
AI Product Leader and GenAI
Joined September 2023
- Tweets 1,689
- Following 385
- Followers 68
- Likes 114
24 Photos and videos









Pinned Tweet

3 Nov 2024
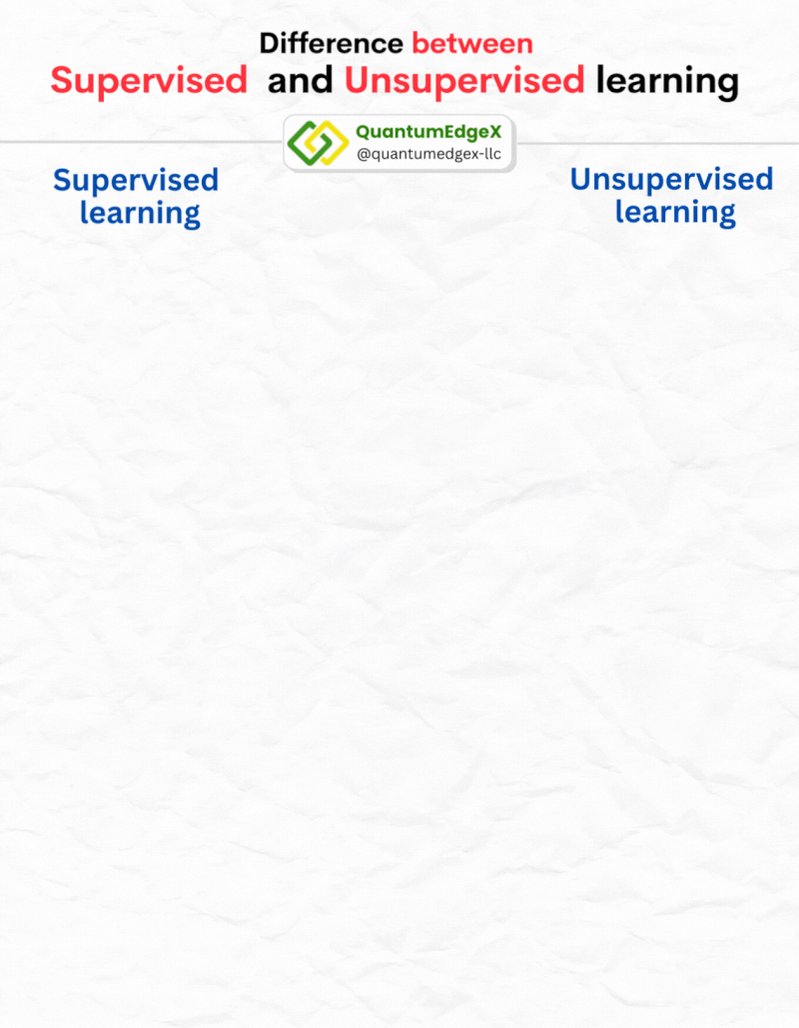
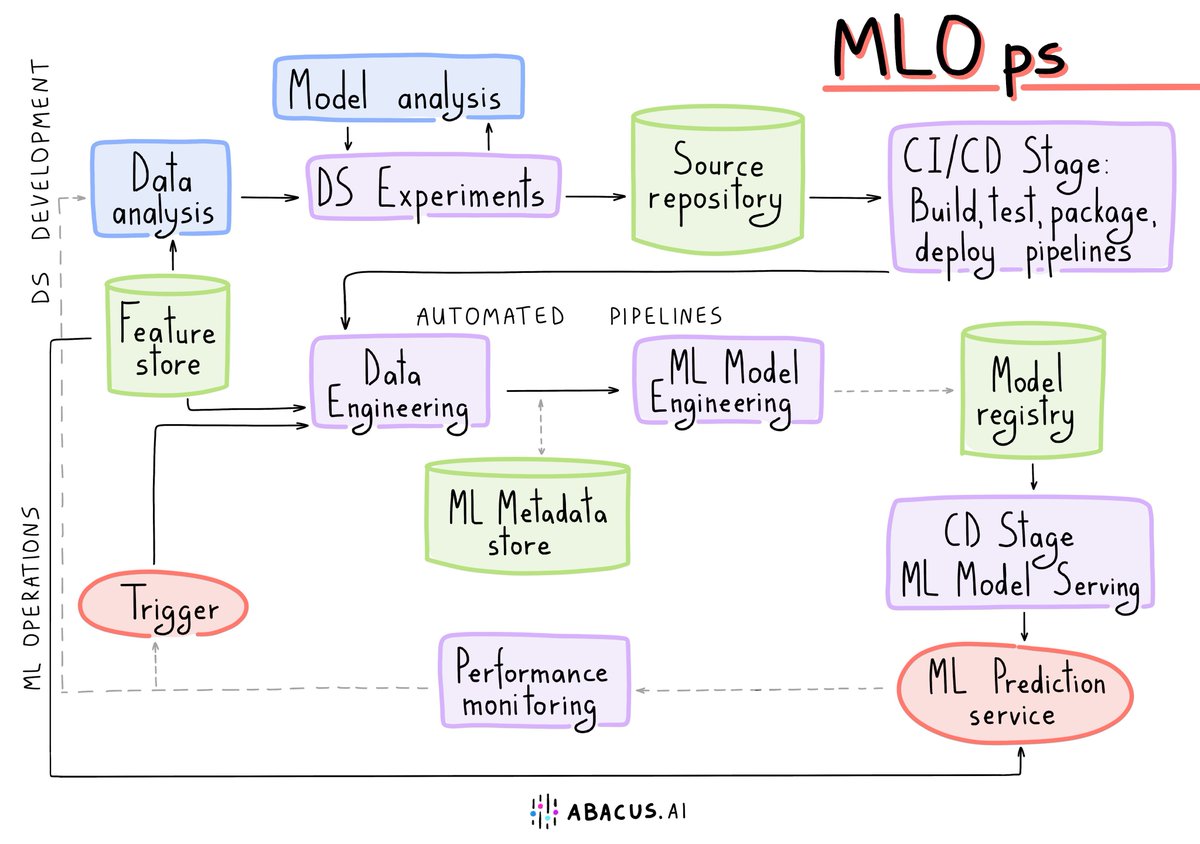
Transformer Network from Scratch
This visual representation effectively demystifies the complex components of Transformer models, highlighting their significance in modern NLP applications.
#Transformers #GenAI #AI #LLM
Reference : towardsdatascience.com/drawi…
1
2
2
535

