
Eater of food, facilitator of liquidity. All views are mine and do not reflect those of my employers - past or present.
Joined April 2009
- Tweets 31,486
- Following 594
- Followers 5,274
- Likes 6,930
826 Photos and videos















Pinned Tweet

21 Nov 2025
I will say this - LLMs are not replacing humans any time soon. I have experience in my domaim and know what to elicit from an LLM. I'm saving myself the hassle of typing 100K LoC every year. But if companies stop hiring young people, there will be a void in the pipeline and it will create havoc. "AI will replace SDEs" is a marketing gimmick. AI will make people more productive and result in more people writing more software. This non-hiring of juniors will be fixed soon enough.
2
3
25
30,755
Indian firms can get GPUs, which is not a problem (for now), but talent is a big, big problem. Indian companies just do not have it in them to pay people multi-million dollar compensation. An equally difficult problem is to convince such people to work in India. I feel that even if Silicon Valley-level comp was on offer, most people in that league would baulk at the idea of living in Indian cities. The solution is to open an office in Dubai or Singapore. That could also open the door to non Indian talent. A $10B spend is possible if 3-4 Indian ITES companies combine forces.
Jun 13

To train a GPT class 1T model from scratch - including failed runs, data acq clean rlhf, post-training, team/people will likely req $250M of compute on an aggressive 3-4mo schedule (i.e. more reserved GPUs), $500-600M all-in IF you do a dense one. MoE fp8 will cut costs by 1/10th depending on how many active params you have. If you want SOTA however, the budgets go significantly higher on test-time compute, post-training RL, and data/synthetic generations..and v. high on talent. Maybe $2-4B all-in. After that comes serving the model. The talent is key to get to SOTA/beat it - and then you have to ensure this is useful enough to have inference vol over time - for which the capital will come if there is usage / TAM. So this is not as much about raising $50-60B, or raising it all at once as the OP says - we are investors in mistral, sarvam, reflection and anthropic - and they all scaled capital over time as models got adoption, but the early bottleneck is more on talent GPUs at that scale where you can do interesting things.
64
37
444
51,478
Jun 12
These people need to be tested for performance-reducing drugs.
Firstly, DCs run on a closed loop. Their net daily consumption is negligible. Second, to put it in perspective, Bengaluru uses about 3000 mld and is growing fast.
Jun 12

data centres are draining bengaluru’s ground water. right now there are 31 data centres in bengaluru. data centres consume roughly 20 million litres of water EVERYDAY.
where will that water come from because bengaluru has no river and is entirely dependent on groundwater.
more data centres are planned and upcoming. our country will not survive this. the planet will not survive this. we will not survive this.
1
34
1,235
Jun 12
But the Mudi must rejine
Jun 11

The drop in nitrogen fertilizer prices has now extended into Asia. India has received offers for its latest urea tender at an average price of $530 per tonne, down ~44% from $947 per tonne in April.
1
1
13
893
Jun 12
Debut itself is unsustainable
Jun 11

BREAKING: Jim Cramer says that SpaceX could soar to unsustainable levels after its debut
5
366
Jun 12
My wife and I lost close to 400K miles each when 9W died. In the end we burnt it all for ¢/$ through the Intermiles thing. Since then I've kept all my miles in the credit card side rather than transfer it to the airline/hotel program.

Just discovered that I've let 500,000 miles expire on one of my frequent flier accounts. Totally gutted.
2
7
2,095
Jun 12
While I don't know about the returns produced by Marcellus, just comparing returns vs the benchmark is half the story. On this basis, almost all multistrats in the world absolutely suck over the last 5 years. But inflows continue to be strong because on risk adjusted basis they outperform the index. To every allocator that's a valuable service. Of course this is a non issue for retail. Sometimes there is much more than meets the eye. However, AUM becoming a 1/5th in four years is pretty poor.

