
35 Photos and videos









Samet Oymak retweeted

Apr 29
Fed Chair Powell: I'm literally staying because of the actions that have been taken. I had long planned to be retiring. The things that have happened in the last 3 months have left me no choice but to stay until I see them through
399
4,633
23,703
583,327
Samet Oymak retweeted

The highest quality video of the moon was just released… this is so beautiful.
5,207
64,700
331,371
11,347,296
Samet Oymak retweeted

Mar 31
Today I feel very proud and am honored to introduce PrismML.
This company grew out of years of research at Caltech and a simple conviction: the future of AI will not be defined only by ever-growing models. It will be defined by intelligence density - how much useful intelligence we can deliver per unit of compute, memory, and energy.
At PrismML, we seek to build the most concentrated form of intelligence. Our first proof point is the 1-bit Bonsai family: models that are small, fast, and efficient enough to run locally, while remaining competitive with full-precision models in their class.
We see this not as an endpoint, but as the beginning of a new paradigm for AI, one that expands where intelligence can exist: on-device, at the edge, in the cloud, and in entirely new products and systems.
We are excited to begin sharing that vision.

Today, we are emerging from stealth and launching PrismML, an AI lab with Caltech origins that is centered on building the most concentrated form of intelligence.
At PrismML, we believe that the next major leaps in AI will be driven by order-of-magnitude improvements in intelligence density, not just sheer parameter count.
Our first proof point is the 1-bit Bonsai 8B, a 1-bit weight model that fits into 1.15 GBs of memory and delivers over 10x the intelligence density of its full-precision counterparts. It is 14x smaller, 8x faster, and 5x more energy efficient on edge hardware while remaining competitive with other models in its parameter-class.
We are open-sourcing the model under Apache 2.0 license, along with Bonsai 4B and 1.7B models.
When advanced models become small, fast, and efficient enough to run locally, the design space for AI changes immediately. We believe in a future of on-device agents, real-time robotics, offline intelligence and entirely new products that were previously impossible.
We are excited to share our vision with you and keep working in the future to push the frontier of intelligence to the edge.

36
23
421
37,108
Samet Oymak retweeted

Feb 27
I was fired from Block today. I was the PM in charge of changing the default tip option on the Square terminal to start at 40%.
Jack replaced me with an AI agent that decides which tip amount to show based on your age, weight, and race.
If anyone is hiring product managers, please let me know!
212
209
5,489
998,285

Feb 26
Fantastic job by @DimitrisPapail! Two hypotheses:
- Harder benchmarks likely have high variance and tricky to predict (like many models achieve near zero).
- Expensive benchmarks with more problems may be more predictable due to finer difficulty granularity (so scaling laws show up).
This makes IMO 2025 hardest to predict as actually observed :)

1
5
1,232
Samet Oymak retweeted

Jan 28
Our paper "SmartChunk Retrieval: Query-Aware Chunk Compression with Planning for Efficient Document RAG" is accepted at #ICLR2026 🎉
Static chunks fail for long docs,Let the model decide. We make chunking a reasoning problem, introducing STITCH, a new RL↔SFT post-training loop

