Data & AI expert | Helping companies transform their business with data
Joined December 2008
- Tweets 40,912
- Following 3,008
- Followers 41,329
- Likes 23,360
8,649 Photos and videos










Pinned Tweet

20 Mar 2021
Who’s Who in #DataScience and #MachineLearning?
Honored to be mentioned by @Onalytica in the report, along with other great people:
@KirkDBorne @schmarzo @BernardMarr @IainLJBrown @rudyagovic @andrewbrust @LouisColumbus @Fabriziobustama and many others
bit.ly/3r4NSyc

14
312
130
Marcus Borba retweeted

1 Dec 2025
Humanoid robotics just got a major boost.
@FlexionRobotics has raised a $50M Series A to build what could become the intelligence layer for the next generation of humanoid robots.
The Zurich-based team, led by Nikita Rudin (with experience from ETH Zurich, NVIDIA, Meta, Google, and Tesla), is taking a different approach than most in the space:
🔹 Language-level task reasoning
🔹 A VLA model trained heavily in simulation
🔹 Transformer-based whole-body control
The ambition?
Robots that don’t just replay human demos, but actually understand, adapt, and perform tasks with true autonomy.
If humanoids are ever going to be useful in factories, logistics centers, and real industrial environments, someone has to solve this intelligence layer. Flexion is taking that challenge head-on.
With $50M in fresh capital, they’re now scaling compute, expanding robot fleets, and moving toward deployments with major OEMs.
And honestly?
Watching the progress — even the way these robots walk — is incredible.
#AI #Robotics #Humanoids #Automation #DeepLearning #FutureOfWork
Source 🙏 @lukas_m_ziegler
@IanLJones98 @NevilleGaunt @bamitav @altiamkabir @sijlalhussain @marcusborba @jblefevre60 @Nicochan33 @TerenceLeungSF @KirkDBorne @CurieuxExplorer @enilev @Eli_Krumova @pascal_bornet @anand_narang @sulefati7 @Xbond49 @Hana_ElSayyed @engmlubbad @Timothy_Hughes @mcanducci @RLDI_Lamy @segundoatdell @engmlubbad @rvp @ipfcoline1 @PatGrant7777 @NigelTozer @Ronald_vanLoon @pierrepinna @Khulood_Almani @BetaMoroney @AkwyZ
2
5
12
3,571
Marcus Borba retweeted

2 Dec 2025
Time To Power: A look Inside Innovation Park from the Summit Floor - @schneiderelectric
At the Schneider Electric Innovation Summit North America 2025, in Las Vegas, I had the chance to experience firsthand how quickly the new energy landscape is taking shape, not in theory, but in real, measurable progress.
Schneider Electric has a 135-year legacy in the United States, and throughout the Summit, it was clear how that history continues to guide the company’s leadership as the leading energy tech partner at the intersection of energy, AI, and digital transformation.
Walking through Innovation Park brought the strategy into sharp focus. Each zone showed how intelligent infrastructure is transforming the systems we depend on:
🏠 Homes: digital energy for smarter, more sustainable living
🏢 Commercial Buildings: efficiency powered by automation and digitalization
🏥 Healthcare: resilient, AI-ready medical environments
💾 Data Centers: high-density, AI-optimized architectures
⚡ Infrastructure & Grid: modernizing the backbone of the energy system
🏭 Industry: real-time automation for manufacturing & process environments
💧 Sustainability & Water: circular, resource-efficient operations
🚀 SE Ventures & Partners: the expanding innovation ecosystem
Across every booth, one theme kept coming up:
AI isn’t just increasing demand, it’s redefining how energy must be produced, delivered, and managed, and Schneider Electric has solutions to meet this challenge head-on.
The event deepened that narrative with concrete momentum:
✅the debut of an AI-enabled One Digital Grid Platform to help utilities modernize, stabilize, and manage rising energy costs;
✅new sustainability milestones such as UL ECOLOGO® certification for energy and industrial automation equipment;
✅and expanded advisory and asset-performance services designed to help organizations de-risk electrification, accelerate AI readiness, and advance grid-interactive operations.
What stood out most to me walking the floor was how Schneider Electric and its partners are moving beyond efficiency as a goal, and treating intelligence as the new baseline for energy and industry.
From autonomous operations to smart buildings to industrial software, you can see the next wave of digital infrastructure taking shape in real time.
This is one of the most important transformations of our decade, and it’s happening faster than most realize.
⚡️ Learn more: se.com/us/en/
🎥 Watch the Video ⬇️:
#ad @SchneiderElec @SchneiderNA #schneiderelectric #SchneiderElectricInnovationSummit #ISNA2025 #InnovationSummitLasVegas #AI #EnergyTechLeaders
17
16
36
7,393
Marcus Borba retweeted

