
Co-founder & CEO of @streamnativeio | @apache_pulsar, @asfbookkeeper. In a previous life: @streamlio @twitter @yahoo
Joined April 2008
- Tweets 1,552
- Following 450
- Followers 1,343
- Likes 1,881
109 Photos and videos







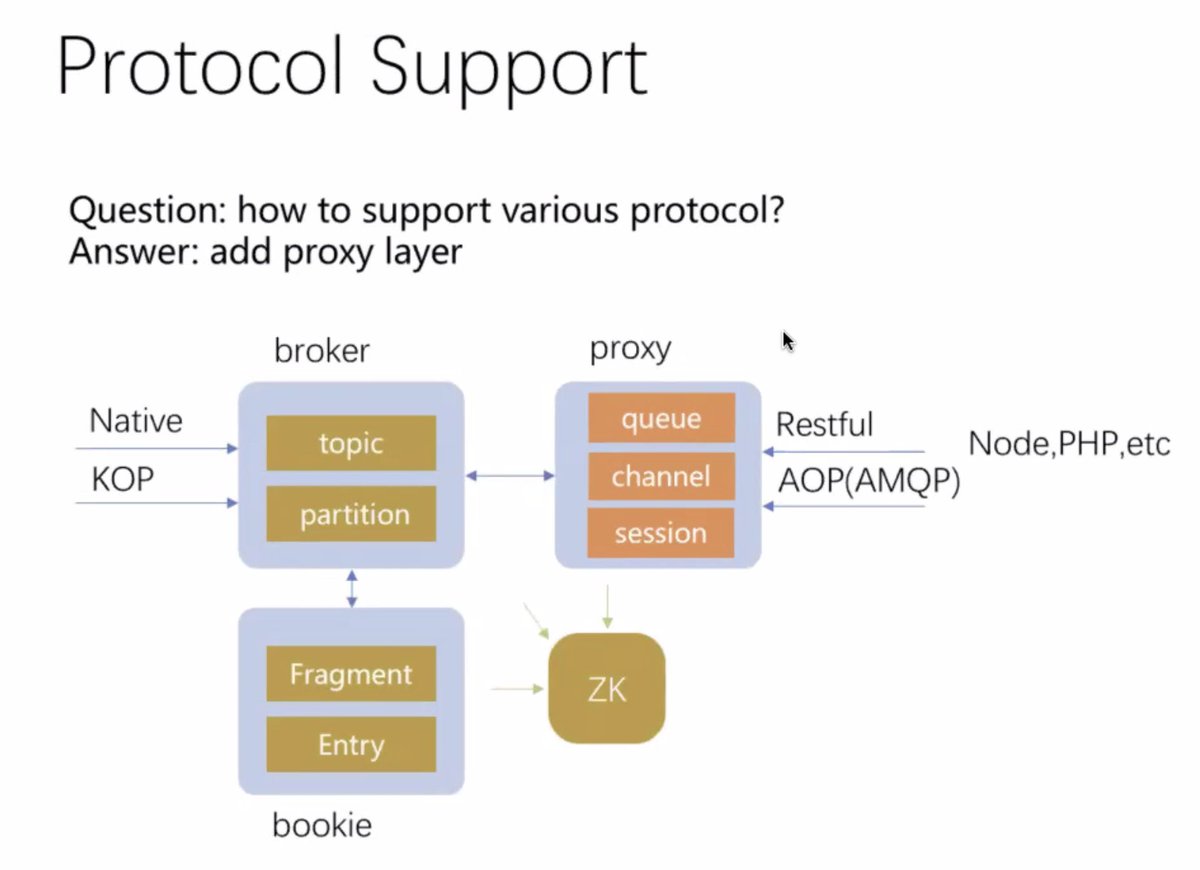
