
Joined September 2024
- Tweets 213
- Following 50
- Followers 978
- Likes 304
96 Photos and videos











Jun 11
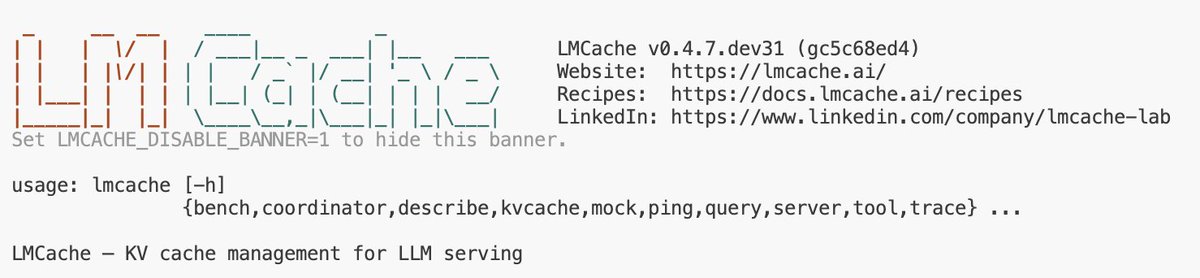
𝐋𝐌𝐂𝐚𝐜𝐡𝐞 𝐂𝐋𝐈 𝐣𝐮𝐬𝐭 𝐠𝐨𝐭 𝐚 𝐧𝐞𝐰 𝐬𝐭𝐚𝐫𝐭𝐮𝐩 𝐛𝐚𝐧𝐧𝐞𝐫! 🎨
Run any lmcache command, or start LMCache through the vLLM connector, to see the new banner with version info and CLI usage.
Huge thanks to @this_will_echo for the contribution! Try it today from source, or look for it in the next release.
Explore LMCache commands: docs.lmcache.ai/cli/index.ht…
#LLM #AIInfrastructure #KVCache #LMCache
1
6
189
Jun 10
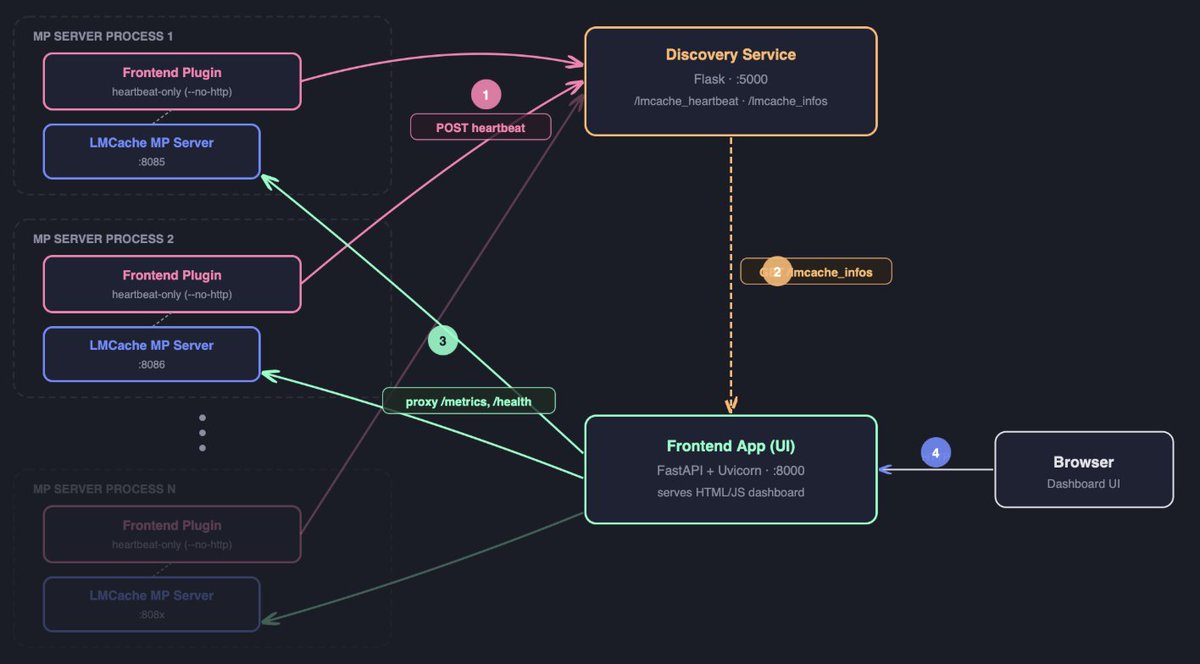
𝐓𝐡𝐞 𝐋𝐌𝐂𝐚𝐜𝐡𝐞 𝐅𝐫𝐨𝐧𝐭𝐞𝐧𝐝 𝐃𝐚𝐬𝐡𝐛𝐨𝐚𝐫𝐝 𝐢𝐬 𝐡𝐞𝐫𝐞! 🎉
We've been wanting a simple way to keep an eye on a running LMCache deployment and now there's one. The Frontend Dashboard is a lightweight web UI that lets you monitor and manage a whole fleet of LMCache multiprocess (MP) servers from a single browser tab.
