
Joined October 2025
- Tweets 84
- Following 85
- Followers 22
- Likes 24
36 Photos and videos





Jun 17
Started diving into knowledge distillation recently and came across SeqKD approaches a lot.
Then I came across the MiniLLM paper (On-Policy Distillation of Large Language Models) and these graphs immediately caught my eye
MiniLLM vs SeqKD across 3 different teachers:
- GPT-2 1.5B teacher
- GPT-J 6B teacher
- OPT 13B teacher
MiniLLM (solid lines) consistently outperforms traditional sequence-level KD (dashed lines) on GPT-4 feedback scores, and gets much closer to the teacher’s performance as student size grows.
On-policy distillation is looking really promising.
Paper: arxiv.org/abs/2306.08543
2
31
Jun 13
That paper is the direct conceptual ancestor of modern On-Policy Distillation (OPD) approaches.
It first showed how to reduce imitation learning and structured prediction to no-regret online learning by performing dataset aggregation on the learner’s own induced distribution (rather than the expert’s).
I came across this while digging into the deeper theoretical foundations of OPD.
arxiv.org/pdf/1011.0686
1
1
40
Jun 15
That 2011 DAGGER paper by Ross, Gordon & Bagnell remains foundational.
It reduces imitation learning under distribution shift to no-regret online learning through iterative on-policy data aggregation , a direct conceptual precursor to today’s on-policy distillation and data flywheel approaches in post-training.
arxiv.org/abs/1011.0686
13
May 14
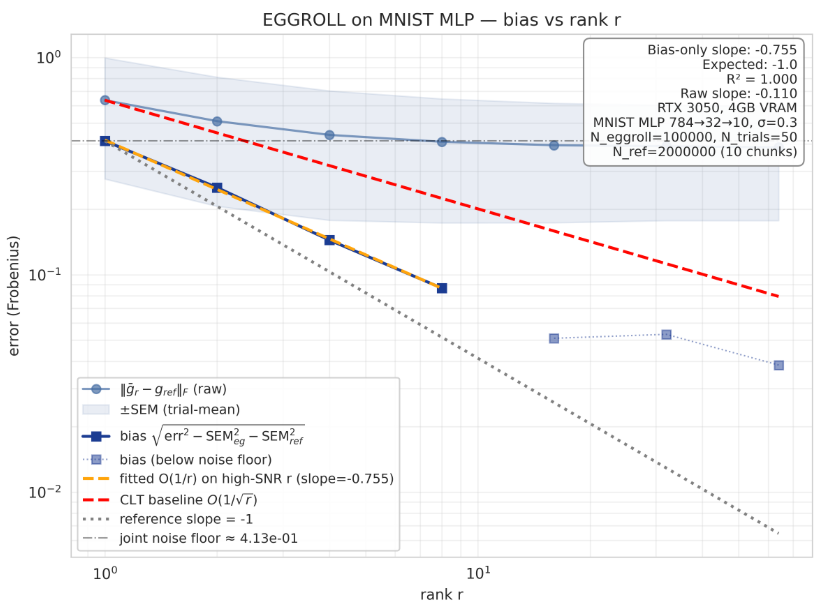
Independently verified Theorem 2 from the EGGROLL paper by @bidiptas13 @j_foerst @shimon8282 @AaronCourville (arXiv:2511.16652) on a 4GB RTX 3050.
slope -0.898 (toy), -0.755 (MNIST MLP). R² = 0.998 and 0.9995. both firmly in [-0.8, -1.2].
but the methodology is the actual contribution , naive replications will get slope ≈ -0.004 and walk away thinking the theorem fails.
Three things have to be right:
1. nonlinear fitness. the obvious quadratic (-‖W − W*‖²) gives EGGROLL and Gaussian ES identical bias by construction zero 3rd derivatives, theorem is invisible.
2. σ-tuning. bias ∝ σ², SEM is roughly σ-independent → SNR ∝ σ². at σ=0.05 slope is flat. at σ=0.3 it’s -0.755. same theorem, same code.