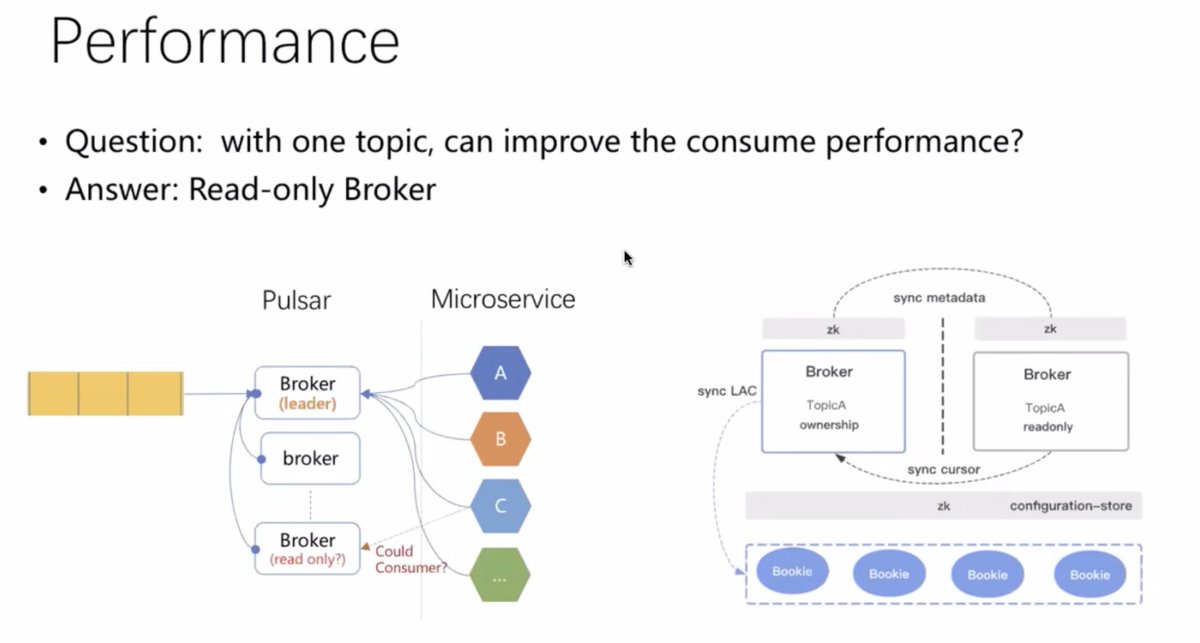
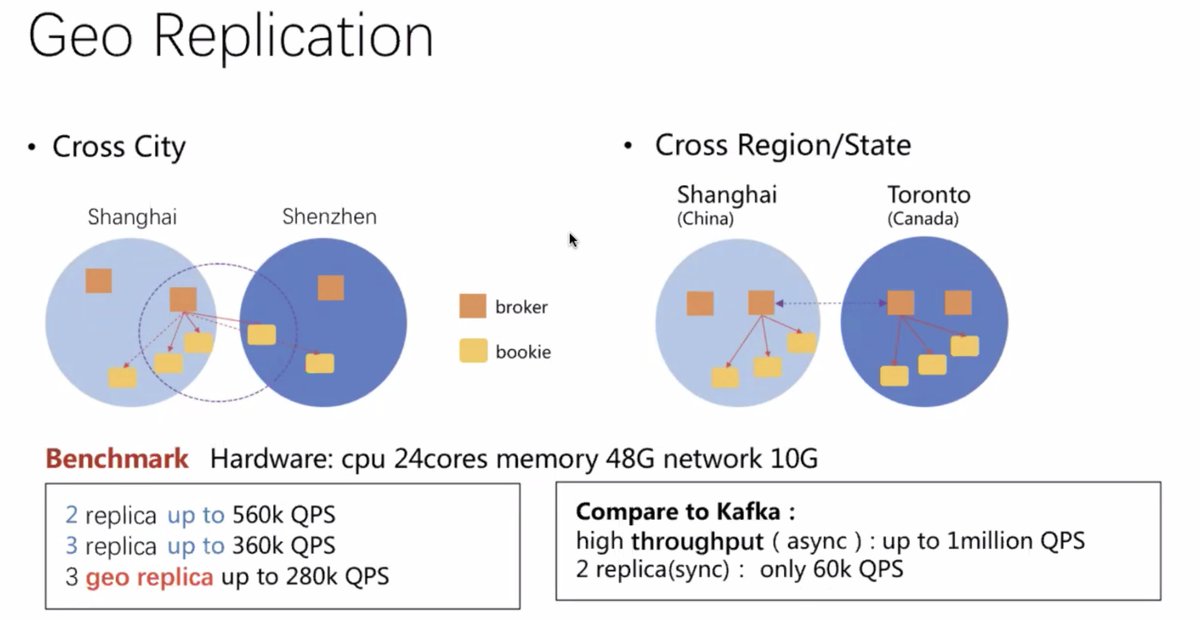

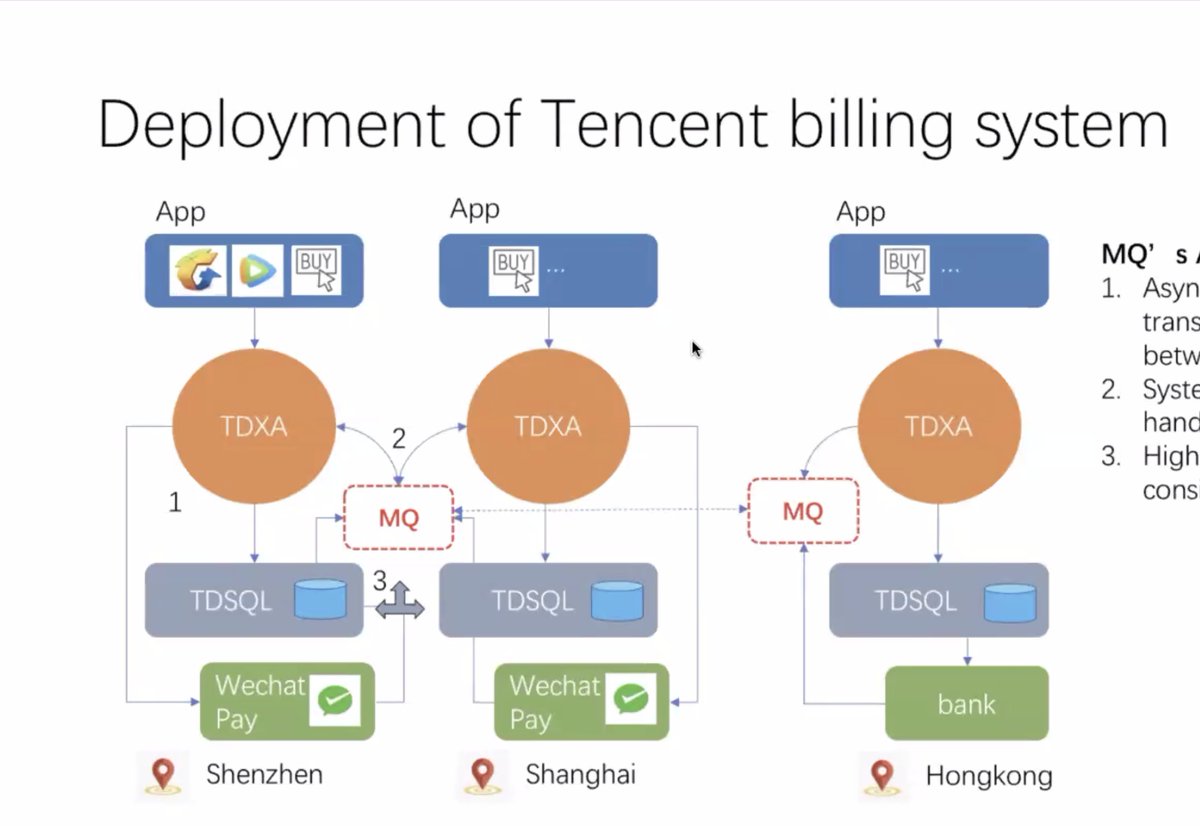

2
1
386
Last week Snowflake launched Datastream — Kafka-compatible streaming built directly into the platform. To me that's a strong signal: the industry now agrees streaming and the lakehouse belong together, especially for AI agents that need to act on fresh data.
That convergence is exactly the shift we've been building toward. We call it - #Lakestream.
