
50 Photos and videos







Pinned Tweet

May 20
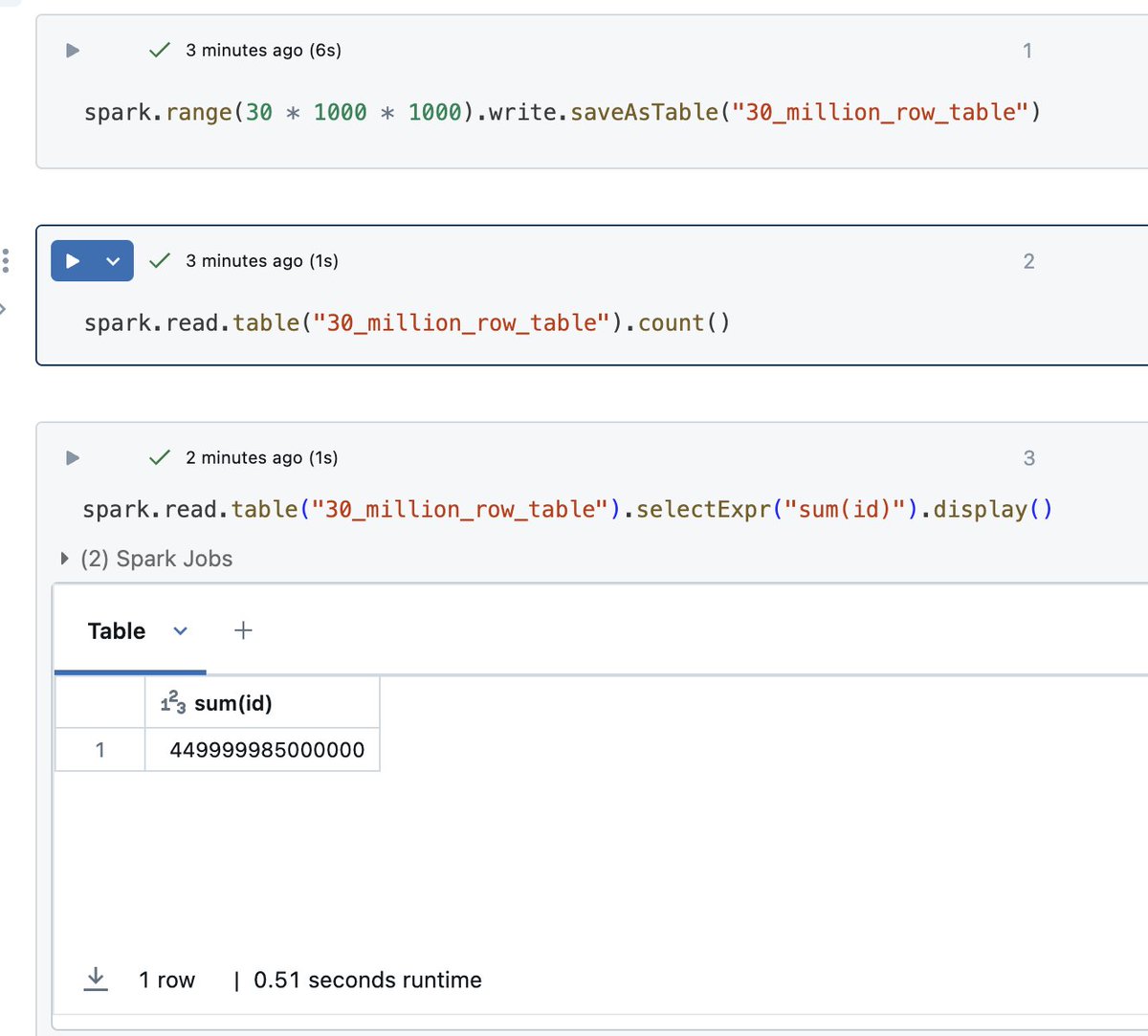
Oracle has spent the last two weeks writing articles comparing Oracle (and PDB) to Lakebase, and it highlights a massive philosophical divide in how we view databases in the agentic era.
They are trying to retrofit heavy, traditional architectures for AI. We believe Lakebase are the future because agents need something entirely different:
⚡️ Super simple APIs: so agents don't have to read a giant manual and hallucinate a query.
⚡️ Sub-second provisioning & auto-scaling: so you aren't paying legacy-level prices for idle time.
⚡️ Branching: Git-style branching to create isolated, safe environments for agents on the fly.
⚡️ Automatic backup & restore: so you don't sweat it when an autonomous agent inevitably drops a table.
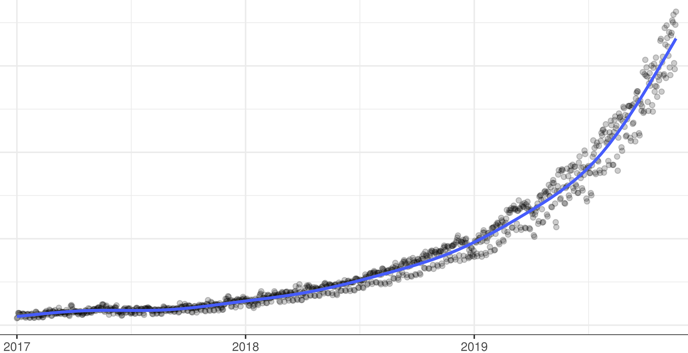
The numbers speak for themselves. Lakebase is our fastest growing product. In the last few months alone, we've seen database start rate 30X, and now we are starting tens of millions of databases EVERY DAY. Some of these databases have 500 level deep branches and lifetime of just seconds due to how fast agents move.
Go try it yourself in a few seconds on neon.com!
The team has been cooking hard to push this gap even further. Come to Data and AI Summit next month to hear about some major new breakthrough capabilities. 🚀
(Links next so you can read their take)
2
10
43
7,876
Reynold Xin retweeted