2 Dec 2025
EngineAI T800: Born to Disrupt!
x.com/engineairobot/status/1…
#EngineAI #robotics #Technology #Robot #humanoid
@AlbertoEMachado @Eli_Krumova @postoff25 @Khulood_Almani @anand_narang @NutritiousMind @baski_LA @TanyaSinha_ @devaang @AlAmadi1 @jeancayeux @enilev @efipm @mvollmer1 @Nicochan33 @RagusoSergio @FrRonconi @Shi4Tech @sallyeaves @LaurentAlaus @Fabriziobustama @smaksked @MargaretSiegien @PawlowskiMario @gvalan @Ym78200 @mikeflache @EduardoValenteI @ipfconline1 @kalydeoo @chboursin @cleartechtoday @SpirosMargaris
4
13
20
3,718
Marcus Borba retweeted

🔥🤖Why Does Sovereign #AI Determine Which Nations Lead the Future❓
🎯AI is no longer “technology”, it is national infrastructure and a strategic power layer. Here is what the 6️⃣ Pillars of Sovereign AI truly mean⤵️
1️⃣ Data Sovereignty ➜ Who shapes your model’s worldview
▪️Models trained on foreign data inherit foreign values and cultural logic
2️⃣ Model Architecture Sovereignty ➜ Whose reasoning patterns does your AI follow
▪️ Base models embed the creator’s logic, safety defaults & cognitive biases
3️⃣ Compute Sovereignty ➜ Who controls your ability to train
▪️ Without sovereign compute, nations cannot independently build or scale their models
4️⃣ Inference Sovereignty ➜ Where does your national data actually run
▪️ If sensitive workloads run on foreign clouds, they fall under foreign jurisdiction
5️⃣ Data Center Sovereignty ➜ Where does your AI physically live
▪️ Foreign-owned infrastructure means foreign leverage over critical systems, energy security
6️⃣ AI Economy Sovereignty ➜ Who captures the value
▪️ A nation can build strong models yet lose the economic upside if the value flows abroad
💡The truth is simple ➜ Countries aren’t racing toward Sovereign AI because it’s fashionable; they’re racing because it determines who shapes the future
By Alex Issakova
@enilev @Jagersbergknut @TysonLester @CurieuxExplorer @GlenGilmore @chidambara09 @jeancayeux @mvollmer1 @Nicochan33 @RLDI_Lamy @pierrepinna @pchamard @Analytics_699 @mikeflache @JeromeMONANGE @FrRonconi @Fabriziobustama @PawlowskiMario @theomitsa @drsharwood @kalydeoo @TAEVisionCEO @baski_LA @AnthonyRochand @smaksked @Eli_Krumova @andresvilarino @fernandolofrano @gvalan @bimedotcom @NewsNeus @domingonarvaez1 @thomas_dettling @kanezadiane @dinisguarda @FmFrancoise @nafisalam @Mhcommunicate @Corix_JC @jblefevre60 @smoothsale @amalmerzouk @PVynckier @bbailey39 @SiddharthKS @anand_narang @bamitav @Nitin_Author
30
90
176
151,298
Marcus Borba retweeted

1 Dec 2025
💥The Ultimate CES 2026 Guide: Hottest AI Panels, Parties And Robots
By @Forbes v/ @chidambara09
#CES2026 #Innovation #AI #WearableTech #Robotics #Engineering #HealthTech
forbes.com/sites/martinepari…

ALT CES2026 The Ultimate Guide By @Forbes Posted by @enilev via @chidambara09
30 Nov 2025