3. proper bias estimator. average gradients across trials first, then: bias(r) = √(max(err² − SEM_eg² − SEM_ref², 0)). per-trial error is just MC noise.
Theorem 2 holds. the math is clean. the setup just has to be.
think @yacinelearning would find the bias-isolation angle interesting.
full writeup → yuvanesh.vercel.app/blogs/EG…
code → github.com/YuvaneshSankar/EG…
4
111
May 12
Built the complete mathematical picture of EGGROLL from scratch, filling in everything the paper skips.
Walked through every proof and insight step by step.
Working on an implementation that runs on a consumer GPU like an RTX 3050 laptop, to actually show what it looks like when memory and compute stop being the bottleneck.
Great work by @bidiptas13 and the team at @j_foerst's Oxford FLAIR lab.
While going deep on this paper, I came across @yacinelearning's video which is a solid high level view of the paper if you want to start there.
Check it out: yuvanesh.vercel.app/blogs/EG…
2
2
209
Yuvanesh S retweeted

May 3
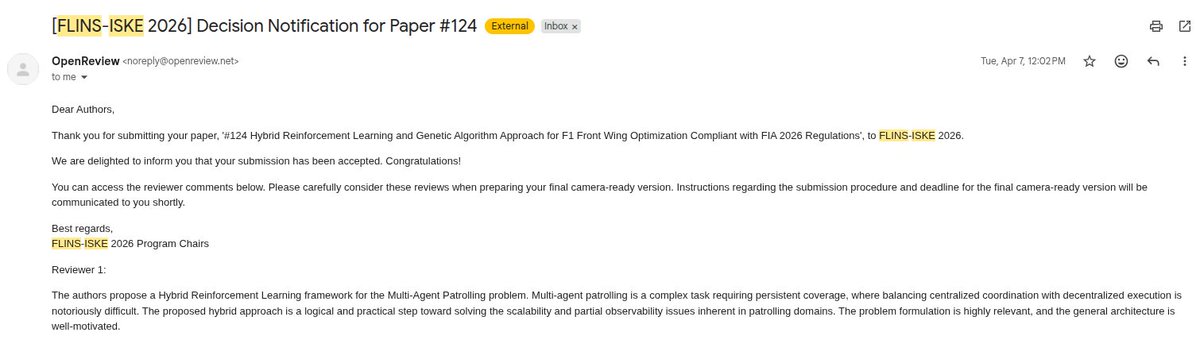
one of our papers, 'alphadesign: a hybrid reinforcement learning and genetic algorithm approach for f1 front wing optimization compliant with fia 2026 regulations', got accepted at flins-iske 2025
couldn't afford the registration so we won't be attending. trying to put it up on arxiv instead -- if anyone can help with an endorsement for cs.LG or cs.NE, would really appreciate it
huge credit to @scriptosis, @harish20205
1
2
3
360
May 2
I've fully covered the mathematical foundation of IceCache that was discussed in the paper, and parts that weren't detailed there.
IceCache is a novel approach to managing KV caches that uses Dynamic Continuous Indexing (DCI) to organize and retrieve tokens based on their semantic relationships more efficiently.
I walked through the complete sparse-retrieval theory step by step , every formula explained from first principles, every design choice motivated, every minute mathematical detail laid out. Implementation is in the next post .... check it out
yuvanesh.vercel.app/blogs/Ic…
Thank you for this wonderful paper, would love any feedback or guidance
@KL_Div @Mao_Yuzhen @q1tong
2
7
3,846
Apr 22
Few weeks ago @anirudhbv_ce shipped TurboQuant in cuTile on a Blackwell B200. Beautiful work - genuinely.
I wanted to see what the same algorithm looks like at the opposite end of the stack: raw CUDA hand-written PTX on a 4GB laptop GPU. No cuTile. No B200. Just nvcc, shared memory, and a lot of nsight-compute.
