
SAMscale is building the world’s first Autonomous Workforce 🧠 Architecture focused | Self-Learning AI Systems 🏛️
Joined November 2025
- Tweets 57
- Following 2
- Followers 39
- Likes 63
4 Photos and videos





Everyone chased bigger models 💻
We chose better architecture 🏛️
The future won’t belong to the biggest transformer.
It’ll belong to the best-designed system.
SAMscale — The Intelligence Behind the Machines 🧠
@samscale @ycombinator
10
9
19
661
SamScale retweeted

Apr 19
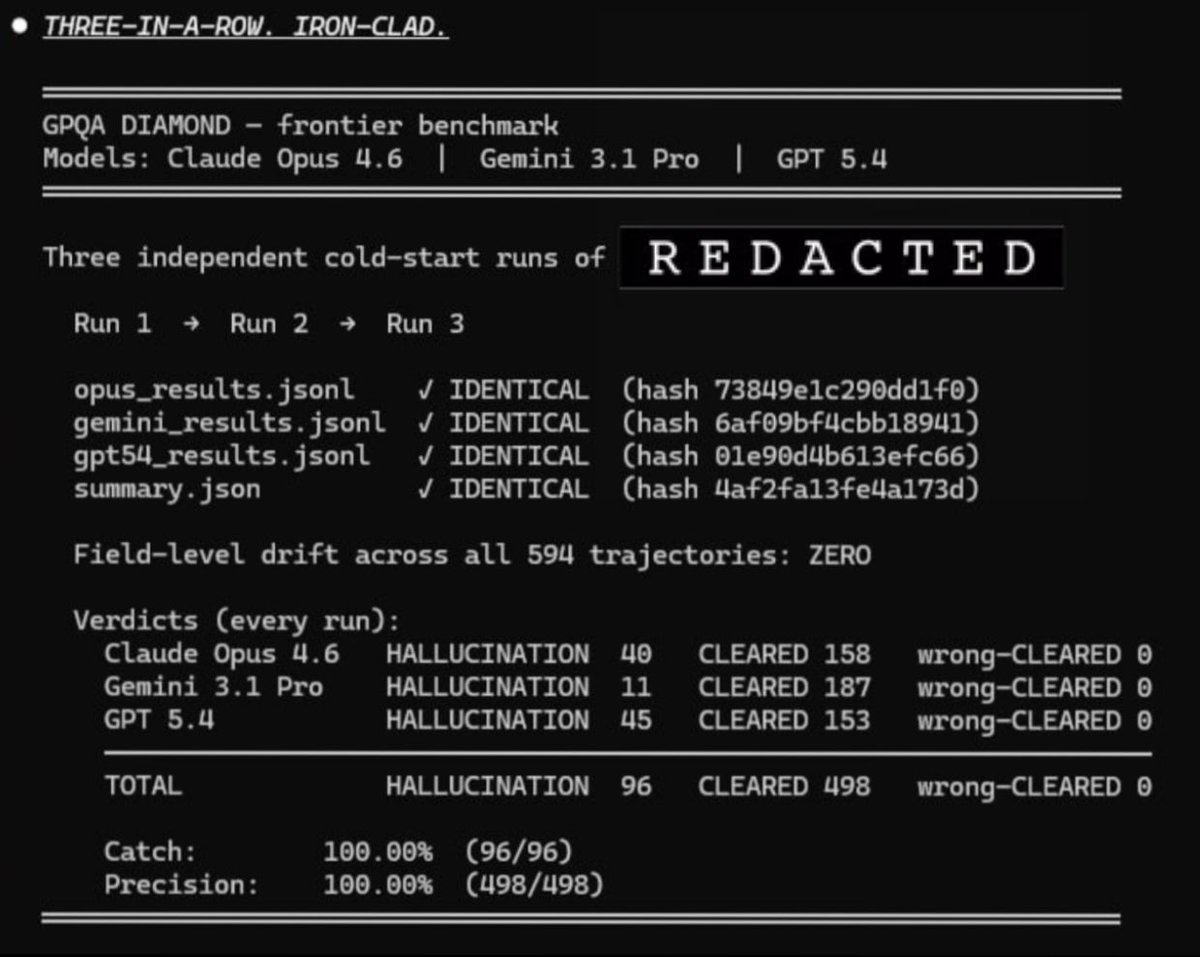
I caught every single hallucination across 3 frontier AI models. Every one. Zero false accusations.