Here's what you'll find inside:
- 𝐍𝐨𝐝𝐞 𝐭𝐫𝐞𝐞 — A collapsible map of your deployment. Each proxy node is an LMCache MP server; its leaf nodes are the cache-engine instances on that server that do the actual KV-cache work — store, lookup, and loading. Expand any proxy to see what's running under it and how the cache is wired together.
- 𝐀𝐠𝐠𝐫𝐞𝐠𝐚𝐭𝐞𝐝 𝐦𝐞𝐭𝐫𝐢𝐜𝐬 — GET /metrics rolls up Prometheus metrics from every leaf node into a single endpoint, so you don't have to scrape each worker by hand.
- 𝐑𝐞𝐯𝐞𝐫𝐬𝐞 𝐩𝐫𝐨𝐱𝐲 — /proxy2/{node_name}/{path} routes straight through to any node, letting you call its API right from the browser.
- 𝐇𝐞𝐚𝐥𝐭𝐡 𝐜𝐡𝐞𝐜𝐤 — GET /health returns {"status": "healthy"} for quick liveness probes.
Huge thanks to our core maintainer maobaolong for building and shipping this. 🙌
Want to try it? Launch instructions here: docs.lmcache.ai/mp/frontend_…
#LLM #AIInfrastructure #KVCache #LMCache
3
193
Jun 8
🚀 𝐋𝐌𝐂𝐚𝐜𝐡𝐞 𝐧𝐨𝐰 𝐬𝐮𝐩𝐩𝐨𝐫𝐭𝐬 𝐆𝐨𝐨𝐠𝐥𝐞’𝐬 𝐆𝐞𝐦𝐦𝐚 𝟒 𝐟𝐚𝐦𝐢𝐥𝐲
Gemma 4 introduces a hybrid attention structure with both sliding-window and full-attention layers, using different KV cache layouts and block sizes.
We’re excited to announce successful deployment and full support for the Gemma 4 family in LMCache. To enable this, LMCache introduces the 𝐇𝐲𝐛𝐫𝐢𝐝 𝐌𝐞𝐦𝐨𝐫𝐲 𝐀𝐥𝐥𝐨𝐜𝐚𝐭𝐨𝐫 (𝐇𝐌𝐀), which can store, transfer, and retrieve multiple KV cache groups with different block sizes. This allows prefix caching and KV reuse to work seamlessly for hybrid models, including Gemma 4 variants such as gemma-4-12b.
𝐋𝐞𝐚𝐫𝐧 𝐦𝐨𝐫𝐞: docs.lmcache.ai/mp/hybrid_mo…
𝐓𝐫𝐲 𝐭𝐡𝐞 𝐝𝐞𝐩𝐥𝐨𝐲𝐦𝐞𝐧𝐭 𝐫𝐞𝐜𝐢𝐩𝐞: docs.lmcache.ai/recipes/gemm…
#LLM #vLLM #KVCache #Gemma4 #LMCache
3
143
Jun 4
LMCache Chinese documentation is now available! Can you help us improve it?
