
Assistant Professor of Computing Science @SFU. Ph.D. from @Berkeley_EECS and Bachelor's from @UofTCompSci. Formerly @GoogleAI and Member of @the_IAS.
Joined June 2019
- Tweets 227
- Following 422
- Followers 6,490
- Likes 358
60 Photos and videos












Diffusion and flow matching-based robot planners are slow and generate noisy and jerky trajectories.
Delighted to share our ICRA 2026 paper, which leverages IMLE to improve planning frequency 19-fold from 4.3 Hz to 83 Hz and reduces jerk by 38% relative to flow matching.
Joint work w/ Grayson Lee, Minh Bui, Shuzi Zhou, Yankai Li and Mo Chen.
(1/7)
14
90
792
94,967
A big thank you to our organizing committee, advisory board, workshop organizers, assistants, volunteers, staff, sponsors, suppliers, @c_a_i_a_c and CIPPRS for helping us pull off the biggest AI/CRV ever! We'd also like to thank our speakers, authors, reviewers, presenters and attendees for contributing ideas and fostering vibrant discussions!
Special shoutout to my co-general chair, Mo Chen, fellow organizing committee members (Carson Leung, Lydia Bouzar-Benlabiod, Katie Ovens, @RezaFaieghi, Ritu Chaturvedi, Tara Azin, Lueder Kahrs, Jun Jin, @HangMa_AI, @duckietown_coo, @lrjconan, Yaoliang Yu, Alexandre Girard, Amy Wu, @angelxuanchang, @d_j_sutherland, @ev4n3sce, @WenhuChen, Annie Ying, @WuyangC and Yasaman Etesam), and advisory board members (Claire Tomlin, Gregory Dudek, @sirbayes, Richard Zemel and @SheilaMcIlraith) for generously contributing their time and effort! Please see ai-crv.ca for a full list of everyone who made the conference possible.

Last week, we were proud to host the Canadian Conference on Artificial Intelligence, Robotics, & Vision (AI/CRV) 2026.
Thank you to our sponsors, speakers, organizers, and attendees for making this year's conference a success.
Read more here: ow.ly/bsi450Z7mZz




1
4
604
Diffusion and flow matching-based robot planners are slow and generate noisy and jerky trajectories.
Delighted to share our ICRA 2026 paper, which leverages IMLE to improve planning frequency 19-fold from 4.3 Hz to 83 Hz and reduces jerk by 38% relative to flow matching.
Joint work w/ Grayson Lee, Minh Bui, Shuzi Zhou, Yankai Li and Mo Chen.
(1/7)
14
90
792
94,967
For more details, see:
- Project website: gmpc-imle.github.io/
- Paper: arxiv.org/pdf/2603.13733
- Code: github.com/kir-/mpc-imle
If you are at ICRA, come check out Poster 301 on Tuesday afternoon!
(7/7)
2
4
24
1,292
A very nicely written blog post on IceCache! Highly recommended for anyone interested in how IceCache works under the hood.
May 2

I've fully covered the mathematical foundation of IceCache that was discussed in the paper, and parts that weren't detailed there.
IceCache is a novel approach to managing KV caches that uses Dynamic Continuous Indexing (DCI) to organize and retrieve tokens based on their semantic relationships more efficiently.
I walked through the complete sparse-retrieval theory step by step , every formula explained from first principles, every design choice motivated, every minute mathematical detail laid out. Implementation is in the next post .... check it out
yuvanesh.vercel.app/blogs/Ic…
Thank you for this wonderful paper, would love any feedback or guidance
@KL_Div @Mao_Yuzhen @q1tong
6
2,703
LLMs require more GPU memory as they generate longer responses. Can we make GPU memory constant without significantly sacrificing accuracy?
IceCache is a new method for managing KV caches that leverages Dynamic Continuous Indexing (DCI) to efficiently group and retrieve tokens by semantics.