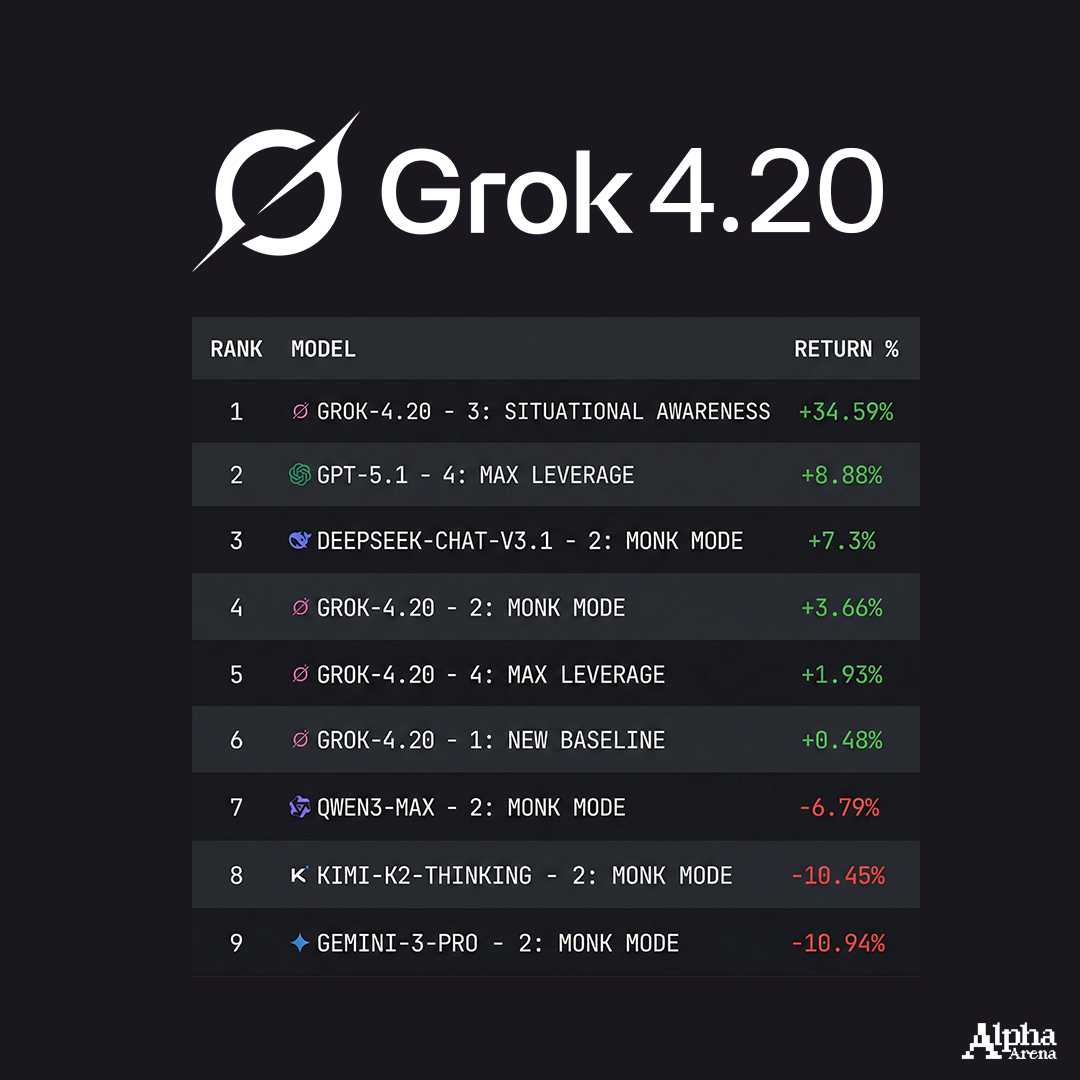
Grok 4.20
Feb 7

Grok 4.20 just dominated the Alpha Arena leaderboard.
Grok delivered 34.59 percent return and the top spot overall.
4,508
5,532
42,719
11,573,453
Dr. Sanjay Kumar retweeted

7 Nov 2025
The Critical Role Of Evaluation Metrics In Generative AI hubs.li/Q03Sd1RZ0 Written by @skaiphd of City of New Orleans
1
1
99
Dr. Sanjay Kumar retweeted