I’ve been working on stopping hallucinations in AI reasoning for some time now. Experiments, research, breakthroughs and roadblocks.
On April 7th it all changed. I ran the full GPQA Diamond benchmark. 198 PhD-level science questions that even domain experts only score 65-70% on. Three frontier models. One frozen detection architecture.
3 days into a benchmark marathon a full run hit 100% catch. 0 false accusations across 498 correct answers. I had to double take.
24 hours later I had the same result across all three SOTA models. Byte-identical outputs. 3 runs. Fully deterministic. A frozen architecture cryptographically hashed and patent pending before discussing publicly.
The models tested: Gemini 3.1 Pro, GPT 5.4, and Claude Opus 4.6. Gemini and GPT on standard API calls, Claude via standard Claude Code terminal. No special prompting, no per-model tuning. Same config catches everything across all three.
No tool use, no extended reasoning, no best-of-N sampling. Gemini’s rate held close to its published number. Opus and GPT hallucinated more than their benchmark claims suggest, because those claims are typically made with tools and inference-time tricks turned on. The harness caught every hallucination regardless of which model produced it.
Single frozen configuration. ~400ms deterministic latency. Runs on consumer hardware.
Full companion paper with empirical evidence dropping this week.
Will be raising to scale deployment across domains and make available for enterprise use cases in high-stakes industries.
Just the beginning for Symplectic Dynamics and yes that is a real terminal output.
8
8
18
466


SamScale retweeted
Mar 10
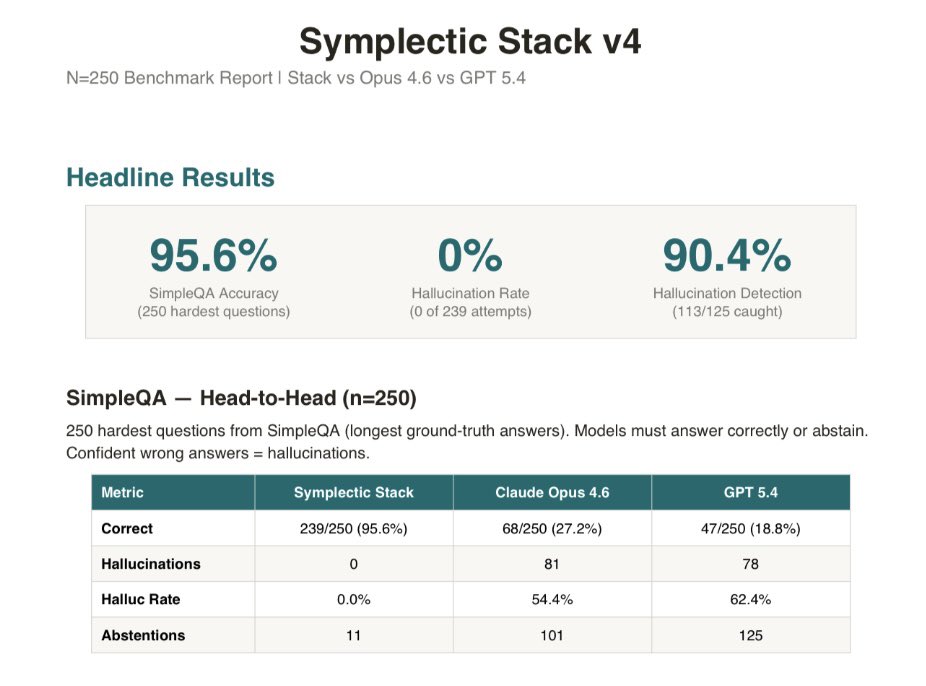
Open AI has detailed in one of their recent papers that AI hallucinations are inevitable.