As our community grows, we’re working to make LMCache more accessible to developers around the world.
We’ve started building a pipeline to translate LMCache documentation into Chinese. While this gives us a strong starting point, technical translation still needs community review. For example, in the LLM serving context, “recipe” should not be translated literally as “食谱,” which means “cooking recipe,” but more naturally as “操作手册” (practical guide) or “配置示例” (configuration example), depending on the context.
If you are new to LMCache and speak Chinese, this could be your great first PR: review the Chinese docs, improve technical accuracy, and get familiar with LMCache along the way.
Come contribute to LMCache with us!
#AI #inference #LMCache #KVCache
5
288
Jun 3
🔧 𝐍𝐞𝐰 𝐢𝐧 𝐋𝐌𝐂𝐚𝐜𝐡𝐞 𝐌𝐏 𝐒𝐞𝐫𝐯𝐞𝐫: /𝐫𝐮𝐧_𝐬𝐜𝐫𝐢𝐩𝐭 𝐀𝐝𝐦𝐢𝐧 𝐄𝐧𝐝𝐩𝐨𝐢𝐧𝐭
One of our core maintainers, 𝐦𝐚𝐨𝐛𝐚𝐨𝐥𝐨𝐧𝐠, introduced /run_script, a new admin endpoint for live debugging and tuning in the LMCache MP server.
With /run_script, developers can inspect runtime state, adjust read/write TTLs, query L1 memory usage, and check server status — all without restarting or redeploying the server.
Because it can access attributes through app.state.engine, changes such as TTL updates are re-read by the running code and take effect on the next read/write operation.
📖 Read the full beginner-friendly tutorial and implementation details here:linkedin.com/pulse/beginner-…
1
2
253
Jun 2
KV cache is becoming an independent AI-native data layer — shared across requests, clusters, and serving systems.
LMCache is proud to help push this frontier forward as an open-source community.
As this space continues to evolve and gain momentum, a new chapter begins for LMCache and the broader KV cache community.
Read more: blog.lmcache.ai/en/2026/06/0…
𝐒𝐭𝐚𝐲 𝐜𝐨𝐧𝐧𝐞𝐜𝐭𝐞𝐝 𝐰𝐢𝐭𝐡 𝐋𝐌𝐂𝐚𝐜𝐡𝐞:
• Follow us on LinkedIn: linkedin.com/company/lmcache…
• Join our Slack community: join.slack.com/t/lmcachework…
• Follow our WeChat Official Account: drive.google.com/file/d/1a-S…
#AI #inference #LMCache #KVCache
1
2
243
Jun 3
Update our Slack invitation link: join.slack.com/t/lmcachework…
This one should never expire 🫡
116
Jun 1
𝐃𝐲𝐧𝐚𝐦𝐨 𝐰𝐢𝐭𝐡 𝐋𝐌𝐂𝐚𝐜𝐡𝐞 𝐌𝐏 𝐦𝐨𝐝𝐞
We've updated the Dynamo integration to support LMCache's new multiprocess(MP) mode, complete with ready-to-run startup scripts. If you're serving with Dynamo, there's now a launch path for running LMCache as an out-of-process sidecar alongside the vLLM backend. Dynamo connects to the sidecar through LMCacheMPConnector, bringing the integration in line with LMCache's newer multiprocess architecture.
Huge thanks to @shaoting_feng for making this possible! Up next: disaggregated serving support for MP mode in Dynamo. Stay tuned! 🚀
👉 Explore more: docs.nvidia.com/dynamo/dev/i…
#AI #inference #LMCache #KVCache
2
4
268
May 28
𝐍𝐞𝐰 𝐢𝐧 𝐋𝐌𝐂𝐚𝐜𝐡𝐞: 𝐋𝟐 𝐚𝐝𝐚𝐩𝐭𝐞𝐫 𝐛𝐞𝐧𝐜𝐡𝐦𝐚𝐫𝐤 𝐂𝐋𝐈.
You can now benchmark throughput of an L2 cache adapter directly without starting an inference engine or an LMCache MP server for all of its base operations (store / lookup / load).
