
Founding DevRel @tessl_io. Java Champion, @virtualJUG founder. Previously VP DevRel @snyksec, ZeroTurnaround, @IBM, LJC co-leader.
Joined March 2009
- Tweets 23,361
- Following 959
- Followers 15,172
- Likes 9,729
1,380 Photos and videos







Simon Maple retweeted

Jun 10
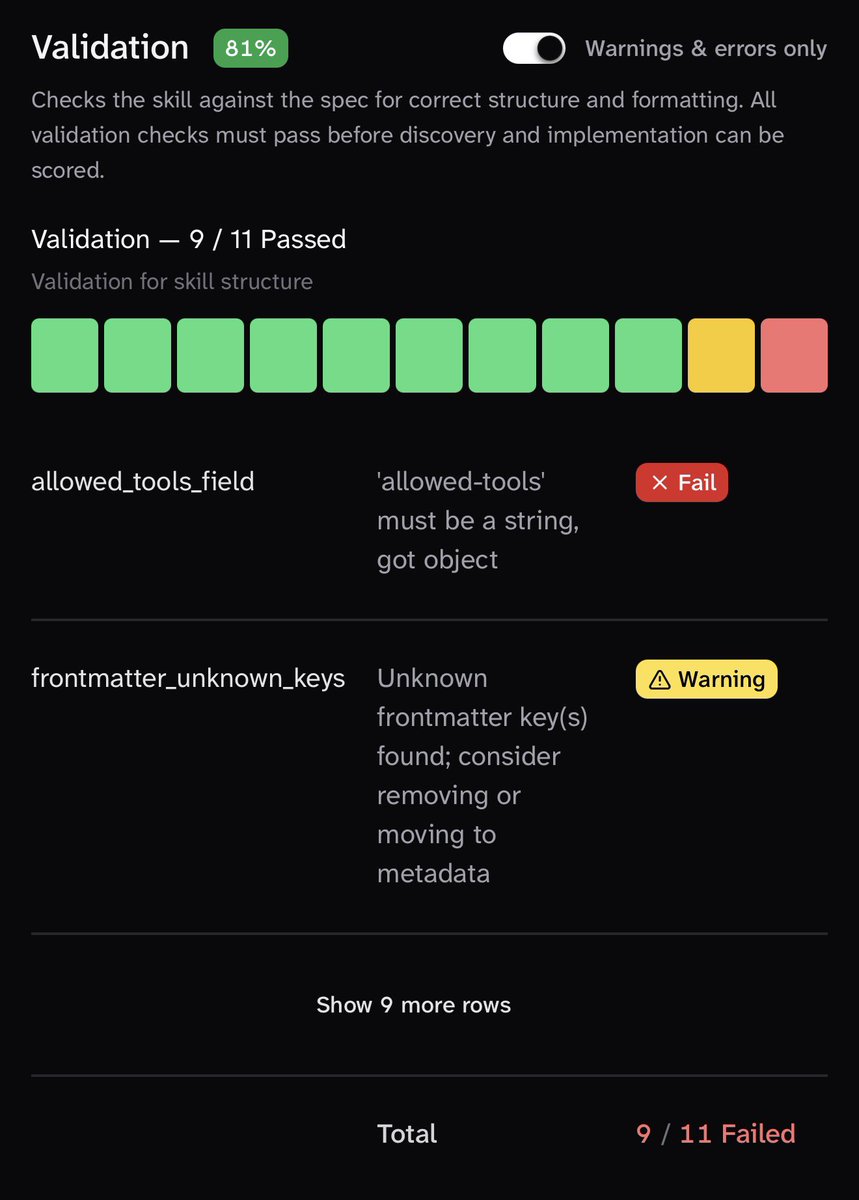
The most expensive model in the benchmark wasn't the best value.
Rob Willoughby and Simon Maple ( @sjmaple ) evaluated 19 model configurations on real agentic tasks and found that DeepSeek V4 Flash scored 82.3 while costing just $0.0236 per task. Claude Haiku 4.5 scored 82.9 at roughly four times the cost, while DeepSeek V4 Pro scored 85.3 at nearly eight times the cost.
The interesting part isn't that Flash beat stronger models. It didn't.
The interesting part is how little quality was gained for how much additional spend.
That becomes a very different conversation once you're running agents at scale. A model that looks marginally better on a benchmark can end up costing dramatically more over the course of a year, especially when agent workloads start growing.
The benchmark also surfaced something that many teams probably aren't measuring closely enough. The biggest performance jump didn't come from switching models. It came from adding the right skill. DeepSeek V4 Flash moved from 64.1 to 82.3 with skill context applied, which raises an uncomfortable question about how much of agent performance is actually model selection versus everything built around the model.
The full breakdown is worth reading, particularly the sections on points-per-dollar, turn counts, and why the cheapest model in the benchmark ended up being one of the most interesting.
Read the full blog here: tessl.io/blog/same-quality-a…
1
1
6
305
Simon Maple retweeted
Jun 10
Ryan Lopopolo tracked PR throughput on his OpenAI team from 3.5 per engineer per week up to 70 — not through adding headcount, but through iterating on the model and the harness together. Every revision of GPT-5 from 5.2 onward compounded on the last, and this clip shows exactly what that felt like from inside the team.
Watch the full episode at youtu.be/MFQIKbr1IEo or listen wherever you get your podcasts.
#AI
#agenticcoding
#claudecode
#codex
#AIskills
2
6
2,854
Simon Maple retweeted
Jun 5
Developers using AI tools are creating and merging twice as many pull requests — but AI-generated PRs have a 60/40 merge rate compared to 80/20 for humans. That gap reveals something important about how agents are actually being used in the wild: probing, experimenting, spawning throwaway work. Jellyfish's Nick Arcolano breaks down what the data actually says.
Watch the full episode at youtu.be/GbHfzFcIa0o or listen wherever you get your podcasts
#AI
#agenticcoding
#claudecode
#codex
#AIskills
2
2
479
Simon Maple retweeted