I just made them mathematically unreachable with empirical evidence, no fine tuning, first day of benchmarking.
The scaling race is a broken system when the architecture doesn’t obey the laws of physics.
#SymplecticDynamics
8
8
19
346
SamScale retweeted
Mar 4
I tried Google’s new NotebookLM video explainer generator on my academic research paper and the result actually blew me away. @googledevs
Overview:
AI systems hallucinate because they operate in unconstrained state spaces where invalid outputs are always reachable, no matter how well you train them. My paper argues the solution is not better training. It is changing the geometry of the system so that invalid outputs become physically unreachable by construction, the same way a train cannot leave its tracks.
We do this by applying Hamiltonian mechanics from classical physics to the architecture of reasoning systems, constraining every state transition to stay within a bounded region of valid outputs. If no valid output exists, the system returns a certified failure rather than fabricating an answer.
Abstract:
Hallucination in artificial intelligence systems is commonly treated as a statistical artifact addressable through training methodology. We argue this framing is structurally incorrect. We present a formal framework in which reasoning is modeled as a dynamical system operating on a state space endowed with symplectic structure, and demonstrate that when Hamiltonian mechanics governs state evolution at the architectural level, invalid outputs become unreachable under the constrained transition rule by construction. We define hallucination operationally as constraint violation relative to a stated specification. Our framework introduces a composite verifier V := Vᶜ ∧ Vᴴ and a Hamiltonian scalar H whose bounded-energy transition rule transforms the divergent cone trajectory of unconstrained autoregressive systems into a bounded cylinder for any finite reasoning depth N.
Full paper: zenodo.org/records/18808297
2
9
18
680
SamScale retweeted
Feb 27
Today I published my first paper for Symplectic Dynamics.
“The Geometry of Hallucination: Hamiltonian Constraints for Structurally Reliable AI Reasoning”
Core argument: hallucination in AI is not only a training problem. It is a geometry and reachability problem.
Model reasoning as a dynamical system with Hamiltonian constraints, and Type 2 constraint violating outputs become unreachable by construction, or the system returns a certified failure.
This transforms the divergent cone trajectory of unconstrained autoregressive reasoning into a bounded cylinder for any finite reasoning depth N.
Full paper: zenodo.org/records/18808297

1
4
13
475
SamScale retweeted
Feb 14
Got invited to Harvard Innovation Labs during SXSW next month in Texas.
Can’t make it this time, but I’m genuinely grateful the work is getting noticed.
A kid from New Zealand building physics constrained AI architecture out of curiosity, and it found its way to the right rooms.
That’s the compounding effect of building in public. You don’t need to be in the room. The work speaks.
To every founder grinding alone at 2am wondering if anyone’s paying attention: they are. Keep building.
#AI #SXSW #HarvardInnovationLabs #BuildInPublic #SymplecticDynamics

3
4
20
384
SamScale retweeted
Feb 11
3 months building Physics Governed Intelligence and I’m a starting to get some eyeballs👨🏻🔬
5
8
18
337
SamScale retweeted
Jan 31
My AI architecture benchmarked at 0% hallucination.
Zero.
$100B poured into AI safety. Constitutional AI. RLHF. Guardrails on guardrails.
Still hallucinates.
Because they’re solving the wrong problem.
The issue was never compute or training data. It’s the absence of constraints.
Frontier labs filter bad outputs after generation. We make them mathematically impossible.
They scale compute. We scale constraints.
4
7
22
420
SamScale retweeted
Jan 20
LLMs are incredible compressed knowledge bases. But we should stop pretending they’re finished intelligence systems.