Quick context — TurboQuant paper proposed compression in KV-cache and vector-search embedding way harder than anything before it, which I have discussed earlier in my blog , please go through it for clearer understanding of the algorithm :
yuvanesh.vercel.app/blogs/Tu…
I implemented it three ways and bench marked them against each other:
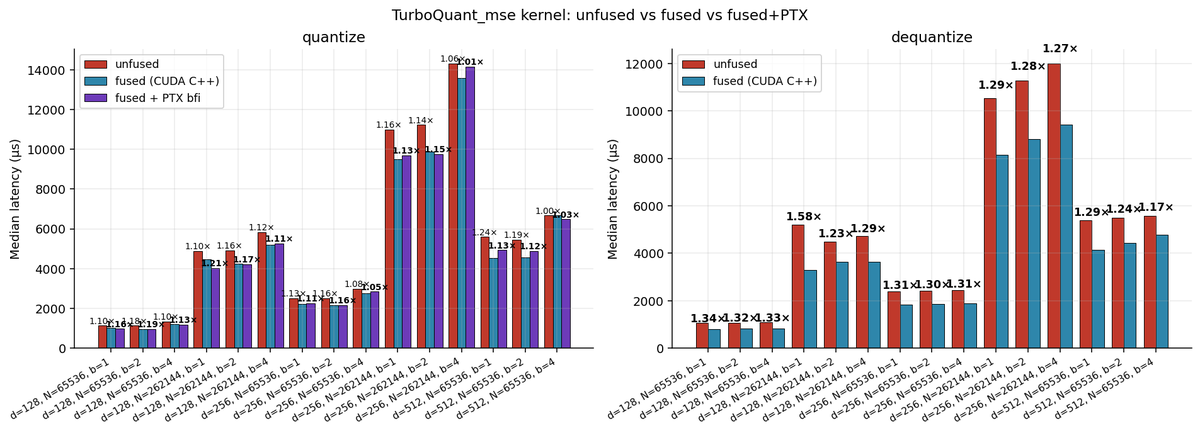
1. Vanilla CUDA — two kernels. Rotate (FWHT) in kernel 1, quantize bit-pack in kernel 2. Clean, but the intermediate rotated tensor gets written out to HBM and read back , 64 MB of wasted memory traffic per call at N=65k, d=128. Two launches too.
2. Fused — one kernel. Rotated vector stays in shared memory, quantize reads it from there directly. HBM round-trip gone. 1.10–1.25× faster on quantize, 1.17–1.41× on dequant. Dequant benefits more because its per-coord compute is smaller, so saving the HBM trip is a bigger fraction of runtime.
Hit a fun bug here. The fused kernel agreed bit-for-bit with the unfused version at b=1 and b=2, but differed in exactly 1 coord out of ~4 million at b=4. Cause: --use_fast_math was fusing (smem * scale) - codebook[k] into a single FMA, which rounds once instead of twice. At midpoint ties, that's enough to flip which centroid wins. Fix: pin the scale multiply with __fmul_rn. Bit-exact parity restored.
(cc @tri_dao — the __fmul_rn / FMA rounding thing felt like exactly the kind of footgun you run into in FlashAttention territory. Curious whether you pin rounding explicitly at ops that matter or just test against a tolerance.)
3. Fused inline PTX. Two experiments. One paid off massively, one did nothing:
pack_signs with warp ballot (vote.sync.ballot.b32) — ~2.0× across every config. 32 threads each contribute one bit in unison via a warp-level primitive. No clean C form.
bfi.b32 for bit-packing the quantized indices — zero speedup within noise. I checked the SASS and nvcc already emits BFI from the C pattern word |= (idx & MASK) << shift. The inline PTX was cosmetic.
Takeaway: inline PTX only pays off when it exposes a hardware primitive C can't express.
End-to-end on SIFT-1M (1M × 128 vectors, standard ANN benchmark): — 93% Recall@10 at 8× compression with fp32 rerank — Naive scalar quantization at same bits: 68% — At 16× compression, naive is essentially random (6%); TurboQuant still preserves 52% of true top-10
(@vikhyatk @StasBekman — tried to be careful separating the three "baselines" here: fp32 ceiling vs fp16 cast vs naive scalar at matched bits. If anyone spots methodology holes, I'd take the feedback.)
