
Distinguished Engineer, IBM Research
Joined June 2015
- Tweets 63
- Following 484
- Followers 1,254
- Likes 1,993
4 Photos and videos





Apr 14
We are looking for exceptional candidates to join the core Granite LLM team at IBM Research. If you’re interested, please fill out this form:
👉 forms.gle/DFoBFTAS7Cb2wsun6
12
22
353
37,304
Rameswar Panda retweeted

Mar 19
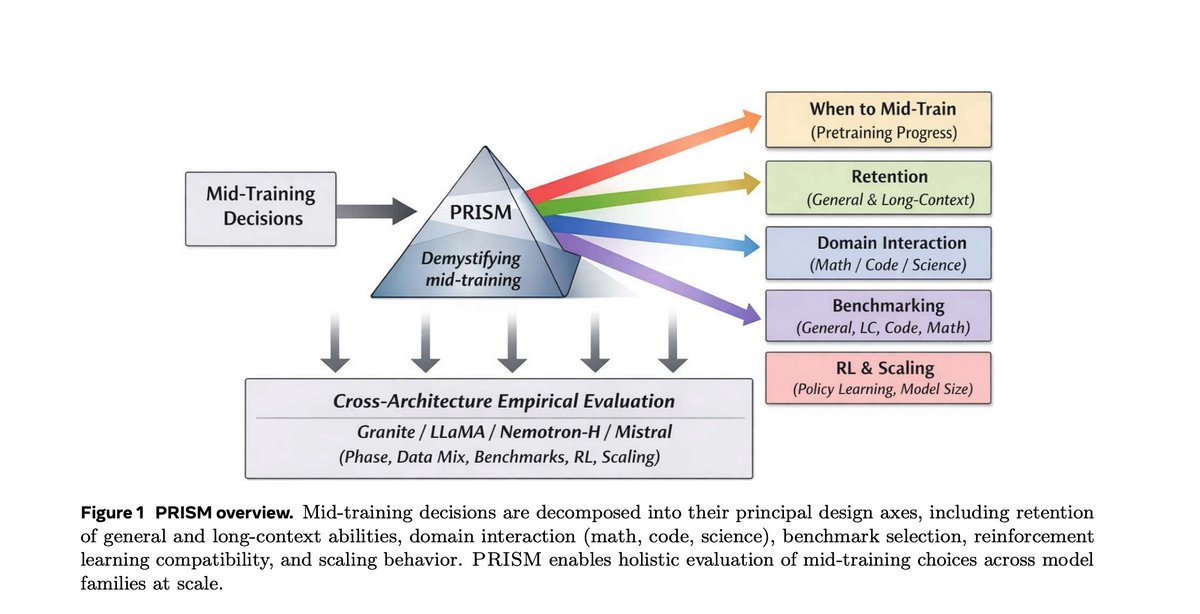
Found another great midtraining paper. I haven't seen it on my TL so thought I would share. Super excited to dig into it later but looks really promising. (ty @lukemerrick_ )
I love seeing more work unifying understanding of midtraining -> RL



3
31
286
28,218
Jan 9
At IBM Research, we’re always interested in connecting with researchers and engineers who are passionate about building open and efficient LLMs for enterprise. If this aligns with your interests, you can share your background with our team using:
👉 forms.gle/DFoBFTAS7Cb2wsun6
1
9
1,290
7 Oct 2025
Amazing work from @zhangchen_xu!
3 Oct 2025

