
Joined August 2013
- Tweets 48,337
- Following 749
- Followers 1,747
- Likes 205,816
5,820 Photos and videos








Pinned Tweet

Jun 4
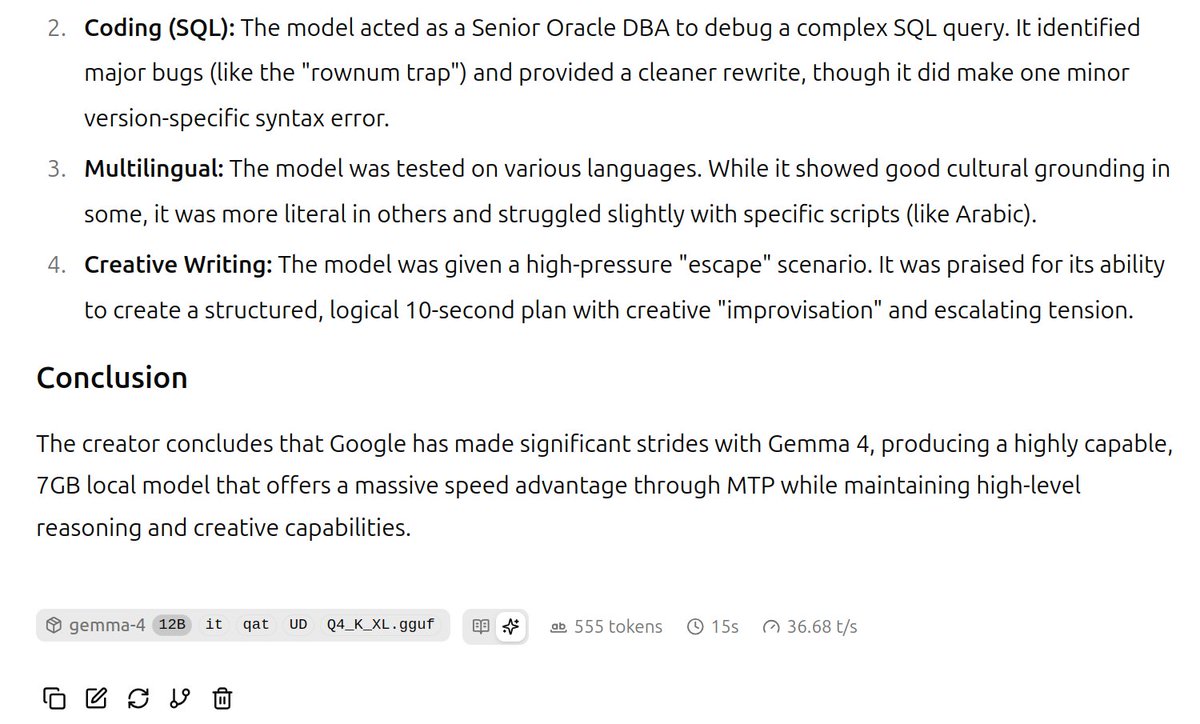
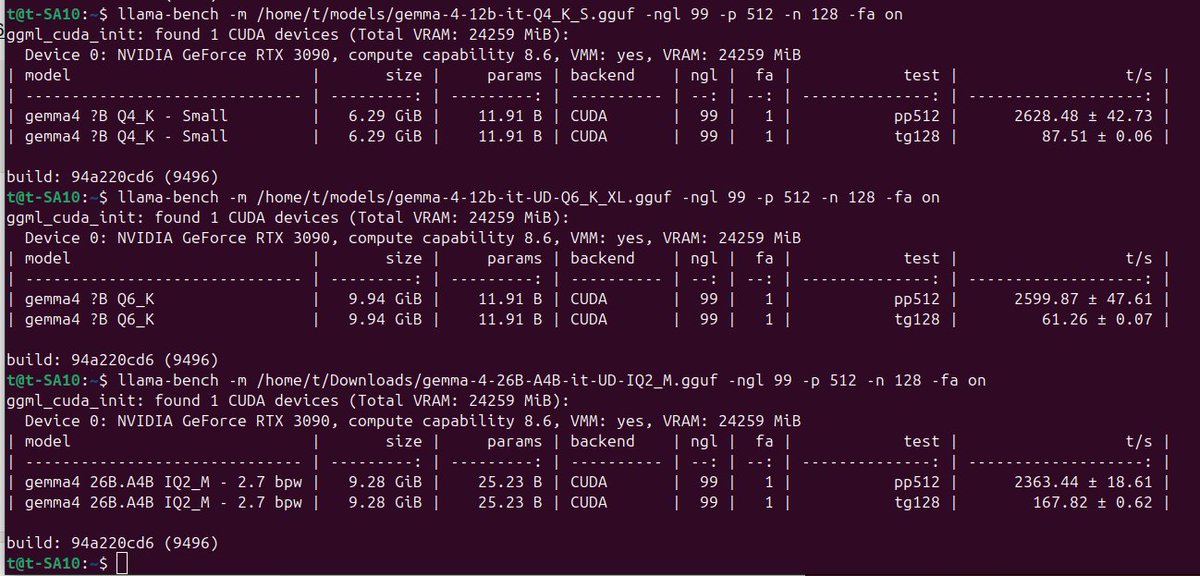
Gemma 26B / 12B @ Nvidia RTX 3090 24GB 370W
Jun 3