Really excited to open source a new project: Omnigent, a meta-harness for AI agents.
It lets you build multi-agent coding and custom agents, sitting above Claude Code, Codex, Pi, and agent SDKs to let you compose them. It also adds live collaboration and rich control policies.

63
157
851
118,157
Reynold Xin retweeted

May 28
Big news: Neon is expanding to offer a more complete set of backend primitives for running apps and agents:
✅ Database ✅ Authentication 🔜 Storage 🔜 Compute 🔜 AI Gateway

4
9
49
16,417
May 28
The future of databases is being built directly on top of object stores. We call this the Lakebase architecture.
For a long time, the industry treated data lakes strictly as analytical or offline storage. But the Lakebase architecture is changing that by enabling true operational databases directly on top of the lake.
I believe this is the future of data infrastructure. It is how every database, whether it's an OLTP system or a vector database, should be built moving forward.
Of course, delivering the stringent performance requirements for operational databases on top of object stores require some creative engineering. Really excited to see more real-world examples of this architecture emerging. The team at Zilliz just shared a piece on why they rebuilt their vector database using this exact approach, and it perfectly captures where the industry is heading.
Check it out here: zilliz.com/blog/why-we-built…
1
9
28
2,829
May 20
Oracle has spent the last two weeks writing articles comparing Oracle (and PDB) to Lakebase, and it highlights a massive philosophical divide in how we view databases in the agentic era.
They are trying to retrofit heavy, traditional architectures for AI. We believe Lakebase are the future because agents need something entirely different:
⚡️ Super simple APIs: so agents don't have to read a giant manual and hallucinate a query.
⚡️ Sub-second provisioning & auto-scaling: so you aren't paying legacy-level prices for idle time.
⚡️ Branching: Git-style branching to create isolated, safe environments for agents on the fly.
⚡️ Automatic backup & restore: so you don't sweat it when an autonomous agent inevitably drops a table.
The numbers speak for themselves. Lakebase is our fastest growing product. In the last few months alone, we've seen database start rate 30X, and now we are starting tens of millions of databases EVERY DAY. Some of these databases have 500 level deep branches and lifetime of just seconds due to how fast agents move.
Go try it yourself in a few seconds on neon.com!
The team has been cooking hard to push this gap even further. Come to Data and AI Summit next month to hear about some major new breakthrough capabilities. 🚀
(Links next so you can read their take)
2
10
43
7,876
Reynold Xin retweeted

Apr 17
Life update: I joined Databricks this week!
I thought I’d do another startup after Hyperbolic, but I was surprised by how startup-y Databricks AI is.
@alighodsi, @pwendell, @matei_zaharia are in full founder mode. They’re the best founders I’ve met. I like working with people who aren’t “normal” and they definitely aren’t. For example, they invited me to an all-hands before I joined.
I’m also impressed by how many former founders are here. @akhilgupta and @hanlintang are incredible leaders.
A big bonus: I finally have unlimited Claude Code & Codex tokens!
AI adoption on the Databricks AI team is insanely high. Every engineer I’ve met uses AI heavily and shares their own ways to drive agents. Many talented people here.
I’m super pumped for this new journey!
155
38
1,619
141,327
Reynold Xin retweeted