4
11
11
560
Marcus Borba retweeted

2 Dec 2025
Most people learn data engineering the hard way…
by drowning in jargon they’ve never heard before.
But here’s the truth no one tells you:
Data engineering isn’t hard because of the tools,
it’s hard because of the terminology.
Once you understand the words,
you finally understand the systems.
And once you understand the systems,
everything else becomes 10× easier.
Here’s a quick breakdown of what you’re learning:
1. ETL vs ELT — Know the difference.
ETL transforms before loading.
ELT loads first, transforms later.
Both shape how your pipeline performs.
2. Data Warehouse ≠ Data Lake.
One is for structured analytics.
The other stores raw, semi-structured everything.
Know which one fits your use case.
3. Real-time vs Batch - choose the right processing model.
Not every problem needs stream processing.
Sometimes batch is faster, cheaper, and simpler.
4. Schema matters more than you think.
Star schema, snowflake schema, table schema -
these decide performance long before the query runs.
5. Distributed systems are the backbone.
If your data isn't spread across nodes,
your system won’t scale.
6. Governance isn’t optional.
Catalogs, quality checks, lineage -
these protect your data, your users, and your business.
7. Partitioning & Sharding are lifesavers.
Large datasets die without them.
Small datasets don’t need them.
8. Fault Tolerance & Scalability keep systems alive.
Your pipeline should run even when things break.
Your platform should grow without manual effort.
If you’re in data engineering, analytics, AI, or backend - mastering these fundamentals will put you ahead of 90% of the industry.
Because tools change.
But foundations stay forever.
Which concept do you think every beginner should learn first?
23
56
205
9,640
Marcus Borba retweeted
1 Dec 2025
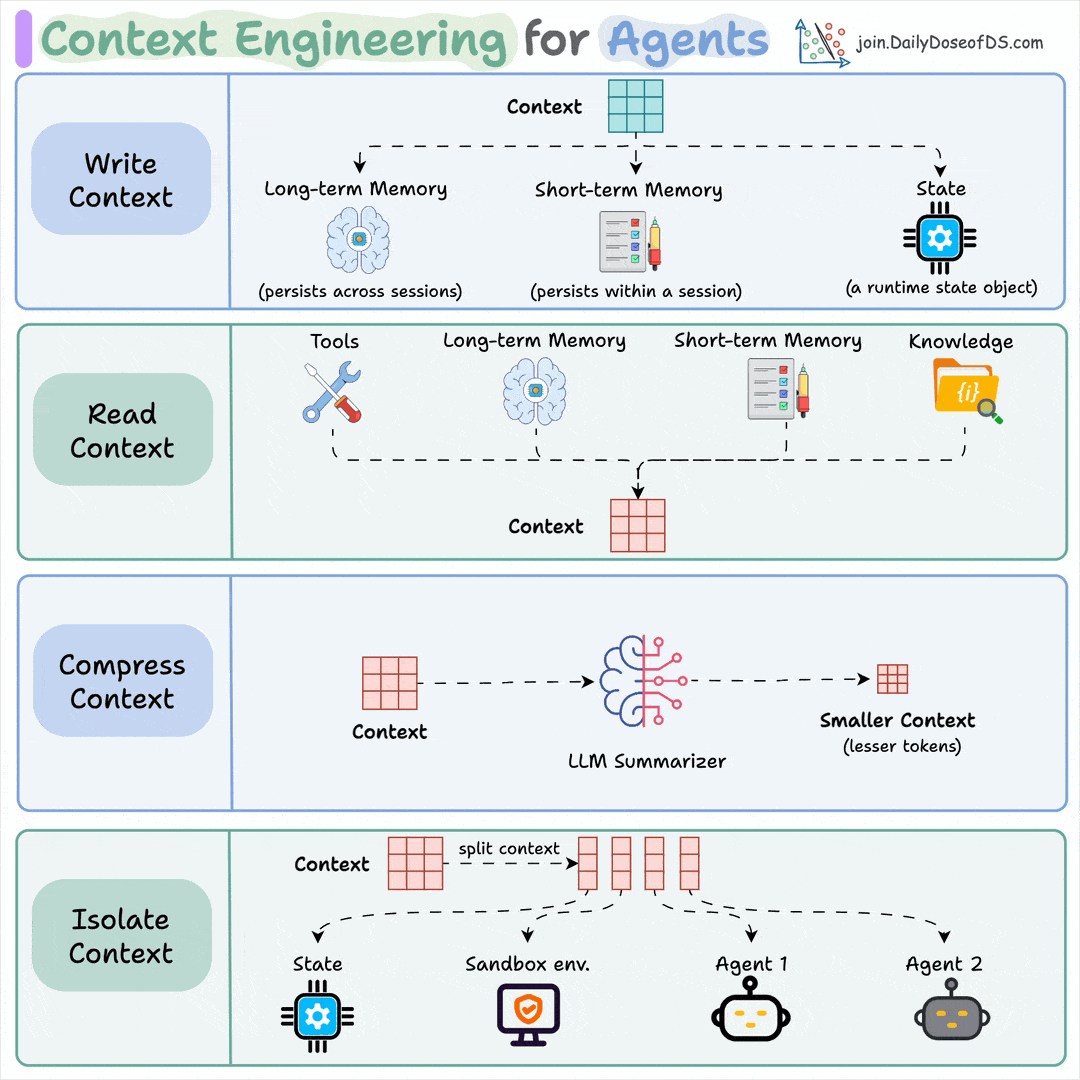
Context engineering, clearly explained (with visuals)
#AI @mvollmer1 @enilev @anijov @CatherineAdenle @FmFrancoise @AkwyZ @avrohomg @jblefevre60 @BetaMoroney @gvalan #MachineLearning @CurieuxExplorer @BIScorecard @Nicochan33 @Kevin_ODonovan @Hana_ElSayyed @sallyeaves
2
10
15
759
Marcus Borba retweeted

