
Joined August 2023
- Tweets 7
- Following 49
- Followers 16
- Likes 56
Photos and videos
Shaoting Feng retweeted

Jun 1
𝐃𝐲𝐧𝐚𝐦𝐨 𝐰𝐢𝐭𝐡 𝐋𝐌𝐂𝐚𝐜𝐡𝐞 𝐌𝐏 𝐦𝐨𝐝𝐞
We've updated the Dynamo integration to support LMCache's new multiprocess(MP) mode, complete with ready-to-run startup scripts. If you're serving with Dynamo, there's now a launch path for running LMCache as an out-of-process sidecar alongside the vLLM backend. Dynamo connects to the sidecar through LMCacheMPConnector, bringing the integration in line with LMCache's newer multiprocess architecture.
Huge thanks to @shaoting_feng for making this possible! Up next: disaggregated serving support for MP mode in Dynamo. Stay tuned! 🚀
👉 Explore more: docs.nvidia.com/dynamo/dev/i…
#AI #inference #LMCache #KVCache

2
4
268
Shaoting Feng retweeted
2 Sep 2025
Join us at SIGCOMM 2025(conferences.sigcomm.org/sigc…) for our full-day LMCache Tutorial — an intelligent caching middleware that makes LLM inference faster & cheaper!
📅 Sept 8, 2025
8:45 AM – 6:00 PM (Portugal Time / WEST)
= 12:45 AM – 10:00 AM (PDT)
What you’ll learn:
🔹 KV-cache offloading & reuse for LLMs
🔹 Cutting GPU memory compute costs
🔹 Real-world integrations with vLLM & beyond
✅ Register here docs.google.com/forms/d/e/1F…
#SIGCOMM2025 #LMCache #LLM #vLLM

3
20
1,334
Shaoting Feng retweeted

14 Jul 2025
With RAG and agents becoming ubiquitous in LLM systems, tuning quality and performance JOINTLY is essential to achieve the best LLM quality-of-experience.
Our paper at SOSP this year, addresses this exact tradeoff!🔥

1
6
17
2,207
Shaoting Feng retweeted
8 Jul 2025
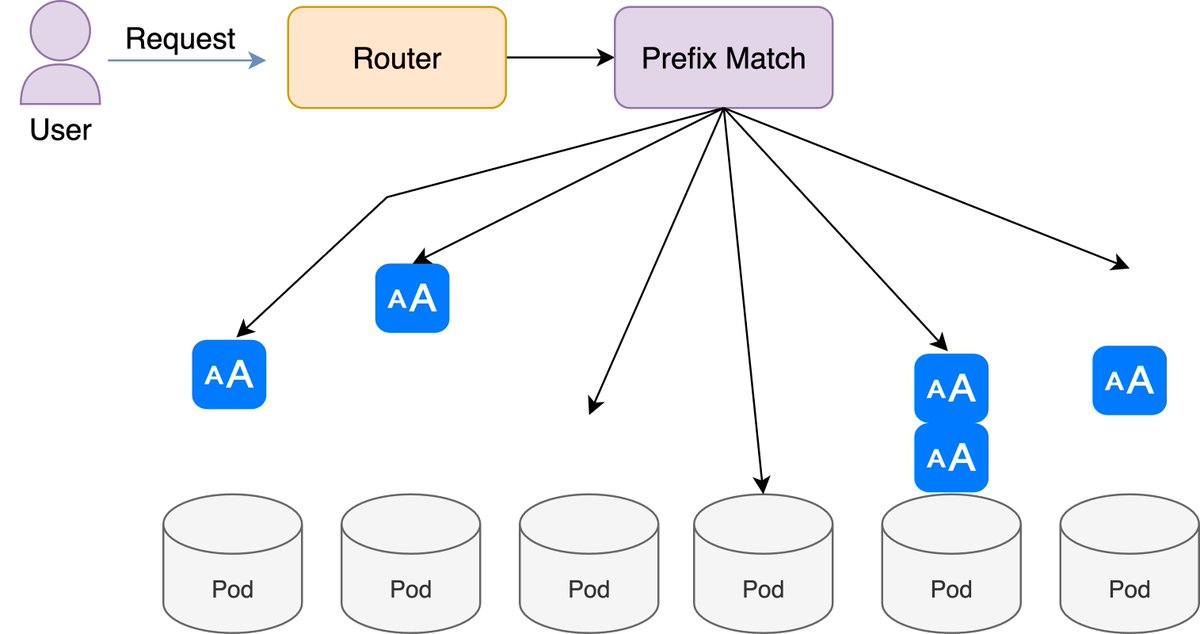
🚨 LMCache now turbocharges multimodal models in vLLM!
By caching image-token KV pairs, repeated images now get ~100% cache hit rate — cutting latency from 18s to ~1s.
Works out of the box.
Check the blog: blog.lmcache.ai/2025-07-03-m…
Try it 👉 github.com/LMCache/LMCache
#vLLM #MLLM #AIinfra #LMCache
12
41
1,650
Shaoting Feng retweeted
11 Jul 2025
Perks of building LMCache with us 😋
WE DO NOT ONLY FUEL YOUR LLMs
10 Jul 2025