Apr 10
Replit now deploys directly to Databricks.
Your apps run inside your Databricks environment while inheriting its security, governance, and data access.
Beta is live. Enterprises are already building with it and seeing massive acceleration in BI and internal tools.
28
50
652
112,968
Reynold Xin retweeted

Mar 30
@JeffDean says it best, the problem in this new agentic era is "tools designed for human speed interaction". That's why we think agents love 𝗟𝗮𝗸𝗲𝗯𝗮𝘀𝗲 𝗣𝗼𝘀𝘁𝗴𝗿𝗲𝘀, it can branch, snapshot, scale up and down in a second, orders of magnitude faster than other databases.
youtube.com/watch?v=joTYgvRH…
Read about this architectural shift from Database to Lakebase:
databricks.com/blog/what-is-…
2
12
66
9,814
Reynold Xin retweeted

Mar 24
the bigger story may be what comes next.
Ghodi said it out loud: "With the sort of SaaS disruption that we’re seeing, Databricks will definitely partake in that disruption"
He has the data, the AI... and now he's building the apps. Its the AWS playbook for the AI age.
Mar 24

Databricks enters cybersecurity... with Anthropic's models inside.
The company that stores data now wants to secure it too. The incumbents prepared for AI entering the market.... less clear they're prepared for the data vendor thats already inside the building
Sitting down w Databricks CEO @alighodsi today around 10:30a PT

8
9
75
20,324
Reynold Xin retweeted

Collaboration should be the default, not a paid feature. GitHub did it for coding, Neon does it for databases.
Mar 13

Big news: You can now add unlimited team members and create multiple organizations on the free plan. 🚀
This helps you isolate your projects, collaborate with ease, and never worry about "per-seat" pricing.
Check out what’s new in the console! 👇
5
2
23
4,376
Reynold Xin retweeted

gumloop raised a $50m series b led by benchmark
here's a video we had fun making about the journey
back to work.
126
69
1,122
313,612
Reynold Xin retweeted

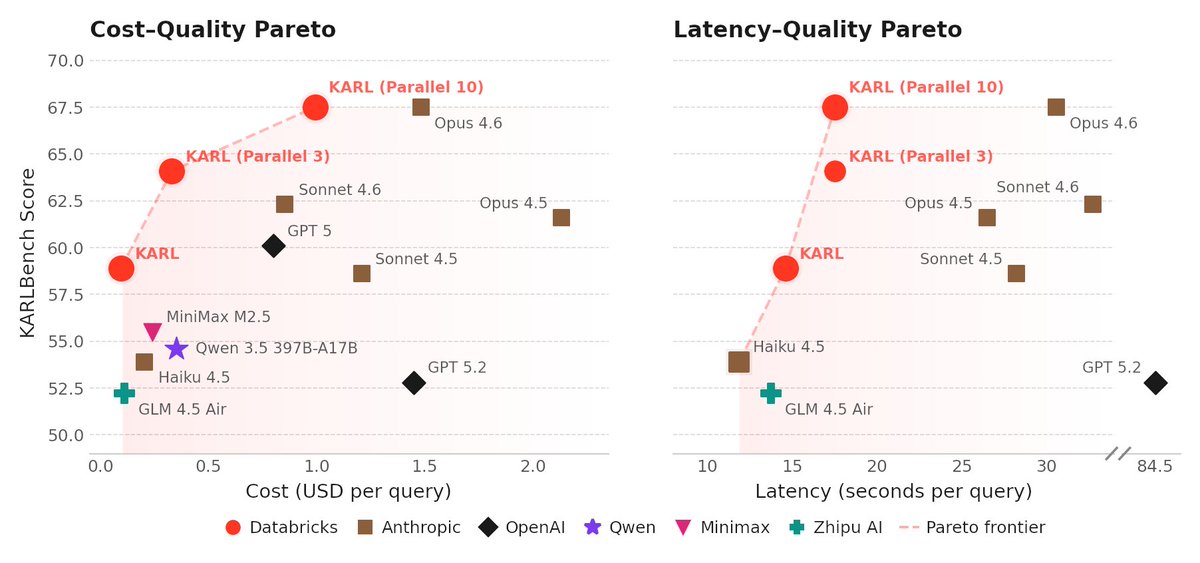
Mar 6
Awesome job by the @databricks team
My summary:
They trained a model called KARL that beats Claude 4.6 and GPT 5.2 on enterprise knowledge tasks (searching docs, cross-referencing info, answering questions over internal data), at ~33% lower cost and ~47% lower latency.
The key insight: instead of throwing expensive frontier models at enterprise search, you can use reinforcement learning on synthetic data to train a smaller model that's faster, cheaper, AND better at the specific task.
RL went beyond making the model more accurate. I t learned to search more efficiently (fewer wasted queries, better knowing when to stop searching and commit to an answer).
They're opening this RL pipeline to Databricks customers so they can build their own custom RL-optimized agents for high-volume workloads.
I think we'll continue to see data platforms become agent platforms. Databricks' KARL paper is really an agent platform play. The pitch: you already store your enterprise data in the Lakehouse, now Databricks will train a custom RL agent that searches and reasons over it, tuned specifically for your highest-volume workloads (workloads = apps = agents). The business move is closing the loop: data storage → retrieval → custom agent training → serving, all on Databricks. They're turning "your data lives here" into "your agents live here too."
Kudos @alighodsi @matei_zaharia @rxin