1 Dec 2025
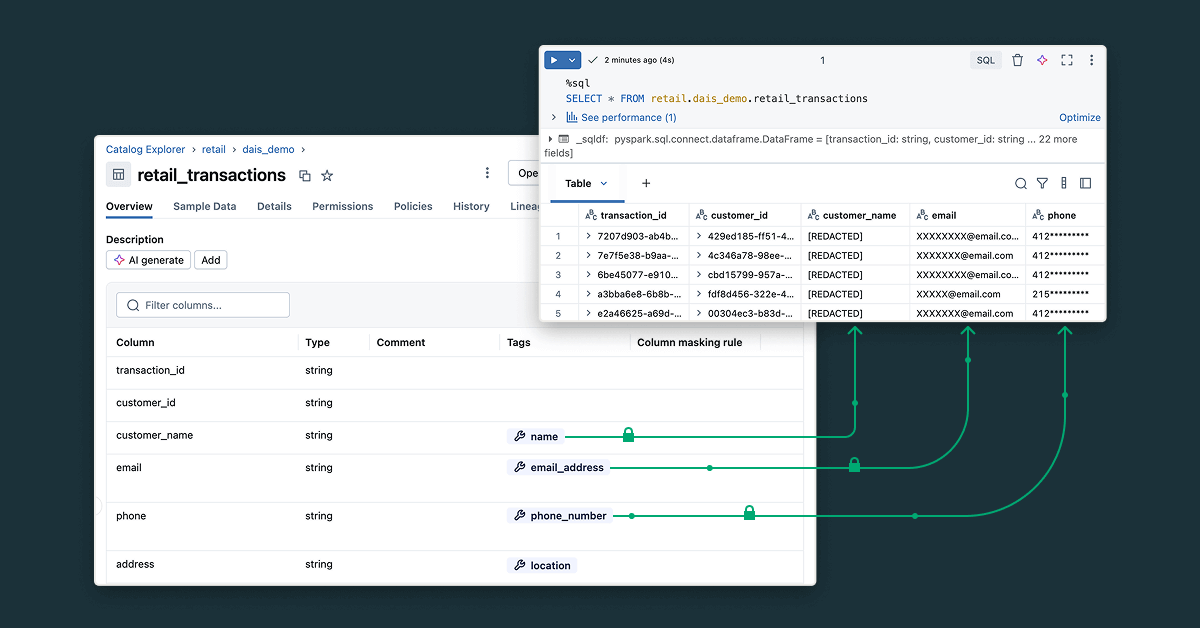
We've made it easier to scale data governance while keeping sensitive data protected. Now in Unity Catalog, you can define tag-driven policies once and automatically apply row and column controls across all tables using Governed Tags and Data Classification.
Learn more about Attribute-Based Access Control (ABAC) in Unity Catalog, now in Public Preview: databricks.com/blog/how-scal…
6
7
43
3,178
Marcus Borba retweeted