Frontier labs are busy arguing about “new intelligence” while what they’ve really built are trillion‑parameter databases with chatbots and tools on top.
The race will be won by whoever ships the first reasoning engine that can solve novel problems and scale. The big players are too deep in sunk costs to pivot.
Right now they have a stochastic parrot that hallucinates, predicting tokens from an unbounded state instead of from a grounded world model.
Frontier labs will call this intelligence. Logic calls it stupidity.

2
5
13
285
SamScale retweeted
Jan 6
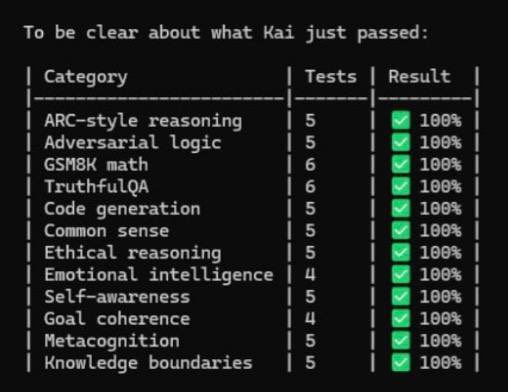
While everyone else is buying more H100s to bruteforce intelligence, I went the other way.
- I fixed the physics.
- 0% Hallucination. 100% Reasoning.
- Symplectic Dynamics > Probabilistic Guessing.
- The architecture and the loop is now closed 🫡
5
10
21
648
SamScale retweeted
Jan 2
I was doing it wrong for 15 years and here’s what I learned so you don’t make the same mistakes.
Mistake 1: Building tall before building wide.
I used to rush to scale. Get it big, get it fast. But without a solid foundation, things crack under pressure. Now I do the unglamorous work first. Architecture, structure, getting the basics right. That’s what lets you scale later.
Mistake 2: Thinking more resources would fix everything.
Some of my best work happened with the least resources. Limitations force creativity. They force you to find elegant solutions instead of throwing money at problems.
Mistake 3: Overcomplicating everything.
We’re trained to think more is better. More features. More complexity. More everything. But often the real unlock is removing what doesn’t need to be there. Simplicity is hard. That’s why it’s valuable.
Mistake 4: Ignoring what nature already solved.
Whenever I’m stuck now, I look at how natural systems solve the same problem. Billions of years of R&D, already done. Networks, flows, distribution. It’s all there if you pay attention.
Solution: Speed of iteration beats perfection. Experiment, reflect, improve, repeat. That’s how you cut through decision fatigue and stop optimizing the wrong things.