Meet KARL: a faster agent for enterprise knowledge, powered by custom reinforcement learning (now in preview).
Enterprise knowledge work isn’t just Q&A. Agents need to search for documents, find facts, cross-reference information, and reason over dozens or hundreds of steps.
KARL (Knowledge Agent via Reinforcement Learning) was built to handle this full spectrum of grounded reasoning tasks. The result: frontier-level performance on complex knowledge workloads at a fraction of the cost and latency of leading proprietary models.
These advances are already making their way into Agent Bricks, improving how knowledge agents reason over enterprise data.
And Databricks customers can apply the same reinforcement learning techniques used to train KARL to build custom agents for their own enterprise use cases.
Read the research → databricks.com/sites/default…
Blog: databricks.com/blog/meet-kar…
31
91
1,213
371,528
Reynold Xin retweeted
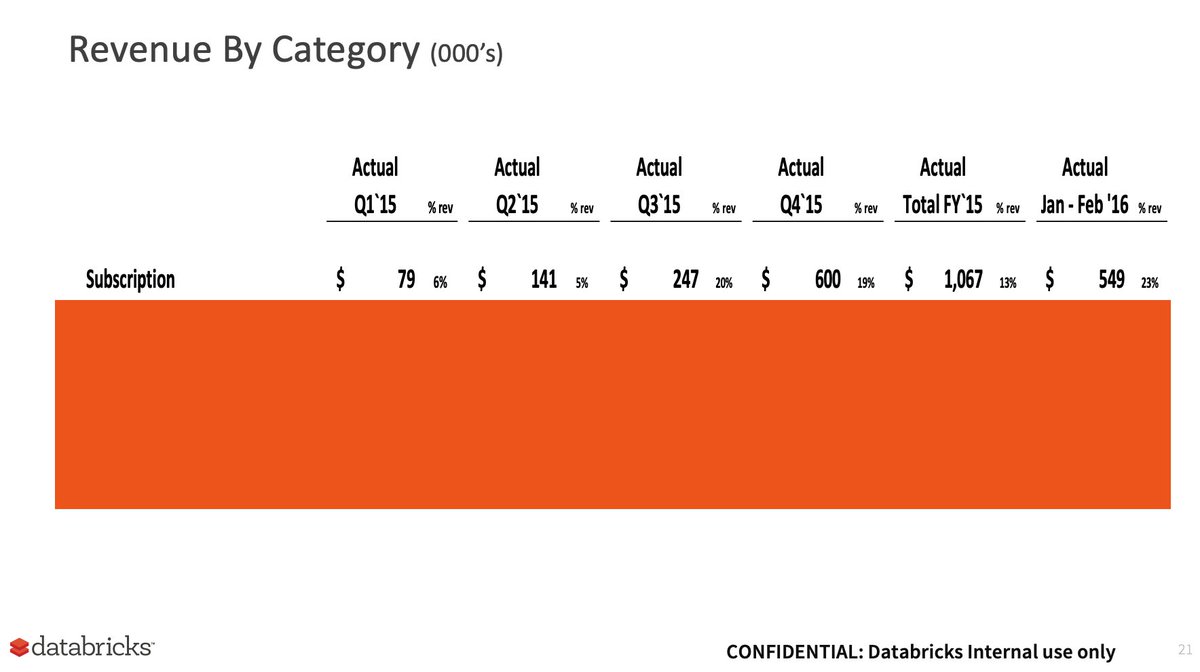
Mar 2
Exactly 10 years ago (Jan 2016), I stepped in as CEO. We had just closed out Q4 with a total of $600k in revenue (screenshot from board deck).
Fast forward a decade.
Q4 audited GAAP Revenue: $1,290M and over $5.4B revenue run-rate ending January.
I’ve never tweeted our exact quarterly financials before, but seeing that $1.29B number cross my desk on my 10-year anniversary hit differently. To the team that built this: thank you. If you're following the data space, you know exactly what this milestone means. 🏗️
52
56
960
190,440
Feb 17
Instead of configuring the Cursor agent from scratch, you can now install the Databricks plugin once and use it to build custom applications that query production data.