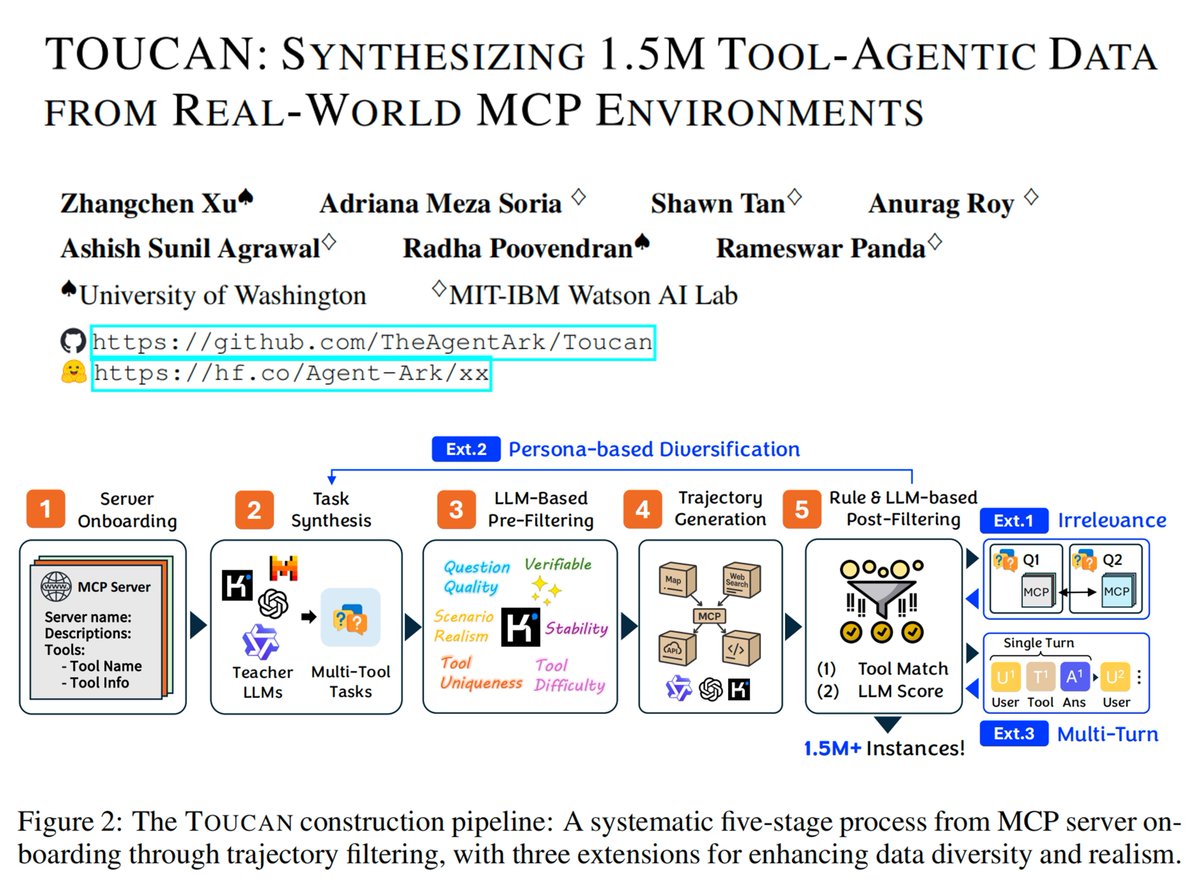
🚀 Want high-quality, realistic, and truly challenging post-training data for the agentic era?
Introducing Toucan-1.5M (huggingface.co/papers/2510.0…) — the largest open tool-agentic dataset yet:
✨ 1.53M real agentic trajectories synthesized by 3 models
✨ Diverse, challenging tasks across wide domains
✨ Built from 495 MCP servers & 2K open-source tools
📈 SOTA results on BFCL & MCP-Universe with just SFT.
💡 Data, models, and pipeline are all open!
Key Features:
- Multi-tool & multi-server tasks for advanced planning
- Multi-turn interactions with auto-generated follow-ups (super-long trajectories)
- Single parallel function calls → efficient tool use
3
660