Having buns for lunch.
Perks of having a colleague whose grandma lives close 🫨
At samuel shen

1
1
6
504
Shaoting Feng retweeted
7 Mar 2025
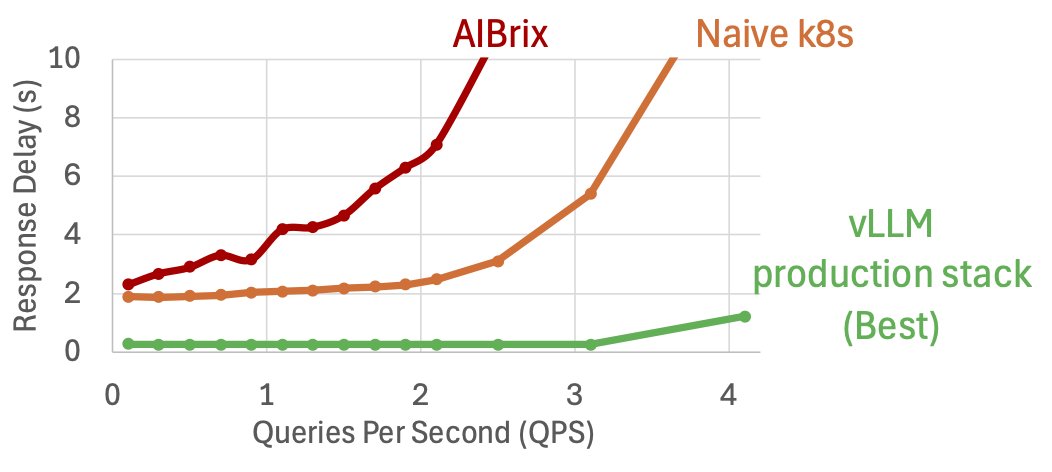
Our open-source LLM cluster deployment solution is 10x faster than SOTA OSS solution. Check out the vLLM Production-Stack!🤩🤩🤩
Since Jan 2025, vLLM Production Stack has been the reference open-source vLLM inference cluster solution with advanced KV cache offloading and K8s native support. Today, our benchmarks show that it is:
✅10x better performance than SOTA OSS solution (AIBrix) in multi-turn chat
✅More stable after set up
Reproduce it yourself:
📝Blog post and benchmark: blog.lmcache.ai/2025-03-06-b…
🔗Github repo: github.com/vllm-project/prod…
📺30s demo: youtube.com/watch?v=RLk8zbQ-…
#vLLM #LLM #GenAI #OpenSource #Inference #AI
6
18
1,234
Shaoting Feng retweeted
18 Oct 2024
🚀 The LMCache docs website are now live! 🎉
Whether you're new to LLMs or a pro, our doc covers your need!
📚 Getting Started guides
🔍 Small examples
👨💻 Code documentations
Boost your LLM deployment today!
Check our blogpost!
blog.lmcache.ai/2024-10-17-d…
8
7
674