3
4
47
3,999
Reynold Xin retweeted
Feb 9
I now constantly get questions about the SAAS meltdown, role of AI, system of records etc. I don't have an answer to all these.
But I do know that we saw an acceleration in our business in Q2, Q3, and now finished the year with accelerating Q4.
The question is, why?
Short answer: AI. But the underlying reason is subtle. We are growing fast because we are finally removing the biggest bottleneck in data: the technical barrier to entry.
For years, if you didn’t know SQL, Python, you were locked out of the value chain. That has changed fundamentally with the 𝐆𝐞𝐧𝐢𝐞 𝐟𝐚𝐦𝐢𝐥𝐲, and it is the "secret sauce" behind our recent momentum:
• 𝐆𝐞𝐧𝐢𝐞: Analysts can query data without any SQL. I use this every day myself.
• 𝐃𝐚𝐭𝐚 𝐒𝐜𝐢𝐞𝐧𝐜𝐞 𝐆𝐞𝐧𝐢𝐞: Builds end-to-end AI models for you, similar to Cursor for ML on your data.
• 𝐃𝐚𝐭𝐚 𝐄𝐧𝐠𝐢𝐧𝐞𝐞𝐫 𝐆𝐞𝐧𝐢𝐞: Write Spark pipelines, does plumbing, troubleshooting.
We've been talking about DATA AI democratization, but generative AI finally enabled it in a way that wasn't possible before. That's why we're seeing a market response.
Take 𝐋𝐚𝐤𝐞𝐛𝐚𝐬𝐞 𝐏𝐨𝐬𝐭𝐠𝐫𝐞𝐬. We launched this serverless engine for agents and apps recently. At 8 months into its journey, its revenue is already 2x what our Data Warehouse product was at the same stage.
All this taken together, we ended up with the following stats for Q4:
🚀 $5.4B Revenue Run-Rate, growing >65% YoY
🚀 $1.4B AI Revenue Run-Rate
🚀 FCF Positive for the year
🚀 NRR >>140%
databricks.com/company/newsr…
60
119
972
505,826
Reynold Xin retweeted