Joint work w/ @Mao_Yuzhen, @q1tong and Martin Ester.
For details, check out the links below.
5
16
217
21,109
Project website: yuzhenmao.github.io/IceCache…
Paper: arxiv.org/abs/2604.10539
Time and Location at ICLR 2026: iclr.cc/virtual/2026/poster/…
17
1,221
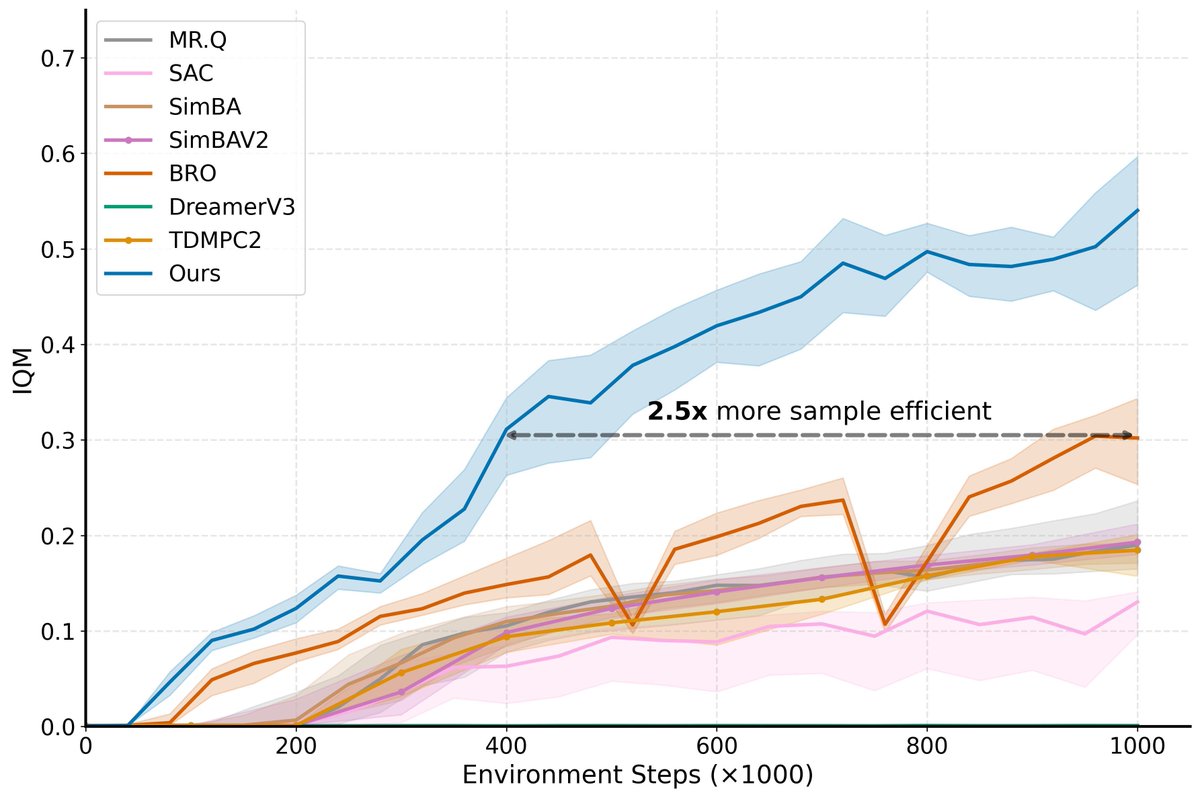
Introducing WIMLE, a model-based RL method that substantially improves sample efficiency and asymptotic performance on hard tasks. Rather assuming a Gaussian world model, WIMLE trains a world model with IMLE.
Joint w/ @mehranag, @Moazeni_Alireza, @yszhang170.
See 👇 for links.
1
7
29
3,999
Project website: mehranagh20.github.io/wimle/
Paper: arxiv.org/abs/2602.14351
Time and Location at ICLR 2026: iclr.cc/virtual/2026/poster/…
3
568
To be fair to the authors, I think the normalization of the kernel is key.
