
Joined November 2011
- Tweets 271
- Following 539
- Followers 63
- Likes 9
12 Photos and videos







20h
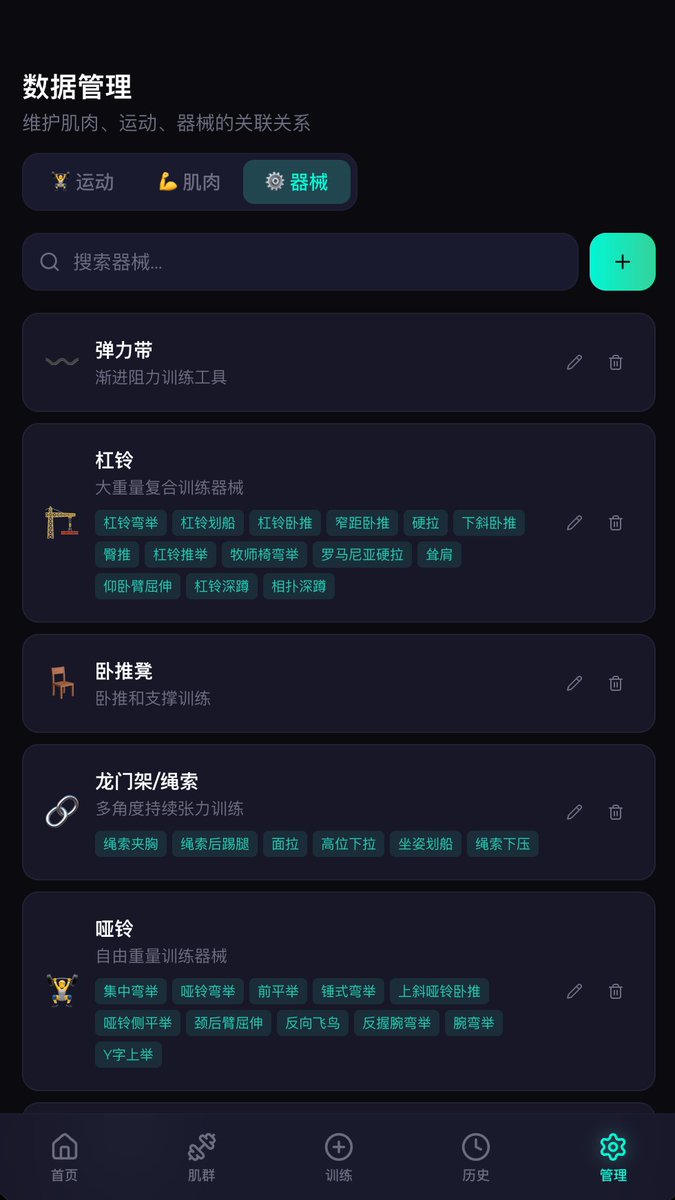
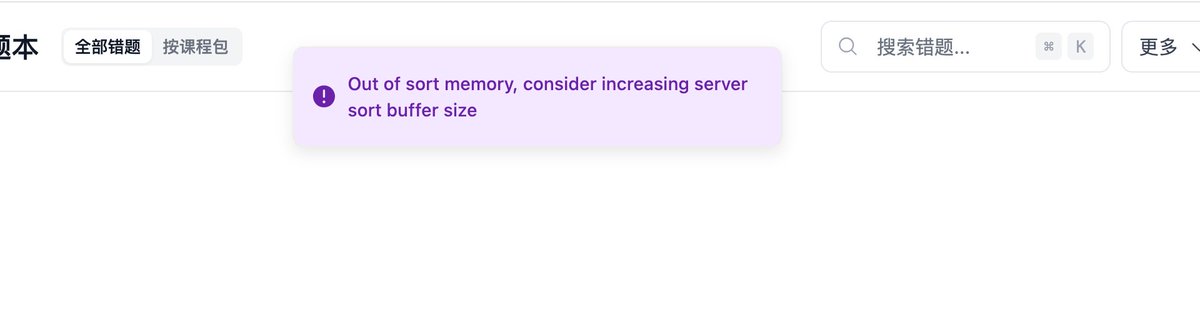
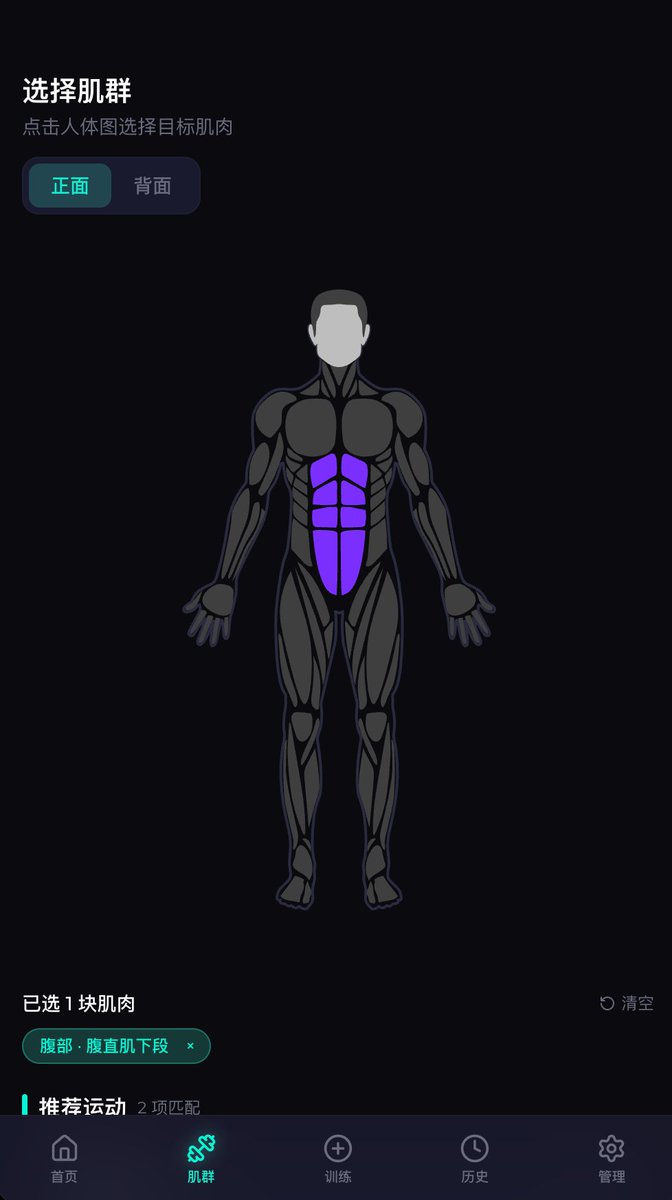
用智谱 GLM 两个版本,同一个提示词,做了一个健身类应用。
第一张图是 GLM 5.2@Zcode(花了 50 分钟,15 分钟修复依赖冲突)。
第二张图是 GLM 5.1@Codebuddy(花了 17分钟,一把过)。这是Codebuddy Agent 能力强?我应该没有用任何 UI类的 Skills,且两个 Agent 都启用了计划模式再执行的。
我想说:
5
1
350
20h
提示词:
我想开发一个移动端适配的 react 应用,主要用来解决我在健身房时,可以根据锻炼的肌肉群,来选择合适的运动项目和训练器械,并记录对应的锻炼量(如几组,每组几个),并最终按日期保存。 在应用中,要解决几个问题: 1. 用 3D 或极其精致的 2D 方式,显示人类在健身方面的常见肌群、肌肉,颗粒度精确到三角肌前束、中束、后束,肌群又可以包含三角肌后束。也就是肌群和肌肉都可以解耦,又可以组合。我不知道有没有开源的可视化解决方案,总之这是一大刚需。 2. 不同的肌肉,以及所属肌群,可以配置不同的徒手运动或训练器械。你可以为我提供一些 mock 数据,但必须支持自定义。 3. 运动记录方式按照最佳实践。 4. 数据持久化考虑直接使用 indexedDB
111

Jun 11
豆包语音刚出这玩意儿的时候,我就在想:Google 还在等啥呢?

