
Exploring LLMs | Data scientist with a curious engineering mind
Joined April 2013
- Tweets 122
- Following 679
- Followers 132
- Likes 128
16 Photos and videos






Pinned Tweet

31 Jul 2024
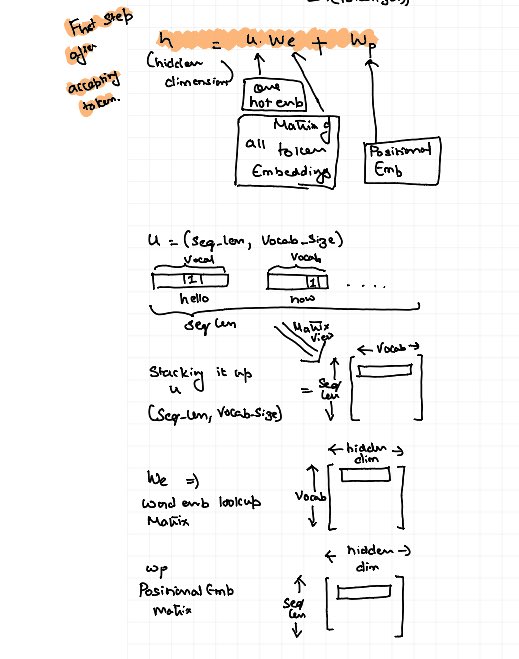
My recent blog with @hasgeek - “Decoding Llama3” is out.
It’s a deep dive into the Llama3 model code released in April this year. This is a fun blog with a code-first approach.
hasgeek.com/simrathanspal/th…

3
6
364
simrat hanspal retweeted

Jun 11
1. Diffusion Language Models
Language models do not always have to generate text one token at a time. Diffusion language models start with a masked sentence, predict many words in parallel, and refine them over multiple rounds. Models like LLaDA and Mercury are exploring a new path for text generation.
courses.vizuara.ai
2
11
423
11 Nov 2025
🫣 Softmax is unstable with very large and very small numbers.
🤓 Here is a simple illustration of how (x-max) makes softmax stable for use.



78
7 Nov 2025
What does it mean to have dropout in Attention computation?
Dropouts are used to prevent overfitting.
In case of attention, we drop some attention scores, which means that if the model learnt to attend to some token, it now has to focus on other related tokens.
#LLM #Attention
33
31 Oct 2025
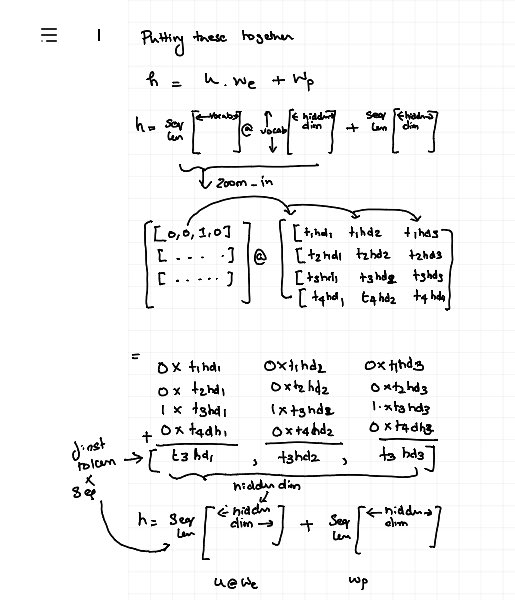
Simple illustration of what token to word embedding conversion looks like.
1
3
119
30 Oct 2025
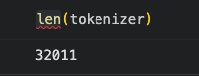
The tokeniser lies about how many tokens it holds ;)
What the tokeniser returns is the size of the base vocabulary that it learnt during training. Everything after that are special tokens.
Special tokens are like metadata and help structure context.
1
1
52
31 Oct 2025
So, you use len(tokenizer)
Not sure why colab is not recognising len() :D
32
28 Oct 2025
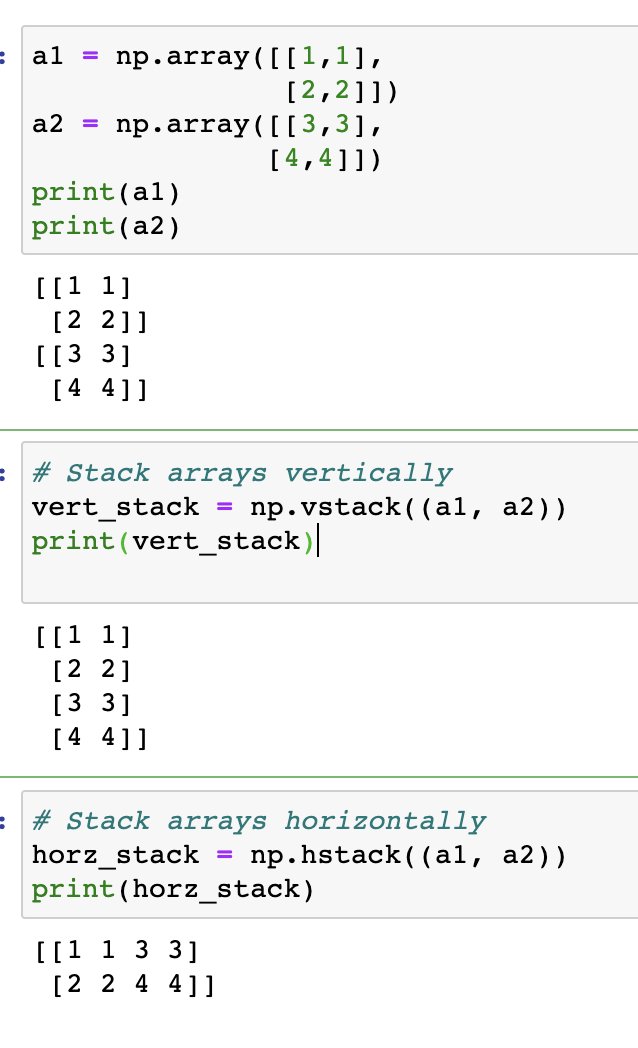
Trivial but worth a reminder use np.matmul for dot product instead of np. dot.
np. dot is meant to be a flexible function that will adjust according to the input shape, instead of raising an error.
Example np. dot(np.array([[1, 2], [3, 4]]), 10)
23
15 Jul 2024
Budding entrepreneur 🥹
I purchased more than I planned.
15 Jul 2024