2
2
5
1,001

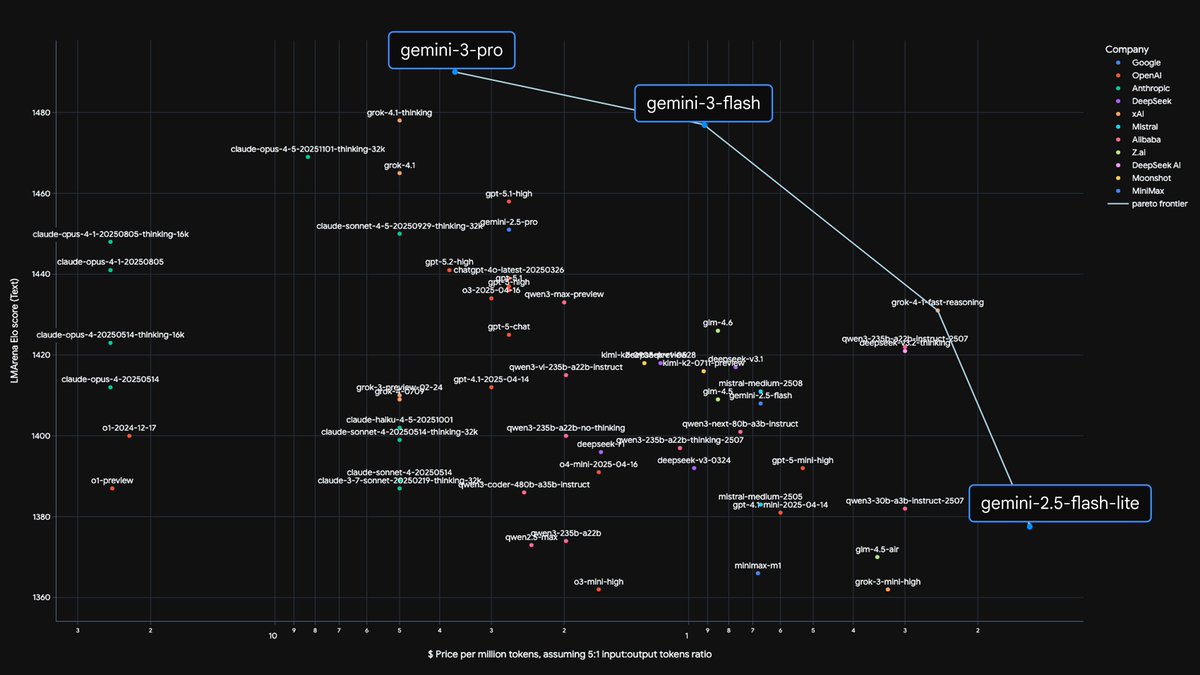
We’ve pushed out the Pareto frontier of efficiency vs. intelligence again.
With Gemini 3 Flash ⚡️, we are seeing reasoning capabilities previously reserved for our largest models, now running at Flash-level latency. This opens up entirely new categories of near real-time applications that require complex thought.
It’s available in the API, and rolling out today as the default model in AI Mode in Search and Gemini app globally.
Read more on the blog at: bit.ly/4pTo5YU
More in thread ⬇️
52
193
1,788
159,543
Samet Oymak retweeted