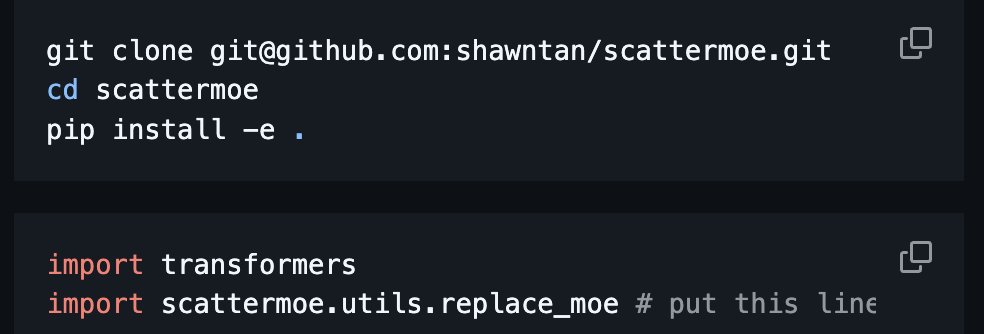
If you want to fine-tune the Granite 4.0 MoE models, Unsloth has a ready-to-go recipe here!
If you're gonna roll your own, I've updated scattermoe to inject a forward pass to the Huggingface implementation that uses scattermoe.
github.com/shawntan/scatterm…
2 Oct 2025

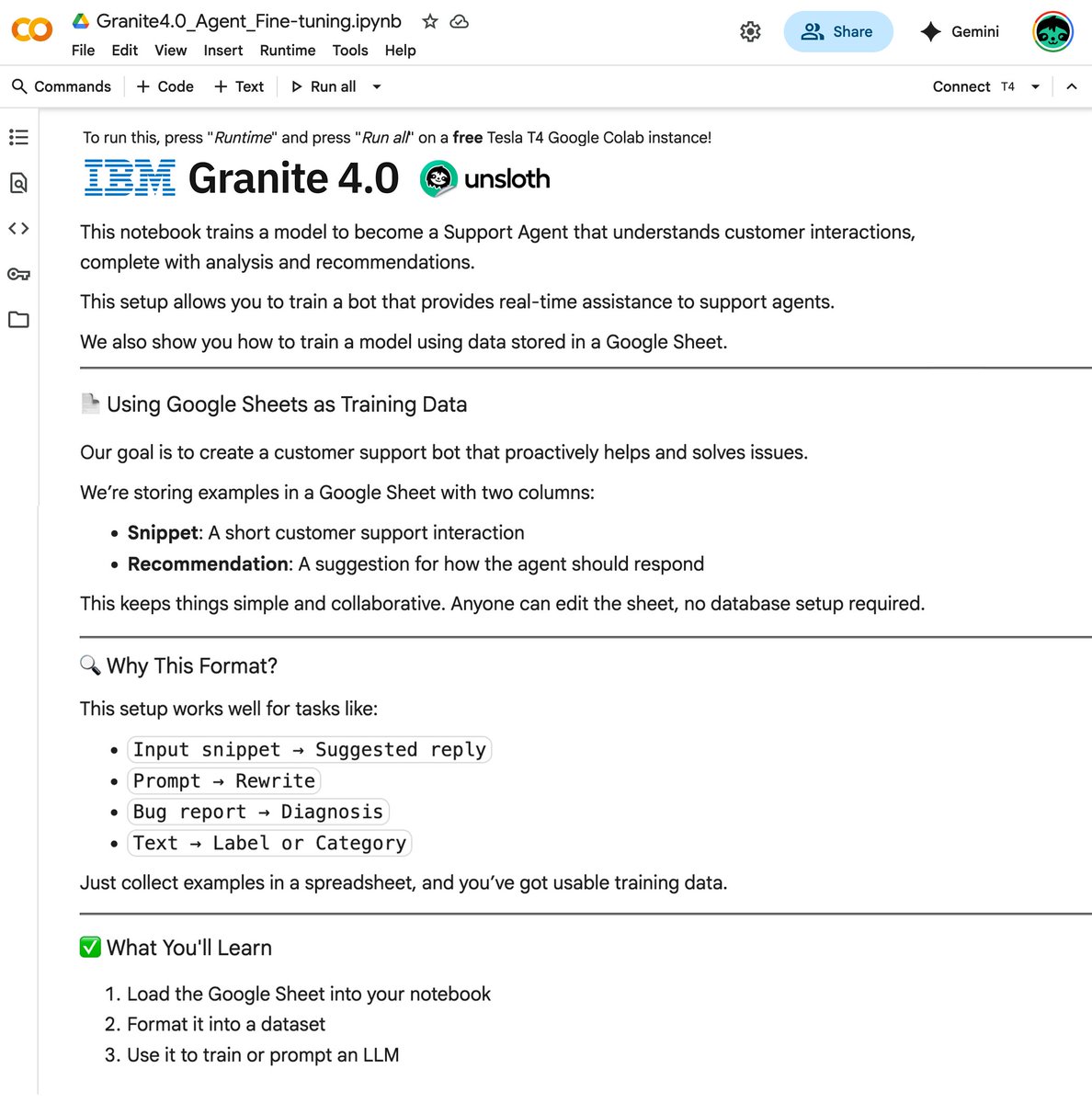
We made a free notebook that fine-tunes IBM Granite 4.0 into a powerful support agent!
This agent will enable real-time analysis & solving of customer interactions.
You'll also learn how to train models using data from Google Sheets.
Colab Notebook: colab.research.google.com/gi…
1
5
36
7,443
Rameswar Panda retweeted

