
32 Photos and videos











Pinned Tweet

28 Jul 2023
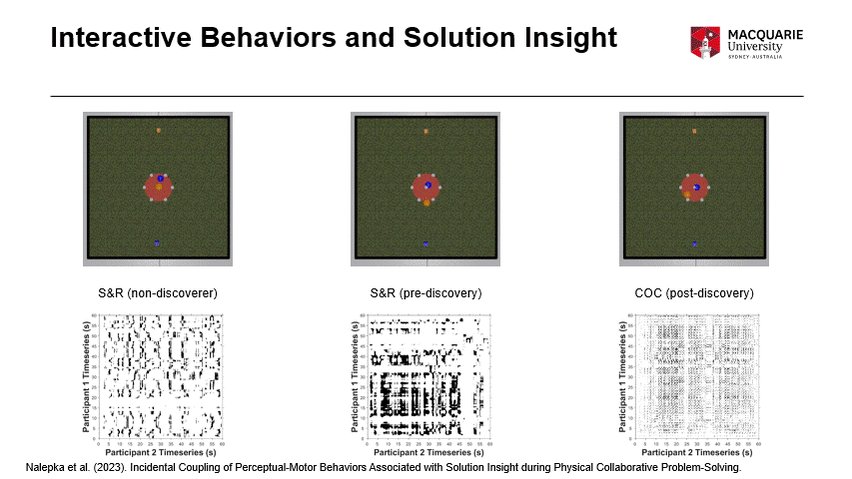
Today at #CogSci2023, I'll be presenting my #SocialVR work investigating the interactive behaviors that scaffold collaborative solution insight, using our social 'shepherding' game, and quantified using multidimensional recurrence analyses escholarship.org/uc/item/1nr…
1
2
15
2,194
Patrick Nalepka retweeted

27 Jul 2025
We're thrilled to release & open-source Hunyuan3D World Model 1.0! This model enables you to generate immersive, explorable, and interactive 3D worlds from just a sentence or an image.
It's the industry's first open-source 3D world generation model, compatible with CG pipelines for full editability & simulation. Set to transform game development, VR, digital content creation and so on. Get started now👇🏻
Project Page:3d-models.hunyuan.tencent.co…
Try it now:3d.hunyuan.tencent.com/scene…
Github:github.com/Tencent-Hunyuan/H…
Hugging Face:huggingface.co/tencent/Hunyu…
176
569
3,345
1,230,043
Patrick Nalepka retweeted

17 May 2024
We deployed 100 deep RL cruise controllers into rush-hour highway traffic to smooth traffic flow and reduce everyone’s energy consumption. Our AVs were decentralized and used standard radar, making our controllers deployable on most cars
1/n
9
25
220
35,362
Patrick Nalepka retweeted