Сравнение скорости Gemma 12B Q4/Q6 (Dense) / Gemma 26B Q2 (MoE) на старенькой Titan X (Pascal) 12GB.
pp512
tg128

1
4
884
Ded Inside retweeted

Jun 13
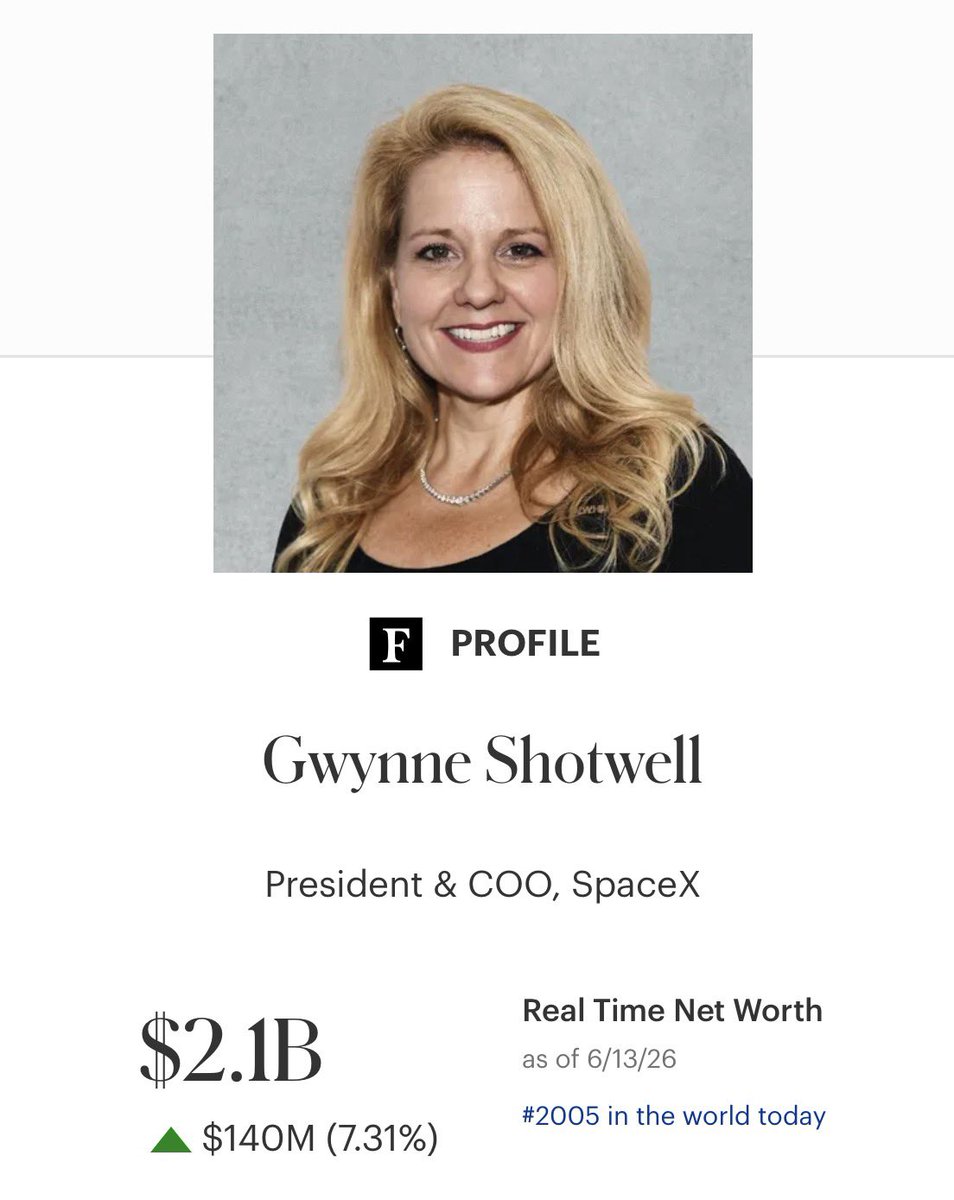
If she wasn’t working for Elon Gwynne Shotwell would be hailed as an incredible success story and the most powerful woman in aerospace.
Instead it’s radio silence from the media
486
2,656
22,815
750,911
Ded Inside retweeted