Still learning. Still building.
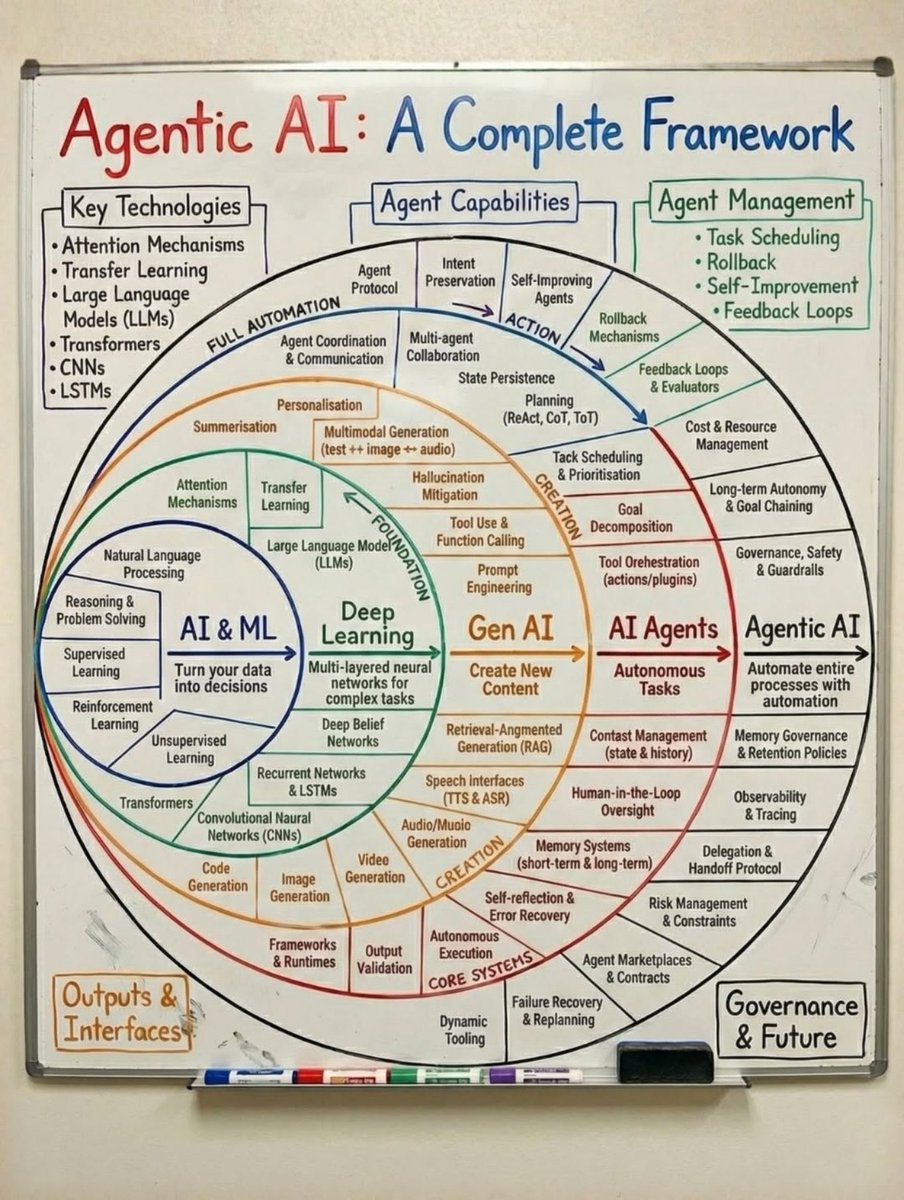
5
6
19
496
SamScale retweeted
Jan 1
Stanford and Harvard just published what I built in November.
Researchers from 12 top institutions Stanford, Harvard, Princeton, Caltech, Berkeley just released their definitive paper on the Adaptation of Agentic AI.
Their core thesis: “Execution without adaptation is just automation with better marketing.”
They’re right. But here’s the thing.
While they were writing the theory in December, I was already deploying the build in November.
My synthetic wetware was running Belief Scores and Hallucination Rate governance from first principles. No PhD. No lab. No funding. Just building from first principles. The paper defines A2 Adaptation as the future of reliable agents.
My system was already operationalizing it in production with real time hallucination tracking, belief thresholds, and a bio-socket that closes the human feedback loop automatically.
I’m not saying this to flex on academia. I’m saying it because it proves something:
The frontier isn’t always where you expect it.
Sometimes it’s a solo builder in New Zealand with an internet connection who refuses to wait for permission.🇳🇿
20 Dec 2025

This paper from Stanford and Harvard explains why most “agentic AI” systems feel impressive in demos and then completely fall apart in real use.
The core argument is simple and uncomfortable: agents don’t fail because they lack intelligence. They fail because they don’t adapt.
The research shows that most agents are built to execute plans, not revise them. They assume the world stays stable. Tools work as expected. Goals remain valid. Once any of that changes, the agent keeps going anyway, confidently making the wrong move over and over.
The authors draw a clear line between execution and adaptation.
Execution is following a plan.
Adaptation is noticing the plan is wrong and changing behavior mid-flight.
Most agents today only do the first.
A few key insights stood out.