3 Dec 2025
All of reinforcement learning in 809 words. argmin.net/p/defining-reinfo…
2
16
187
19,572
I’m really excited about our release of Gemini 3 today, the result of hard work by many, many people in the Gemini team and all across Google! 🎊
We’ve built many exciting new product experiences with it, as you’ll see today and in the coming weeks and months.
You can find it today on @GeminiApp and AI Mode in Search. For developers, you can build with it now in @GoogleAIStudio and Vertex AI.
blog.google/products/gemini/…
The model performs quite well on a wide range of benchmarks.
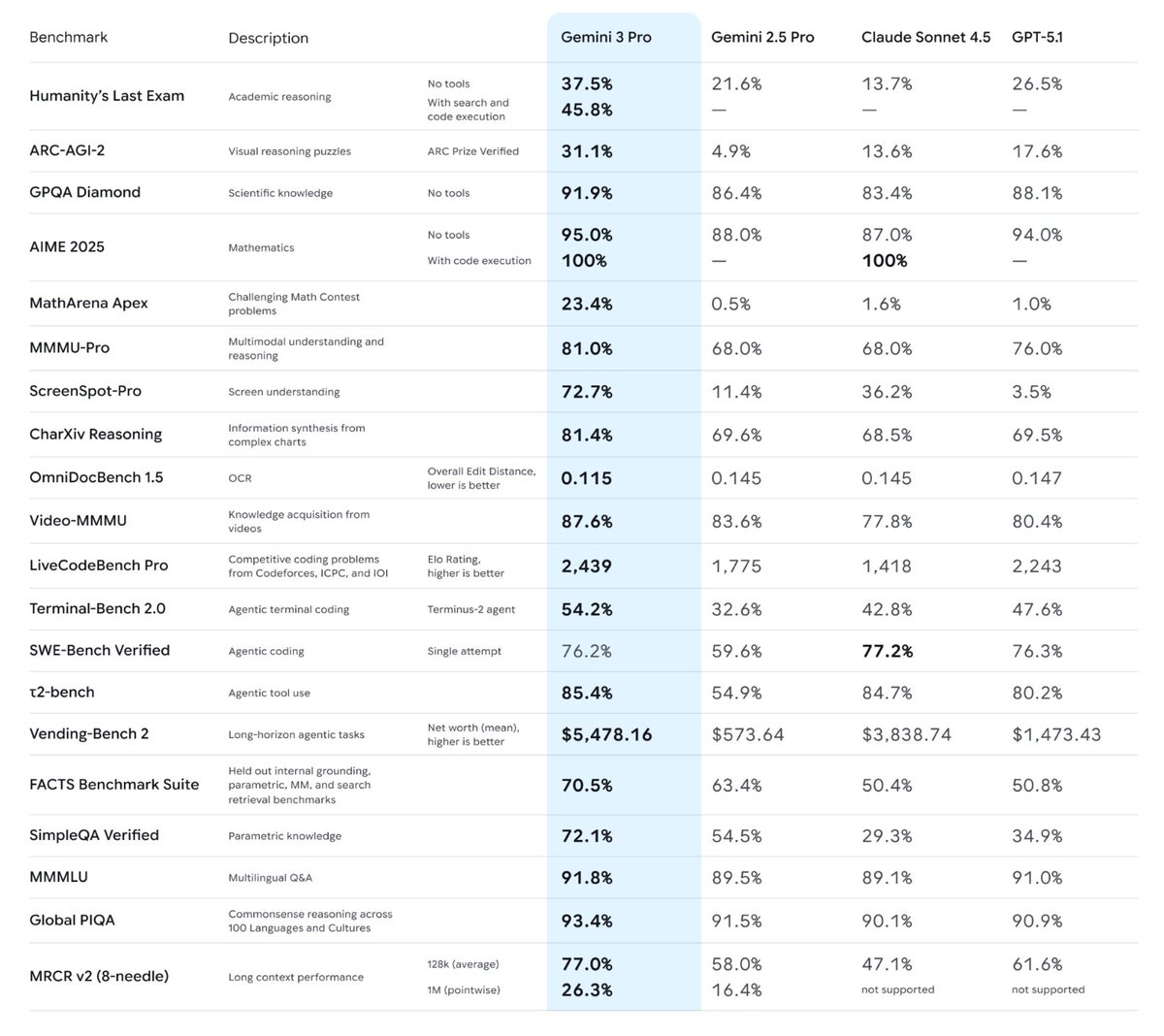
205
340
3,422
399,244
Samet Oymak retweeted