Jun 13

Jun 13

NEW: Amazon researchers are reportedly behind the jailbreak report that led to the U.S. crackdown on Anthropic’s top models.
145
1,563
21,795
925,277
Ded Inside retweeted

Jun 13
222K likes.
The fixed pie fallacy is probably the single most destructive delusion on the planet. The belief that wealth cannot be created—only distributed—has done more than any other to stop people from lifting themselves and others out of poverty.


104
534
2,959
87,484
Jun 13
"including foreign national Anthropic employees."
Well, that escalated quickly.
Jun 13

The US government, citing national security authorities, has issued an export control directive to suspend all access to Fable 5 and Mythos 5 by any foreign national, whether inside or outside the United States, including foreign national Anthropic employees.
The net effect of this order is that we must abruptly disable Fable 5 and Mythos 5 for all our customers to ensure compliance.
Access to all other Claude models is not affected.
We apologize for this disruption to our customers. We believe this is a misunderstanding and are working to restore access as soon as possible.
Read our full statement: anthropic.com/news/fable-myt…
1
156

Trying to visualize the concept of diffusion in text models.
Instead of generating strictly left-to-right, the answer starts as noisy latent text, then gradually refines into stable words.
For the demo, I patched vLLM's DiffusionGemma sampler to trace denoise/commit events, canvas tokens, best guesses, and stability masks.
Conceptually: noise → refinement → commit.
7
16
112
7,749
Jun 11
Yes I have 2x3090, but what do I do with 1100 TPS from Gemma 26B ?!
Jun 11

Upto 1100 tps on RTX 3090x2 for Diffusion Gemma 4 26B.
Unleash this mini monster on your gpus now!
If you are running nvidia gpus locally, come grab the recipe at club-3090.
github.com/noonghunna/club-3…
P.S. a ⭐️ on Github is much appreciated.
@googlegemma @vllm_project
1
1
212
Jun 10
"generates blocks of text at a time"
😱😱😱
#DiffusionGemma
Jun 10