24 May 2025
📢 (1/16) Introducing PaTH 🛣️ — a RoPE-free contextualized position encoding scheme, built for stronger state tracking, better extrapolation, and hardware-efficient training. PaTH outperforms RoPE across short and long language modeling benchmarks
arxiv.org/abs/2505.16381
9
90
543
76,884
14 Mar 2025
🚨Hiring🚨 We are looking for research scientists and engineers to join IBM Research (Cambridge, Bangalore). We train large language models and do fundamental research on directions related to LLMs. Please DM me your CV and a brief introduction of yourself if you are interested!
11
53
605
71,555
21 Sep 2024
Apply soon if you’re interested in joining a small, growing team to make a large impact together!!
20 Sep 2024

🚨Job alert🚨
1. IBM Foundation Model team is hiring research engineers in India and North Carolina.
2. We are also looking for 2025 summer research interns in Boston.
We train large language models and do fundamental research on directions related to LLMs.
Please email or DM me your CV and a brief introduction of yourself if you are interested!
1
15
4,590
Rameswar Panda retweeted

27 Aug 2024
Thanks for posting our work!
(1/5) After running thousands of experiments with the WSD learning rate scheduler and μTransfer, we found that the optimal learning rate strongly correlates with the batch size and the number of tokens.
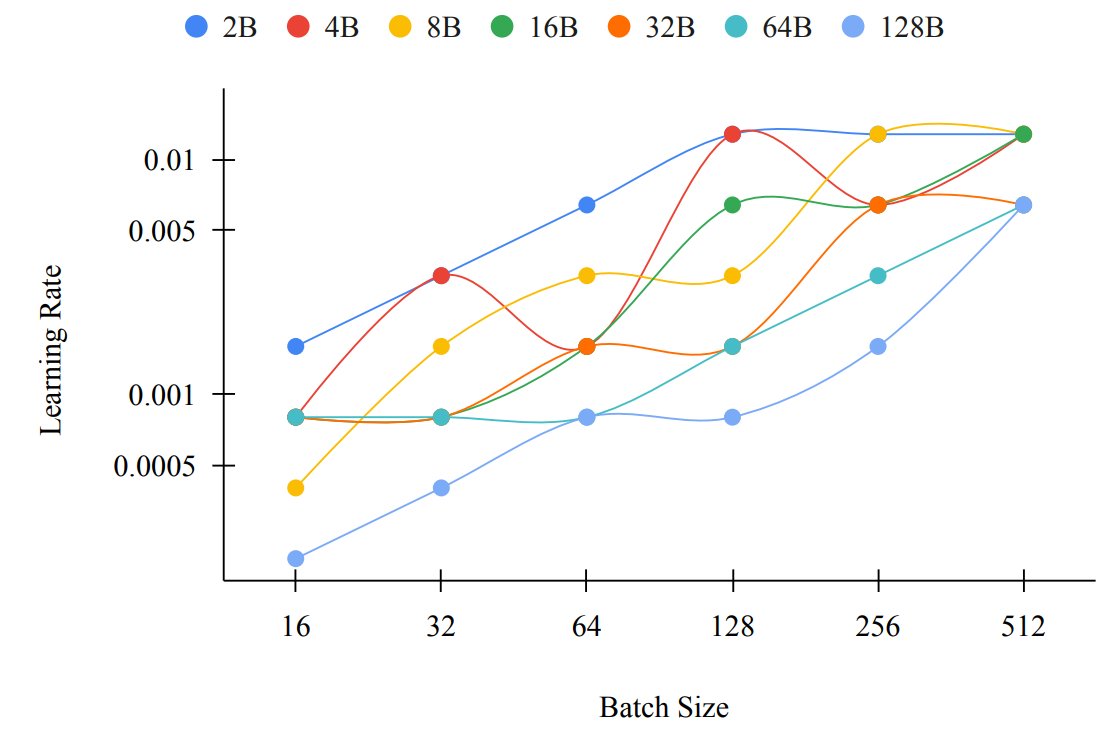