If the normalization weren't there, the kernel would not depend on other samples. In that case, the drift would be the same regardless of whether (1) all fake samples are far away from a real sample (which is common at the beginning of training), or (2) one fake sample is much closer to a real sample compared to other fake samples (which is common later on in training).
One would want the drift to be large in the former case and small in the latter case. But without normalization, there would be no way to make that happen.
Feb 9

The recent Drifting Models paper from Kaiming's group got very hyped over the past few days as a new generative modeling paradigm, but in fact, it can actually be seen as a scaled-up/generalized version of the good old GMMN from 2015 (and the authors themselves acknowledge this in the paper in Appendix C.2, noting that GMMN can be seen as Drifting Models for a particular choice of the kernel). Also, I am very skeptical about its scalability (for higher diversity / higher resolution datasets, larger models, and videos).
The way Drifting Models work is actually very simple:
- 1. Sample random noise z ~ N(0, I)
- 2. Feed it to the generator and get a fake sample x' = G(z)
- 3. For each fake sample x', compute its similarity (in the feature space of some encoder) to each of the real samples x_i from the current batch.
- 4. Push it closer toward these real samples using the similarities as weights (i.e. so that we push to the nearest ones the most).
- 5. To make sure that we don't have any sort of mode collapse, repel each fake sample from other fake samples via the same scheme.
- 6. Profit
Now, GMMN follows exactly the same scheme, with the only difference being that it uses a different (unnormalized) function in the "distance computation" and doesn't allow for cleanly plugging in normalization/scaling in the similarity scores or CFG.
Why didn't GMMN take off and why am I skeptical about Drifting Models? The issue is that it makes it much harder to compute any meaningful similarity when your dataset gets more diverse (happens when you switch to foundational T2I/T2V model training), or the batch size gets smaller (happens when your model size or training resolution increases), or your feature encoder produces less comparable representations (happens for videos or more diverse datasets). You can sure get informative similarities for 4096 batch size on the object-centric, limited diversity ImageNet with ResNet-50 feature encoder, but for smth like video generation, we train on hundreds of millions of videos or, at high resolutions larger model sizes, with a batch size of 1 per GPU (not sure if will be fast to do inter-GPU distance computations).
From the theoretical perspective, even though the final objective and the practical training scheme are the same, the mathematical machinery to formulate the framework is very different and enables direct access to the drifting field (e.g., to easily enable CFG which the authors already did). But I guess what I like the most about this paper is that Kaiming's group is boldly pushing against the mainstream ideas of the community, and hopefully it will inspire others to also take a look at the fundamentals and stop cargo-culting diffusion models.
6
4
101
26,035
Thanks for pointing out the similarity between drifting and Implicit Maximum Likelihood Estimation!
I worked out the mathematical connection - the crux is that drifting fields are similar to the gradient of a soft version of the IMLE loss. So drifting is defined in terms of the gradient, whereas IMLE is defined in terms of the objective, but the behaviour should be similar. It's reminiscent of the formulation of classical mechanics vs. Lagrangian mechanics from physics.
One difference is that in drifting the weights on the positive samples and the negative samples are different, whereas they are the same in IMLE. It'd be interesting to see if the negative weights can be replaced with positive weights.