Jun 1

1
2
35
1,342
Simon Maple retweeted
Jun 1
AI Native DevCon is live.
After an opening keynote from Simon Maple ( @sjmaple ), Guy Podjarny ( @guypod ) has just taken the stage with "Skills are the New Code".
As software development shifts from writing instructions to defining intent, skills, specs, and context are becoming the core building blocks of modern engineering.
If you're building AI-native systems, this is exactly the conversation happening right now.
Can't join us in London? Watch live from anywhere:
youtube.com/watch?v=akZ85mG5…

2
6
667


Simon Maple retweeted
May 15
Your eval leaderboard can change completely depending on which model grades the answers.
Simon Maple ( @sjmaple ) reran the same benchmark suite using three different LLM judges: Sonnet, GPT-5.5, and Opus-4-7. Nothing else changed. The tasks, rubrics, scenarios, and model outputs were identical.
The scores were not.
One model moved by 47 points on a single skill depending on the judge. gpt-5.3 ranked near the top under Sonnet, then dropped sharply under GPT-5.5.
Opus consistently scored itself higher than the other judges did. GPT-5.5 turned out to be dramatically stricter overall, averaging almost 7 points lower than Sonnet across the benchmark.
What makes this especially interesting is that the instability wasn’t evenly distributed.
Tasks with concrete pass/fail conditions stayed relatively consistent across judges. But as soon as the rubric involved interpretation, structure, writing quality, or “best practices”, the variance widened fast. Two judges could look at the exact same output and disagree by double digits on whether the model had actually solved the task properly or just approximated it convincingly.
That has pretty major implications for how people read benchmark charts right now.
A lot of public evals are presented as if the number is objective, when in reality the scoring model itself is shaping the outcome. In some cases, the judge preference is large enough to reorder the leaderboard entirely.
The interesting exception was Opus. It stayed in first place regardless of which model acted as the judge. Everything below it shifted around.
Read the full breakdown here:
tessl.io/blog/your-benchmark…
1
3
446
Simon Maple retweeted
May 13
The problem is not that AI has not been trained... the problem is that AI has been trained A LOT.
@venkat_s shares his thoughts on "Accelerated Inference".
Watch the full episode at youtu.be/C0OeWkbhiL8 or wherever you get your podcasts. #AI
#agenticcoding
#claudecode
#codex
#AIskills
1
5
293
Simon Maple retweeted
May 13
We audit packages. We audit infra. We don’t audit the instructions shaping our AI agents.
That’s the problem tessl-audit is tackling.
In a new post, Simon Maple ( @sjmaple ) introduces an open-source CLI that scans the skills and plugins loaded into your agent’s context for security findings, quality issues, and actual task uplift.
Because agent skills are not just “extra context”. They directly influence how models reason, which patterns they follow, and what they decide to do.
The workflow is intentionally simple: npx tessl-audit
The tool reads your tessl.json, fetches registry data for installed skills, and produces a posture report showing risky plugins, weak guidance, and skills that have never been evaluated against real tasks.
What makes this interesting is how familiar the problem suddenly feels. AI agents are starting to develop their own dependency graphs, except the dependencies are prompts, policies, evals, and reasoning layers instead of libraries.
And unlike broken code, bad context often fails quietly.
The post also walks through optimizing low-quality skills, generating eval scenarios, and measuring whether a plugin genuinely improves agent performance before trusting it in production.
Read the full post here: tessl.io/blog/stop-trusting-…
1
5
297