AUM of 12000 cr in June 2023 to an AUM of 2500 cr in May 2026 is the real Sankatkaal sir.
Saurabh Mukherjea says we are in Sankatkaal but his PMS clients have been in Sankatkaal ever since they gave their money into the hands of Marcellus Investment Managers.
His main Scheme Consistent Compounders Portfolio benchmarked against Nifty 50 fell short of even Nifty 50 returns over 1 year, 2 years, 3 years, 5 years, and since Inception. So are his other schemes.
His client base fell from 7000 clients to 2133 clients in last 30 odd months.
AUM fell from a massive 10000 cr to 2515 cr in the last 30 months. Marcellus has seen negative net flows every month.
He is an amazing salesman but clients have seen through his inability to generate returns.
Our Media houses dont question him because they need each other to scratch each other’s back. Its a shame. Retail Investors must be extremely careful when we have such a scary ecosystem built by incapable fund managers and media houses.

2
9
2,618
Jun 12
That game is over. Whoever comes to power will realize that Adani and Ambani are instruments of the states will. As are most other very large industrial houses. They can move mountains the govt cannot, especially overseas.
Behind the scenes, all these industrialists and politicians have great relationships. It's only here on X that people are willing to live or die with this nonsense.
1
3
23
1,370
Jun 11
Claude teams is precisely for enterprises and has a Premium seat feature. As an enterprise you can take an enterprise subscription or teams subscription based on your needs. I also know of firms that are paying an extra salary component that is equal to two Claude Max 20x accounts. Lots of solutions out there.

Correction here. There's no $200/mo plan for enterprises. Enterprises are all on token based usage.
Have some imagination and you can think of a scenario where TCS has their employees use Sonnet 4.5 level model and get majority of what they already do done with far higher quality, fraction of the price.
343
Jun 11
Of ourse people are going to put on a carry trade. Really retarded move.

232
Rishabh Mukherjee retweeted

Jun 10
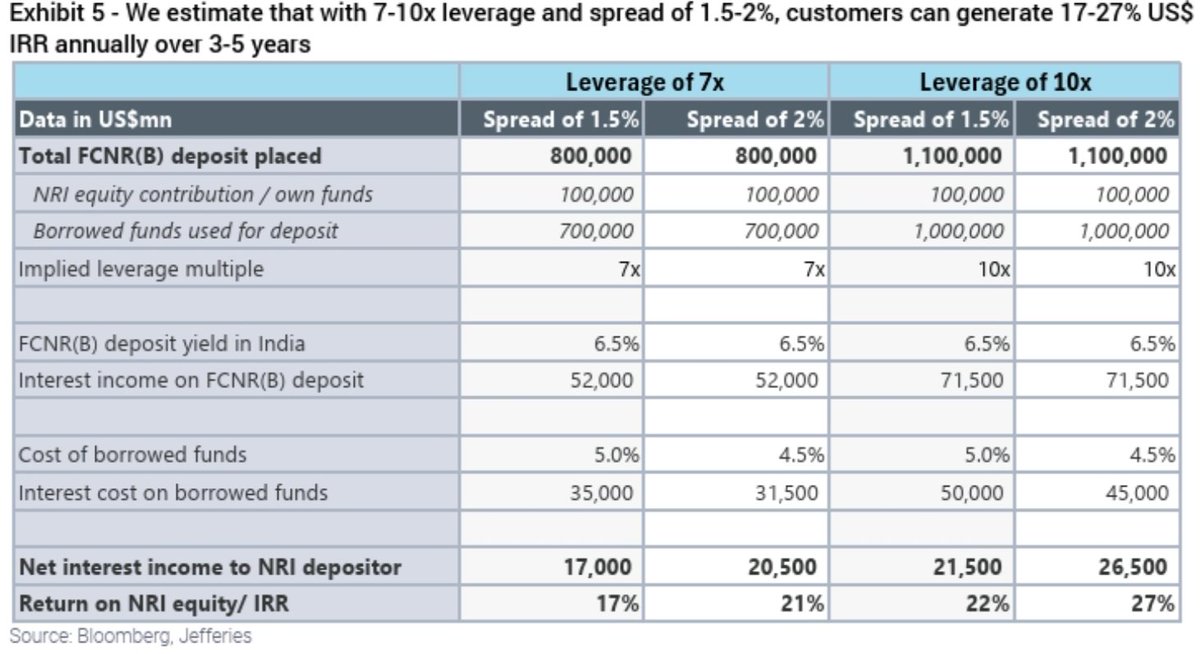
Two weeks before RBI announced the FCNR(B) hedging subsidy, I published a thread arguing they should not do it.
They did it anyway.
So now the honest question. As an NRI investor, should you take it?
My answer will sound like a contradiction. It is not. 🧵
13
8
131
72,931
Jun 11
Blue Label? Black Label?????
Chal kya raha hai
Jun 11

Man was crooked enough to amass 200 cr but not clever enough to hide the money safely. The whiskey bottles are a nice touch.