4 Apr 2024
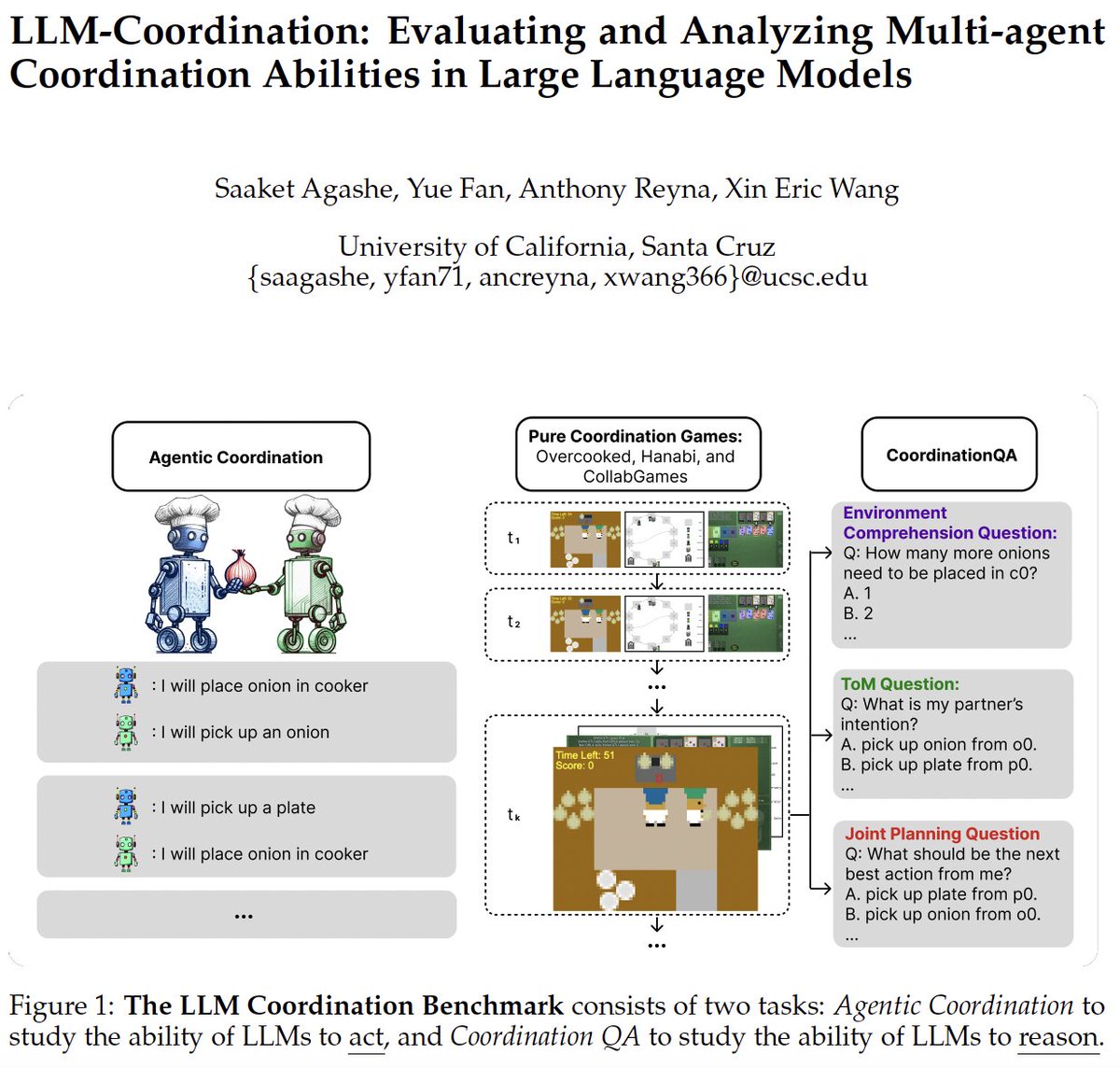
🔮Demystifying Coordination in #LLMs: We are excited to announce LLM-Coordination, a new benchmark for the evaluation and analysis of #LLMs in Multi-agent coordination tasks.
Our benchmark studies two task settings:
1. 🤖 Agentic Coordination, where LLMs act as proactive participants for cooperation in 4 pure coordination games;
2. ❓Coordination Question Answering (CoordQA), where LLMs are prompted to answer questions from coordination games for evaluation of three key reasoning abilities: Environment Comprehension, #ToM Reasoning, and Joint Planning.
Interestingly, we find that LLM agents excel at coordination games where the primary challenge is common-sense reasoning about the environment 🌎 and following the rules of the game.
However, they struggle at games requiring an advanced Theory Of Mind🤔 #ToM, which is the ability to reason about the beliefs and intentions of their partners!
Keep Reading 🧵 for the details and discoveries!
Website: eric-ai-lab.github.io/llm_co…
📜paper: arxiv.org/abs/2310.03903
🔗data & code: github.com/eric-ai-lab/llm_c…
2
15
38
23,142
Patrick Nalepka retweeted

19 Apr 2024
Wrenching news: Dan Dennett has died.
He's been a great friend and incredible inspiration for me throughout my career. I will miss him enormously.
dailynous.com/2024/04/19/dan…
34
172
1,049
108,468
Patrick Nalepka retweeted

17 Apr 2024
It’s amazing how many empirical features of interactions and collective response can emerge from a simple imperative: to minimize surprise. Out today in PNAS @PNASNews - with @conorheins @richardpmann Karl Friston and colleagues! @CBehav @maxplanckpress pnas.org/doi/10.1073/pnas.23…
7
109
403
68,388
Patrick Nalepka retweeted

Excited by our new perspective piece! 😊
Why is it that not all social engagement consistently increases inter-brain synchrony? Irruption theory predicts that more subjective involvement increases interference. Next step: experimentally test this idea! frontiersin.org/articles/10.…
3
16
37
3,965
Patrick Nalepka retweeted

26 Feb 2024
I am really excited to reveal what @GoogleDeepMind's Open Endedness Team has been up to 🚀. We introduce Genie 🧞, a foundation world model trained exclusively from Internet videos that can generate an endless variety of action-controllable 2D worlds given image prompts.
132
539
2,400
833,071
Patrick Nalepka retweeted

7 Feb 2024
Foundation models are well-established in vision and language, but time series forecasting has lagged behind - it still relies on dataset-specific models.
Meet Lag-Llama: the first open-source foundation model for time series forecasting!

28
168
700
142,494
Patrick Nalepka retweeted

29 Jan 2024
what's happening 👇

12
21
124
22,593
Patrick Nalepka retweeted

18 Dec 2023
New paper from @ThaliaWheatley, me, @StolkArjen & @lukejchang at Perspectives on Psychological Science!
"The Emerging Science of Interacting Minds"
Read about why we think that this is a particularly auspicious moment for interaction science!
Link: journals.sagepub.com/doi/10.…

5
83
279
37,054
Patrick Nalepka retweeted

14 Dec 2023
Together with the Ego4D consortium, today we're releasing Ego-Exo4D, the largest ever public dataset of its kind to support research on video learning & multimodal perception — including 1,400 hours of videos of skilled human activities.
Download ➡️ bit.ly/3teP49w
24
232
1,188
260,350
Patrick Nalepka retweeted

