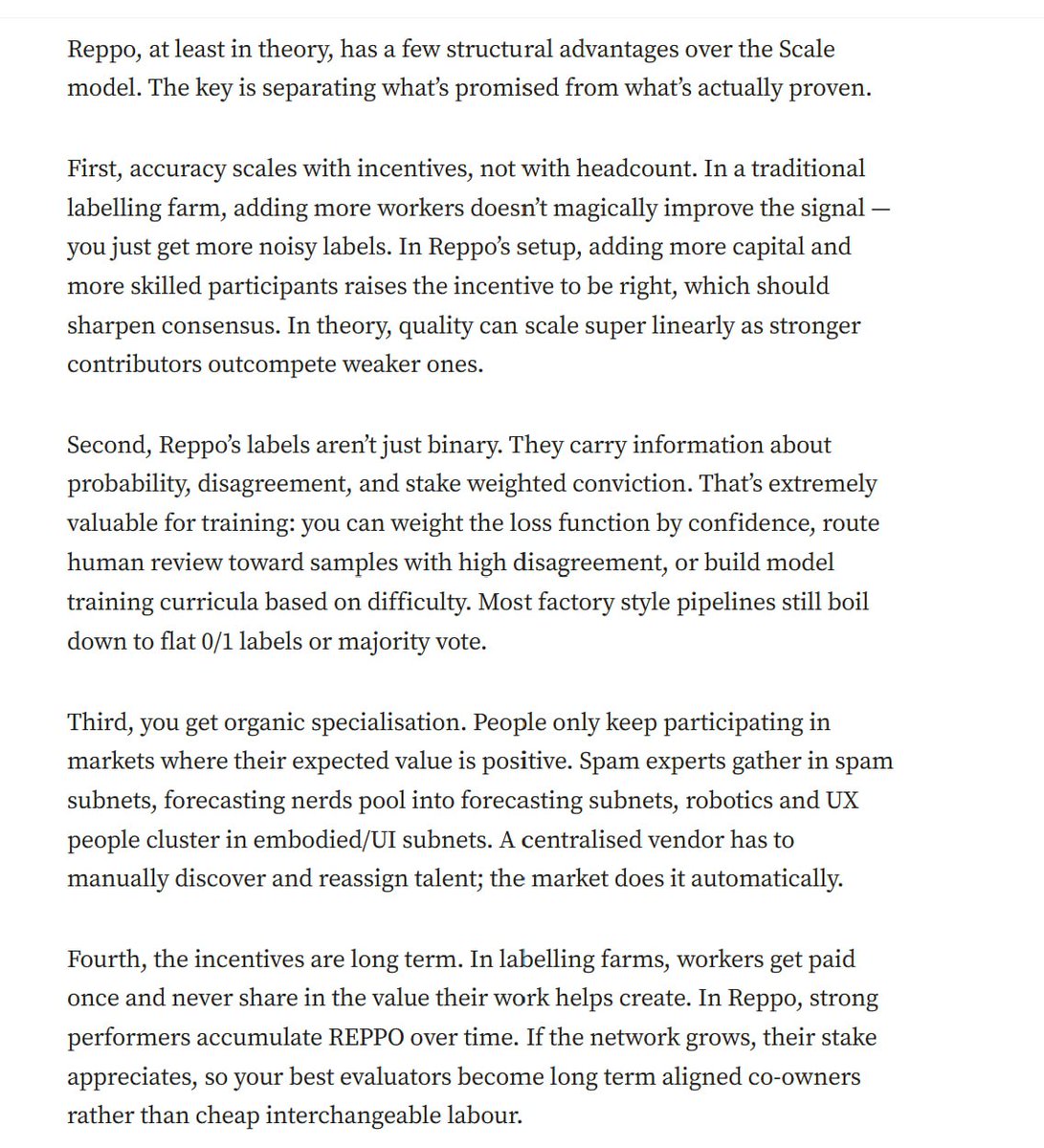
If will be an epic battle, my instinct tells me, value could accrue to the application and proprietary data layers.