今天被很多人忽略的大新闻
Google 发布实时翻译模型 :Gemini 3.5 Live Translate
- 能在70多种语言之间做到边听边译
- 同时保留说话人的语调、节奏和音高
- 不用等说完才翻,全程只比说话人慢几秒
- 自动滤除噪音,嘈杂环境也能用
- Google Translate App 新增「听筒模式」贴耳即听翻译
- 开发者可通过 Gemini Live API 和 Google AI Studio 直接调用
自动语言检测:
不需要提前告诉模型「我说的是中文,帮我翻成英文」。你直接说,它自己判断你在说什么语言,自动翻成目标语言。
31
Jun 6
想睡觉就有人送枕头
Jun 5

You can use codex within your own programs using the Python SDK. It's awesome. Built by @ah20im and friends
```
pip install openai-codex
```
developers.openai.com/codex/…
22
Jun 2
这个属实有点牛逼了

45
Mr.PB retweeted

May 27
昨天见了一个非常牛逼的Agent团队,我敢说在国内绝对是T0的级别(之前DPSK还找他们搞了点Agent数据)
刚好聊到了这两天推上吵得非常热闹的AI产品(Agent)要不要用Python的话题
他们Founder说的很直接:SB才在Agent项目里用Python🤣
TS适合100%Agent项目,主要有几个原因:
第一,Agent最终大多时候会在产品里。
不管你做的是Chat界面、工作流面板、浏览器插件、Copilot,还是IDE扩展、Slack/Discord/网页工具,TS天然离这些更近。
前端是TS,后端也是TS,中间的tool schema、事件流、UI状态都能共用一套类型。
如果你用Python那就会变成:
模型服务在Py、后端在Node、前端在TS
一份schema要复制三份
如果某个字段名大小写错了,你的Agent马上就给死给你看。
第二,Agent很依赖异步和事件流。
Agent不是一次请求一次回答这么简单。
它要边想边输出,边调用工具,边等用户确认,边更新UI,边处理取消、重试、超时、恢复。
TS/Node在事件驱动、stream、WebSocket、server-sent events这些场景里很顺。
Python当然也能做,但你会更容易感受到「这东西本来不是为这类Web产品链路长出来的」。
第三,类型系统对Agent很重要。
Agent真正容易炸的地方不是「模型不会说话」,而是工具参数错、返回结构错、状态字段错、上下文对象变形。
TS可以把很多东西提前卡住:
tool input/output、agent state、message format、UI事件、workflow node、permission object、external API response
这对Agent很关键,因为Agent系统里有大量JSON对象在飞来飞去。
第四,TS更适合做「Agent runtime」。
如果你做的是一个Agent框架、SDK、运行时、插件系统,TS优势更明显。
因为使用者往往要把它接进:
网页、后台服务、Electron、浏览器插件、VS Code插件、API route、serverless、edge runtime
这些地方TS生态更统一。
所以很多Agent infra选TS,不是因为Python不行,是因为它们要服务的使用场景更接近Web开发者和产品团队。
第五,AI应用现在其实是拼系统。
早期大家用Python,是因为AI=模型。
现在很多AI产品已经演化到包含LLM API、tool calling、database、vector store、browser automation、workflow、UI、billing、auth、analytics
这已经不是研究工程了,是产品工程。
互联网产品工程的主语长期就是JS/TS。
很无聊,但世界就是这么没品😮💨
但他也表示Python不会消失。
更合理的分工其实是:
Python做模型层、数据层、eval、embedding pipeline、离线任务、实验脚本。
TS做产品层、Agent编排层、前端交互层、插件层、用户可见的runtime。
所以你如果做一个Agent产品,你最好:
MVP前端 Agent orchestrator用TS。
涉及模型训练、数据处理、复杂检索、评测系统,再上Python。
聊了一下午,真的学了太多了
才知道自己之前对于Agent的认知到底有多浅薄🧎
156
155
1,033
291,775
Mr.PB retweeted