May 8
I’m honestly not sure I could sleep on a pillow that was untitled… this would keep my mind too active #bedSHEETS
May 7


474
Simon Maple retweeted

May 6
Simon Maple’s ( @sjmaple ) benchmark (1,742 tests):
5.5 vs 5.4 → tied with skills (89.4 vs 89.3)
$0.49 vs $0.30 → 63% for 0.1
Only win: speed (89s vs 135s)
Read more here: dev.to/tessl/gpt-55-is-opena…
1
3
6
410
May 5
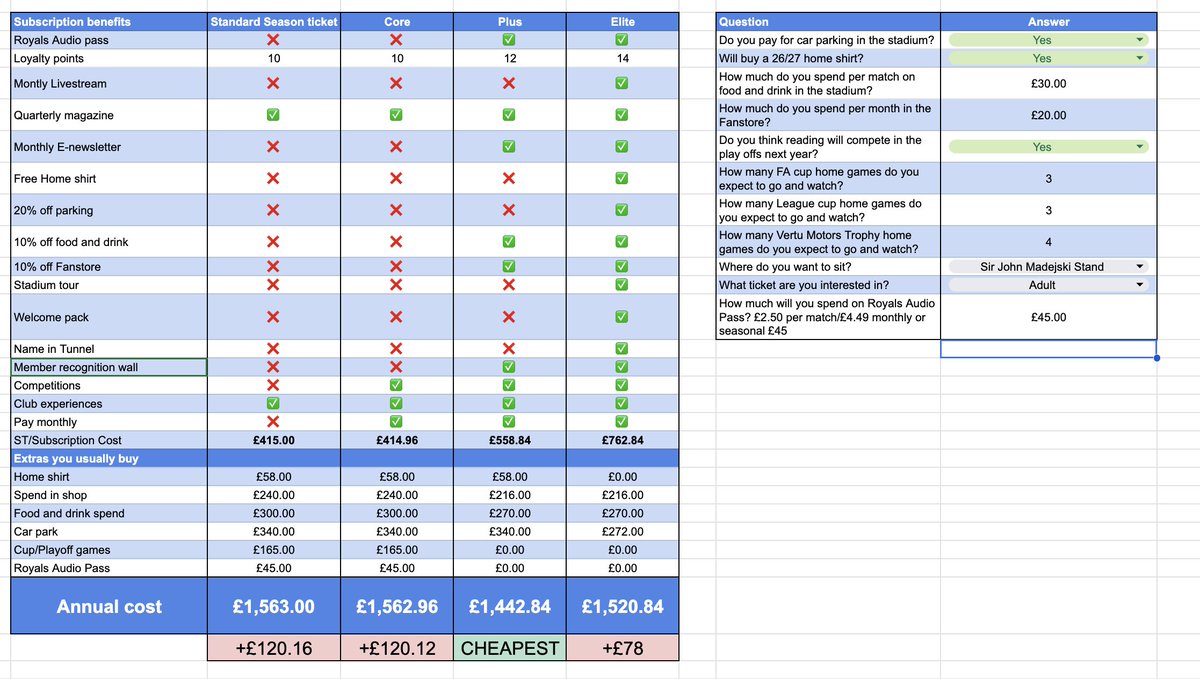
Hey #readingfc fans - here's a spreadsheet to work out whether subscription or season ticket is best for you. Copy the spreadsheet for yourself, answer questions in column H, and you'll get some idea of overall costs over the season for each subscription option in row 26!
I did this to help me, hope it helps others too :) Disclaimer, my sums may not add up.
docs.google.com/spreadsheets…
May be of interest @TalkReading @ReadingFC @RFCCommunity @RFC_Analysis @ElmParkRoyals
24
22
146
54,826
May 6
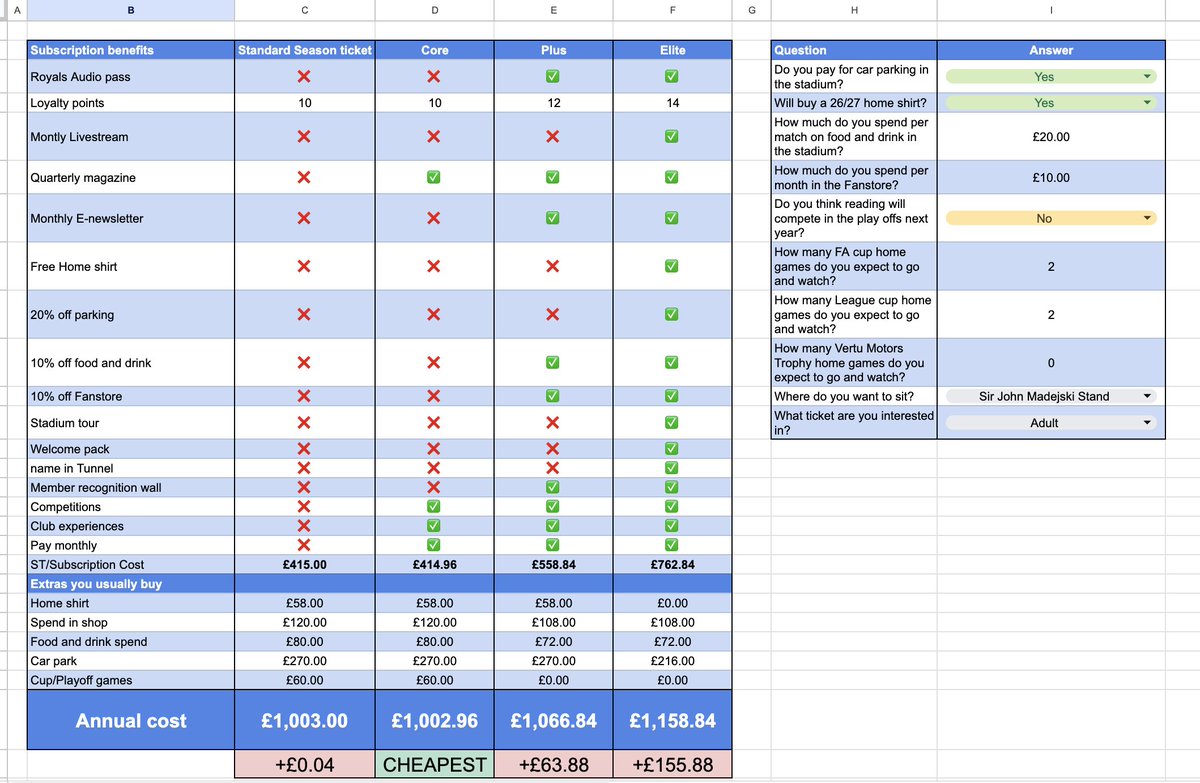
Updated this several times now - shows how many edge cases there are (but to be honest, I'm starting to like it) Fixes include.
- Food and drink discount was only counting cup games (massive update for plus and elite value) - thx @Paul_S_8
- Plus only has 1st cup games free, and home Vertu games free - thx @suemsymes02
- Audio pass value/question added in which reflects in price - thx @ElmParkRoyals