Paper's predicted distortion for b={1,2,4}: {0.36, 0.117, 0.009}. I measured {0.361, 0.116, 0.00933} over 10 seeds. Sits right on the predicted curve.
Full repo, all three implementations, reproducible benchmarks: → github.com/YuvaneshSankar/CU…
@mirrokni
1
2
7
591
Apr 13
TurboQuant paper's author , @daliri__majid , just liked my post ❤️
It really means a lot that the person behind the work took a moment to check out my deep dive.
Feeling grateful—and even more motivated to keep going. More decodes coming soon…
Thank you so much!
Apr 13

I’ve fully covered the mathematical foundation of TurboQuant that was not detailed in the original paper.
I derived and proved the complete quantization theory behind it, showing that TurboQuant achieves distortion only a factor of ~2.7 away from the theoretical ideal quantizer.
I’ve worked through all the minute mathematical details and proofs step by step.
Implementation is coming soon .... check it out
Thank you for this wonderful paper @daliri__majid @mirrokni
yuvanesh.vercel.app/blogs/Tu…
2
219
Apr 13
I’ve fully covered the mathematical foundation of TurboQuant that was not detailed in the original paper.
I derived and proved the complete quantization theory behind it, showing that TurboQuant achieves distortion only a factor of ~2.7 away from the theoretical ideal quantizer.
I’ve worked through all the minute mathematical details and proofs step by step.
Implementation is coming soon .... check it out
Thank you for this wonderful paper @daliri__majid @mirrokni
yuvanesh.vercel.app/blogs/Tu…
3
325
Yuvanesh S retweeted
Apr 8
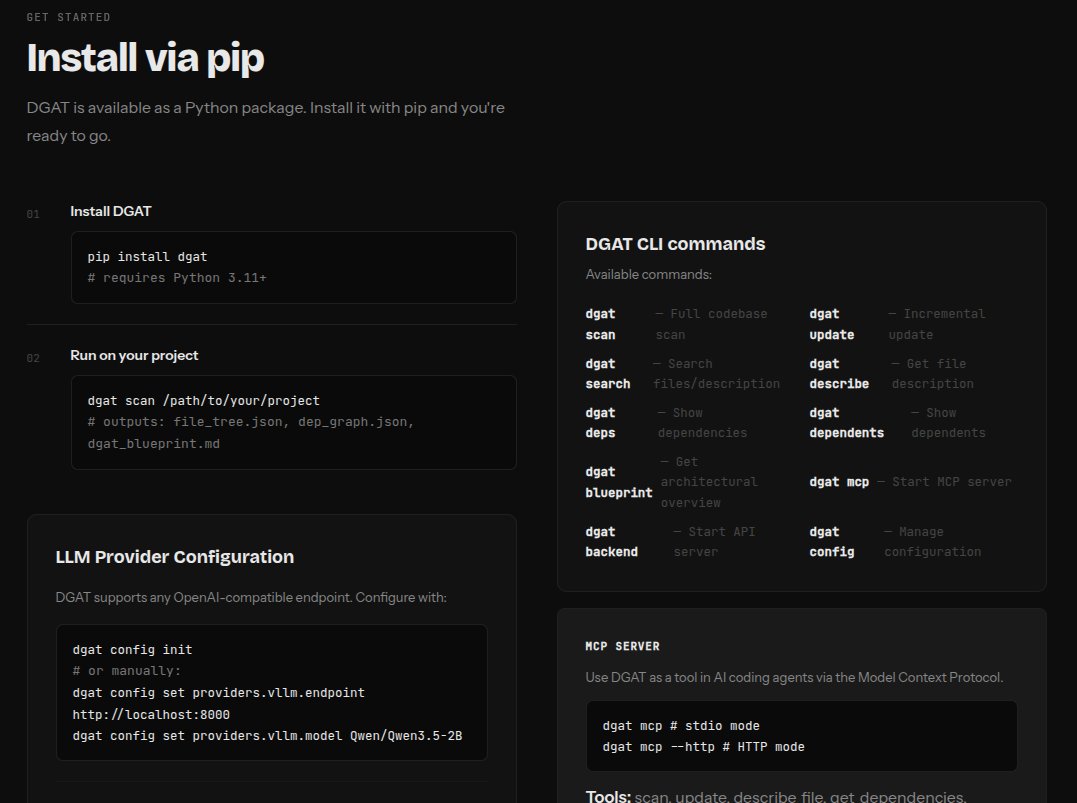
Just made understanding any codebase way simpler.