May 26
永远不要向别人透露你的愿景,这根本无关于保密、事以密成之类的谎话。
因为时间会让所有的想法朽烂,显得愚不可及。你会因为A而上路,但最终把事情做成了B,直到改造为C,C让你活下来,最后在D上成功,D发展为E的时候,E让你人尽皆知,E里面的F、G、H可能让你身败名裂,但F、G交织出来的J让你伟大!
自己想想,有哪个先驱不是这个剧情?
55
22
163
17,401
May 20
活久见了

We are investigating unauthorized access to GitHub’s internal repositories. While we currently have no evidence of impact to customer information stored outside of GitHub’s internal repositories (such as our customers’ enterprises, organizations, and repositories), we are closely monitoring our infrastructure for follow-on activity.
22
May 11
郭老弟牛逼的,我看到这些评论了,当时就不太舒服。你的tuwa对我启发很大,帮了我很大的忙。没法评论,只能引用支持一下。

40
May 7
对人类来说,时间感也是一种明确注入的上下文啊。嗨,这说的真不是人话。

基于 Transformer 架构的 LLM 最大的问题就是没有时间感,我觉得这是主观智能甚至是意识到重要部分,时间的连续感知和记忆的先后形成了“自我”!每次涉及到Agentic 任务我都得让模型自己使用 tool 确定操作时间,别让它靠幻觉脑补😂 不知道我这样对不对?
1
26
May 5
If that's true, it'll totally change the world!
May 5

Introducing SubQ - a major breakthrough in LLM intelligence.
It is the first model built on a fully sub-quadratic sparse-attention architecture (SSA),
And the first frontier model with a 12 million token context window which is:
- 52x faster than FlashAttention at 1MM tokens
- Less than 5% the cost of Opus
Transformer-based LLMs waste compute by processing every possible relationship between words (standard attention).
Only a small fraction actually matter.
@subquadratic finds and focuses only on the ones that do.
That's nearly 1,000x less compute and a new way for LLMs to scale.
1
28
Mr.PB retweeted
May 5
是Desire让生命与众不同。这是只有人类作为主体才有的东西。欲望与智能是解耦,智能让世界被收敛,欲望让世界弥散,这也是碳基生命作为地球online的特殊使命,硅基目前形成机制不足。
1
275

May 5
中转站行业迎来了底层理论支撑...