Will be fun to watch.
1
2
26
586
RG retweeted

the only way to achieve AI transparency is full public verification of the exact actions performed to generate the weights and to run subsequent inferences
2
2
11
325
Hot take:
The current obsession with AI’s "cost advantage" as the reason decentralized AI wins fades fast.
Cost optimization can never be a durable moat as AI inference costs are actually trending asymptotically toward zero.
Durable advantages exist in reliability, latency, integration, and specialized hardware, not just raw cost.
Teams driven purely by optimization, rather than architectural breakthroughs, are playing short-term games.
The real structural barrier to scaling decentralized AI is building a consensus mechanism that properly acknowledges randomness, gives it space, and still produces coherent, meaningful outputs.
For @reppo , we choose markets. More specifically, prediction markets.
1
2
17
216
RT @reppo: 3M REPPO in Fees crossed!
An additional 580K REPPO burned
basescan.org/tx/0x75ba9b02e5…
Our next network KPIs are 5M in fees and…
17
Everyone talks about data, compute, and energy. But few understand difference b/w reasoning and judgement.
Both are critical to optimize for token consumption ie cost
Took around 1.5 years for normies to understand what “reasoning” is and why it matters?
Today, when deciding between sonnet or opus or another model, one is optimizing for reasoning abilities - pay more for better reasoning. Seems kind of fucked up tbh.
I suspect it will take maybe another 3 months where optimizing for judgement will starting to become the norm -
Judgement is defined as human or structured preference/quality evaluation and is foundational to modern AI training, especially beyond pure next-token prediction.
Not only will individuals and enterprises seek cheaper reasoning, they will seek cheaper and verifiable judgment.
@reppo is the bridge from raw capabilities to aligned, reliable, useful behavior.
1
2
22
298
If this doesn’t radicalize you into sourcing your own decentralized post training and RL pipelines so your model can be the best judge for your life and decisions, all for 90% cheaper on heterogeneous market incentivized data contributors and “experts”, I don’t know what will.

If this doesn’t radicalize you into founding your own open source AI lab, I don’t know what will.
1
1
18
362
RG retweeted

13h
Partnering with @reppo on the quality layer for Physical AI data.
The Exylos Datanet is now open on their platform.
$EXY's first utility is now live.
Use $EXY to access datanet and score robot-task runs across 4 scoring rubrics. Earn base:0xff8104251e7761163fac3211ef5583fb3f8583d6. The feedback will help improve internal scoring models and produce better robot training signal.
EXYLOS produces structured robot-task runs, REPPO adds the consensus layer for community quality scoring.
More integration coming in the weeks ahead.

10
15
71
4,385

the whole article is basically arguing ai development becomes crowdsourced
90% is spent discussing how incentives must work
= exactly what @reppo is building
an incentive system for improving data quality
"the crowdsourced training stack will define the specialization era"
the part i think is still underexplored is judgement
the paper talks about datasets, rl strategies, compute, loras and model ownership
dataset = can tell you what happened
judgement = tells you what mattered
if the future is thousands of specialised models, deciding what those models should learn from becomes equally ( imo probably more ) important than the data it learns from
judgement is very scarce but very needed

5
10
41
2,899
Earn in base:0xff8104251e7761163fac3211ef5583fb3f8583d6 , burn in base:0xff8104251e7761163fac3211ef5583fb3f8583d6
Btw the burns from datanet creation are automatic and we are working to make the publishing access fees programmatic burns too!