AI agents can't act on yesterday's data. They need the latest events — seconds old — sitting next to the full history that gives them meaning, governed enough to trust. That's real-time context, and it's what the classic two-system setup — streaming on one side, the lakehouse on the other, pipelines in between — was never designed to deliver.
A Lakestream unifies the two, end to end on open standards. You produce and consume the live stream through the Kafka API, and you query that same data as an open Apache Iceberg table from any engine. One stream, written once — a low-latency event stream and an open table at the same time. The log that backs the stream is the table, one copy serving the present and the past at once.
The lakehouse merged the lake and the warehouse. The #Lakestream does it one step earlier in the data's life: it merges the stream and the lakehouse — and keeps both sides open.
We wrote up the full thesis 👇
streamnative.io/blog/what-is…
1
2
97
Data Streaming Summit (organized by @streamnativeio) back. October 7–8, San Francisco. 🎉
Same hardcore, community-first conference we've always run. Same room full of practitioners running real-time data infrastructure at real scale. Same bias toward production numbers over keynote theater.
What's new: we're adding two tracks for the era we're actually living in.
→ Data Streaming Engines — the foundation. Pulsar, Kafka, Ursa, Flink, diskless topics, leaderless logs, lakehouse-native storage.
→ Data Streaming for Agents — the bridge. Real-time context, durable memory, event-driven tool orchestration, agent observability.
→ Agent Harness, Runtime & Governance — the agentic layer. Managed Agents, Agent Executor, Deep Agents, and many in-house runtimes enterprises are quietly building.
Here's the thing: the agent community is running into problems data infrastructure engineers have been solving for a decade — durable state, event ordering, replayable history, observability at scale. They're building the same layer of the stack from opposite ends.
With Current now part of IBM, the case for an independent, practitioner-first venue matters more than ever. Same taste. Bigger scope.