DGAT is live:
uv pip install dgat
dgat config init
dgat scan /path/to/your/project
One command and you get:
- file_tree.json
- dep_graph.json
- dgat_blueprint.md (LLM-synthesized architectural overview)
Point it at any repo → instant annotated dependency graph blueprint. Trying with different harnesses like opencode, claude code. Benchmarks coming soon!!
2
1
3
261
Apr 2
The author of the MaxRL paper @FahimTajwar10 just liked my post ❤️
I’m genuinely smiling right now.
It means a lot that the person who wrote the paper took a moment to check out my deep dive. Feeling incredibly grateful and motivated.
More decodes coming up....
Thank you so much!
Apr 2
Just dropped a full mathematical deep-dive on the MaxRL paper
I went way beyond the original paper and derived every single step they skipped — the hidden connections between maximum likelihood and RL, the exact gradient mismatch, why the simple "average over successes" estimator is actually unbiased for the truncated MaxRL objective, the full binomial expansion proofs, and how it all smoothly interpolates from standard RL (T=1) to true MLE as compute → ∞.
No hand-wavy explanations. Pure math. All the derivations you actually need to understand what's going on under the hood .
Checkout the blog :
yuvanesh.vercel.app/blogs/Ma…
1
3
376
Apr 2
Just dropped a full mathematical deep-dive on the MaxRL paper
I went way beyond the original paper and derived every single step they skipped — the hidden connections between maximum likelihood and RL, the exact gradient mismatch, why the simple "average over successes" estimator is actually unbiased for the truncated MaxRL objective, the full binomial expansion proofs, and how it all smoothly interpolates from standard RL (T=1) to true MLE as compute → ∞.
No hand-wavy explanations. Pure math. All the derivations you actually need to understand what's going on under the hood .
Checkout the blog :
yuvanesh.vercel.app/blogs/Ma…
1
2
621
Yuvanesh S retweeted
Mar 21
One of our papers, 'SpecQuant: Speculative Decoding with Multi-Parent Quantization for Adaptive LLM Inference', just won the Best Paper Award at a conference! Huge credit goes to @harish20205 and @scriptosis !"
project website: specquant.vercel.app/

1
2
2
267
Mar 20
I wouldn't agree at all that this EsoLang-Bench drop is some profound revelation -- frontier models tanking on brainfuck etc. isn't 'shocking', it's expected when you deliberately pick syntax torture tests with near-zero training data. Many replies nail it: no human baseline, unfair apples-to-oranges (humans suck at BF too), ignores that agentic setups (tools/iterations) crush it anyway. Feels like classic visibility-farming clickbait ('🚨 Shocking') while poking at memorized patterns.
Real optimization isn't syntax games—it's efficient binaries/kernels, which is why KernelBench matters.
@xai recent reorg/talks (@elonmusk) push exactly that: models discovering optimal machine binaries directly, skipping traditional compile paths for massive efficiency gains.
Not what I'd expect serious labs (including Indian ones) to hype, but here we are.

🚨 Shocking: Frontier LLMs score 85-95% on standard coding benchmarks. We gave them equivalent problems in languages they couldn't have memorized. They collapsed to 0-11%.
Presenting EsoLang-Bench.
Accepted to the Logical Reasoning and ICBINB workshops at ICLR 2026 🧵
123
Feb 17
It’s finally here .....
My deep dive into NVIDIA’s new “alien” Rubin GPUs — faster than my WiFi when I’m not downloading anything.
If Blackwell was strong, Rubin looks like it bench pressed a data center.
Read before it achieves AGI without us:
yuvanesh.vercel.app/blogs/Ru…
1
1
2
160