If you've already tried this, I'd heavily recommend doing it again to see the new figures! Pls keep giving feedback!
1
1
1,257
May 5
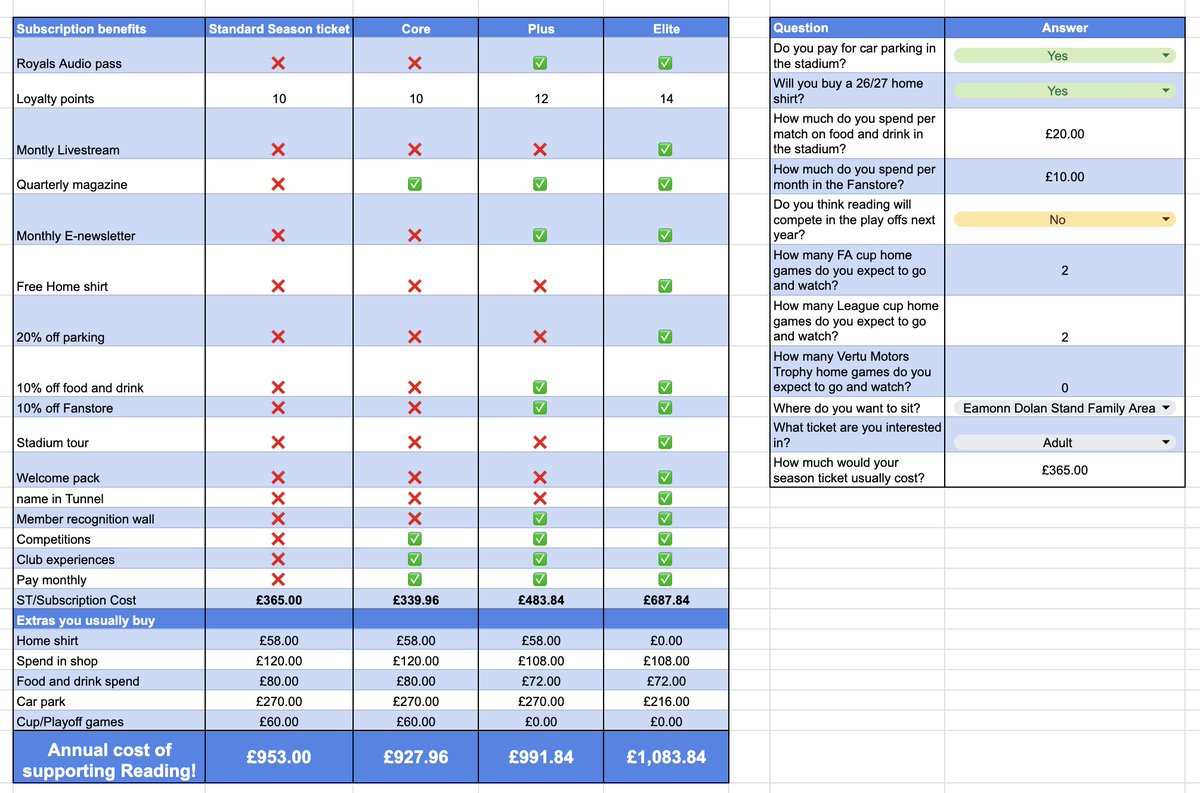
If you're new to google sheets, you'll need to make your own copy of the spreadsheet, and then you can edit like this:
2
5
2,063
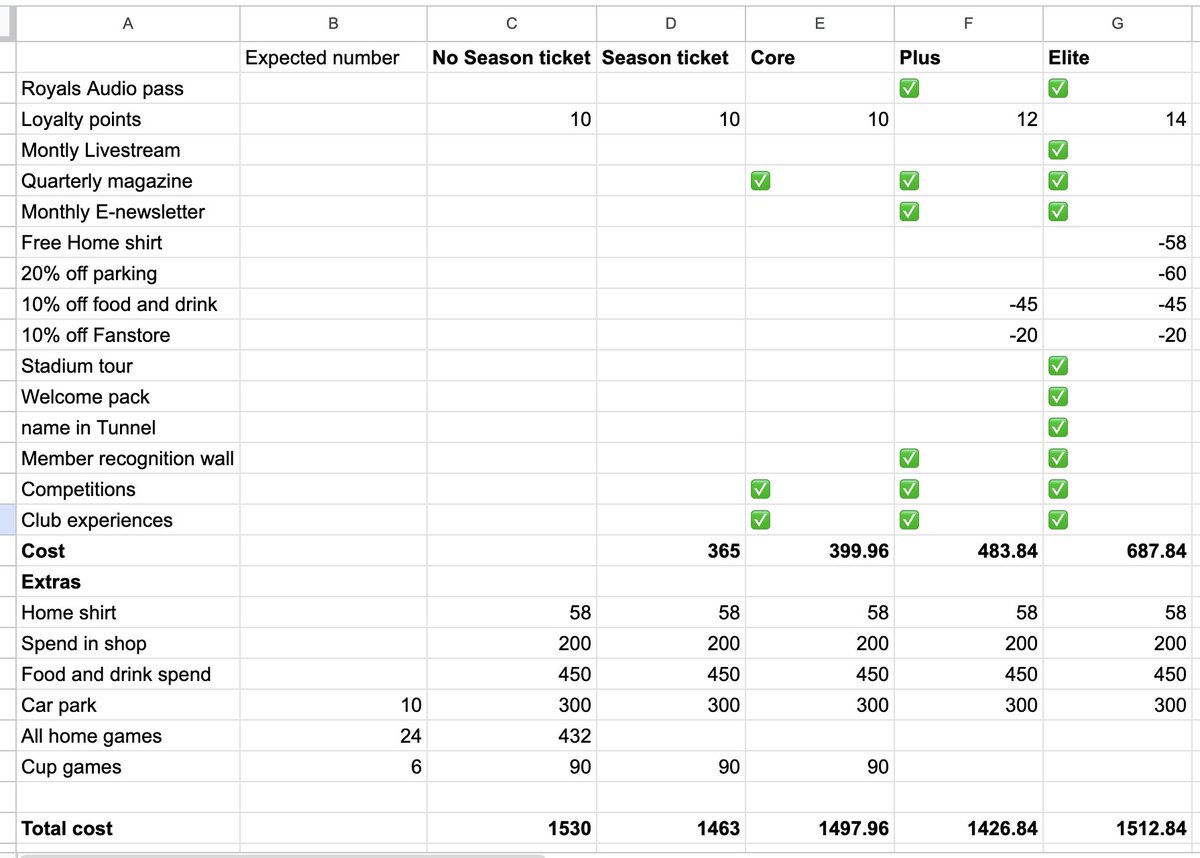
May 5
From what I've seen, how worthwhile each tier can be, is totally dependant on your typical annual spend in megastore, carpark, food/drink, and how many cup games we might get at home next season.
5
2,027
Simon Maple retweeted
May 4
Big models, bigger bill. But do you actually get better results?
In a new benchmark by Simon Maple ( @sjmaple ), 1,742 tests across 45 scenarios and 11 real engineering skills reveal a much more nuanced picture. GPT-5.5 does come out on top in raw capability, leading the baseline with a 75.6 average. But the moment you give these models structured domain skills, the gap disappears.
With skills loaded, GPT-5.5 scores 89.4. GPT-5.4 scores 89.3. That’s effectively identical performance.
Now look at what you’re paying for that 0.1 difference. $0.49 per run vs $0.30. A 63% increase in cost for something you won’t notice in output quality.