CFP is open through June 30. If you're running this in production, come tell the story.
streamnative.io/blog/announc…
Happy Friday. Hope to see you in SF.
1
1
7
214
113
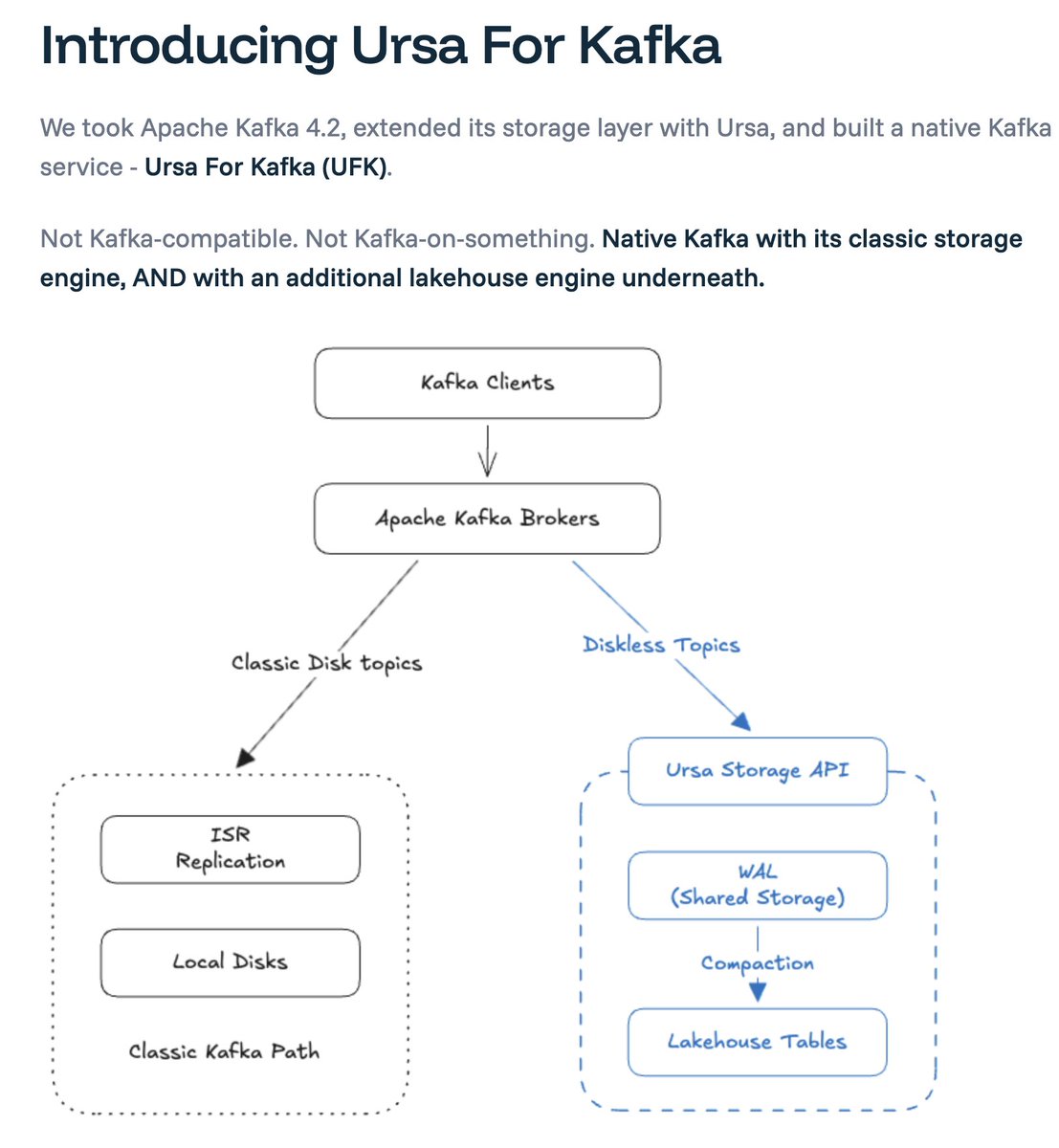
Six days ago I said we're a #Kafka company, too. Not an April Fools' joke.
Today: introducing #Lakestream — an architecture where streams are first-class lakehouse primitives alongside tables.
First proof point: a Native #ApacheKafka Service powered by #Ursa. Now in Limited Public Preview. 🧵
Apr 7

🚀 The Native Apache Kafka Service powered by Ursa is now in Limited Public Preview.
Apache Kafka 4.2 on Ursa. Every topic is a lakehouse table. Up to 95% lower TCO.
🌟 $1,000 credits with code UFK1000 (Apr 7–14).
👉 Sign up: hubs.ly/Q049R9Kr0
📖 Read the announcement: hubs.ly/Q049Rbkt0
#ApacheKafka #Lakestream #Lakehouse #Iceberg #RealTimeAnalytics

1
197
📢 "Wait — my Kafka topic IS a table?"
Yes. Streams and tables on the same open storage and catalog. Protocol is a choice of interface, not a choice of data silo.
Apache Kafka 4.2 fork on Ursa. Every client works, zero code changes. Up to 95% cost reduction at 5 GB/s throughput.
1
78
🤔 Joined the waitlist last week? Your access is live.
Didn't? Use code UFK1000 (Apr 7–15) for $1,000 in StreamNative Cloud credits.
🌊 The Lakestream story: streamnative.io/blog/from-st…
✨ Kafka announcement: streamnative.io/blog/ursa-fo…
🤝 Launch partners: streamnative.io/blog/announc…
44
Sijie retweeted

Apr 7
🚀 The Native Apache Kafka Service powered by Ursa is now in Limited Public Preview.
Apache Kafka 4.2 on Ursa. Every topic is a lakehouse table. Up to 95% lower TCO.
🌟 $1,000 credits with code UFK1000 (Apr 7–14).
👉 Sign up: hubs.ly/Q049R9Kr0
📖 Read the announcement: hubs.ly/Q049Rbkt0
#ApacheKafka #Lakestream #Lakehouse #Iceberg #RealTimeAnalytics
1
1
4
817
Sijie retweeted

👉 StreamNative is introducing a Kafka fork too!
One which adds an additional storage engine to Kafka (their proprietary Ursa engine).
This Kafka fork will feature Diskless Topics that store the data directly to S3 in an open-table format. Zero copy, kind of similar to Aiven's Iceberg Topics, but for Diskless.