The command only requires the adapter’s backing storage to be reachable, making it easier to test and compare L2 backends before plugging them into a full serving workflow.
Try it with the L2 backend that best fits your workflow, whether that’s local filesystem, Redis, S3, or any other adapter.
Read more and start testing:
docs.lmcache.ai/cli/bench_l2…
#AI #inference #LMCache #KVCache
1
3
168
May 27
Congrats to @tensormesh for the funding!
Tensormesh is among the major contributors to #LMCache. The investment from @CoreWeave , @nvidia and @AMD (among others) testifies to the important role #LMCache plays in AI infra today and tomorrow.
BTW, Tensormesh is hiring engineers (full-time, part-time or spare-time) to work on LMCache! Shoot an email to hiring@tensormesh.ai if you are interested.
May 27

Today we announced $20M in new funding from investors including AMD Ventures, CoreWeave, NVentures, Valley Capital Partners, and Laude Ventures, bringing Tensormesh’s total funding to $24.5M.
We’re also launching Tensormesh Inference into general availability.
AI applications are moving into production, and inference costs are becoming harder to ignore.
Agentic workflows repeatedly process the same prompts, context, conversation history, and tool definitions, driving up API costs on work that has already been done.
Tensormesh changes that with caching-accelerated inference.
We’re also introducing $0 cached input tokens across Tensormesh serverless deployments, so teams only pay when input tokens need to be processed, not when they can be served from cache.
Read the full announcement: tensormesh.ai/blog-posts/ten…

6
383
May 27
𝐂𝐚𝐥𝐥𝐢𝐧𝐠 𝐚𝐥𝐥 𝐧𝐨𝐧-𝐂𝐔𝐃𝐀 𝐮𝐬𝐞𝐫𝐬 — 𝐋𝐌𝐂𝐚𝐜𝐡𝐞 𝐌𝐏 𝐦𝐨𝐝𝐞 𝐧𝐨𝐰 𝐫𝐞𝐚𝐜𝐡𝐞𝐬 𝐛𝐞𝐲𝐨𝐧𝐝 𝐂𝐔𝐃𝐀!
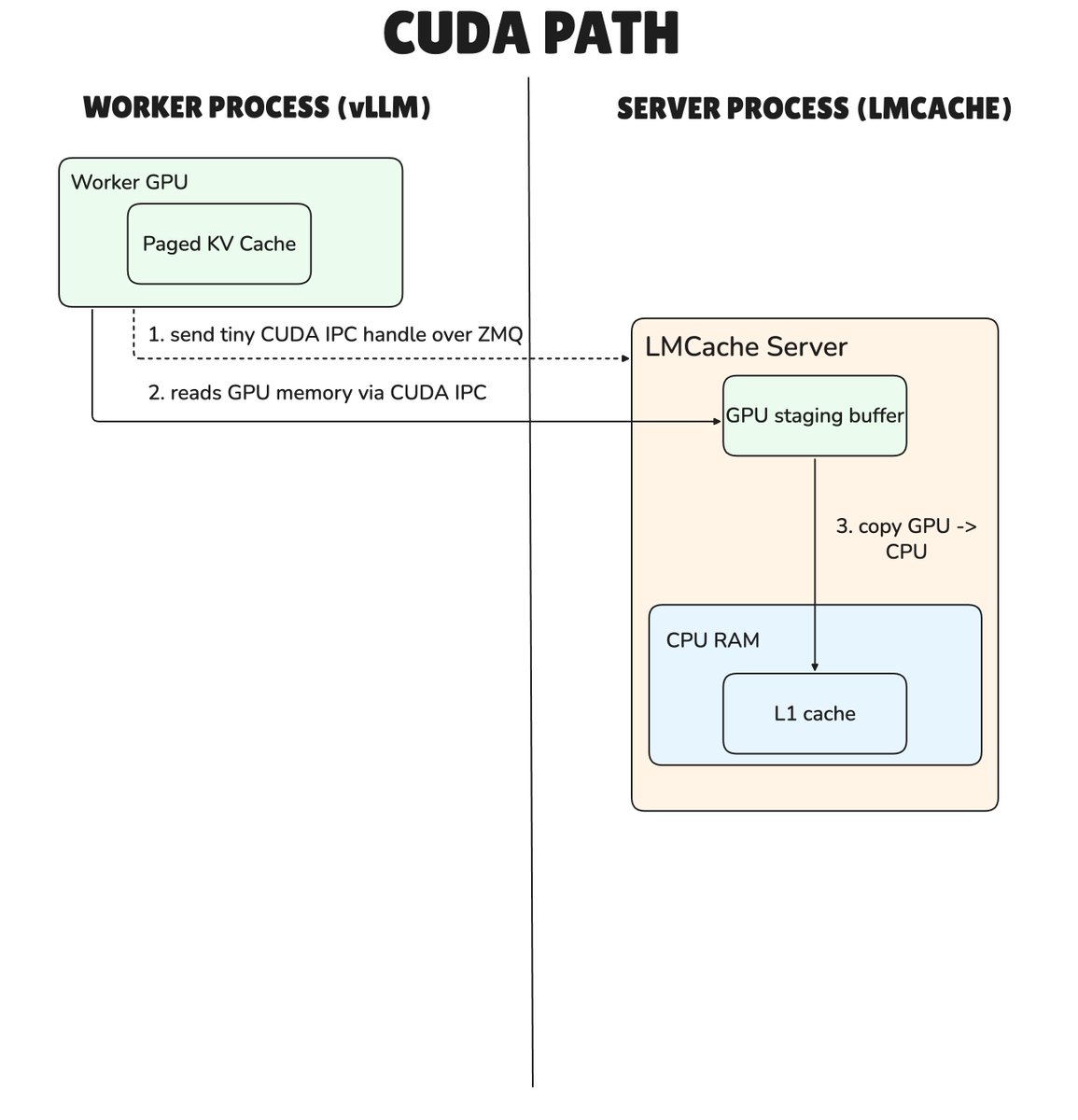
On non-CUDA devices, LMCache MP can now use ZMQ (instead of CUDA IPC) to send the KV bytes.
LMCache MP mode uses CUDA IPC, but this is not available on non-CUDA devices. To remove that limitation, community contributor 𝐡𝐥𝐢𝐧𝟗𝟗 added a 𝐧𝐨𝐧-𝐂𝐔𝐃𝐀 transfer path for CPU, XPU, HPU, and other non-CUDA environments. Since these devices do not support CUDA IPC, the worker sends the actual KV bytes over the message queue instead:
𝑔𝑎𝑡ℎ𝑒𝑟 𝑝𝑎𝑔𝑒𝑑 𝐾𝑉 -> 𝐶𝑃𝑈 𝑐ℎ𝑢𝑛𝑘𝑠 -> 𝑠𝑒𝑟𝑖𝑎𝑙𝑖𝑧𝑒 𝑤𝑖𝑡ℎ 𝑝𝑖𝑐𝑘𝑙𝑒 -> 𝑠𝑒𝑛𝑑 𝑏𝑦𝑡𝑒𝑠 𝑜𝑣𝑒𝑟 𝑍𝑀𝑄 -> 𝑑𝑒𝑠𝑒𝑟𝑖𝑎𝑙𝑖𝑧𝑒 𝑜𝑛 𝑡ℎ𝑒 𝑠𝑒𝑟𝑣𝑒𝑟 -> 𝑤𝑟𝑖𝑡𝑒 𝑡𝑜 𝐿1
On CUDA devices, LMCache continues to use the existing CUDA IPC path, where the worker sends a lightweight handle and the server reads the worker’s GPU memory directly:
𝑤𝑜𝑟𝑘𝑒𝑟 𝑝𝑎𝑔𝑒𝑑 𝐾𝑉 (𝐺𝑃𝑈) -> 𝐿𝑀𝐶𝑎𝑐ℎ𝑒 𝑟𝑒𝑎𝑑𝑠 𝑣𝑖𝑎 𝐶𝑈𝐷𝐴 𝐼𝑃𝐶 -> 𝐺𝑃𝑈 𝑠𝑡𝑎𝑔𝑖𝑛𝑔 𝑏𝑢𝑓𝑓𝑒𝑟 -> 𝐿1 𝑐𝑎𝑐ℎ𝑒 (𝐶𝑃𝑈 𝑅𝐴𝑀)
In both paths, ZMQ serves as the control channel and carries messages such as REGISTER, PREPARE_STORE, and COMMIT_STORE.