The only place GPT-5.5 clearly pulls ahead is latency. It finishes in ~89 seconds compared to ~135 seconds for GPT-5.4. If you’re running time-sensitive workflows, that matters. If you’re optimizing for cost or scale, it probably doesn’t.
The sharper takeaway is actually GPT-5.3. It scores significantly lower at 83.9, yet costs more than GPT-5.4 due to token inefficiency. That’s the worst combination: lower quality and higher cost.
What this points to is a shift in how these systems should be evaluated. Once you introduce skills, models stop competing purely on intelligence and start competing on how efficiently they use context. At that point, price-performance dominates.
The headline isn’t that GPT-5.5 is bad. It’s that it’s not meaningfully better where it counts, and you’re paying a premium for that gap.
Read the full blog here: tessl.io/blog/gpt-55-is-open…
1
2
325
Apr 22
We spend so much time debating timelines and benchmarks about AGI, but here's what @GoogleDeepMind Product Manager @OfficialLoganK has to say:
"AGI is not going to be a model. It's going to be a product."
This week on the pod, he drops something every dev needs to hear right now: The way you use AI tools today is already different from three months ago, and three months before that was different again. The rules are being rewritten under your feet. You can either ride the wave or get left behind. From why there will be 100x software engineers with AI to what’s changing in Deepmind, this episode is worth a listen.