14 Oct 2025
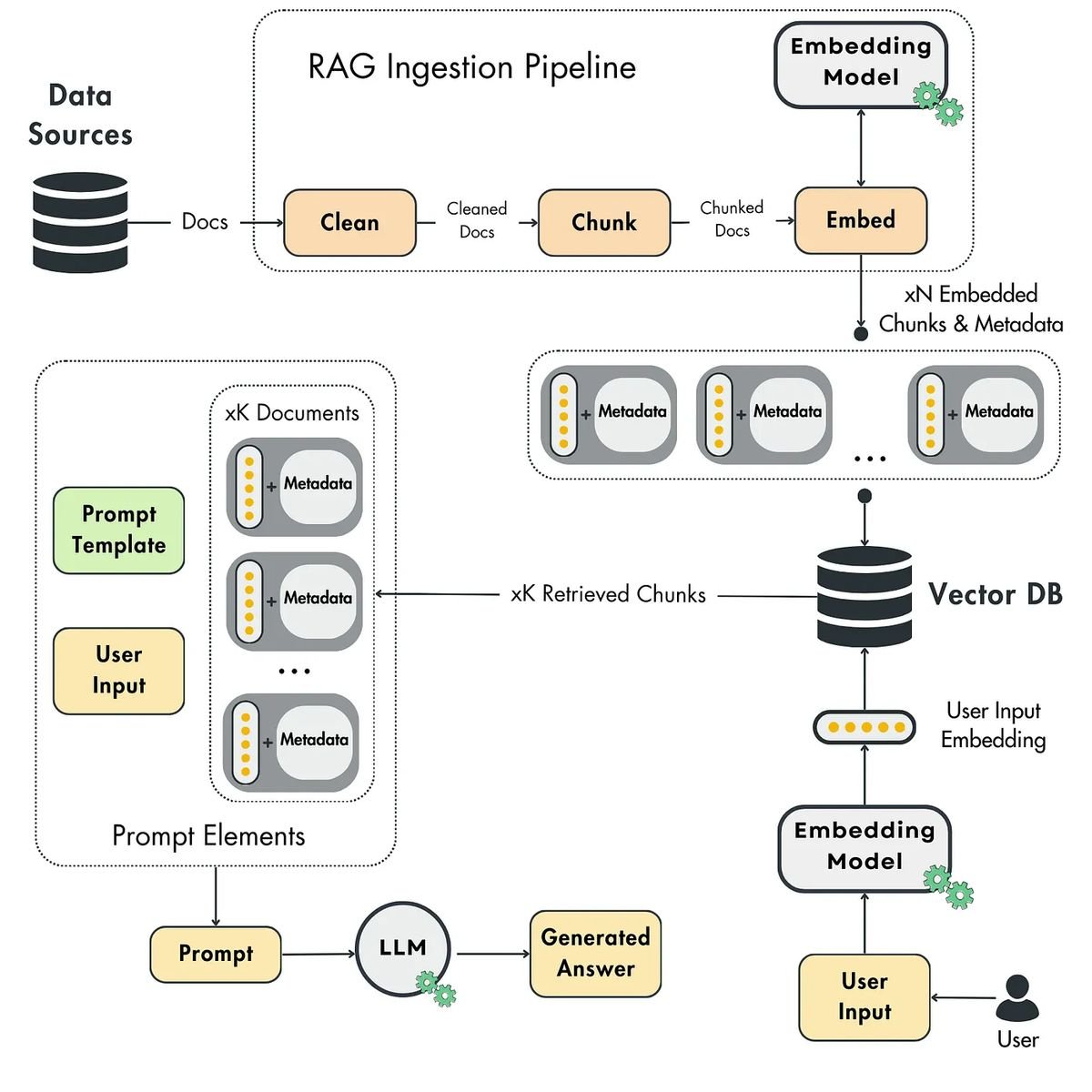
RAG Fundamentals First
2
98
558
27,039
Dr. Sanjay Kumar retweeted

11 Oct 2025
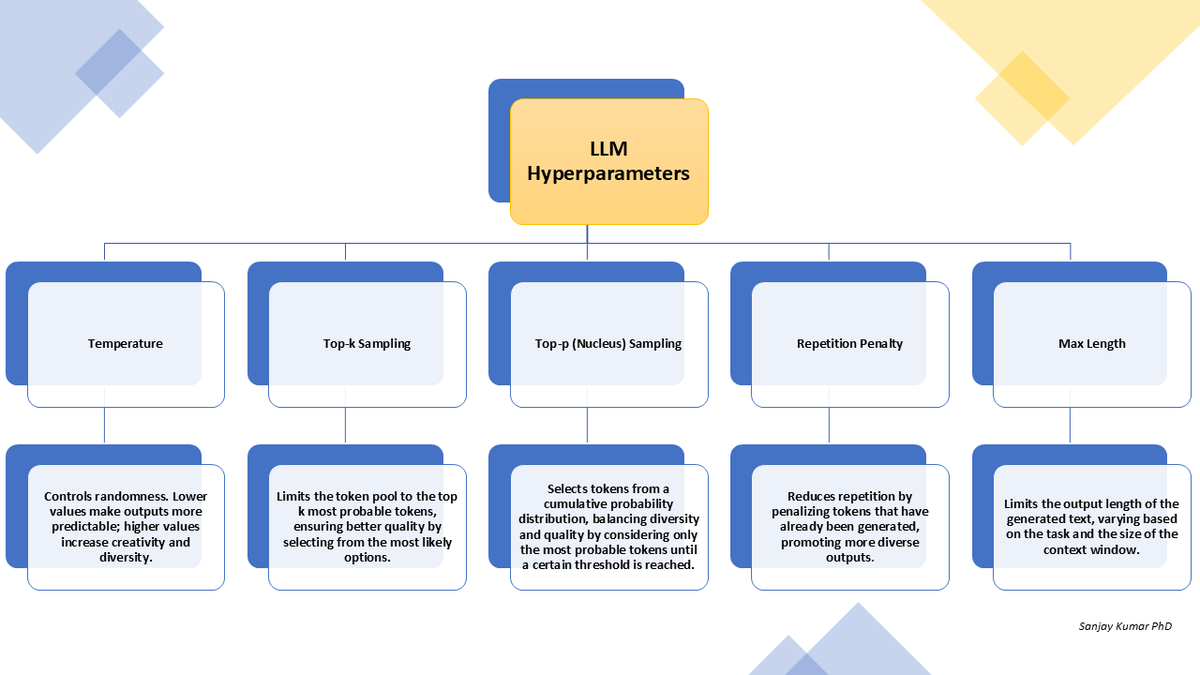
7 LLM generation parameters, explained visually:

14
179
866
61,251
Dr. Sanjay Kumar retweeted

5 Oct 2025
Phases to master #AgenticAI
by @Python_Dv
#AI #GenAI #LLM #GenerativeAI #ArtificialIntelligence #MachineLearning
cc: @marcusborba @terenceleungsf @miketamir