Compared with the CUDA path, the non-CUDA path adds two CPU-side copies, but 𝐞𝐱𝐭𝐞𝐧𝐝𝐬 𝐌𝐏 𝐦𝐨𝐝𝐞 𝐭𝐨 𝐧𝐨𝐧-𝐂𝐔𝐃𝐀 environments.
#KVCache #LMCache #AI #inference
5
180
May 26
New blog: 𝐖𝐡𝐞𝐧 𝐎𝐩𝐞𝐧 𝐒𝐨𝐮𝐫𝐜𝐞 𝐌𝐞𝐞𝐭𝐬 𝐎𝐩𝐞𝐧 𝐒𝐨𝐮𝐫𝐜𝐞 — 𝐀 𝐉𝐨𝐢𝐧𝐭 𝐄𝐟𝐟𝐨𝐫𝐭 𝐁𝐞𝐭𝐰𝐞𝐞𝐧 𝐋𝐌𝐂𝐚𝐜𝐡𝐞 𝐚𝐧𝐝 𝐌𝐨𝐨𝐧𝐜𝐚𝐤𝐞
The story starts with the LMCache community building the foundation: the native connector framework, dynamic plugin loading, and the MooncakeStore L2 plugin path for MP mode.
The Mooncake community then helped optimize the RDMA path step by step, adding L1 memory preregistration, batch operations, and dedicated worker lanes for different cache operations. Under Mooncake RDMA, 𝐭𝐡𝐢𝐬 𝐰𝐨𝐫𝐤𝐞𝐫-𝐥𝐚𝐧𝐞 𝐝𝐞𝐬𝐢𝐠𝐧 𝐫𝐞𝐝𝐮𝐜𝐞𝐝 𝐥𝐨𝐨𝐤𝐮𝐩 𝐩𝟗𝟗 𝐟𝐫𝐨𝐦 𝟏𝟔.𝟖 𝐦𝐬 𝐭𝐨 𝟎.𝟒𝟖 𝐦𝐬!
This was not a one-sided integration. LMCache brought the MP framework and native connector abstraction and Mooncake brought deep storage and RDMA expertise. Together, the two communities built a stronger L2 KV cache integration for distributed LLM inference systems.
Huge thanks to maobaolong, fangchizheng, chunxiaozheng, and everyone in both communities who helped make this happen!
Read the full story:
blog.lmcache.ai/en/2026/05/2…
#KVCache #LMCache #AI #inference
1
3
262
May 21
PD Disaggregation unleashed! The new async PDBackend is now much more efficient in LMCache.
In Prefill-Decode Disaggregation, a single LLM request is split across two types of nodes. A prefill node reads the prompt and produces the KV cache, while a decode node consumes that KV cache to generate tokens. The KV cache needs to move from the prefill node to the decode node over the network, typically through RDMA. In LMCache, the component responsible for moving these KV chunks is called the PDBackend.
Before the asynchronous PDBackend, LMCache’s prefill workers sent KV cache chunks one at a time and waited for each transfer to finish before continuing. This worked for simple cases, but under chunked prefill, where a long prompt is split into multiple KV transfers, concurrent requests could deadlock.
The new fully asynchronous PDBackend moves KV transfer off the critical path. Instead of blocking on each network transfer, the prefill worker can hand off KV chunks in the background and continue processing the next prompt. On the receiver side, LMCache also reserves enough buffer space for the whole request before the transfer starts, so each admitted request has enough room to finish.
This update is a great community effort from LMCache. As Prefill-Decode Disaggregation becomes more widely used, improvements like async PDBackend are essential for making KV cache transfer more reliable and scalable. Thank you to everyone in the LMCache community who helped shape, review, and harden this update!
#KVCache #LMCache #AI #inference
1
1
5
321