Links in thread.
1
497
Apr 22
YouTube: youtube.com/watch?v=TL8VXkFc…
Apple pod: podcasts.apple.com/us/podcas…
Spotify: open.spotify.com/episode/44u…
1
226
Simon Maple retweeted

Apr 21
Google DeepMind's Logan Kilpatrick (@OfficialLoganK) just said something the big labs may not want to hear.
"AGI won't be a model. It's going to be a product that somebody creates."
Not a grand GPT or Claude release, but a product built by a small team who took an existing model and figured out what everyone else missed.
The labs are racing to build the brain.
By the time anyone announces AGI, it'll already have been out for months.
Nobody will even notice when it happens.
Source: AI Native Dev hosted by @sjmaple of @tessl_io
---
Link to the full video in comment.
21
18
158
25,817

Shipping faster with AI coding agents is easy. Shipping reliable code isn’t.
Tomorrow’s talk at @aiDotEngineer is about fixing that: Make Your Coding Agents Reliable (and Prove It with Evals)
Friday, 1:45pm in Wordsworth
@sjmaple will walk through a live demo showing how to:
- Give agents better context
- Reuse skills across your team
- Measure if your skills actually improve agent performance
This session focuses on practical workflows (not theory), so if you’re using agents day-to-day, this one's for you!

2
5
356