IBM presents Power Scheduler
A Batch Size and Token Number Agnostic Learning Rate Scheduler
discuss: huggingface.co/papers/2408.1…
Finding the optimal learning rate for language model pretraining is a challenging task. This is not only because there is a complicated correlation between learning rate, batch size, number of training tokens, model size, and other hyperparameters but also because it is prohibitively expensive to perform a hyperparameter search for large language models with Billions or Trillions of parameters. Recent studies propose using small proxy models and small corpus to perform hyperparameter searches and transposing the optimal parameters to large models and large corpus. While the zero-shot transferability is theoretically and empirically proven for model size related hyperparameters, like depth and width, the zero-shot transfer from small corpus to large corpus is underexplored. In this paper, we study the correlation between optimal learning rate, batch size, and number of training tokens for the recently proposed WSD scheduler. After thousands of small experiments, we found a power-law relationship between variables and demonstrated its transferability across model sizes. Based on the observation, we propose a new learning rate scheduler, Power scheduler, that is agnostic about the number of training tokens and batch size. The experiment shows that combining the Power scheduler with Maximum Update Parameterization (muP) can consistently achieve impressive performance with one set of hyperparameters regardless of the number of training tokens, batch size, model size, and even model architecture. Our 3B dense and MoE models trained with the Power scheduler achieve comparable performance as state-of-the-art small language models.

4
27
130
31,811
Rameswar Panda retweeted

30 May 2024
We have released 4-bit GGUF versions of all Granite Code models for local inference. 💻
The models can be found here: huggingface.co/collections/i…
9
13
1,844
Rameswar Panda retweeted

22 May 2024
Reducing Transformer Key-Value Cache Size with Cross-Layer Attention
Shows that it is possible to share key and value heads between adjacent layers w/o perf degradation
arxiv.org/abs/2405.12981

5
76
361
45,585
Rameswar Panda retweeted
17 May 2024
JetMoE and IBM Granite Code models are now natively available on in Huggingface Transformers v4.41!
github.com/huggingface/trans…
1
8
13
2,883
Rameswar Panda retweeted
13 May 2024
Yes, our goal is to create really useful code LLMs for real production use cases, not for just getting some kind of sota on HumanEval (but we still get it 😉).
12 May 2024