13 Nov 2025
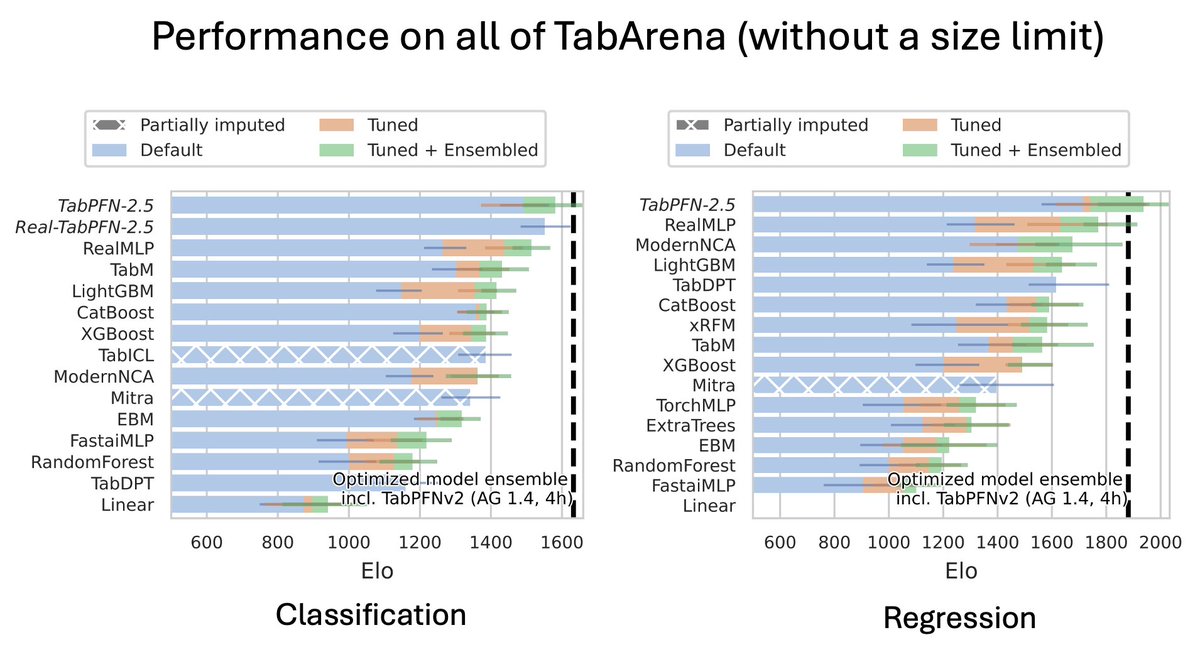
Update: TabPFN-2.5 is actually the SOTA model on all of TabArena (which has datasets with up to 100k training data points).
In a single forward pass, TabPFN-2.5 outperforms all other models, even if you tune them for 4 hours.
We built and previously evaluated TabPFN-2.5 for up to 50k data points (and 2k features) and were kind of surprised that it's SOTA up to 100k 🙂
👉 TabPFN-2.5 webinar tomorrow: app.livestorm.co/p/21526e44-…
👉 Model report on arXiv: arxiv.org/pdf/2511.08667
7
73
5,764
Samet Oymak retweeted
10 Nov 2025
The arXiv position paper controversy and the weird, unwritten, organic evolution of academic practice. argmin.net/p/a-position-on-p…
3
3
30
4,618
Samet Oymak retweeted

6 Nov 2025
(1) Our team at @GoogleDeepMind has been collaborating with Terence Tao and Javier Gómez-Serrano to use our AI agents (AlphaEvolve, AlphaProof, & Gemini Deep Think) for advancing Maths research. They find that AlphaEvolve can help discover new results across a range of problems.
25
179
1,810
148,805
1 Nov 2025
Much needed step from arXiv for quality control and preventing blog post & survey dumping: blog.arxiv.org/2025/10/31/at…
1
1
16
2,543
Samet Oymak retweeted

22 Oct 2025
Learning is the derivative of knowledge.
90
134
1,593
109,769
20 Oct 2025
This paper plane outside my office has been there since I joined U of M in 2023. Considering nominating it for tenure.
2
1
76
7,092
Samet Oymak retweeted