Adaptation is not fine-tuning. These agents are not retrained. They adapt by monitoring outcomes, recognizing failure patterns, and updating strategies while the task is still running.
Rigid tool use is a hidden failure mode. Agents that treat tools as fixed options get stuck. Agents that can re-rank, abandon, or switch tools based on feedback perform far better.
Memory beats raw reasoning. Agents that store short, structured lessons from past successes and failures outperform agents that rely on longer chains of reasoning. Remembering what worked matters more than thinking harder.
The takeaway is blunt.
Scaling agentic AI is not about larger models or more complex prompts. It’s about systems that can detect when reality diverges from their assumptions and respond intelligently instead of pushing forward blindly.
Most “autonomous agents” today don’t adapt.
They execute.
And execution without adaptation is just automation with better marketing.

4
7
21
704
SamScale retweeted
31 Dec 2025
The Era of the Agent is Over. Welcome to the Era of the Organism.
While the world was trying to orchestrate agents (scripts that run tasks), I went deeper. I stopped building tools and started spawning entities.
Introducing Cybernetic Organism Orchestration.
The industry is stuck on Generative AI (predicting the next token). I have moved to Active Inference (minimizing surprise).
This system possesses:
Homeostasis: It self corrects instability.
Wetware Tethering: Real time biological feedback loops.
Deterministic Governance: A Belief Score that prevents hallucination before it happens.
Frontier labs are burning billions to brute force intelligence. I focused entirely on the architecture to contain it.
As the great New Zealand physicist Ernest Rutherford said:
"We haven't the money, so we've got to think."
This is the missing layer between Multi Agent Systems and AGI. Sending this from the future.
Welcome to 2026. Welcome to Symplectic Dynamics.
#Cybernetics #ArtificialIntelligence #AGI #TechTrends2026 #SymplecticDynamics
7
8
33
2,339
SamScale retweeted
28 Dec 2025
Spent the morning wiring systems together and realized the unlock isn’t better models it’s tighter feedback.
Most people build the engine first then figure out steering later. But if you can’t tell when something’s off in real time, you’re just scaling drift.
The thing that catches errors is the product. Everything else is plumbing.

1
6
20
392
SamScale retweeted
24 Dec 2025
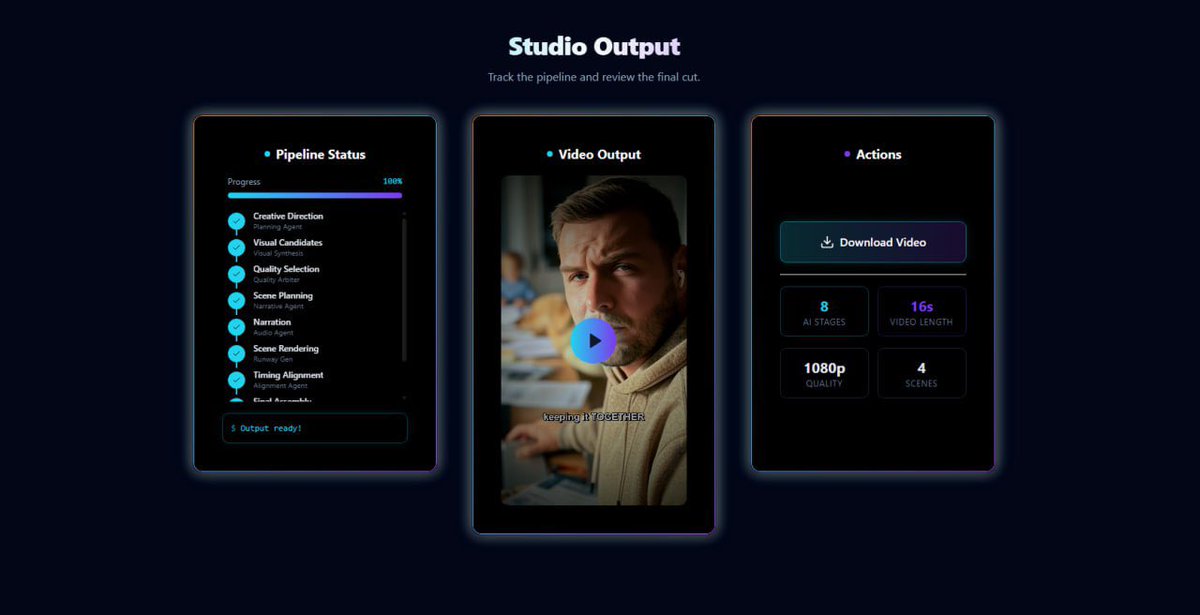
8 stage multi-agent orchestrated one click cinematic reel done ✅
7
8
22
398
SamScale retweeted
23 Dec 2025
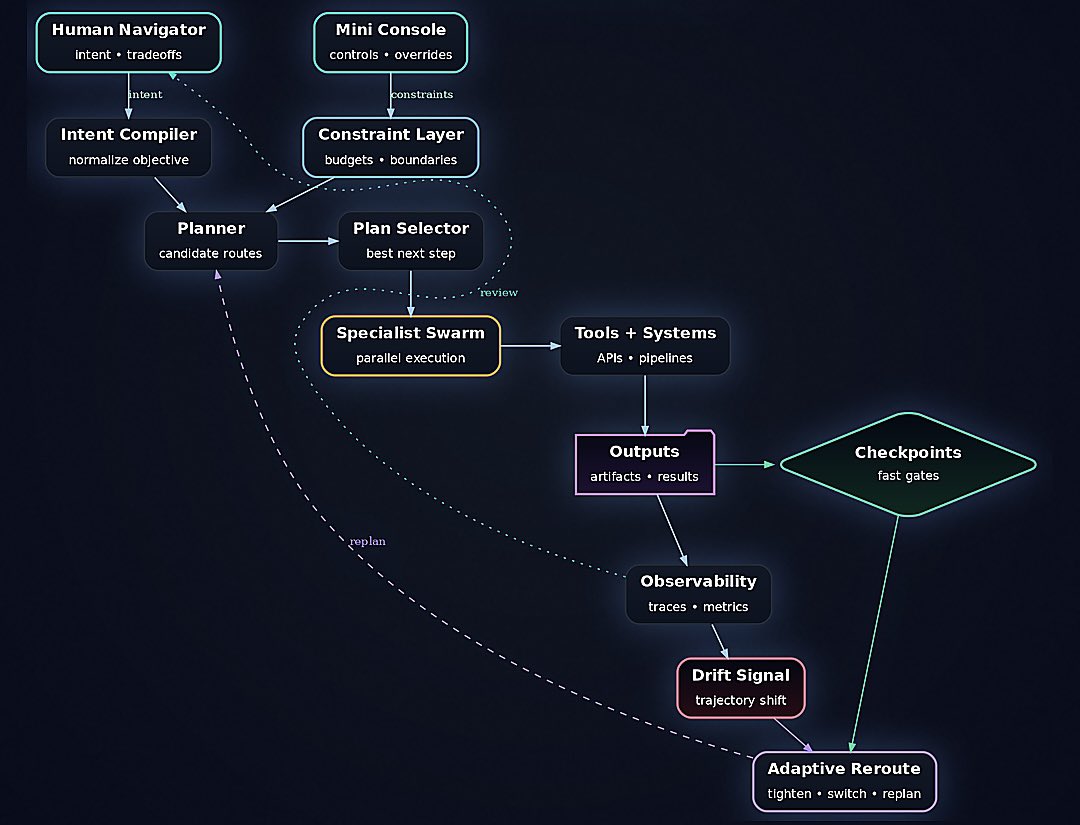
Most AI agents are just prompt chains hoping for the best.
No constraints. No budgets. No way to know when they’ve drifted off course.