30 Nov 2025
Anthropic dropped the best free masterclass on prompt engineering

30
87
602
49,557
Marcus Borba retweeted

30 Nov 2025
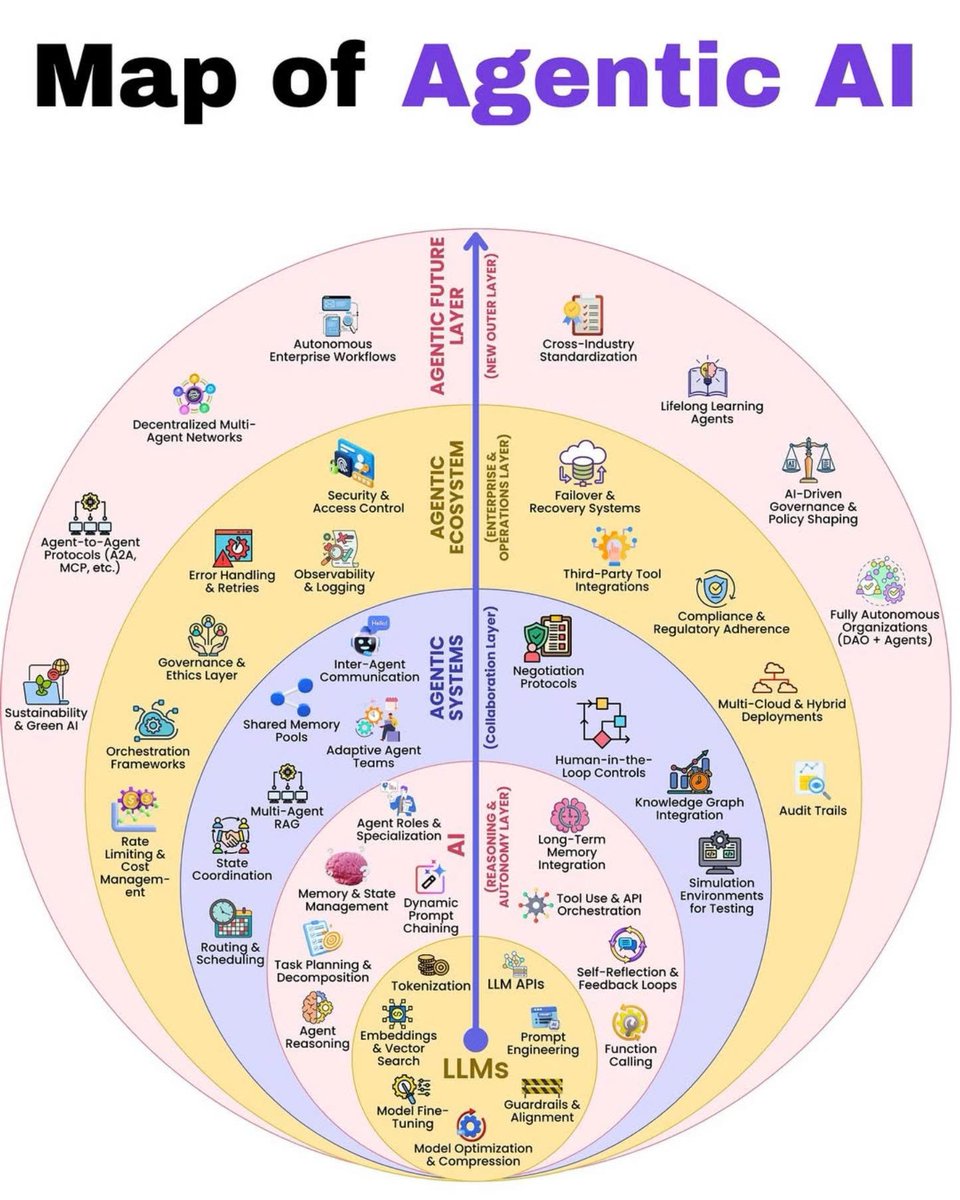