Most importantly, they said they'll open source it! ⭐️
Some really good writing in there re: the power of the Kafka protocol. They also call it the TCP/IP of streaming (I expect a hat tip to Justin Manchester here just a few days after our podcast haha).
I'll record a more in-depth video on this announcement. Despite being bearish on the Kafka industry in terms of economic value, I'm starting to think we will see MORE acceleration in terms of things shipped in the space.
With coding harnesses like Claude Code massively boosting dev productivity, I expect that the bottleneck will become organizational structure.
The fastest-moving startup wins the feature war, essentially.
Just yesterday we had RedPanda ship their R1 engine also with adaptable topics (fast & expensive, slow & cheap, etc.).
💡 With this StreamNative UFK (Ursa for Kafka) announcement, we have three Kafka engines that support flexible topics - Aiven Inkless, RedPanda R1, StreamNative UFK.
Just a few months ago Aiven was the star child with the only such flexible engine. Competitors are catching up. 🔥
2
6
39
2,539
It's April 1st and I have an announcement:
@streamnativeio is a @apachekafka company now.
Yes, the Pulsar people. We took Apache Kafka 4.2 and gave it a lakehouse foundation. Topics = Iceberg tables. 10x cheaper. Zero code changes.
streamnative.io/blog/we-are-…
1
2
170
Just listened to Jay’s keynote at Current Summit London.
Unified batch and streaming? That’s old news. Snapshot queries? That’s just querying Iceberg tables… come on.
You can already do that with #Ursa by querying Ursa topics’ lakehouse tables using #Flink, #Spark, or any engine you like—no need to wait for Confluent’s snapshot query to GA.
Want to see it in action?
Stop by the StreamNative booth. We’ll show you how Ursa open source Flink gives you fast, flexible snapshot queries—today. #Current25
1
230
I just kicked off a new blog series on AI agents! First post tackles a pain point: chatbots powered by stale data and sit in silos. 🤖➡️🌊 How do we feed them real‑time streams and get them talking at scale?
Check it out & tell me what you think 👉 streamnative.io/blog/ai-agen…
1
5
216
Very excited to announce that @streamnativeio now integrates with @databricks Unity Catalog—the first & only data streaming engine to natively support it!
Seamlessly ingest streaming data into Delta Lake & Iceberg for real-time analytics with unified governance by Unity Catalog.
streamnative.io/blog/seamles…
#DataStreaming #UnityCatalog #Lakehouse #AI #RealTimeAnalytics #ApacheKafka #DeltaLake #ApacheIceberg
3 Feb 2025
StreamNative's Ursa Engine now integrates with @databricks Unity Catalog, bringing real-time streaming to the Lakehouse!
✅ Stream to Iceberg & Delta Lake
✅ Better data governance & AI workflows
✅ Faster, cost-effective real-time analytics
hubs.ly/Q0351NYT0
#RealTimeData #Databricks #Lakehouse #AI #Streaming

2
410
Sijie retweeted
3 Feb 2025
StreamNative's Ursa Engine now integrates with @databricks Unity Catalog, bringing real-time streaming to the Lakehouse!
✅ Stream to Iceberg & Delta Lake
✅ Better data governance & AI workflows
✅ Faster, cost-effective real-time analytics
hubs.ly/Q0351NYT0
#RealTimeData #Databricks #Lakehouse #AI #Streaming
7
9
1,495
Sijie retweeted
12 Dec 2024
🚀 Excited to announce our Technology Select Tier partnership with @SnowflakeDB
Together, we’re simplifying real-time analytics & AI:
✔️ Faster performance
✔️ Lower cloud costs
✔️ Scalable, streamlined architectures
Learn more: hubs.ly/Q02_rXR60
#DataStreaming #AI #Snowflake

1
1
210
While #BYOC has become increasingly popular, we've seen debates about which approach to BYOC is best. In our view, whether it's BYOC, Dedicated/Serverless, or self-managed, what organizations need is a Portable Data Plane. Checkout our blog post:
streamnative.io/blog/byoc2-p…
2
243
While "Shift-Left" is a hot topic in data strategies today, particularly for advancing real-time data streaming architectures, it's important to look at it within a broader context. We believe in a more holistic approach. In today’s data-driven world, Shift-Left alone isn’t enough. For a truly comprehensive strategy, you need to balance Shift-Left with other architectures like Lakehouses.