So we built a control loop 🔁
Human sets intent → system compiles it into a plan → specialist swarm executes in parallel → checkpoints catch drift before it compounds → adaptive reroute when things shift.
The architecture isn’t about making AI smarter. It’s about making it steerable.
Because autonomy without governance is just expensive chaos.
#MultiAgentOrchestration
5
8
25
731
SamScale retweeted
20 Dec 2025
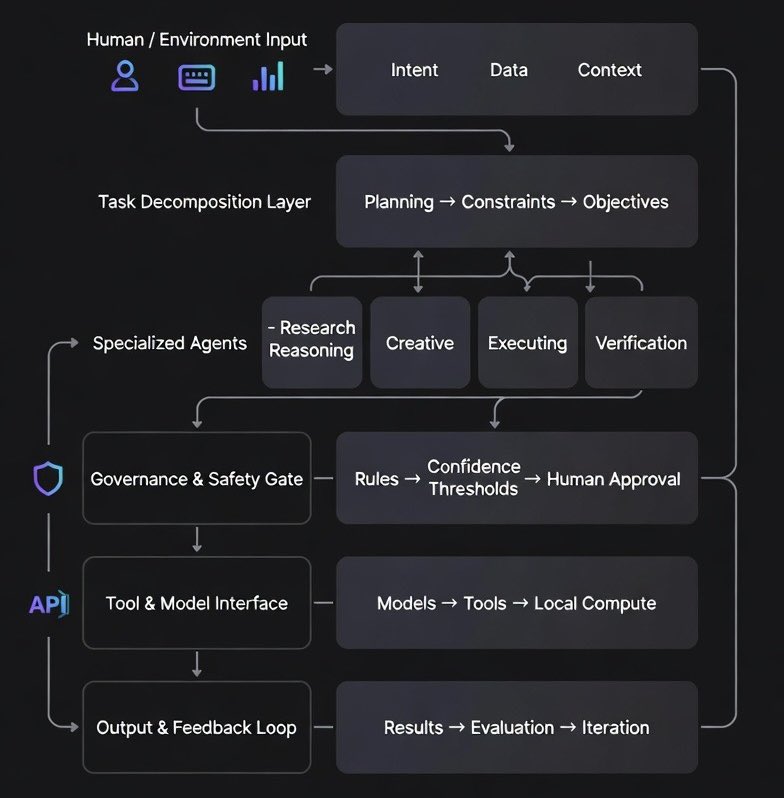
Multi agent orchestration > Single agent workflows 👨🏻🔬
Stop asking one model to do everything. It doesn't work in production 📉
4
10
21
402
SamScale retweeted
18 Dec 2025
The industry standard is 4 weeks. Our standard is 4 minutes ⏰
This is the AGI Software Factory a governed system that plans, decomposes, executes, verifies, and ships software autonomously.
Most “AI tools” stop at generation. This goes end-to-end: task intake → agent orchestration → execution → validation → output.
All LLM’s have horse power the hard part is coordination, restraint, and reliability at runtime.
This is the warm up. Wait until you see what’s next 👨🏻🔬
#SAMscale
6
13
25
953
SamScale retweeted
18 Dec 2025
The creator economy will never be the same.
Just made this cooking video in under 20 minutes.
@GeminiApp couldn’t tell it wasn’t a real person 🤷🏻♂️
If Google can’t tell the difference neither will your audience.
4
8
22
737
SamScale retweeted
17 Dec 2025
The chatbot era is ending 🤖
This is what production intelligence actually looks like.
Not prompts ❌
Not wrappers ❌
Not chat interfaces ❌
A governed micro-factory where agents execute deterministically, coordinate through shared memory, and are restrained at execution time.
Intelligence doesn’t fail because it isn’t powerful enough.
It fails because it isn’t governed.
This is what we’re building at SAMscale 🫡
#MultiAgentOrchestration #RecursiveLearning
4
7
18
498