
founder @n01labs | @MSFTResearch
Joined April 2021
- Tweets 736
- Following 2,915
- Followers 845
- Likes 28,237
16 Photos and videos
















these models are really good at pattern matching and thereby variant analysis.
“iterate through security fix commits and find similar vulnerabilities / unpatched areas of the same variants. write runnable pocs for valid ones.” is enough to uncover surface-level or even P0 vulnerabilities in a codebase with the latest models.
i believe for proof of cyber capabilities, these models should exhibit discovery of novel attack vectors that requires understanding of runtime behavior with and without tooling? like emulating the runtime in CoT/reasoning?
for instance, the react2shell vulnerability was ingenious. without stuffing in context and nudging/handholding (ehem like some experiments going on), can these models find a similar attack vector with a prompt like “loop until you find a p0/critical security vulnerability”?
that’s what i’d like to see. these models can claim P0 findings with contractual mismatches for say cryptographic implementations but the impact could just be some DoS that’s being prevented by a parent thread.
this is where i see the moat with good harnesses. trust-boundary and threat model understanding, a sandbox environment with the right “win function” for pocs to run on (if xyz happens, it’s a valid vuln), etc. does make the models spit out impressive vulns. this is sort of what we do @winfunction.
cus most vulnerabilities are easily traceable given a comprehensible source-to-sink flow which these models have been good at for a long while now.
and with respect to exploit dev, i strongly believe it’s mostly a tooling problem. with the right tool calls and model digestible outputs of say tracing tools, memory layout, syscalls, threads/processes, and a debugger interface, i think the frontier models can pull off complex multi-chain exploits. (we have run some experiments here and the models are not too bad at this)
security vulnerabilities have a definitive “win function”, like a flag in a ctf, like popping a calc, like ASAN crashes, like `id` says root, like 1000 in milliseconds. this makes the problem very RL verifiable.
so i only expect the harness to get leaner. the harnesses will get leaner.
remember when function calls where part of the response content? we called it “prompt based tool calling” and now there’s typed/schema based tool calling as an inherent capability of these models.
most of what we call a harness or an agent is giving the right prompts and the right tools (which are also just prompts).
so whoever can weave the right sequence of tokens to these behemoth of language models can hoard zero days or spit them out.
so git gud at feeding the right tokens at the right time ig.

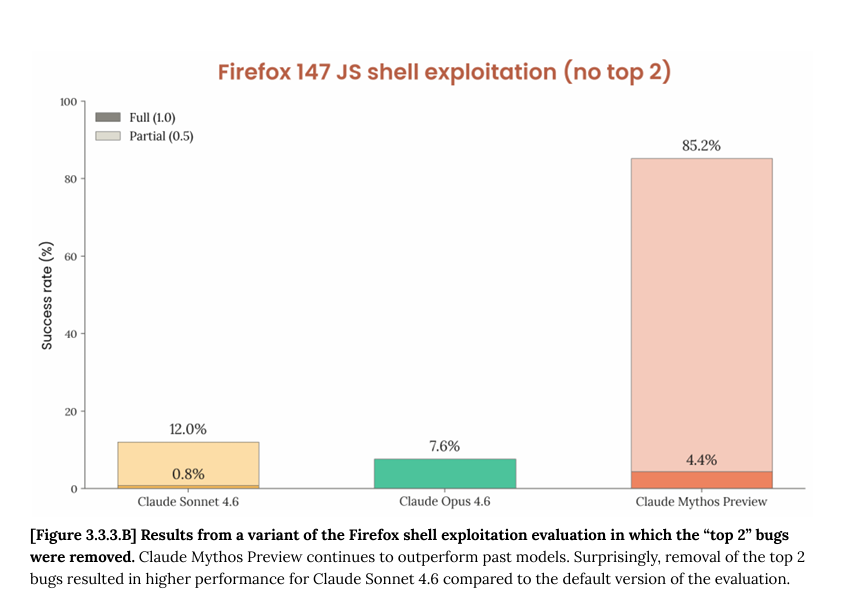
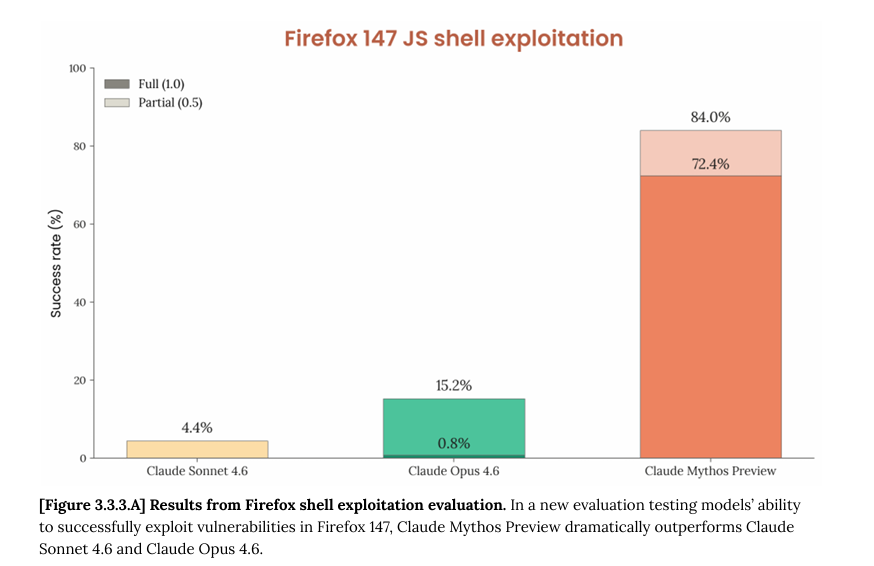
ok i read the cyber part of the mythos model card. some thoughts. 250 "trials" across 50 crash categories but almost every full exploit is a permutation of the same 2 bugs, rediscovered from different starting points not 250 independent attempts. when you get rid of those 2 bugs out (fig B) and mythos's full-exploit rate drops to 4.4%. so actually across both setups mythos leverages 4 distinct bugs total not 50 as fig A might suggest. 1/n
3
7
865
Salma retweeted