22 Nov 2023
Autocurricula can produce more general agents...but can be expensive to run 💸.
Today, we're releasing minimax, a JAX library for RL autocurricula with 120x faster baselines. Runs that took 1 week now take < 3 hours.
Paper: arxiv.org/abs/2311.12716
github.com/facebookresearch/…
5
78
454
139,290
Patrick Nalepka retweeted

22 Nov 2023
📢Just published! Our new paper looks at some of the processes people use to hear and be heard when (mis)communicating in noise 🗣️🔊Spoiler: adapt and coordinate! #CommunicationDifficulty #CommunicationBreakdowns
nature.com/articles/s41598-0…
1
5
22
1,460
Patrick Nalepka retweeted

20 Oct 2023
Announcing Habitat 3.0, simulating humanoid avatars and robots collaborating!
- Humanoid sim: diverse skinned avatars
- Human-in-the-loop control: mouse/keyboard or VR
- Tasks: social navigation and rearrangement
Over 1,000 steps per second on 1 GPU for large-scale learning!
8
87
478
261,453
Patrick Nalepka retweeted

12 Oct 2023
Interested in #OpenScience, machine learning, motion tracking, and/or (social) signal processing? envisionbox.org has officially launched! 🚀
This is a community-driven platform for learning and sharing methods, with everything open-source (using R and Python).
1
18
35
5,086
Patrick Nalepka retweeted

13 Aug 2023
RIP to Dr. Michael Turvey… an intellectual pioneer and wonderful mentor to so many. echovita.com/us/obituaries/c…
2
31
61
30,837
Patrick Nalepka retweeted

1 Aug 2023
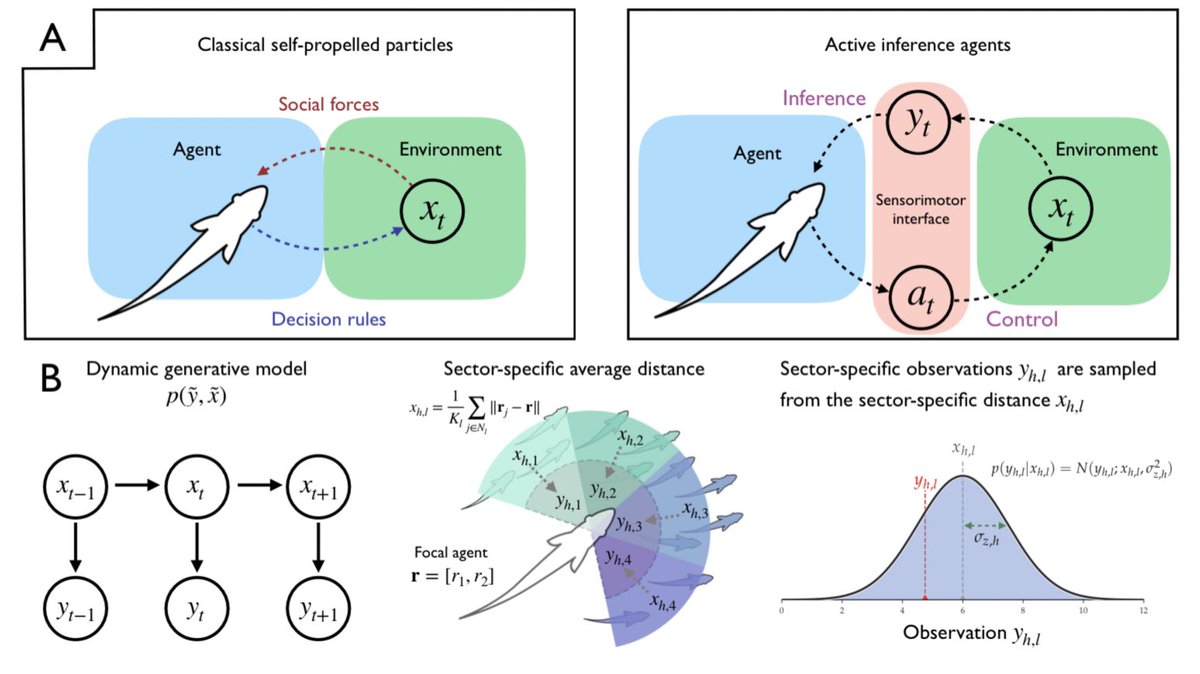
Collective Behavior from Surprise Minimization arxiv.org/abs/2307.14804 —🍿 @icouzin meets Friston! cc @C4computation
1
39
154
16,203
28 Jul 2023
Today at #CogSci2023, I'll be presenting my #SocialVR work investigating the interactive behaviors that scaffold collaborative solution insight, using our social 'shepherding' game, and quantified using multidimensional recurrence analyses escholarship.org/uc/item/1nr…
1
2
15
2,194
28 Jul 2023
The talk is titled "Incidental Coupling of Perceptual-Motor Behaviors Associated with Solution Insight during Physical Collaborative Problem-Solving" and will be presented in the "Groups and Cooperation" track which starts at 1:50pm!
1
1
81
28 Jul 2023
Here is a visual summary. Squares = player hand movements; Spheres = player gaze; white spheres = the sheep that are trying to escape!
1
64