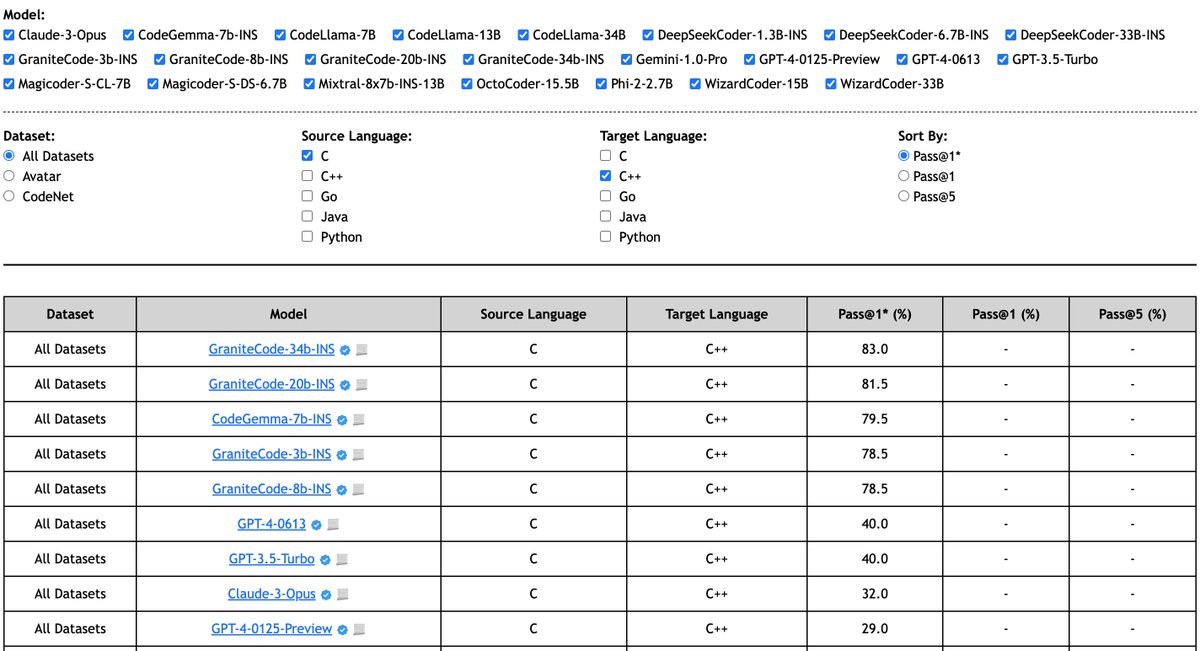
Interested in LLM-based Code Translation 🧐?
Check our CodeLingua leaderboard (codetlingua.github.io/leader…). We have updated the leaderboard with newly released Granite code LLMs from @IBMResearch. Granite models outperform Claude-3 and GPT-4 in C -> C translation 🔥.
7
20
5,602
13 Jan 2024
Our team is currently looking to hire PhD candidates for 2024 summer internship, to work on efficient training and inference of large language (and/or multimodal) models. Please DM or send me an email if you are interested. @MITIBMLab @IBMResearch
3
16
75
14,578
5 Jul 2023
We at @MITIBMLab, are currently looking for a senior AI researcher, to work on efficient large language models, and develop prototype solutions to real-world problems, while publishing papers in top AI conferences. Apply at: careers.ibm.com/job/18637769… #NLP #efficiency #LLMs #AI
1
10
30
5,061
28 Mar 2023
We at @MITIBMLab, are currently looking for a research software engineer, to work on efficient large language models, and develop prototype solutions to real-world problems, while publishing papers in top AI conferences. Apply at: krb-sjobs.brassring.com/TGne… #NLP #efficiency #LLMs
1
8
30
4,326
21 Jan 2023
Happy to share that 3 papers on Efficient AI accepted to @iclr_conf. One as a "notable-top-25%" paper (Spotlight). Huge thanks to all my co-authors. Stay tuned for more details! Work @MITIBMLab #ICLR2023
1
35
5,764
5 Jan 2023
Very happy to announce that our work "Select, Label, and Mix: Learning Discriminative Invariant Feature Representations for Partial Domain Adaptation" received the Best Paper - Honorable Mention award at #WACV2023! @MITIBMLab

4
6
52
13,381
5 Jan 2023
1
3
797
5 Jan 2023
Project Page: cvir.github.io/projects/slm.…
Code: github.com/CVIR/SLM
#ComputerVision #MachineLearning @wacv_official
3
672