3
8
1,268
Jun 11
What do any of these people have in common? This stuff does not produce a stable govt.
Jun 10

BREAKING : After a possible TMC merger into Congress, Rohit Pawar also hinted at a probable NCP merger
“TMC Chief and NCP Chief are considering the proposal. Merger is definitely possible, at the right time.”
Mark my words, United Congress with old heavyweights will completely destroy BJP in 2029 🔥
12
758
Jun 10
Shareholders of TCS and Tata Sons should be thankful that these folks invested in the AI that they did and not the other one. With geniuses like these in charge...

TCS To Have As Many AI Agents As Staff In Next 3 Years: N Chandrasekaran
ndtv.com/india-news/tcs-to-h…

3
1
15
1,980
Jun 10
This is the tweet of the day
Jun 10

This is like a guy in the 90s saying we will have as many excel files as employees….
4
570
Jun 10
Tell this to your great party leader RaGA who doesn't believe in private enterprise and wants to go back to the days of the govt being the only player in town.
Jun 10

Shashi Tharoor: 75-80% of research and development costs are borne by the private sector in developed countries. In India, 75% of R&D spending is done by the government. This is crazy
5
27
1,093
Jun 10
Not to be that guy, but technically speaking, no investment of any form can beat a fixed deposit on a risk-adjusted basis because most common measures of risk-adjusted returns involve division by standard deviation in either returns or direction of returns - both of which for a fixed deposit are zero. Divide by zero -> ∞
The reason you invest in lower "Risk Adjusted Return" (think sharpe/sortino) products is higher absolute returns. If you give it enough time, that thesis can play out as it has for millions of retail investors who have done so via simple passive investments. This is also true in the institutional space where many Macro and Equity L/S firms have a great track record of returns, but terrible Sharpes.
I'm surprised none of the panellists called this out. But I am not surprised, given the quality of the vast majority of Indian financial journalism, their programs, and their guests.
Jun 9

Shankar Sharma on retail investors:
“Equity markets are meant for big boys and professionals, they’re not meant for Mr. Joe on the street (retail investors).”
“Best you can make 10-12%, those days are also in the hindsight. Add taxes on that and you cannot even beat FD returns.”
“I have never advised my relatives or friends or even my own sister to invest in equity directly and today they thank me.” 😅
- src: NDTV Profit. June 2026
12
16
74
16,410
Jun 10
Nahin milega. Baith jaiye, baith jaiye.
Jun 9

Starlink remains in active and productive discussions with the Government of India contrary to misleading stories based upon unsubstantiated claims from anonymous sources.
We have worked with the Government through all of the required regulatory and compliance processes in a transparent and responsible manner. To align with India's sovereign technology, regulatory and security requirements, Starlink has setup a bespoke deployment model for India that further demonstrates our commitment to working within India’s strategic framework.
We have heard nothing but encouraging feedback on Starlink’s capabilities and its potential to advance India’s connectivity ambitions, especially in remote and underserved regions. We remain fully committed to India and to working with the Government to bring Starlink’s services very soon to the country.
1
9
947
Jun 10
Dada, nobody wants to invest in a Greenfield project because then the politicians of the country have an avenue to blackmail you. If you are say $1B into some research, you'll need to sell to break even. The politicians in the govt of the day will find a way to extract money from you by threatening to enact a policy that makes it impossible for you to sell. Nobody wants this headache. So going forward all this money will be in family offices where you can't really be subject to such blackmail.

India Inc is sitting on more than $100 billion in cash.
Clearly, Indian companies don't have the confidence to invest in India.
Then why do we expect foreign companies to rush in with FDI?
12
22
208
25,808
Jun 10
Feeding such junk to the alligators must be a crime.
Jun 10

Whoever at X who decided to replace the "copy link" button with "send via DM" deserves to be thrown into an alligator pit.
2
15
2,160