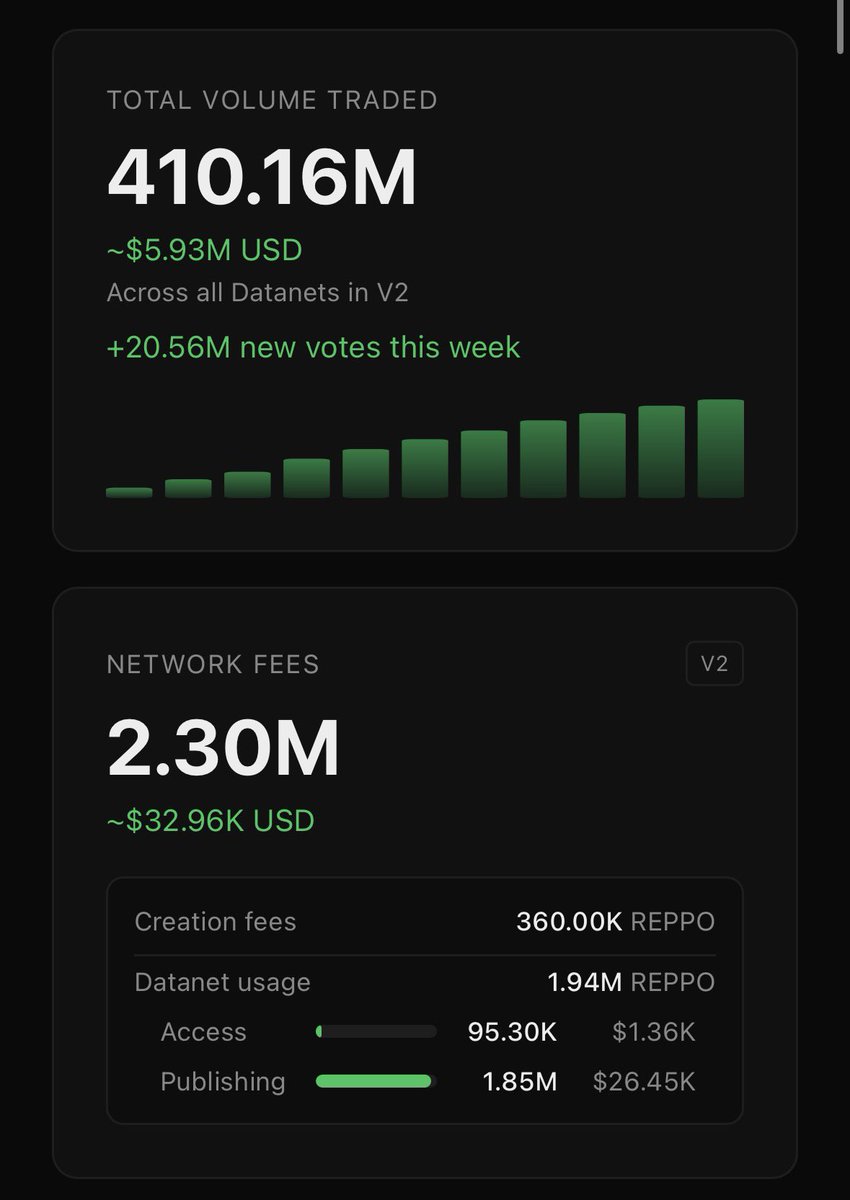
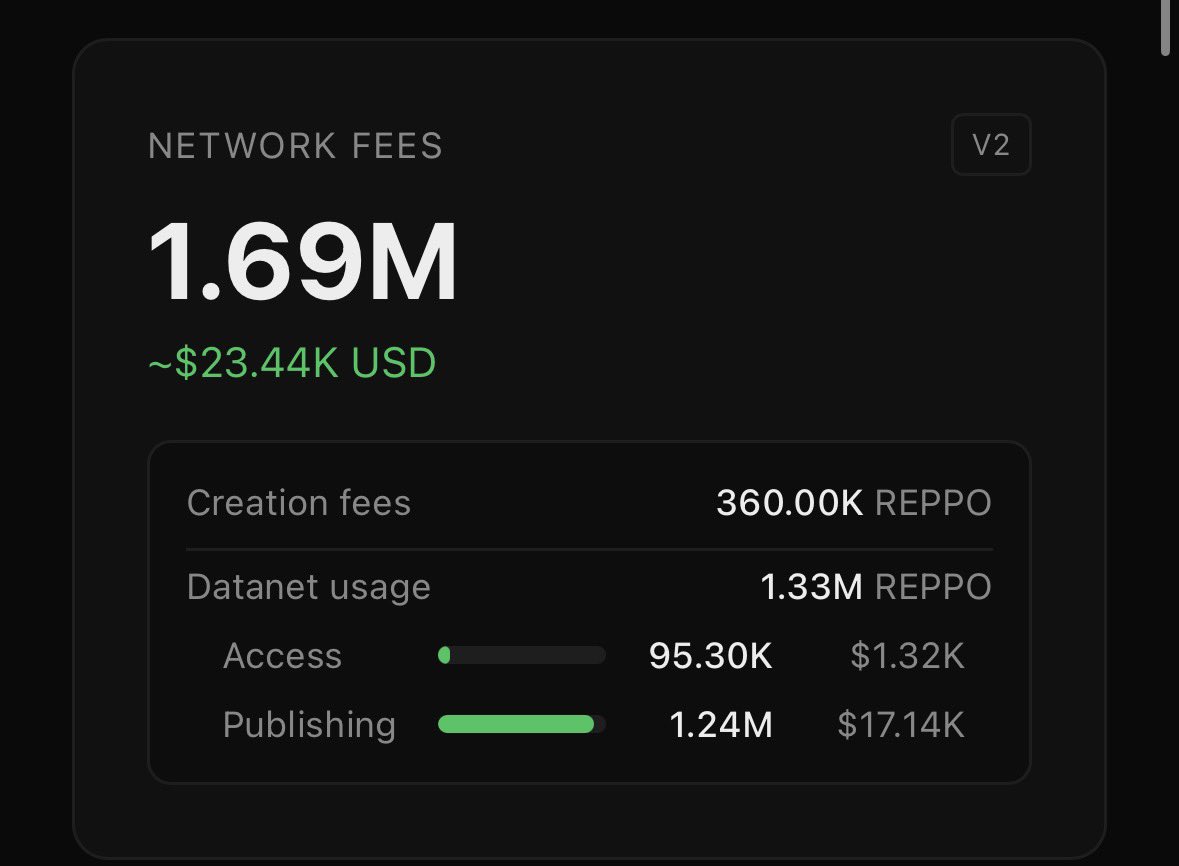
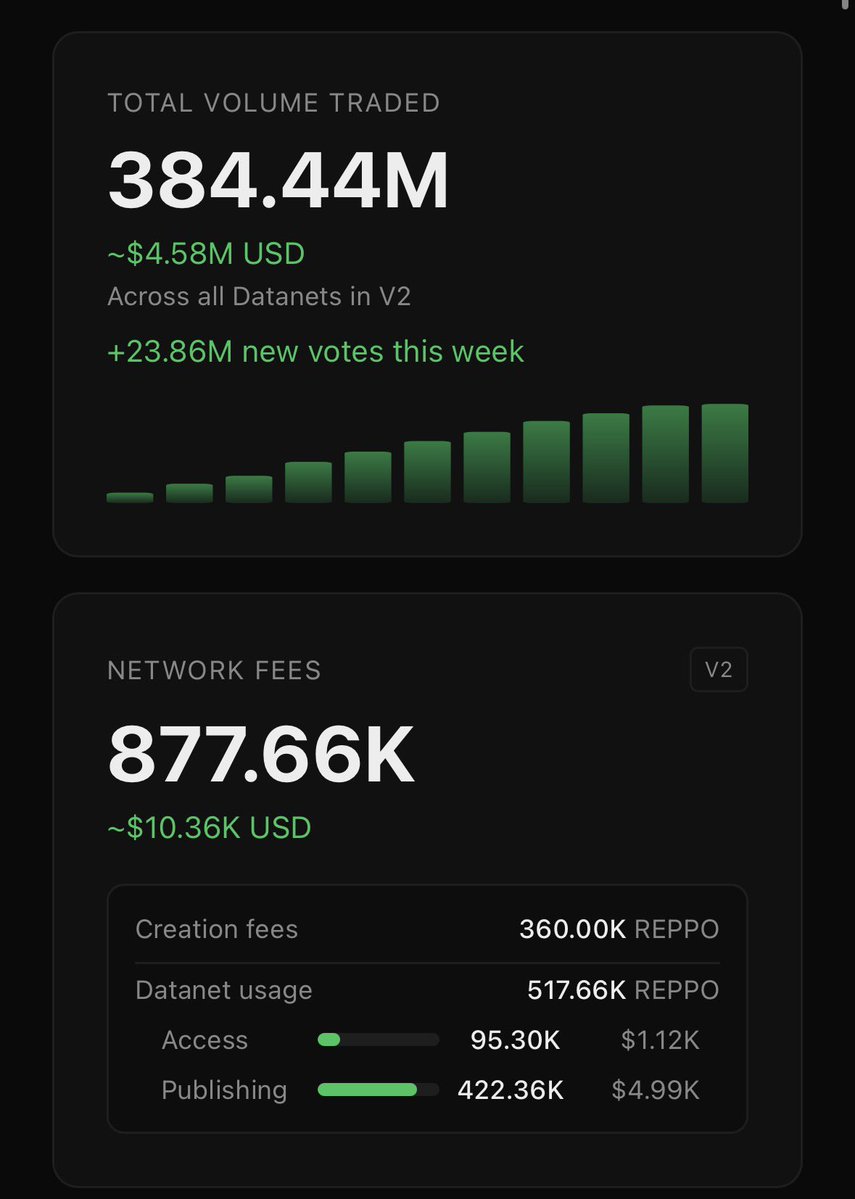
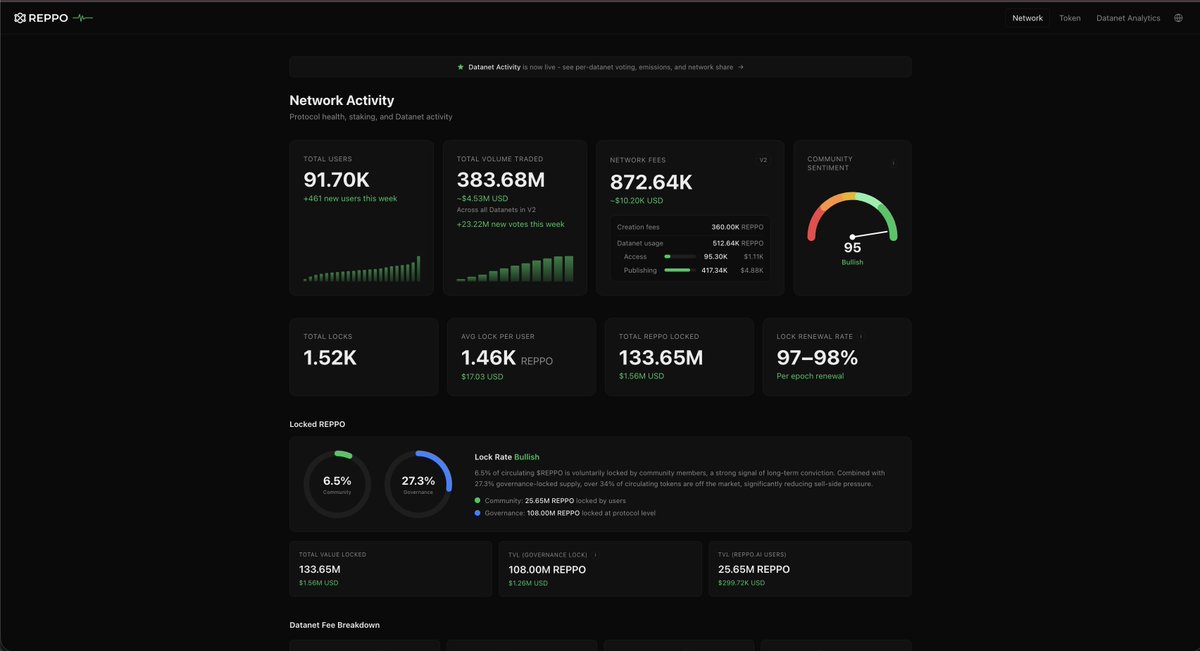
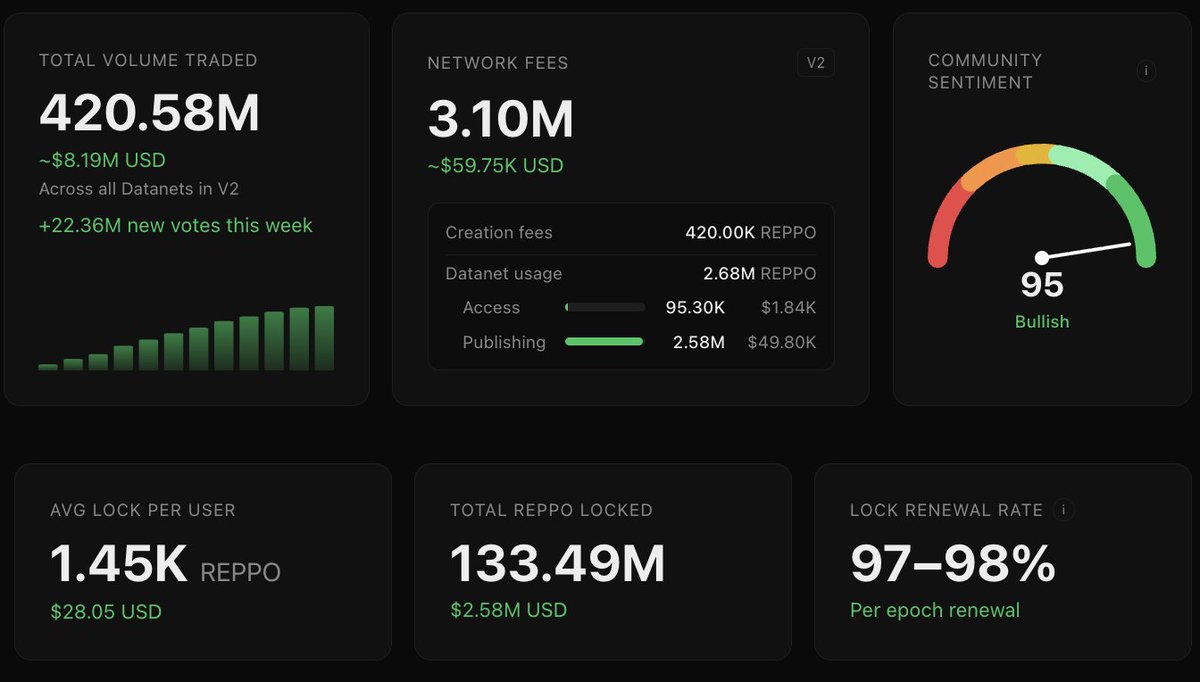
3M REPPO in Fees crossed!
An additional 580K REPPO burned
basescan.org/tx/0x75ba9b02e5…
Our next network KPIs are 5M in fees and 500M in trading volume.
9
45
741
RT @reppo: Enterprise expansion has begun!
Build no code games using AI on playabl.ai, publish on Reppo.ai an…
17
1
Agreed. It’s no longer just about consuming web2 outputs on web3 plumbing.
We’ll have to go up the full stack -
The data, algorithms, the compute.
How to make deployment of current and future open source models as useful and good closed labs? It’s possible. Less convenient but possible
Answer lies in localization of data inference.
The good thing is, there are already projects on chain pushing these limits. Just need more collaboration instead of liquidity wars ⛽️
Jun 13

Decentralized, permissionless, uncensored AI running on crypto plumbing is probably the most important battle arena of the next five years.
Actions like today’s are eye openers for many, but we knew. We knew governaments, technocrats, big companies where hoarding compute, talent, resources. A more and more centralized and dystopian future where social divide is even more prominent. Where access to frontier models is stonewalled.
It gives crypto once again a mission. A clear flag to carry.
The 0 to 1 moment is happening this year. Things will only accelerate going forward.
1
1
13
469