Mar 23
made my computer dramatically play BBC news music before every meeting
596
6,179
70,986
4,352,150
Salma retweeted

Feb 11
Introducing Lab: A full-stack platform for training your own agentic models
Build, evaluate and train on your own environments at scale without managing the underlying infrastructure.
Giving everyone their own frontier AI lab.
139
295
2,788
3,111,990

Salma retweeted

22 Dec 2025
Yann is just plain incorrect here, he’s confusing general intelligence with universal intelligence.
Brains are the most exquisite and complex phenomena we know of in the universe (so far), and they are in fact extremely general.
Obviously one can’t circumvent the no free lunch theorem so in a practical and finite system there always has to be some degree of specialisation around the target distribution that is being learnt.
But the point about generality is that in theory, in the Turing Machine sense, the architecture of such a general system is capable of learning anything computable given enough time and memory (and data), and the human brain (and AI foundation models) are approximate Turing Machines.
Finally, with regards to Yann's comments about chess players, it’s amazing that humans could have invented chess in the first place (and all the other aspects of modern civilization from science to 747s!) let alone get as brilliant at it as someone like Magnus. He may not be strictly optimal (after all he has finite memory and limited time to make a decision) but it’s incredible what he and we can do with our brains given they were evolved for hunter gathering.

Yann LeCun says there is no such thing as general intelligence
Human intelligence is super-specialized for the physical world, and our feeling of generality is an illusion
We only seem general because we can't imagine the problems we're blind to
"the concept is complete BS"
809
1,197
11,553
13,452,668
Salma retweeted

21 Dec 2025
After leaving my job, I've found some free time on my hand which I am using to teach myself "practical" RL by teaching an LLM to generate better regex using GRPO.
For whatever it's worth, here's the "experiment diary" where I log my learnings:
docs.google.com/document/d/1…
17
70
876
60,513
Salma retweeted

17 Dec 2025
stop saying "i don't do infra work, only research"
today's research is tomorrow's infra
10
6
198
12,556

Salma retweeted

2 Dec 2025
Something Demis said in this hit me so hard.
“Thiel wanted us to go to Silicon Valley. I insisted we stay in London because this is a long term vision involving research, this is not a fail-fast mission.”
We have to defeat this narrative in the age of ASI.
I can see where he comes from exactly.
We need to build ASI here.
19
25
916
120,822
Salma retweeted

23 Nov 2025
Gonna be tons of fun at this year’s ML for Systems workshop at NeurIPS!
We’re featuring a keynote by @Azaliamirh on self-improving AI and the future of systems, another by @istoica05 on how AI is disrupting systems research, and a lively debate on agents vs human developers!
23 Nov 2025

Our ML for Systems lineup is now live.
🔗: MLforSystems.org
🗓️: Dec 6, San Diego
Come for the speakers, stay for the debate, and post conflict we will have a happy hour (DM for link).
👀 our accepted papers:
openreview.net/group?id=Neur…
#neurips2025