在五道口看了几百家AI创业公司
大家做的其实都是一件事,在想象和抢占 AI 时代的入口。
企图像上个时代的移动互联网一样,像 Google 一样抢夺搜索的入口,像抖音一样抢夺注意力的入口。
于是有了 AI 眼镜、有了 AI 录音笔、AI 录音豆、AI 戒指等各种各样能够记录文字、存储语料的设备。
在很长时间里,我也曾认为投资人高瞻远瞩,觉得他们说的都是对的,并且深以为然,
但又始终感觉不得究竟。现在终于想明白了。
AI 软件的核心并不是"入口",也不是其他的任何东西
有且仅有 "Token"。
一切围绕着 Token 来,一切围绕着 Token 展开,理解了 Token 才算对 AI 有了入门的理解。
在 AI 时代只存在两个问题,造 Token 和卖 Token。
为了把 token 消耗得更快、卖得更快,所以有了 Agent 长时间执行任务。
为了把 token 卖得更贵,所以做软件提供各种各样的服务,从而给 Token 更高的附加值,能让自己这个分销 Token 分销商卖的价格更贵。
因为别人用其他地方的 Token 实现不了他的任务,只有用你的 Token 能够实现他的目标。
如果从"入口"、从"应用场景"、从"细分行业"来看AI,会发现一团乱麻,无比复杂,但又不触及本质。
但当你把视角转向token的时候。会发现这个行业无比简单,整个产业链无非就是造 Token 和卖 Token 这两件事情罢了。
一旦从经济的角度、利益的角度、沿着token 生产制造的角度来去思考,就会发现一切都很清晰。
从 token 生产、到分销的这个过程上,谁赚钱,谁赚的分别是什么钱。整个过程、所有行业变得无比简单。并且能够一眼看出哪些创业方向一定会死
---
这也是毛选里面最牛逼的方法 ,我也是偶然才发现两者的相似之处
为了完全的讲清楚,请一定花一点时间,顺着我的思路,了解一下这位清朝猛男毛泽东是怎么分析问题并且找到关键杠杆点的
现在可以把自己带入1920年的中国
1920年代的中国,跟今天的AI行业一样——所有聪明人都在分析中国的出路,每个人都有一套理论,但越分析越乱,谁也说服不了谁。
鲁迅说根本问题是文化问题,说国民性有问题,有奴性,要唤醒民众。
康有说根本问题是道德,说三纲五常没了,要恢复礼教。
梁启超说根本问题是教育,说民智未开,要办报启蒙。
张謇说根本问题是实业,说没有工业,要办工厂
孙中山说根本问题是政治制度,说帝制腐朽,要搞共和。
当时远不止这六个角度,六套理论,每一个都能自圆其说,但每一个都只照亮了局部,拼不出全貌。
---
毛泽东牛逼的地方就牛逼在分析的维度完全不是一个层级
这六个人分析的东西——文化、道德、制度、教育——都是"上层"的东西。它们重不重要?重要。但它们都有一个特点:去掉它们,人照样活。
这六个人分析的东西——文化、道德、制度、教育——都是"上层"的东西。
它们有一个共同的特点:去掉它们,人照样活。
没有好的制度,人还是要吃饭。
没有新文化,人还是要吃饭。
制度可以崩溃,
文化可以断裂,
道德可以沦丧,
但只要人活着,他就要吃饭,就要争夺让自己活下去的资源。
毛泽东找到的就是这个去掉所有东西之后还剩下的那个东西:经济利益。
鲁迅看到的"国民劣根性",往下挖一层,是穷。人穷到只能顾眼前一口饭,自然就麻木了。
康有为看到的"道德沦丧",往下挖一层,是利益格局变了,旧秩序养不活人了,人当然不守旧规矩。
孙中山看到的"制度不行",往下挖一层,还是利益——军阀不听国会的,不是制度设计得不好,是他的经济利益不需要国会。
这些人看到的都是症状,毛泽东看到的是最底层的驱动力。今天有个时髦的说法叫"第一性原理"——把表面的东西一层层剥掉,找到最底下那个不可再分的东西。
经济利益关系,就是当时社会那个不可再分的东西。
从它出发,地主靠收租活着,他一定反对土地革命,跟他有没有道德没关系。贫农一无所有,他一定支持变革,跟他有没有文化没关系。
---
今天的AI行业,一模一样。
有人说自己项目牛逼是因为在抢占AI入口,我叫做"入口论"
把AI按"用户从哪接触AI"划分,
做眼镜的说眼镜是入口,
做耳机的说耳机是入口。
有人说自己项目牛逼是因为深入结合了场景,我把他叫做"场景论"
按"用在什么地方"划分,
做法律的说法律 AI是金矿,
做医疗的说医疗 AI是刚需。
有人说自己项目牛逼是因为AI给行业赋能,我把他叫做"行业论"
行业论按"改造哪个行业"划分,每家都说自己是某行业AI化的领头羊。
同理:技术论按"谁的模型更强"划分,谁参数大推理快谁就赢。
人性论按"满足什么需求"划分,做AI女友的说自己抓住了人性底层。
平台论按"谁能成为生态"划分,每家都想做AI时代的iOS。
数据论按"谁的数据多"划分,都在搞数据飞轮、数据壁垒。
无数种切法,无数套理论,每一种都有道理,每一种又都不是全貌。跟一百年前一模一样。
这些论分析的——入口、场景、行业、技术——也全是"上层"的东西。去掉它们,AI照样运转。
没有眼镜这个入口,AI还是要跑推理。
没有"教育"这个场景标签,AI回答一道数学题消耗的算力一分不少。
把所有入口、场景、行业分类全部拿掉,剩下的那个最基本的事实是什么?
一段文本进去,一段文本出来。每一次进出,消耗token,产生成本,创造价值。
这就是AI行业那个不可再分的东西。
入口论往下挖一层,争的是token消耗的渠道。
场景论往下挖一层,争的是token的附加值——同样的token,闲聊值一分钱,法律咨询值一块钱,医疗诊断值十块钱。
技术论往下挖一层,争的是token的生产效率。
平台论往下挖一层,争的是token分销的垄断权。
这些论看到的都是上层的竞争,token才是底下那个最根本的东西。
毛泽东面对几亿人、上百种矛盾的中国,找到了一把钥匙:土地。
谁有地谁没地,决定了一个人怎么吃饭、怎么站队、怎么行动。沿着这条线一捋,几亿人分成了几个清清楚楚的阵营。
AI行业今天几千家公司、几十个赛道,也有一把钥匙:token。
谁造token,谁卖token,决定了一家公司怎么赚钱、什么位置、什么命运。
所有和AI相关的公司,要么是token的生产商,要么是token的分销商,仅此而已
1
35