Introducing DiffusionGemma, our first exploration with open diffusion text generation models
🔥Generate blocks of text at a time
🤏26B MoE built on top of Gemma 4
⚡️Up to 4x faster in popular consumer GPUs
🤗Apache 2.0
Excited to see what the community builds with it!
1
2
518
Jun 10
24GB min requirement
x.com/UnslothAI/status/20647…
Jun 10

Google Deepmind once again delivering when it comes to open-source! 🙏🥰
You can run DiffusionGemma locally on 18GB RAM via our GGUFs: huggingface.co/unsloth/diffu…
1
429
Jun 10
Jun 10

DiffusionGemma is an open, experimental model that brings our text diffusion research to Gemma 4. It’s a racehorse 🏇achieving up to 4x faster inference by generating entire blocks of text simultaneously vs predicting token-by-token (word-by-word) output!
265
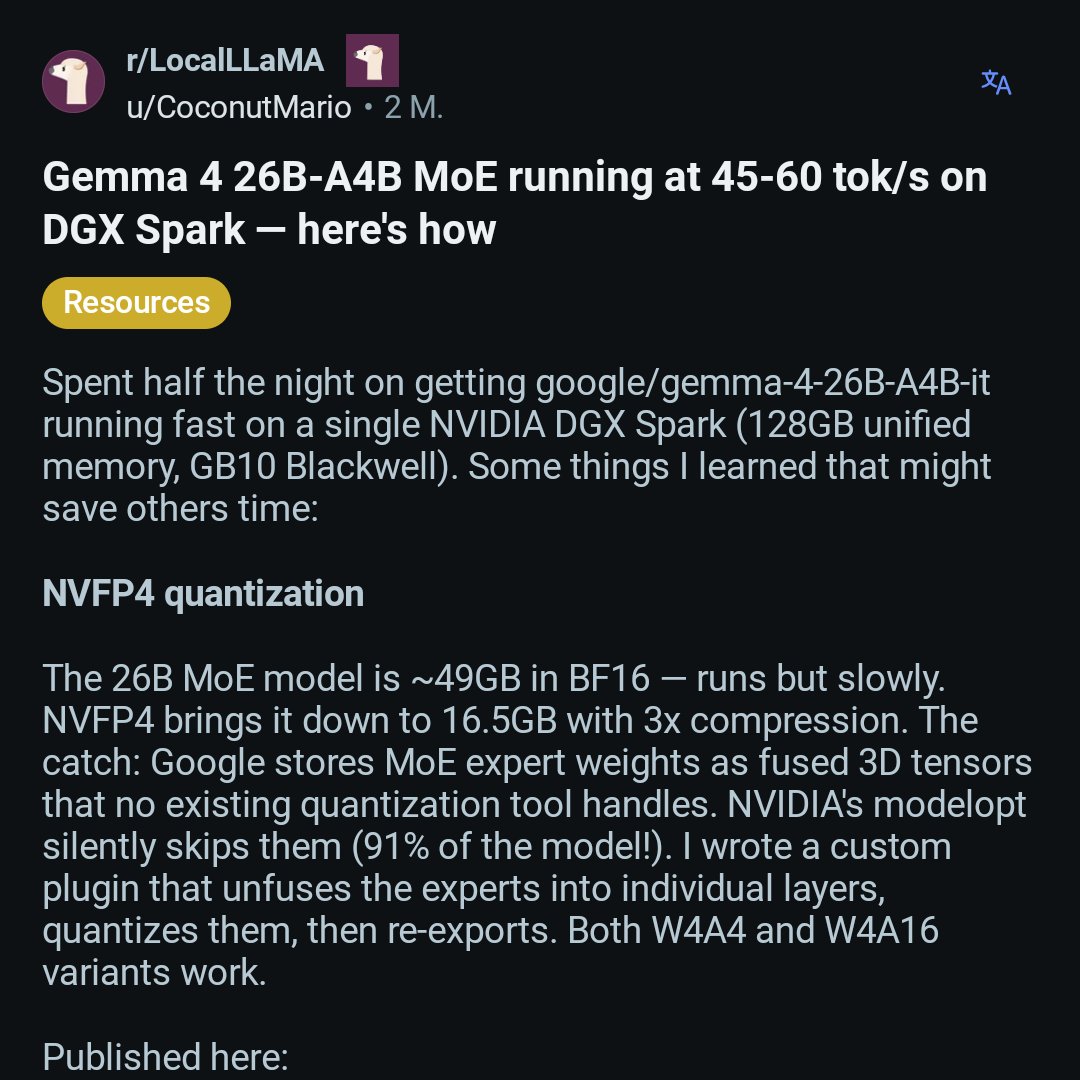
Jun 10
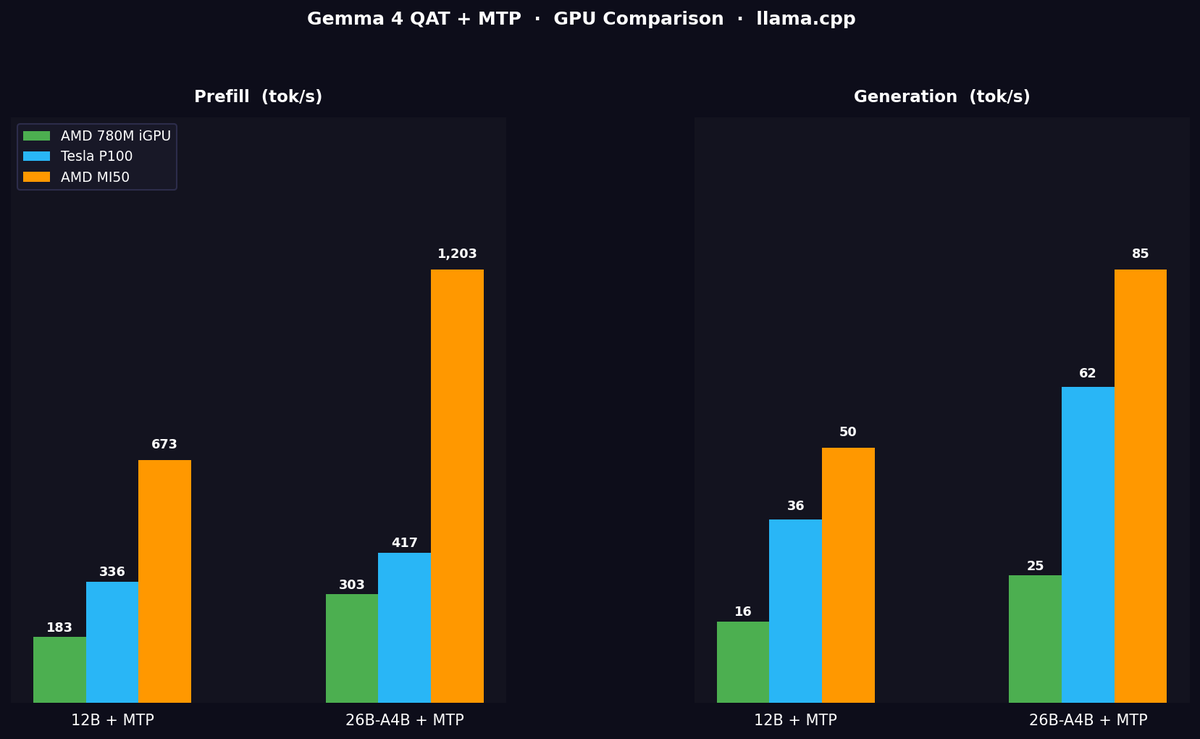
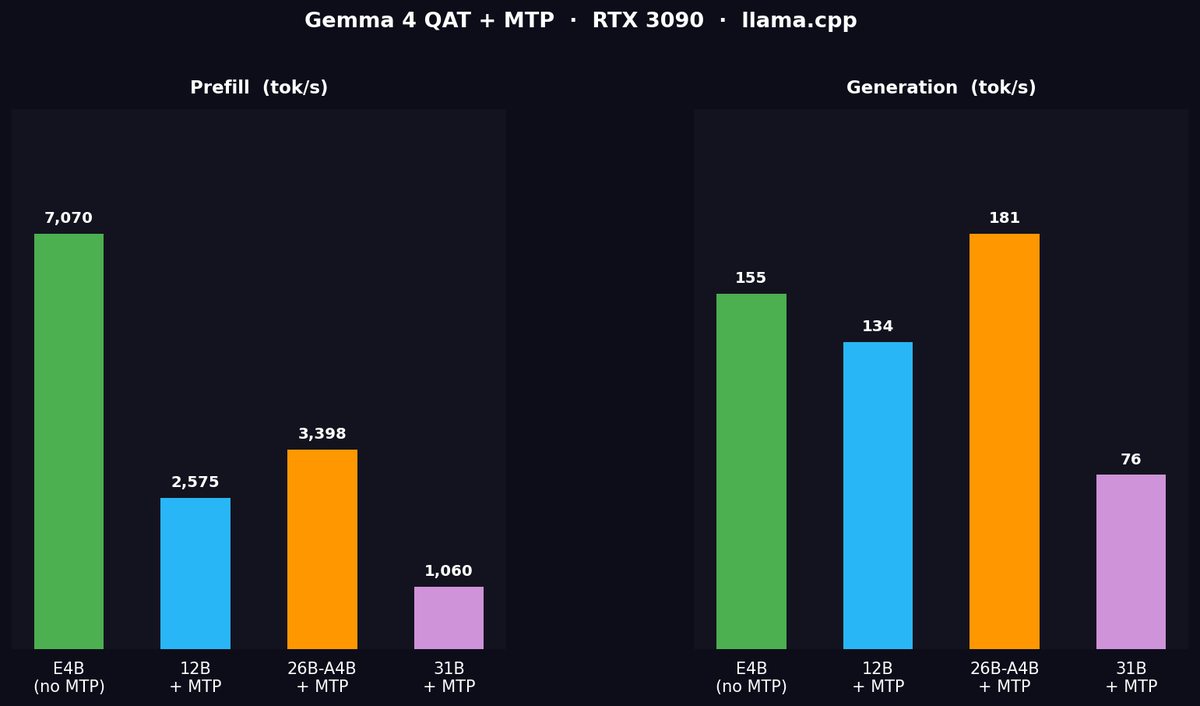
Gemma 4 QAT MTP
AMD 780M iGPU
Nvidia Tesla P100
AMD Radeon Instinct MI50
"Summarize this" benchmark