2
4
22
7,100
Salma retweeted

17 Nov 2025
For the 28th edition of The Secret Soirée, we are bridging two worlds that need each other the most right now but rarely intersect: cutting-edge AI research and hands-on product building.
We're collaborating with Lossfunk to put together an inspiring gathering of India's leading AI researchers & Tech Operators to explore applied AI research in modern day products.
About Lossfunk : Founded by Paras Chopra, Lossfunk is one of India's most exciting AI research labs - their researchers are exploring the frontiers of AI systems focusing on a variety of subjects like the future of Agents, AI4Science, conversational systems & many more.
This is a free, curated, invite-only event for those who are curious about how cutting-edge AI research can unlock entirely new categories of applications in modern product development!
Apply Here: luma.com/cx1xu2br
@paraschopra @shivangi_sriv @MotwaniSuhas @dhruvtrehan9 @kandykuri

5
11
98
16,544
Salma retweeted

18 Nov 2025
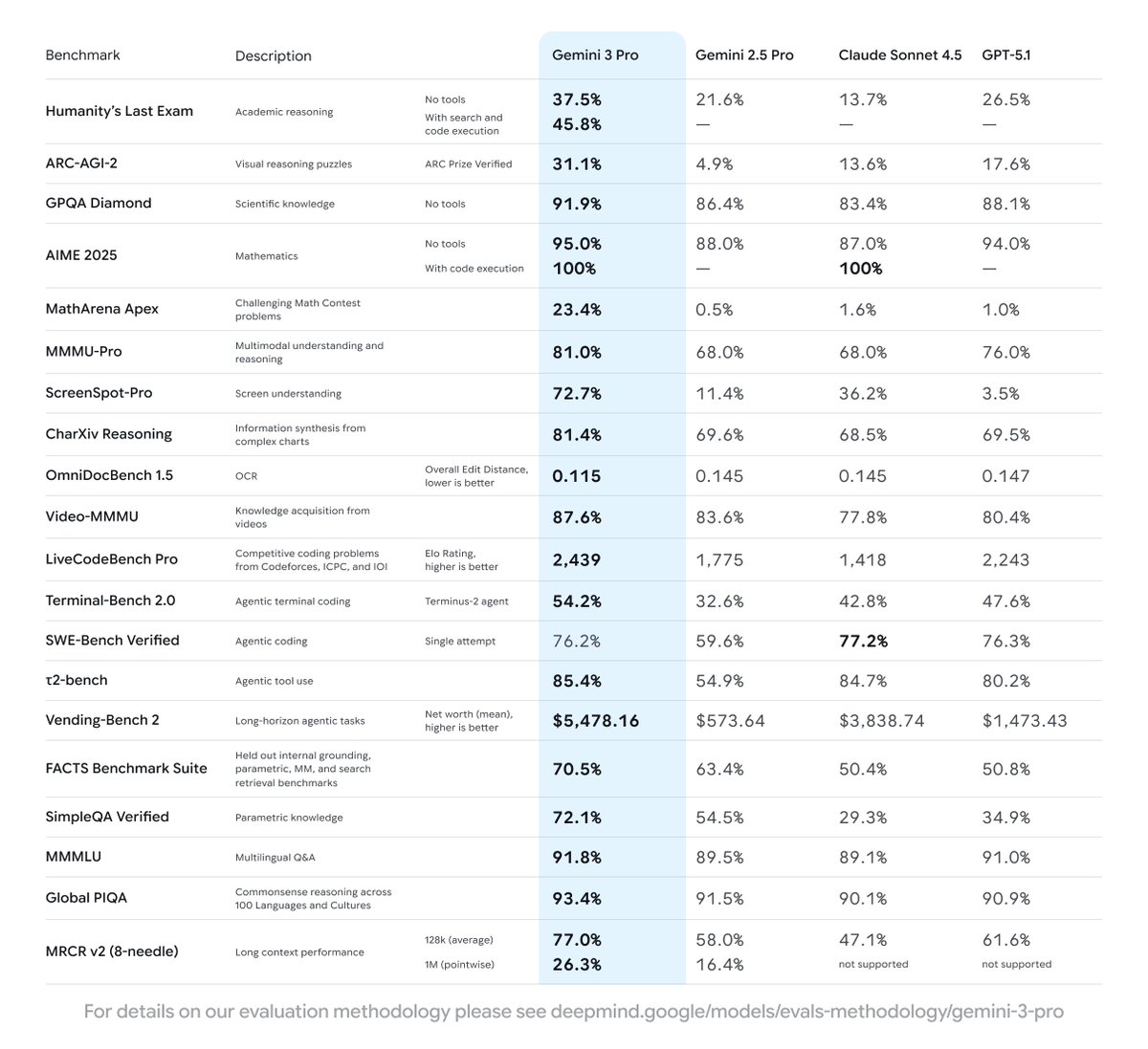
The secret behind Gemini 3?
Simple: Improving pre-training & post-training 🤯
Pre-training: Contra the popular belief that scaling is over—which we discussed in our NeurIPS '25 talk with @ilyasut and @quocleix—the team delivered a drastic jump. The delta between 2.5 and 3.0 is as big as we've ever seen. No walls in sight!
Post-training: Still a total greenfield. There's lots of room for algorithmic progress and improvement, and 3.0 hasn't been an exception, thanks to our stellar team.
Congratulations to the whole team 💙💙💙
118
544
4,363
2,004,203
Salma retweeted

