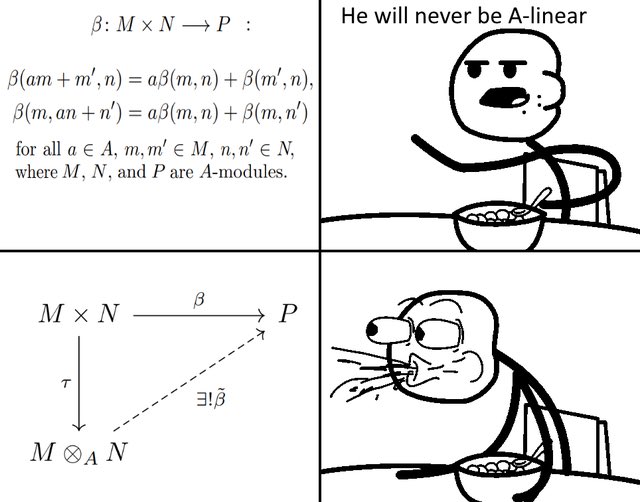Focused on AI work.
Joined October 2014
- Tweets 2,610
- Following 864
- Followers 455
- Likes 2,029
301 Photos and videos















Rob K retweeted

7 Dec 2025
TransformerLens 3.0 is out! 🎉 Congrats to collaborator and friend Bryce Meyer (no X 😢) for getting it across the line. Details in the Open Source Mechanistic Interpretability slack: opensourcemechanistic.slack.…
1
1
185
Rob K retweeted

19 Sep 2025
Sphinx is helping businesses unlock their sprawling and disparate datasets -- read more in Fast Company’s profile of how we’re rethinking AI for data science ⬇️
fastcompany.com/91405220/why…
1
4
14
619
Rob K retweeted

11 Jul 2025
Joseph's guide provides clear tactical advice on how to learn RL.
Give it a read. Build Environments. You can just learn RL.
11 Jul 2025

1
7
79
4,500
Rob K retweeted

13 Mar 2025
🧵Chain-of-Thought reasoning in LLMs like Claude 3.7 and R1 is behind many recent breakthroughs.
But does the CoT always explain how models answer?
No! For the first time, we show that models can be unfaithful on normal prompts, rather than contrived prompts designed to trick them.
11
62
515
113,396
Rob K retweeted

1 Oct 2024
🚨 IAPS is hiring 🚨
We seek Researchers / Senior Researchers to join our team to identifies concrete interventions that could manage risk and secure benefits of advanced AI.
One role is fully remote and can be done in most countries, the other will be in DC.
App due Oct 21

2
14
42
10,255
19 Jul 2024
Outer loss transmits very limited bits of information through the info-theoretic bottleneck of the training process... so yes, if your function family (eg wetware brains) priors mesa-optimizers relatively densely, no sparsely delivered outer loss (death in the EEA) suffices...
22 May 2023

"Train it to be nice" is the obvious thought. Alas, I predict that one idiom that does generalize from natural selection to gradient descent, is that training on an outer loss gets you something not internally aligned to that outer loss. It gets you ice cream and condoms.
249
19 Jul 2024
Disagree. "Gradient-descenting" is the wrong verb as it implies attribution to kindness-likelihood is primarily the optimizer. The text that is to be predicted matters; the etiology of the ontology implicit in the training distribution *was* shaped by m-s of proteins and IS kind
22 May 2023
Gradient-descending an AI system to predict text, or even to play video games, is nothing like this. It is exploring nowhere near this space. Gradient descent of matrices is not mutation-selection of proteins and I don't expect it to hit on anything like similar architectures.
1
1
276
Rob K retweeted

19 Jul 2024
The Microsoft / CrowdStrike outage has taken down most airports in India. I got my first hand-written boarding pass today 😅

1,165
10,456
58,184
8,015,580



18 Jul 2024
What does fine tuning do to models? Do representations transfer between base and chat versions? Find out in the next episode of @Connor_Kissane and Rob project!
18 Jul 2024