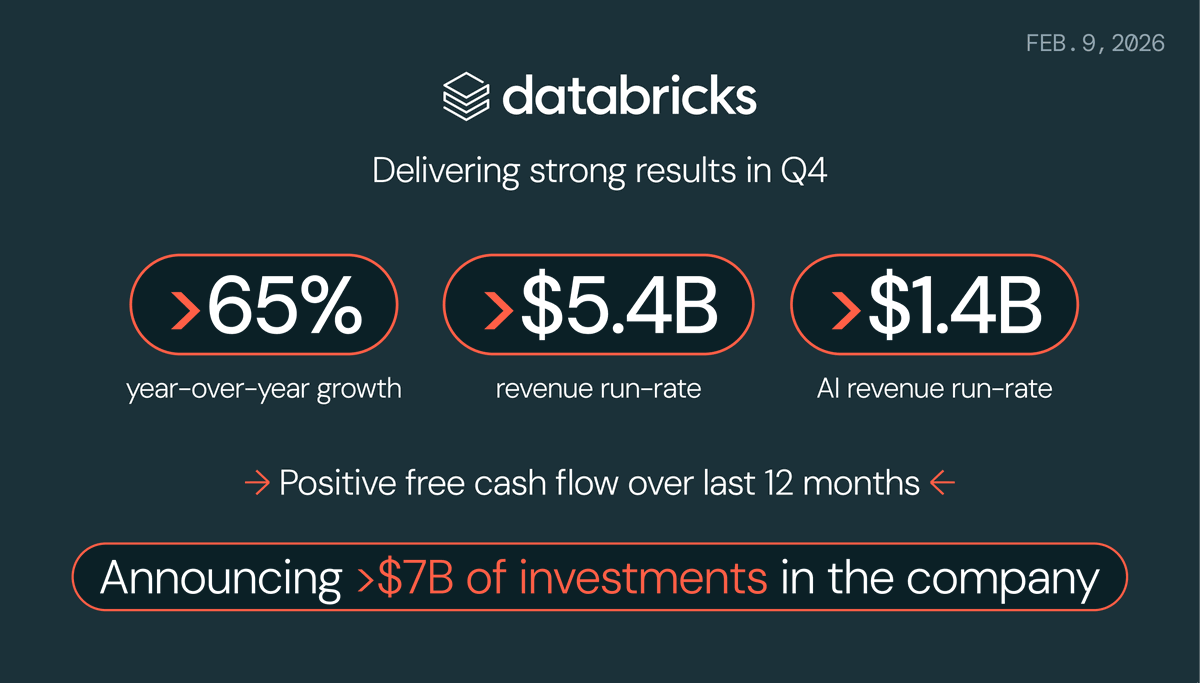
Feb 9
Today we announced Databricks Q4 results:
* Surpassing $5.4B revenue run-rate, growing >65% year-over-year
* Delivering positive free cash flow over the last 12 months
* Crossing $1.4 billion revenue run-rate for our AI products
Databricks is also completing investments in the company in excess of $7 billion, including ~$5B of equity financing at a $134 billion valuation and ~$2B of additional debt capacity.
“We’re seeing overwhelming investor interest in our next chapter as we go after two new markets,” said @alighodsi, co-founder and CEO of Databricks.
“With this new capital, we’ll double down on Lakebase so developers can create operational databases built for AI agents. At the same time, we’re investing in Genie to let every employee chat with their data, driving accurate and actionable insights.”
databricks.com/company/newsr…
17
32
287
132,589
Reynold Xin retweeted
Feb 4
AI agents are no longer just writing code. They’re building the data layer itself.
New data shows agents now create 80% of enterprise databases and 97% of dev and test environments. This is evidence of a broader shift in data infrastructure - it needs to evolve to support building intelligent apps at machine-speed iteration.
@nikitabase, VP at Databricks and co-founder of @neondatabase, explains what is driving the move to a new kind of database: “The database is the system of record for AI applications. It’s no longer just a place to store rows; it’s the persistent memory and coordination layer for multi-agent systems.”
More from @Forbes writer @iamVictorDey: forbes.com/sites/victordey/2…

31
64
336
29,890
Reynold Xin retweeted
Lakebase is GA! We think this is going to make it radically simpler and more reliable to work with online databases. You can instantly branch your DB, take snapshots, roll back to a point in time, or create a copy for offline analysis, whether it's humans or AI doing the work.
Feb 3

Operational databases have long relied on tightly coupled compute and storage. This architecture creates resource contention and pushes teams to manage infrastructure rather than build. As applications become more real time and automated, the transactional layer needs to adapt.
Databricks Lakebase is built for that evolution:
• Familiar Postgres semantics for app developers
• Compute separated from durable state
• Operational data running directly on the lakehouse
• Serverless autoscaling (including scale to zero), branching, and recovery to match agent-driven workload
Now generally available: databricks.com/blog/databric…
2
16
61
13,430
Reynold Xin retweeted
Feb 3
Operational databases have long relied on tightly coupled compute and storage. This architecture creates resource contention and pushes teams to manage infrastructure rather than build. As applications become more real time and automated, the transactional layer needs to adapt.
Databricks Lakebase is built for that evolution:
• Familiar Postgres semantics for app developers
• Compute separated from durable state
• Operational data running directly on the lakehouse
• Serverless autoscaling (including scale to zero), branching, and recovery to match agent-driven workload
Now generally available: databricks.com/blog/databric…
3
11
126
18,674