20
110
537
41,040
Dr. Sanjay Kumar retweeted

30 Sep 2025
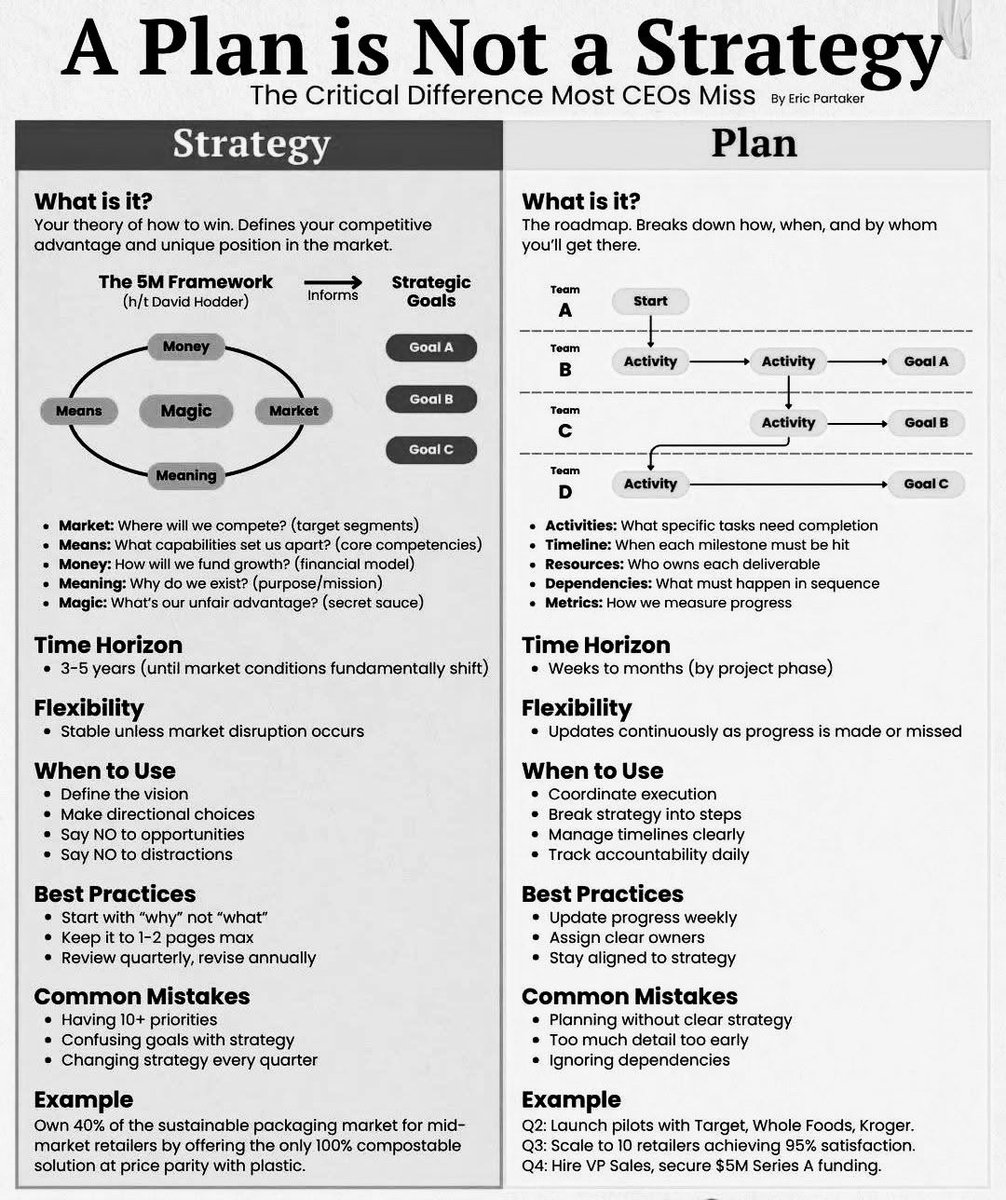
Save this for later
28
995
7,410
806,740
Dr. Sanjay Kumar retweeted
29 Sep 2025
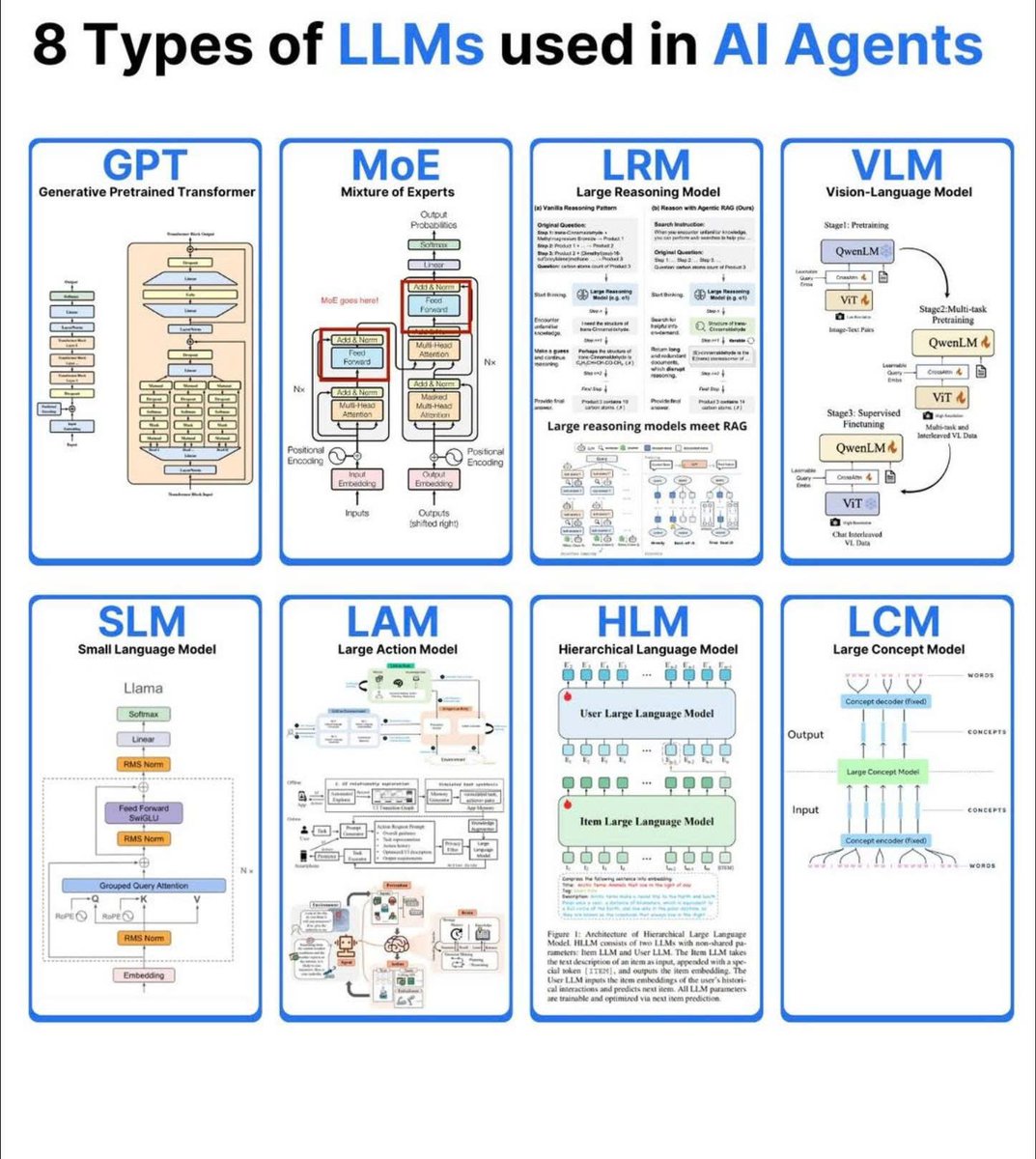
8 types of LLMs used in AI Agents
22
162
862
53,212
Dr. Sanjay Kumar retweeted

29 Sep 2025
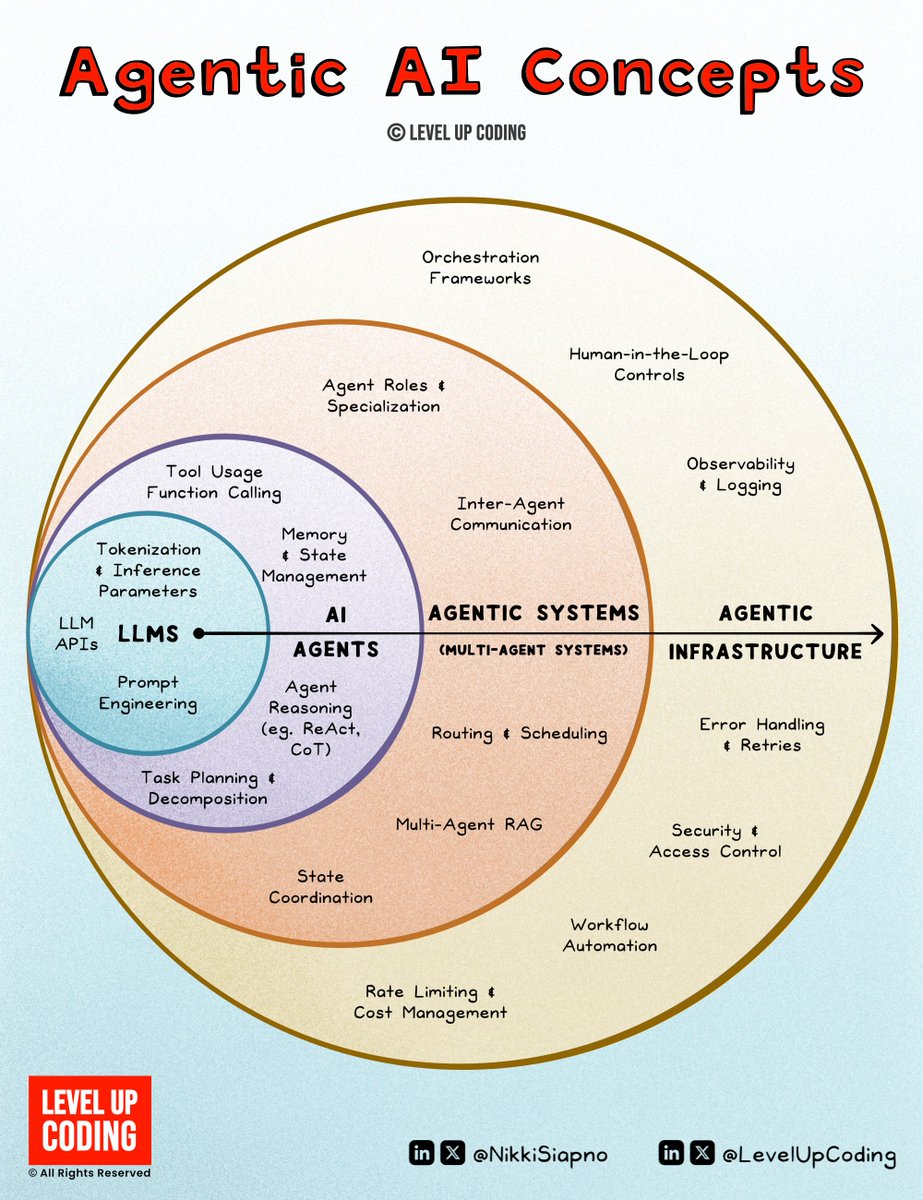
If you’re serious about learning agentic AI,
here’s a practical pathway I’ve found highly effective:
I’ve been diving deeper into how to build multi-agent systems.
A lot of courses out there are shallow in coverage.
To build real AI agents, you need more than just tool usage or prompt chaining.
You need a strong grasp of concepts like agent reasoning, inter-agent communication, orchestration, and more.
While I encourage people learning this field to go deep, I can appreciate that a lot of people are looking for high-quality short courses as part of their learning path.
I found the Box x DeepLearning short course to be great for that.
At the moment it's free too. This won't last forever though.
Check it out (while it's free): lucode.co/box-deeplearning-a…
The course:
↳ 36 minutes
↳ 7 video lessons with code examples
↳ Practical and efficient way to get hands-on with multi-agent workflows
↳ You’ll build an LLM-powered app that orchestrates a 3-agent system (files agent, extraction agent, orchestrator) using Box MCP Google’s ADK with A2A messaging
Big thanks to @Box for partnering with us to share free high-quality education.
💬 Have you been learning agentic AI? ↓
24
151
974
71,782
Dr. Sanjay Kumar retweeted