在五道口看了几百家AI创业公司
大家做的其实都是一件事,在想象和抢占 AI 时代的入口。
企图像上个时代的移动互联网一样,像 Google 一样抢夺搜索的入口,像抖音一样抢夺注意力的入口。
于是有了 AI 眼镜、有了 AI 录音笔、AI 录音豆、AI 戒指等各种各样能够记录文字、存储语料的设备。
在很长时间里,我也曾认为投资人高瞻远瞩,觉得他们说的都是对的,并且深以为然,
但又始终感觉不得究竟。现在终于想明白了。
AI 软件的核心并不是"入口",也不是其他的任何东西
有且仅有 "Token"。
一切围绕着 Token 来,一切围绕着 Token 展开,理解了 Token 才算对 AI 有了入门的理解。
在 AI 时代只存在两个问题,造 Token 和卖 Token。
为了把 token 消耗得更快、卖得更快,所以有了 Agent 长时间执行任务。
为了把 token 卖得更贵,所以做软件提供各种各样的服务,从而给 Token 更高的附加值,能让自己这个分销 Token 分销商卖的价格更贵。
因为别人用其他地方的 Token 实现不了他的任务,只有用你的 Token 能够实现他的目标。
如果从"入口"、从"应用场景"、从"细分行业"来看AI,会发现一团乱麻,无比复杂,但又不触及本质。
但当你把视角转向token的时候。会发现这个行业无比简单,整个产业链无非就是造 Token 和卖 Token 这两件事情罢了。
一旦从经济的角度、利益的角度、沿着token 生产制造的角度来去思考,就会发现一切都很清晰。
从 token 生产、到分销的这个过程上,谁赚钱,谁赚的分别是什么钱。整个过程、所有行业变得无比简单。并且能够一眼看出哪些创业方向一定会死
---
这也是毛选里面最牛逼的方法 ,我也是偶然才发现两者的相似之处
为了完全的讲清楚,请一定花一点时间,顺着我的思路,了解一下这位清朝猛男毛泽东是怎么分析问题并且找到关键杠杆点的
现在可以把自己带入1920年的中国
1920年代的中国,跟今天的AI行业一样——所有聪明人都在分析中国的出路,每个人都有一套理论,但越分析越乱,谁也说服不了谁。
鲁迅说根本问题是文化问题,说国民性有问题,有奴性,要唤醒民众。
康有说根本问题是道德,说三纲五常没了,要恢复礼教。
梁启超说根本问题是教育,说民智未开,要办报启蒙。
张謇说根本问题是实业,说没有工业,要办工厂
孙中山说根本问题是政治制度,说帝制腐朽,要搞共和。
当时远不止这六个角度,六套理论,每一个都能自圆其说,但每一个都只照亮了局部,拼不出全貌。
---
毛泽东牛逼的地方就牛逼在分析的维度完全不是一个层级
这六个人分析的东西——文化、道德、制度、教育——都是"上层"的东西。它们重不重要?重要。但它们都有一个特点:去掉它们,人照样活。
这六个人分析的东西——文化、道德、制度、教育——都是"上层"的东西。
它们有一个共同的特点:去掉它们,人照样活。
没有好的制度,人还是要吃饭。
没有新文化,人还是要吃饭。
制度可以崩溃,
文化可以断裂,
道德可以沦丧,
但只要人活着,他就要吃饭,就要争夺让自己活下去的资源。