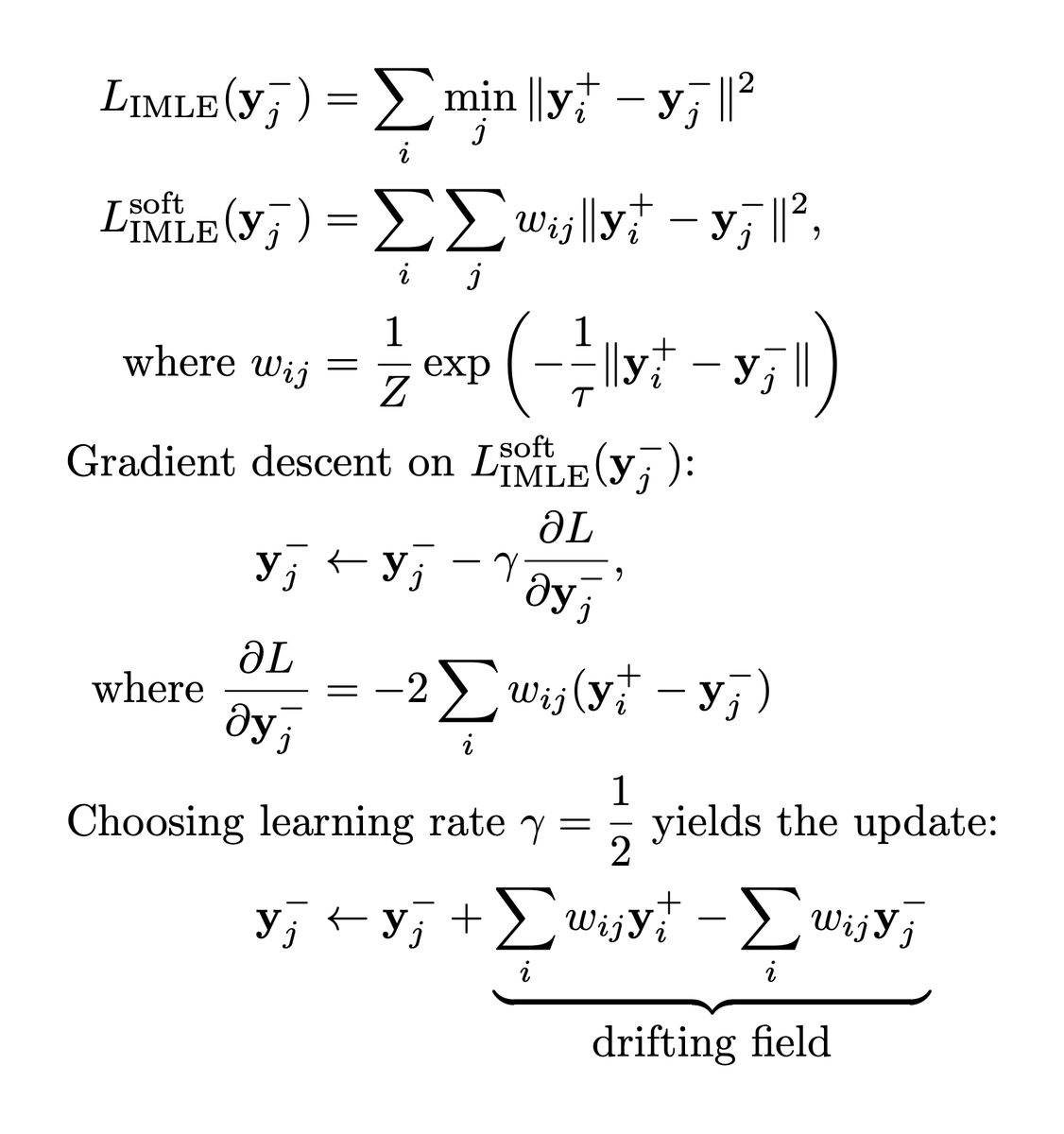
Feb 5

Cool new paper by @Goodeat258 and Kaiming's team!
arxiv.org/abs/2602.04770
Reminds me of @KL_Div's Implicit Maximum Likelihood Estimation paper
10
76
768
181,045
If you are at #ICCV2025, check out our work on interpolating between two states of a 3D scene with large motion at poster 269 on Tuesday afternoon. It proposes a general-purpose method that can disambiguate points with similar appearance.
Website: junrul.github.io/gmc/
1/5
1
12
2,171
More results are below.
This was a fun collaboration with @_Linjunru, @researchirag, @mikacuy, @Stearns2Colton, @XuanLuo14 and @GuibasLeonidas :)
5/5
3
895