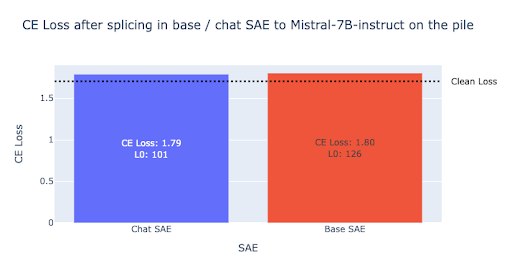
New post with @robertzzk, @ArthurConmy, & @NeelNanda5: Sparse Autoencoders (usually) Transfer between Base and Chat Models! This suggests that models' representations remain extremely similar after fine-tuning.
1
159
Rob K retweeted

18 Jul 2024
New post with @robertzzk, @ArthurConmy, & @NeelNanda5: Sparse Autoencoders (usually) Transfer between Base and Chat Models! This suggests that models' representations remain extremely similar after fine-tuning.
3
4
42
9,977
12 Jul 2024
Open X for *one* moment and then it's, like, 3 hours of ML paper reading later...
👋 cya crazy peeps
2
113
12 Jul 2024
My feed is nothing except COLM paper acceptances.
I get, it you got in, nice job. I'm very proud of you.
2
139
27 Jun 2024
Sparse Autoencoders help us understand the MLPs of LLMs, but what's up with attention?
Find out in our new paper with @Connor_Kissane and @NeelNanda5!
26 Jun 2024
Sparse Autoencoders help us understand the MLPs of LLMs, but what's up with attention?
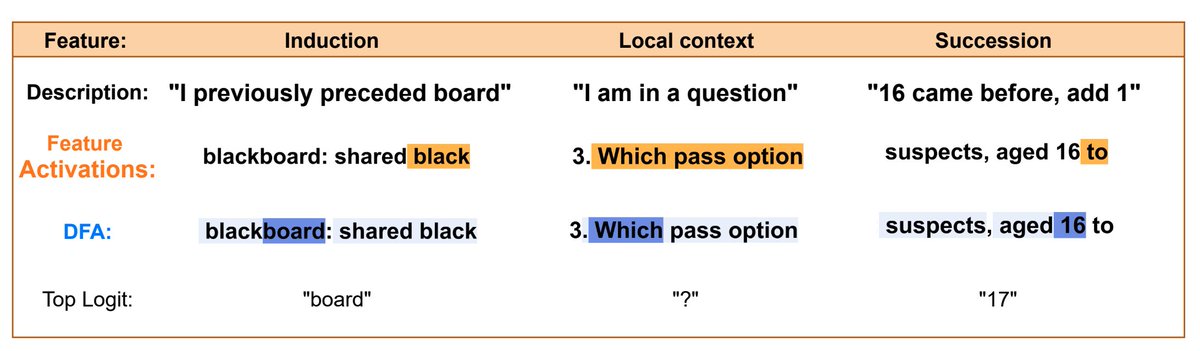
In our new paper with @NeelNanda5, we introduce Attention Output SAEs to uncover what concepts attention layers learn. Further, we use them to find novel insights previously out-of-reach!🧵
4
157
22 Jun 2024
One step closer to a full symbolic notation for dance: zacksdancelab.com/blog/a-new…
109
22 Jun 2024
New attention sparseautoencoders post dropped.
$1000 bounty to whomever find the best attention circuit!
21 Jun 2024

Great post from my scholars @Connor_Kissane
& @robertzzk!
SAEs are fashionable, but are they a useful tool for researchers? They are! We find a deeper understanding of the well-studied IOI circuit, and make a circuit analysis tool
$1000 bounty to whoever finds the best circuit!
1
5
2,307
Rob K retweeted

6 Mar 2023
Anyone know of any publications or research on changing out the activation function of trained transformer network? Looking to replace GELU with ReLUs in a trained model with minimal finetuning/postprocessing
1
1
6
796