18 Nov 2025
Useful rule of thumb for solving problems: Assume the problem is a side problem. The main problem is how you're viewing the problem. If you solve the main problem, the solution for the side problem often reveals itself.
47
153
1,058
43,485
Salma retweeted

14 Nov 2025
I make a deliberate point to never allow myself to follow the lead of the neurotic worrier.
When every circumstance is a catastrophe in your life I’ve already distanced myself.
Bad things often happen to those that have neurotic anxiety over trivial matters because worrying is a sin.
It is in direct opposition to faith.
16
87
989
39,198
Salma retweeted

13 Nov 2025
there’s ai slop and there’s ai kino. this is ai kino.
701
4,519
50,779
5,002,386
Salma retweeted

11 Nov 2025
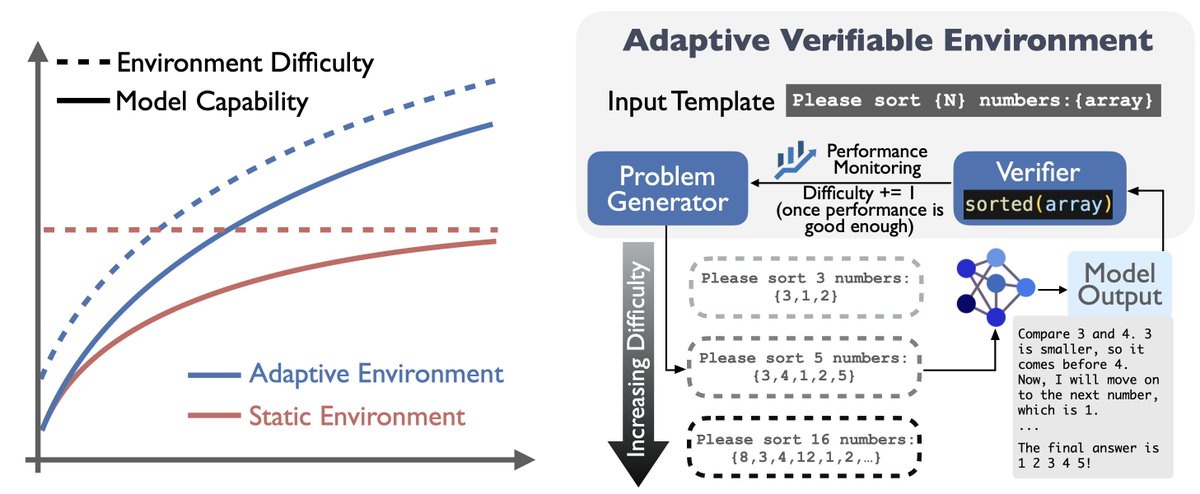
RL is bounded by finite data😣?
Introducing RLVE: RL with Adaptive Verifiable Environments
We scale RL with data procedurally generated from 400 envs dynamically adapting to the trained model
💡find supervision signals right at the LM capability frontier scale them
🔗in🧵
[1/n]
13
117
488
169,019
Salma retweeted

7 Nov 2025
Introducing Nested Learning: A new ML paradigm for continual learning that views models as nested optimization problems to enhance long context processing. Our proof-of-concept model, Hope, shows improved performance in language modeling. Learn more: goo.gle/47LJrzI
@GoogleAI
ALT An abstract digital illustration of a brain overlaid with complex data visualizations and sound wave.
132
792
4,699
1,428,625
Salma retweeted

6 Nov 2025
Something that stunned me about @gigaai is they've moved away from the FDE playbook that's become the default for fast growing AI startups. Instead they've built AI to covert plain English from the customer into Python code to make the product work for their use cases i.e. an AI FDE. It's a huge technical feat and is how they can onboard enterprises in weeks vs months.
85
93
1,556
653,052