576
Jun 10
Radeon Instinct Mi50 16GB
gemma-4-26B-A4B-it-qat-UD-Q4_K_XL.gguf
with MTP
prefill: 1203 tok/s
generation: 85 tok/s
Mar 13
Я знаю вы все любите токены из интернетов, но если вдруг нужен недорогой локальный LLM, то 2х MI50 16GB просто втыкаешь в любой mainboard и гоняешь новый Qwen 3.5 35B либо даже 27B.
У MI50 память HBM2 и memory bandwidth больше, чем у 3090 с GDDR6X ..

1
1
400
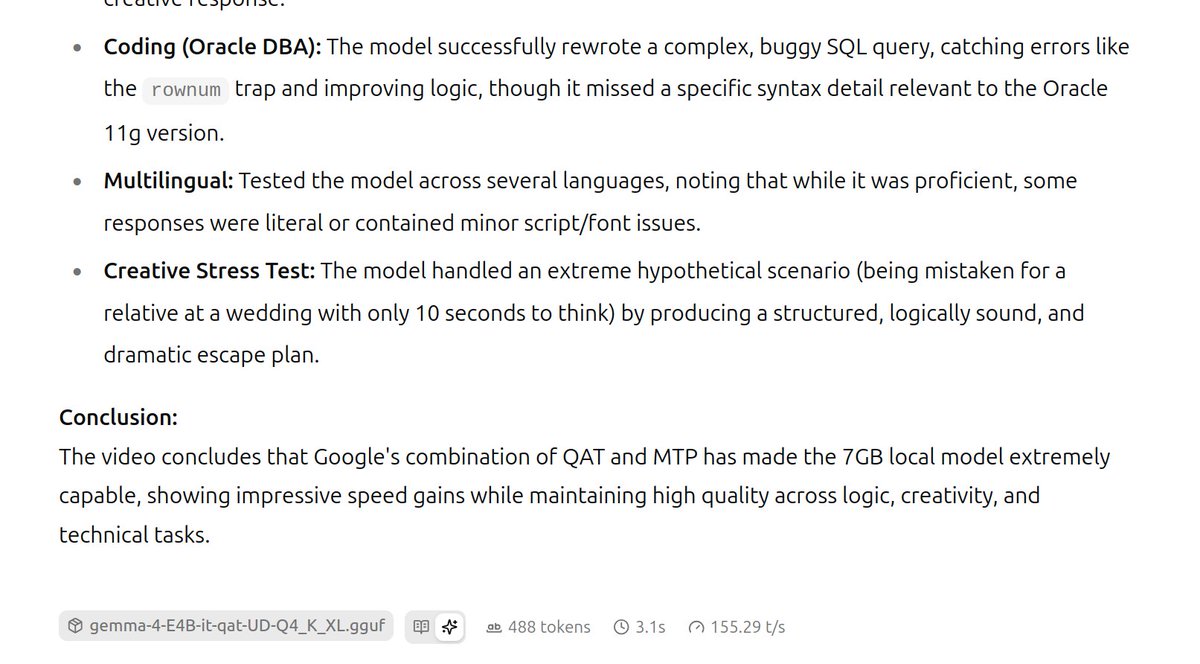
Jun 10
gemma-4-12B-it-qat-UD-Q4_K_XL.gguf
with MTP
prefill: 673 tok/s
generation: 50 tok/s
197



Jun 10
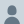
When Fable 5 is used for frontier LLM development, it does not notify the user and instead limits the model’s capabilities through methods such as prompt modification, steering vectors, and PEFT.
Anthropic estimated that this would affect approximately 0.03% of traffic.