And also assisting madame in coordinating logistics and order shipping the day after #fifthel
@jackerhack @_waabi_saabi_
1
7
744
10 Jul 2024
Looking forward to it.

Tech x society enthusiasts, show up for The Fifth Elephant Annual Conference on 13th July!
I'll be hosting the session on Deploying AI in Key Sectors: Robust Risk Mitigation Strategies with @jnkhyati, @bargava, @simsimsandy & @fooobar
@fifthel @hasgeek @anthillin @zainabbawa

2
156
simrat hanspal retweeted

First, @simsimsandy walked us through GPU architecture, optimizations, CUDA, and the challenges of running large ML models on GPUs, with a special look at the attention mechanism, KV-Cache optimizations, and PagedAttention!


1
1
12
887
6 Jul 2024
Thank you for the shoutout @TheOtherRaghav. It was a lovely event. x.com/theotherraghav/status/…
3
286
28 Jun 2024
If you are into GenAI, @hasgeek is organizing a call today to build a community on #ResponsibleAI. Join for cross-learning.
🔗 Meeting Link: Register here to confirm your participation - lnkd.in/gFSt8bYc
🕰Time: 7 PM IST Friday, 28 June (tonight)
1
3
227
simrat hanspal retweeted

26 Jun 2024
🚀Join us in Chennai next week for our hands-on workshop: "Building AI Agents with RAG and Functions" 🤖✨
Limited seats available, so hurry and secure your spot! 🏃♂️💨
🔗 Register now: lu.ma/6lrnyo1b
#AIWorkshop #ChennaiEvents #llm #genai
1
5
7
1,762
22 Jun 2024
Thank you for the call out @zainabbawa :)
Best wishes to all the speakers at FifthEl 2024, looking forward to networking in person.
22 Jun 2024
.@simsimsandy introduced Bhumika Makwana @GalaxEyeSpace who will speak about multimodal fusion as the new game changer.
Reach out to Simrat for review and feedback on #nlp work, and for simplifying complex AI concepts. 3/5
1
2
240
15 May 2024
Really fun video on the basics - dot prd and inner prd.
Also, potentially a great resource on Quantum Mechanics #QuantumSense YT channel.
youtube.com/watch?v=3N2vN76E…
Inner product is an important concept for Rotary Positional Embedding, which is used by #LLM like #Llama3 (#Llama).
2
128
simrat hanspal retweeted

13 May 2024
Surprised how Twitter Influencers have got more insider informations and conclusions than anyone else!
Also, because Apple uses OpenAI means it couldn't make it on its own 🤦🏽
12
5
41
9,276
12 May 2024
Concise end-to-end #RAG tutorial by @jasonzhou1993
youtu.be/u5Vcrwpzoz8?si=kPwf…
This YouTube channel is a Gem with a lot of use case-based tutorials.
Check it out :)
#LLM #GenAI #AI
6
146
9 May 2024
I discovered fairscale today, PyTorch extension by Meta that helps you with distributed model training. Looks like #Llama3 used it.
github.com/facebookresearch/…
I am definitely going to be reading more about it.
Please drop in your thoughts if you have used it or read something.
1
121