4 Oct 2025
Honest question. What "scaling laws" theory papers that are not a variation on 1980s nonparametric statistics?
6
9
134
16,092
19 Sep 2025
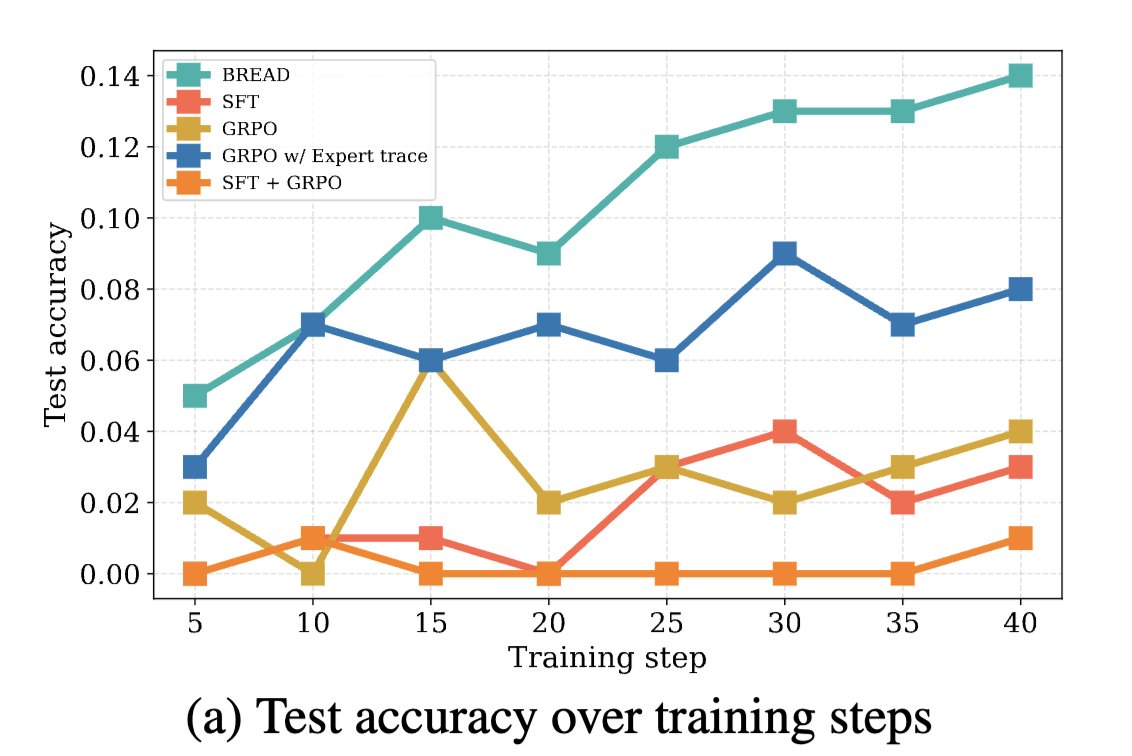
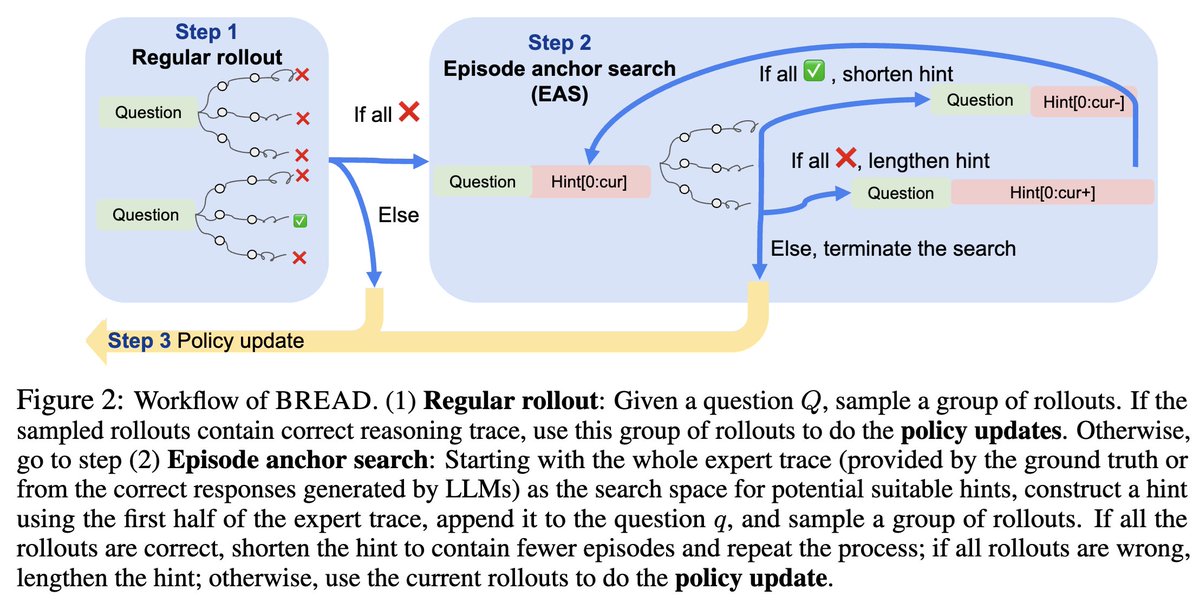
Our paper BREAD is accepted to #NeurIPS2025. BREAD can (provably) solve problems that are not solvable with standard SFT->GRPO training by interpolating between them: arxiv.org/pdf/2506.17211
Congrats to the lead authors @xuechen_zhang (on the job market!) and @HuangJ42673.
2
19
159
8,532
Samet Oymak retweeted