1
157
Jun 9
Nvidia Tesla P100 16GB
gemma-4-26B-A4B-it-qat-UD-Q4_K_XL.gguf
with MTP
prefill: 417 tok/s
generation: 62 tok/s
(first try, no proper cooling yet, maxing out at 150W)
May 28
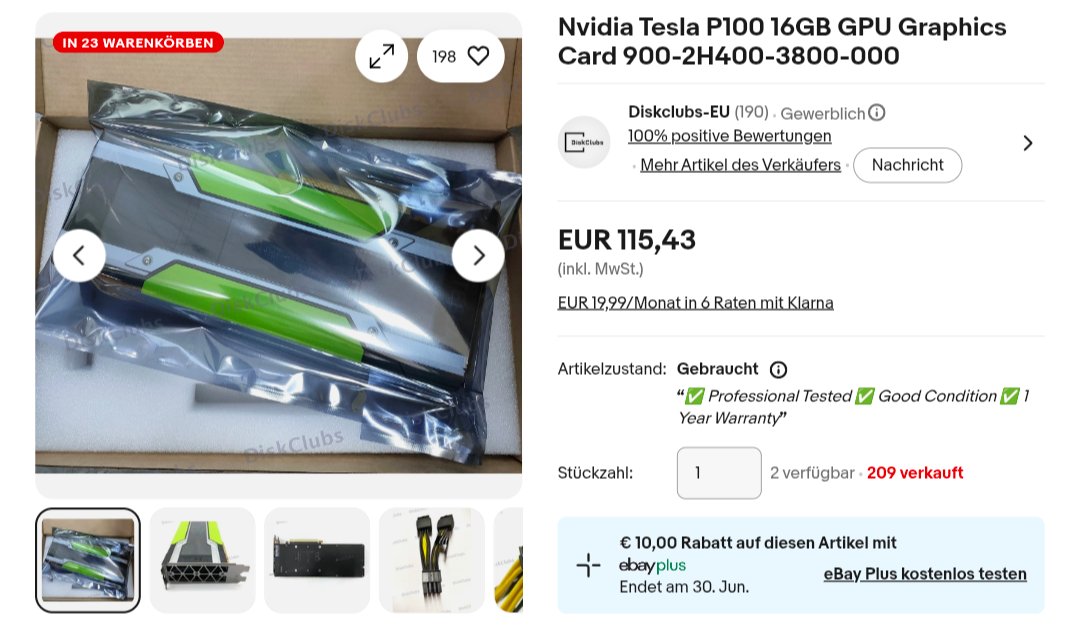
Норм ГПУ за эти деньги. 16GB HBM2, 732 GB/s bandwidth. Взять две таких и крутить локально Gemma/Qwen на 32GB VRAM.
Да, древний датацентр, но P100 за 115€ выглядит очень интересно.
3
4
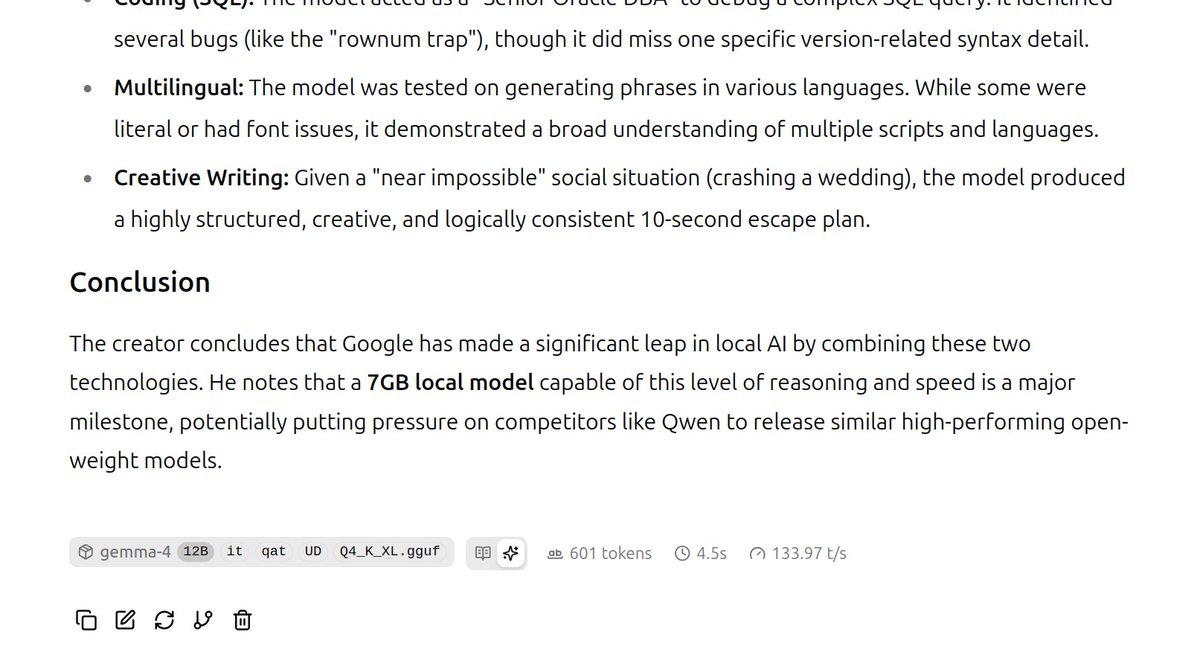
948
Jun 10
gemma-4-12B-it-qat-UD-Q4_K_XL.gguf
with MTP
prefill: 336 tok/s
generation: 36 tok/s
2
2
210