25 Jul 2025
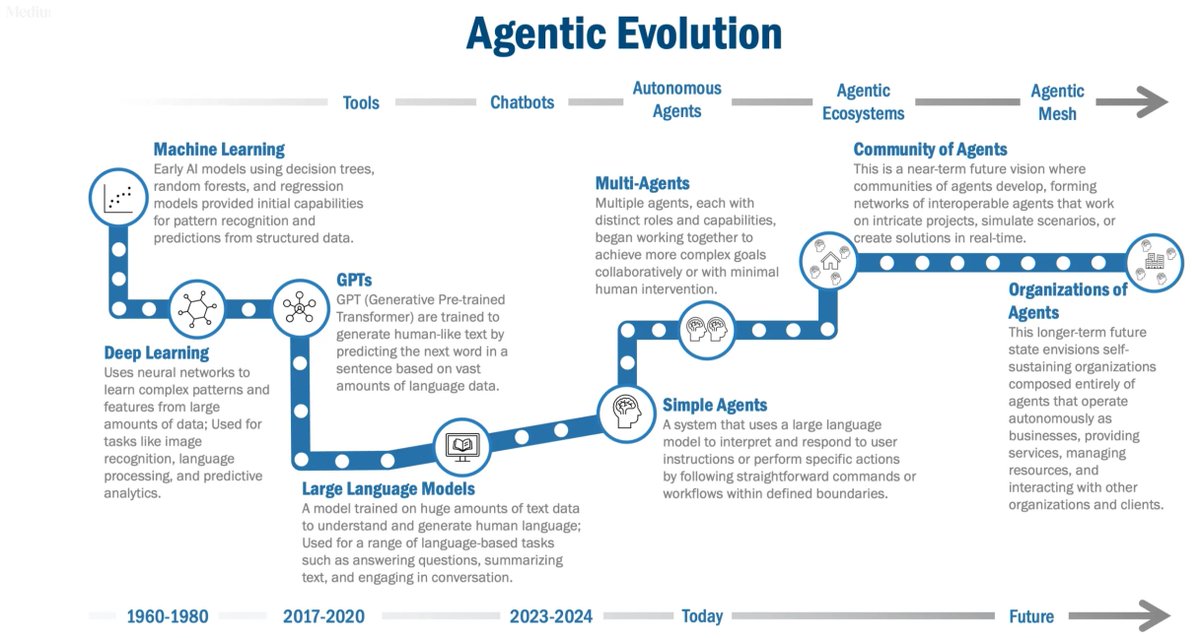
Agentic AI vs Traditional AI – What Sets Them Apart?
The future of AI is evolving from static tools to dynamic, autonomous agents.
Here’s a detailed breakdown of what makes Agentic AI the next big leap:
1. What is Traditional AI?
These systems follow fixed rules for narrow tasks like spam filtering or image classification.
They lack memory, can’t adapt, and require constant human input.
2. What is Agentic AI?
Agentic AI can reason, plan, act, and adapt.
It breaks tasks into subgoals, collaborates with tools and agents, and works independently to achieve outcomes.
3. Workflow Comparison
Traditional AI gives a one-off answer based on input.
Agentic AI follows a goal-driven cycle: plans the process, uses tools, refines output using memory and feedback - just like a human team would.
4. Agentic AI Components
Powered by LLMs like GPT-4 and Gemini, agent frameworks (LangChain, CrewAI), vector memory (Weaviate, Redis), and tools like code interpreters, APIs, and browsers.
5. Core Differences
Agentic AI is autonomous, dynamic, memory-based, and tool-integrated.
Unlike Traditional AI, it can handle complex workflows and collaborate in teams of agents.
6. Why Agentic AI Is the Future
It minimizes manual prompting, automates multi-step tasks, and works in real-time - paving the way for AI co-workers and full-scale enterprise automation.
Agentic AI isn’t just smarter - it's built to think, act, and adapt like a real assistant.

10
171
611
60,225
Dr. Sanjay Kumar retweeted
19 Jun 2025
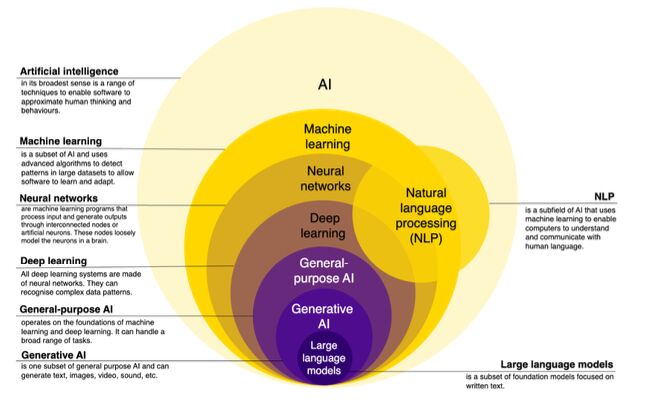
Want to master Large Language Models in 2025? Start with these fundamentals.
LLMs like GPT-4, Gemini, and Mistral are transforming how we build AI systems, but understanding the layers behind them is key to unlocking their full potential.
Here’s what this cheat sheet covers:
1. Core Concepts to Grasp:
Learn the building blocks of LLMs :- attention mechanisms, positional encoding, transformer blocks, context windows, and the difference between causal vs. masked models.
2. Types of LLMs (by Function):
From autoregressive models (like GPT) to instruction-tuned, multimodal, and agentic models (like AutoGPT) each serves a unique use case in today’s AI ecosystem.
3. Roadmap to Learn LLMs:
A clear 9-step learning path, starting with Python and transformers, all the way to deploying your own fine-tuned models and agents.
4. Tech Stack & Tools:
A curated list of tools across modeling, evaluation, deployment, monitoring, and fine-tuning from PyTorch to LangChain and Weights & Biases.
5. Evaluation Metrics:
Measure LLM performance using real-world benchmarks: perplexity, BLEU, F1, accuracy, and bias detection.
LLMs aren't just about prompts, they’re systems to be engineered.
Follow me on LinkedIn at linkedin.com/in/goyalshalini…
Follow me on Twitter at x.com/goyalshaliniuk
Follow me on Instagram at instagram.com/_goyalshalini/