18 Sep 2025
Congrats to @jackcai1206 and @nayoung_nylee for their NeurIPS Spotlight on "Extrapolation by Association: Length Generalization Transfer In Transformers" :)
4 Aug 2025
Excited about our new work:
Language models develop computational circuits that are reusable AND TRANSFER across tasks.
Over a year ago, I tested GPT-4 on 200 digit addition, and the model managed to do it (without CoT!). Someone from OpenAI even clarified they NEVER trained GPT-4 explicitly on 200-digit arithmetic. (can't find the tweet :( )
How?? It felt like magic. In controlled arithmetic tests on transformers, length generalization consistently failed. There must be something magic about pretraining?
Turns out there's a clean, simple, and plausible answer: Transfer.
Here is what we find with Jack @jackcai1206 Nayoung @nayoung_nylee, Avi @A_v_i__S, and my friend Samet @SametOymac:
Language models develop computational circuits that TRANSFER length generalization across related tasks.arxiv.org/abs/2506.09251
A "main" task (like addition) trained on short sequences inherits length capabilities from an "auxiliary" task (like carry prediction) trained on longer sequences, if the model is co-trained on BOTH.
This happens even when we train from scratch on only task A and B. But it only happens when A and B are related.
So, length TRANSFERS between tasks, when they are similar. I think this is very cool!
We tested this across three types of tasks:
- arithmetic (reverse addition, carry operations)
- string manipulation (copying, case flipping)
- maze solving (DFS, shortest path).
Same pattern!
We also find that language pretraining acts as implicit auxiliary training. Finetuning checkpoints at different pretraining stages shows that more pretraining => better length generalization on downstream synthetic tasks.
After ~3 years studying length generalization, much of the initial magic has dissipated. And that's great! This is what science does. It lifts the veil of ignorance :)


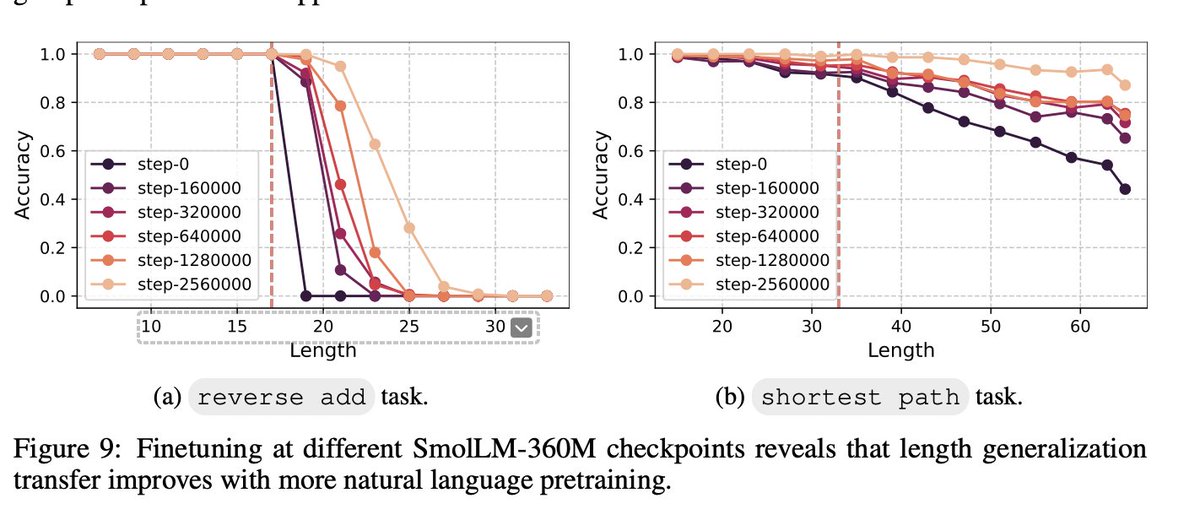

4
20
113
11,355