毛泽东找到的就是这个去掉所有东西之后还剩下的那个东西:经济利益。
鲁迅看到的"国民劣根性",往下挖一层,是穷。人穷到只能顾眼前一口饭,自然就麻木了。
康有为看到的"道德沦丧",往下挖一层,是利益格局变了,旧秩序养不活人了,人当然不守旧规矩。
孙中山看到的"制度不行",往下挖一层,还是利益——军阀不听国会的,不是制度设计得不好,是他的经济利益不需要国会。
这些人看到的都是症状,毛泽东看到的是最底层的驱动力。今天有个时髦的说法叫"第一性原理"——把表面的东西一层层剥掉,找到最底下那个不可再分的东西。
经济利益关系,就是当时社会那个不可再分的东西。
从它出发,地主靠收租活着,他一定反对土地革命,跟他有没有道德没关系。贫农一无所有,他一定支持变革,跟他有没有文化没关系。
---
今天的AI行业,一模一样。
有人说自己项目牛逼是因为在抢占AI入口,我叫做"入口论"
把AI按"用户从哪接触AI"划分,
做眼镜的说眼镜是入口,
做耳机的说耳机是入口。
有人说自己项目牛逼是因为深入结合了场景,我把他叫做"场景论"
按"用在什么地方"划分,
做法律的说法律 AI是金矿,
做医疗的说医疗 AI是刚需。
有人说自己项目牛逼是因为AI给行业赋能,我把他叫做"行业论"
行业论按"改造哪个行业"划分,每家都说自己是某行业AI化的领头羊。
同理:技术论按"谁的模型更强"划分,谁参数大推理快谁就赢。
人性论按"满足什么需求"划分,做AI女友的说自己抓住了人性底层。
平台论按"谁能成为生态"划分,每家都想做AI时代的iOS。
数据论按"谁的数据多"划分,都在搞数据飞轮、数据壁垒。
无数种切法,无数套理论,每一种都有道理,每一种又都不是全貌。跟一百年前一模一样。
这些论分析的——入口、场景、行业、技术——也全是"上层"的东西。去掉它们,AI照样运转。
没有眼镜这个入口,AI还是要跑推理。
没有"教育"这个场景标签,AI回答一道数学题消耗的算力一分不少。
把所有入口、场景、行业分类全部拿掉,剩下的那个最基本的事实是什么?
一段文本进去,一段文本出来。每一次进出,消耗token,产生成本,创造价值。
这就是AI行业那个不可再分的东西。
入口论往下挖一层,争的是token消耗的渠道。
场景论往下挖一层,争的是token的附加值——同样的token,闲聊值一分钱,法律咨询值一块钱,医疗诊断值十块钱。
技术论往下挖一层,争的是token的生产效率。
平台论往下挖一层,争的是token分销的垄断权。
这些论看到的都是上层的竞争,token才是底下那个最根本的东西。
毛泽东面对几亿人、上百种矛盾的中国,找到了一把钥匙:土地。
谁有地谁没地,决定了一个人怎么吃饭、怎么站队、怎么行动。沿着这条线一捋,几亿人分成了几个清清楚楚的阵营。
AI行业今天几千家公司、几十个赛道,也有一把钥匙:token。
谁造token,谁卖token,决定了一家公司怎么赚钱、什么位置、什么命运。
所有和AI相关的公司,要么是token的生产商,要么是token的分销商,仅此而已
53
59
306
58,313