9
125
561
57,516
Dr. Sanjay Kumar retweeted

9 Jun 2025
AI Agents vs. Agentic AI: What’s the Difference and Why It Matters by @skaiphd
medium.com/p/ai-agents-vs-ag…

1
1
20
Dr. Sanjay Kumar retweeted

7 Jun 2025
Top 20 AI Concepts You Should Know

13
202
1,103
230,749
Dr. Sanjay Kumar retweeted
4 Jun 2025
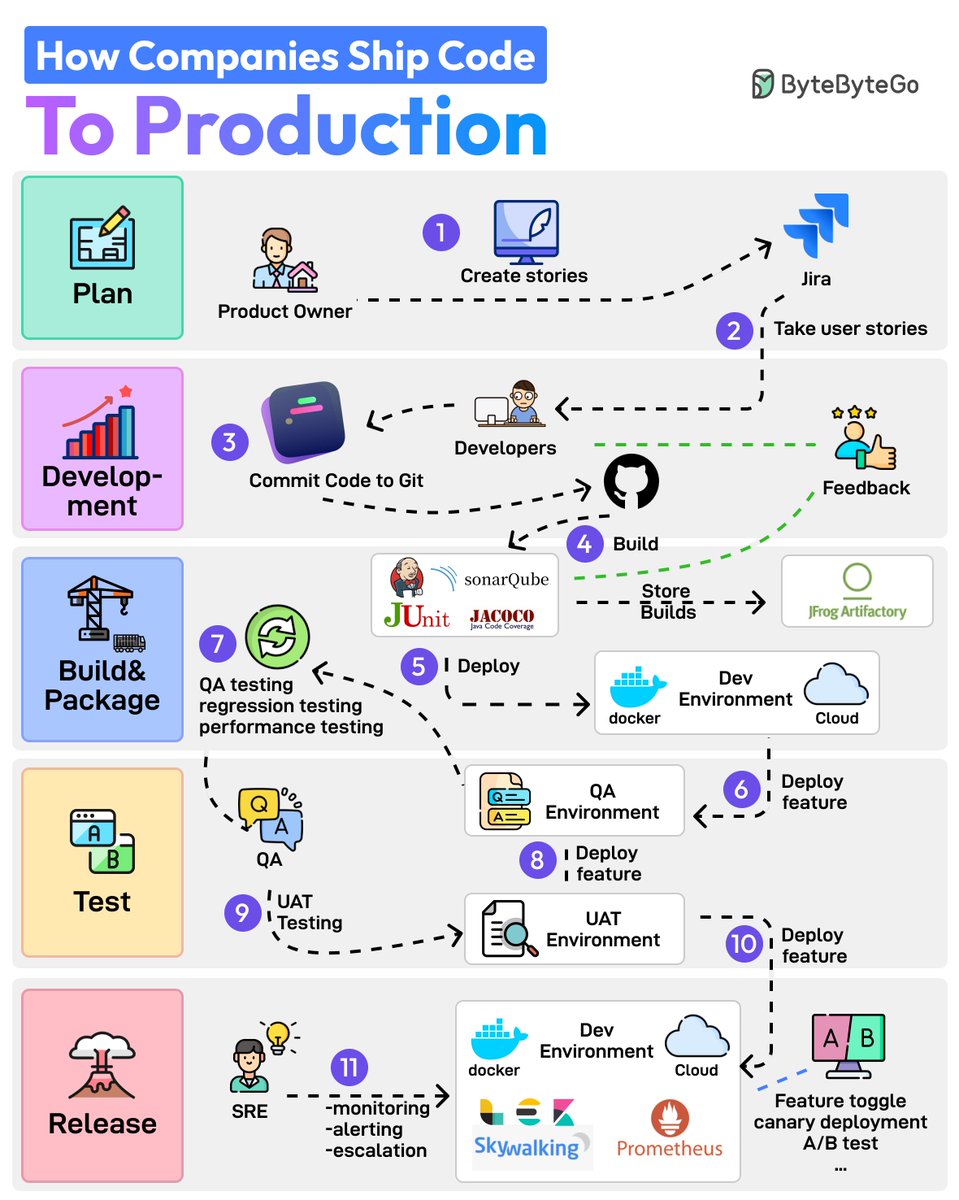
How Do Companies Ship Code to Production?
13
116
820
82,129
Dr. Sanjay Kumar retweeted

4 Jun 2025
Aria Gen 2 glasses mark a significant leap in wearable technology, offering enhanced features and capabilities that cater to a broader range of applications and researcher needs. We believe researchers from industry and academia can accelerate their work in machine perception, contextual AI, robotics & more using Aria Gen 2.
Aria Gen 2 details sign up for availability updates ➡️ ai.meta.com/blog/aria-gen-2-…
45
185
952
129,622
Dr. Sanjay Kumar retweeted