Data streaming is critical for real-time generative AI, but the real foundation for these applications lies in the combination of data streaming and lakehouses. This synergy is what we call the Streaming-Augmented Lakehouse (SAL)—akin to how Retrieval-Augmented Generation (RAG) enhances large language models (LLMs). Just as RAG augments AI, SAL enhances lakehouses with real-time streaming capabilities, creating a dynamic data ecosystem for real-time AI.
But let’s be clear: SAL is not just another Lambda Architecture. The essence of SAL is in its headless, multi-modality data storage that allows you to store one copy of data and present it as a stream or table depending on your use case. It moves ingestion and computation left, achieving low latency while ensuring data quality and governance. With SAL, businesses get the flexibility of multiple modalities (stream or table), protocols (Kafka or Pulsar), and semantics (competing queues vs. sequential streams) to meet diverse business needs.
In the AI age, the future of data strategy demands more. Businesses need a new data foundation that combines the real-time power of streaming with lakehouses. SAL is that foundation. It enables real-time data to continuously fuel AI systems while also managing the vast historical datasets required for training and improving models.
By adopting SAL, enterprises can bring real-time insights directly into their lakehouse architectures—acting on data as it arrives while maintaining governance, scalability, and deep analytics. We believe SAL is the key to unlocking the full potential of real-time Gen AI.
Curious to learn more? Check out our latest blog post! 👉 streamnative.io/blog/introdu…
And if you’re passionate about the latest trends in data streaming and AI, join us at the Data Streaming Summit on October 28-29 at the Grand Hyatt SFO. DM me if you’d like discounted tickets! eventbrite.com/e/data-stream…
#ApacheKafka #ApachePulsar #Lakehouses #ShiftLeft #StreamingAugmentedLakehouse #GenAI
1
263
6 years ago, I never imagined #ApachePulsar would grow into what it is today. From an idea to solve real-time data challenges to a thriving community project @apache_pulsar it’s been an incredible journey. 🙌 Grateful for everyone who's been a part of this! 🚀
👉 streamnative.io/blog/celebra…
2
9
439
Sad to hear that Upstash shut down its serverless Kafka service. If you're looking for an alternative, check out Serverless Kafka on @streamnativeio Cloud! Start with $200 in free credits—no credit card needed. Need more? DM me!
Learn more: streamnative.io/blog/introdu…

Hey friends, this tweet is an announcement to our Upstash Kafka users.
When we founded Upstash, we identified messaging and task scheduling as the next problems to solve after state management. Initially, we considered Kafka the ideal solution due to its power as a messaging platform.
This assumption seems correct as we've received positive feedback for our Kafka offering, and it's financially viable. However, we noticed significant friction for serverless developers using Kafka. Traditional message broker like Kafka is not well-adapted for the serverless use cases. This is why we had to make the difficult decision to halt new Kafka feature development to focus our resources on QStash and Upstash Workflow.
Existing users can continue using all platform features, including connectors and the schema registry as normal for the next six months. No immediate action is required because we recognize that a migration plan needs time. After the six month period, we plan to deprecate Upstash Kafka.
On the other hand, QStash and, recently, Upstash Workflow naturally evolved into tools specifically for serverless needs. To our surprise, we see an increasing number of customers use QStash for complex business logic orchestration, effectively using it as an alternative to Kafka.
This strategic shift allows us to focus on solutions specifically for serverless environments. By focusing our limited resources, we can invest more heavily into QStash and Upstash Workflow. Also, this decision allows us to improve our Redis and Vector offering to provide a more cohesive ecosystem of tools.
We want to be fully transparent about our intentions and want to make this transition as easy as possible for our Kafka users. If your Kafka use case can be covered with Upstash QStash, we will cover the entirety of your migration costs. If not, our professional support is always there to help with any of your questions.
We appreciate your trust in us and are excited about the future we're building. We believe these changes will ultimately allow us to provide you with a better, more focused solution optimized for serverless.
Read the full announcement here: upstash.com/blog/workflow-ka…
5
9
1,085