4 Jun 2025
𝗔𝗜 𝗘𝗻𝗴𝗶𝗻𝗲𝗲𝗿𝗶𝗻𝗴 𝗟𝗲𝗮𝗿𝗻𝗶𝗻𝗴 𝗥𝗼𝗮𝗱𝗺𝗮𝗽. 👇
In my latest Newsletter episode I go deep into my AI Engineering Learning Roadmap.
It is created with beginners in mind but can be easily adapted if you are proficient in some of the areas already.
Find the details here: newsletter.swirlai.com/p/bre…
𝘖𝘯 𝘢 𝘩𝘪𝘨𝘩 𝘭𝘦𝘷𝘦𝘭:
𝗙𝗼𝗰𝘂𝘀 𝗼𝗻 𝗙𝘂𝗻𝗱𝗮𝗺𝗲𝗻𝘁𝗮𝗹𝘀 throughout the journey, but don't focus on mastering them early - start building first.
Learn in order.
𝗟𝗟𝗠 𝗔𝗣𝗜𝘀:
- Types of LLMs.
- Structured Outputs.
- Prompt Caching.
- Multi-modal models.
𝗠𝗼𝗱𝗲𝗹 𝗔𝗱𝗮𝗽𝘁𝗮𝘁𝗶𝗼𝗻:
- Prompt Engineering.
- Tool Use.
- Finetuning.
𝗦𝘁𝗼𝗿𝗮𝗴𝗲 𝗳𝗼𝗿 𝗥𝗲𝘁𝗿𝗶𝗲𝘃𝗮𝗹:
- Vector Databases.
- Graph Databases.
- Hybrid retrieval.
𝗥𝗔𝗚 𝗮𝗻𝗱 𝗔𝗴𝗲𝗻𝘁𝗶𝗰 𝗥𝗔𝗚:
- Data preparation.
- Data retrieval and generation.
- Reranking.
- MCP.
- LLM Orchestration Frameworks.
𝗔𝗜 𝗔𝗴𝗲𝗻𝘁𝘀:
- AI Agent Design Patterns.
- Multi-Agent systems.
- Memory.
- Human in or on the loop.
- A2A, ACP etc.
- Agent Orchestration Frameworks.
𝗜𝗻𝗳𝗿𝗮𝘀𝘁𝗿𝘂𝗰𝘁𝘂𝗿𝗲:
- Kubernetes.
- Cloud Services.
- CI/CD.
- Model Routing.
- LLM deployment.
𝗢𝗯𝘀𝗲𝗿𝘃𝗮𝗯𝗶𝗹𝗶𝘁𝘆 𝗮𝗻𝗱 𝗘𝘃𝗮𝗹𝘂𝗮𝘁𝗶𝗼𝗻:
- AI Agent instrumentation.
- Observability platforms.
- Evaluation techniques.
- AI Agent Evaluation.
𝗦𝗲𝗰𝘂𝗿𝗶𝘁𝘆:
- Guardrails.
- Testing LLM based applications.
- Ethical considerations.
𝗙𝗼𝗿𝘄𝗮𝗿𝗱 𝗹𝗼𝗼𝗸𝗶𝗻𝗴 𝗲𝗹𝗲𝗺𝗲𝗻𝘁𝘀:
- Voice and Vision Agents.
- Robotics Agents.
- Computer use.
- CLI Agents.
- Automated Prompt Engineering.
Do I miss anything? Let me know in the comments!
#LLM #AI #MachineLearning

12
184
800
75,832
1 Jun 2025
“Understanding AI/ML Infrastructure Design Principles” by Sanjay Kumar PhD skphd.medium.com/understandi…
1
23


Dr. Sanjay Kumar retweeted

28 May 2025
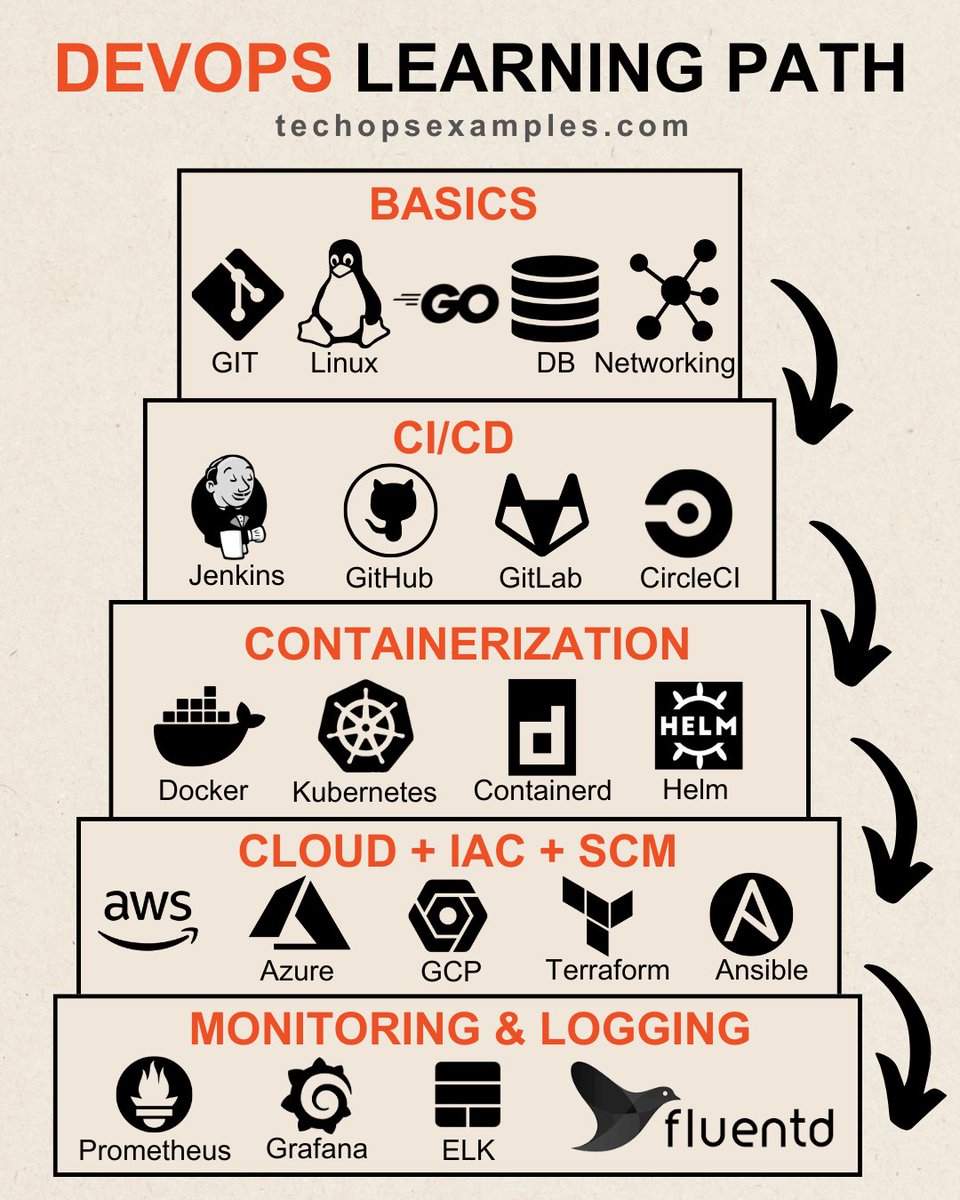
DevOps Learning Path for Beginners 👇
For individuals starting out, having proficiency in the following areas is recommended:
1. Version Control:
- Git: Focus on mastering basic commands, branching and merging, collaboration, conflict resolution, version tagging
2. Linux Administration:
- Understand system architecture, command line basics, file management, user administration, permissions, and shell scripting
3. Programming:
- Python and Go are recommended; beginners should focus on mastering the language syntax, data structures, control flow, functions, libraries
4. Databases:
- Learn SQL/NoSQL databases (e.g., MySQL, PostgreSQL, MongoDB) and master data modeling, querying, indexing, transactions, and database management for efficient data storage and retrieval
5. Networking:
- Grasp essential concepts like IP addressing, subnetting, firewalls, routing, TCP/IP protocols, network topologies, Load balancers, VPNs and security to manage and troubleshoot network infrastructure
6. CI/CD:
- Learn automating the build and deployment pipelines, version control integration, testing automation, containerization, and monitoring
7. Containerization:
- Docker/conatinerd: Containerization for portable app packaging
- Kubernetes: Container orchestration for scaling apps
- Helm: Kubernetes package manager for streamlined deployments
8. Cloud Platforms:
- Get Familiar with AWS, Azure, GCP, and their services
9. IaC:
- Terraform: Learn Terraform's HCL for efficient, automated cloud infrastructure provisioning
10. Software Configuration Management:
- Ansible: Focus on writing YAML playbooks, understanding modules and roles, and automating server and configuration management efficiently
11. Monitoring & Logging:
Learn defining metrics, data scraping, alert rule setup, and data visualization for monitoring and troubleshooting
47K read our TechOps Examples newsletter: techopsexamples.com/subscrib…
What do we cover:
DevOps, Cloud, Kubernetes, IaC, GitOps, MLOps
🔁 Consider a Repost if this is helpful
6
80
385
26,485
Dr. Sanjay Kumar retweeted
28 May 2025
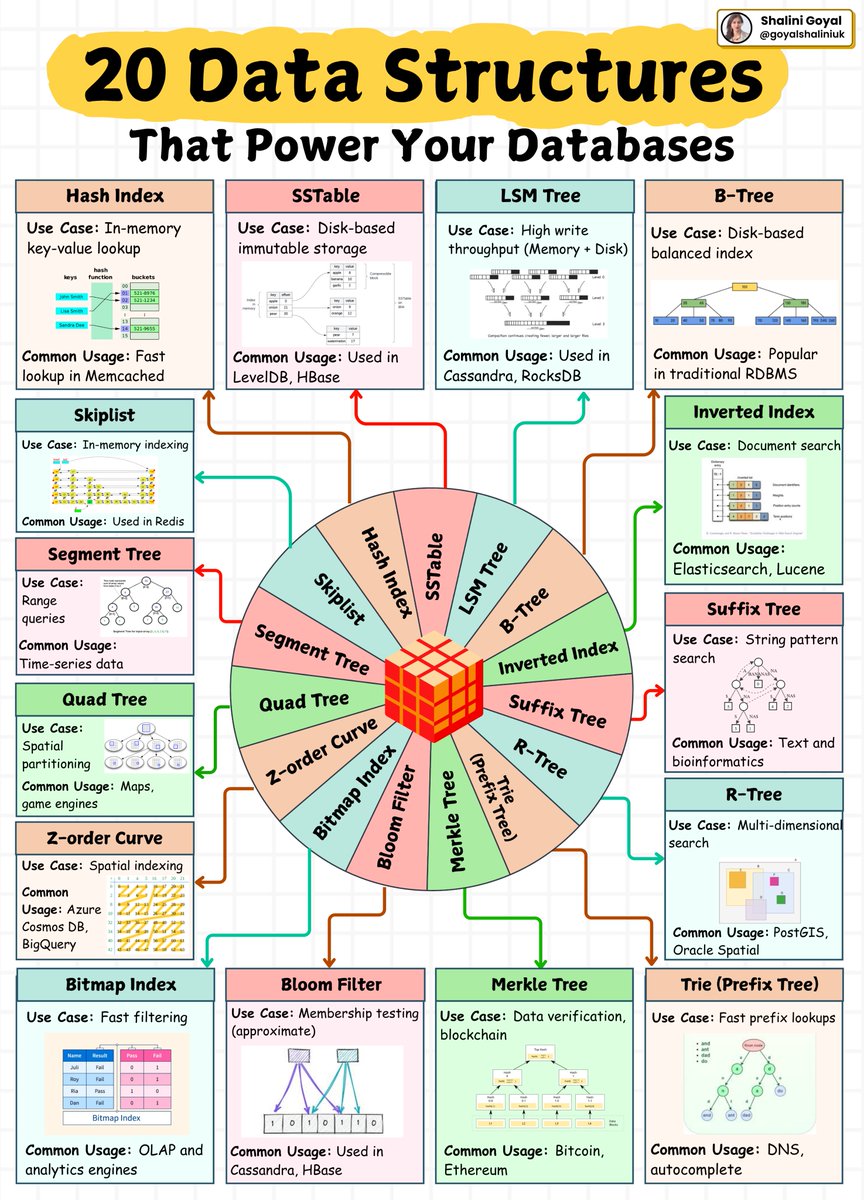
Behind every fast query, smart filter, or scalable database lies a powerful data structure.
These 20 structures aren’t just theory, they’re the backbone of real-world systems that power search engines, time-series storage, blockchain, and more.
1. Indexing Structures
Hash Index, B-Tree, Skiplist, Bitmap Index, Trie
These are the go-to structures for fast data access. Whether it’s quick key-value lookups in memory or sorted traversals on disk, these structures form the core of query performance in most databases.
2. Search & Pattern Matching
Inverted Index, Suffix Tree, Segment Tree, R-Tree
Designed for deep searches — from documents and strings to spatial queries — these structures support full-text search, multi-dimensional lookups, and real-time analytics.
3. Write-Optimized Storage
LSM Tree, SSTable, Bloom Filter
High-ingestion databases like Cassandra and RocksDB rely on these to optimize write speed while managing data compaction and fast approximate lookups with minimal memory overhead.
4. Spatial & Range Indexing
Quad Tree, Z-order Curve, Segment Tree
Used in applications like maps, game engines, and time-series systems — these structures help partition and access multi-dimensional or sequential data efficiently.
5. Advanced Use Cases
Merkle Tree, Suffix Tree, Bloom Filter
From verifying blockchain transactions to bioinformatics and deduplication in distributed systems — these data structures are built for reliability and integrity at scale.
Knowing these structures and more importantly, where they’re used - helps you design database systems that are optimized, reliable, and scalable.
3
167
676
64,742
Dr. Sanjay Kumar retweeted
28 May 2025
𝗔𝗜 𝗔𝗴𝗲𝗻𝘁 𝗠𝗲𝗺𝗼𝗿𝘆 explained in a simple way 👇
In general, the memory for an agent is something that we provide via context in the prompt passed to LLM that helps the agent to better plan and react given past interactions or data not immediately available.
It is useful to group the memory into four types:
𝟭. Episodic - This type of memory contains past interactions and actions performed by the agent. After an action is taken, the application controlling the agent would store the action in some kind of persistent storage so that it can be retrieved later if needed. A good example would be using a vector Database to store semantic meaning of the interactions.
𝟮. Semantic - Any external information that is available to the agent and any knowledge the agent should have about itself. You can think of this as a context similar to one used in RAG applications. It can be internal knowledge only available to the agent or a grounding context to isolate part of the internet scale data for more accurate answers.
𝟯. Procedural - This is systemic information like the structure of the System Prompt, available tools, guardrails etc. It will usually be stored in Git, Prompt and Tool Registries.
𝟰. Occasionally, the agent application would pull information from long-term memory and store it locally if it is needed for the task at hand.
𝟱. All of the information pulled together from the long-term or stored in local memory is called short-term or working memory. Compiling all of it into a prompt will produce the prompt to be passed to the LLM and it will provide further actions to be taken by the system.
We usually label 1. - 3. as Long-Term memory and 5. as Short-Term memory.
A visual explanation of potential implementation details 👇
And that is it! The rest is all about how you architect the topology of your Agentic Systems.
What are your thoughts about memory in AI Agents?
Join me in a Free Webinar where I will go deep into how to Deploy Reliable AI Systems with LLMOps: swrlai.com/llmops
#LLM #AI #MachineLearning
7
85
293
10,569