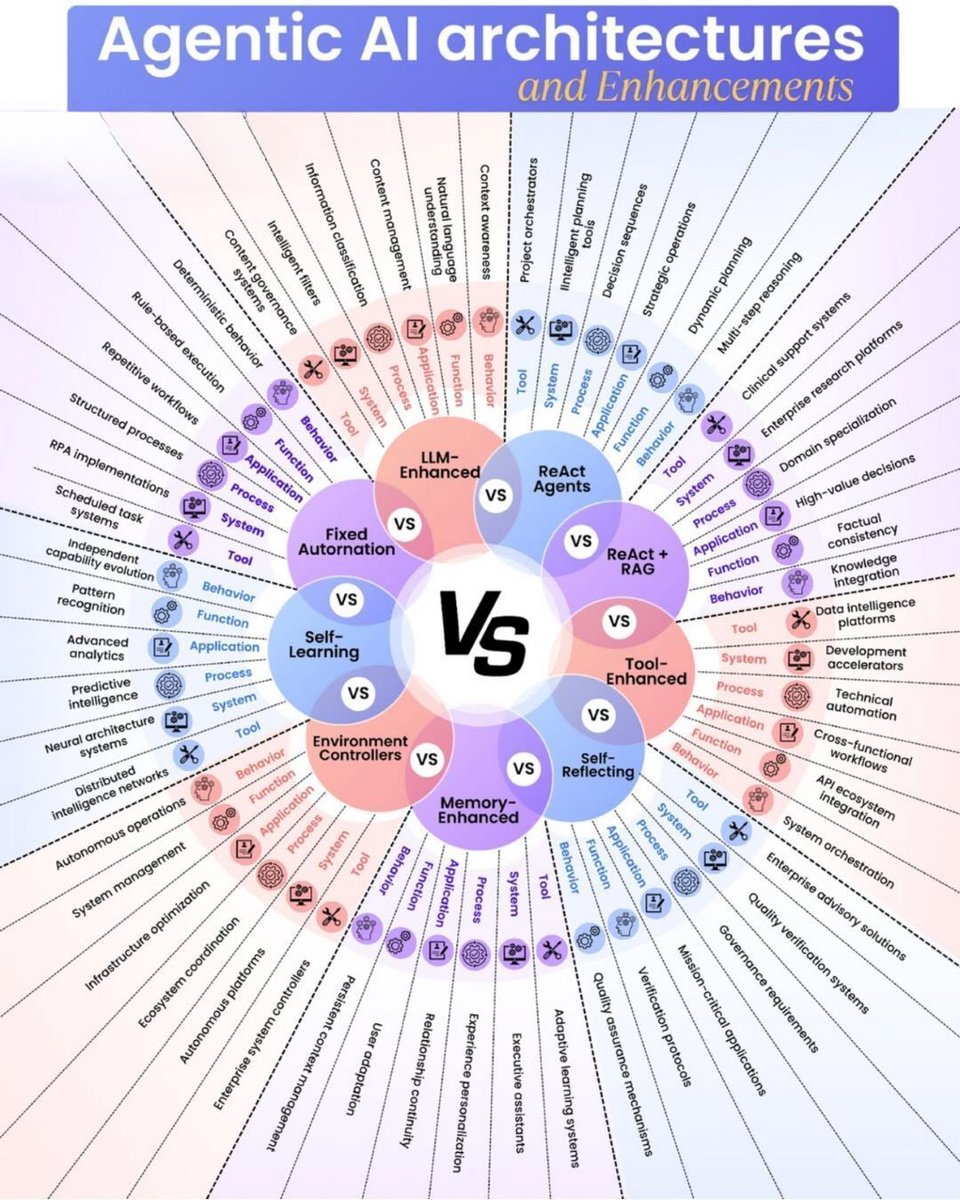
#AgenticAI Architecture
by @Python_Dv
#AI #GenAI #LLM #GenerativeAI #ArtificialIntelligence #MachineLearning
2
31
91
4,173
Marcus Borba retweeted

28 Nov 2025
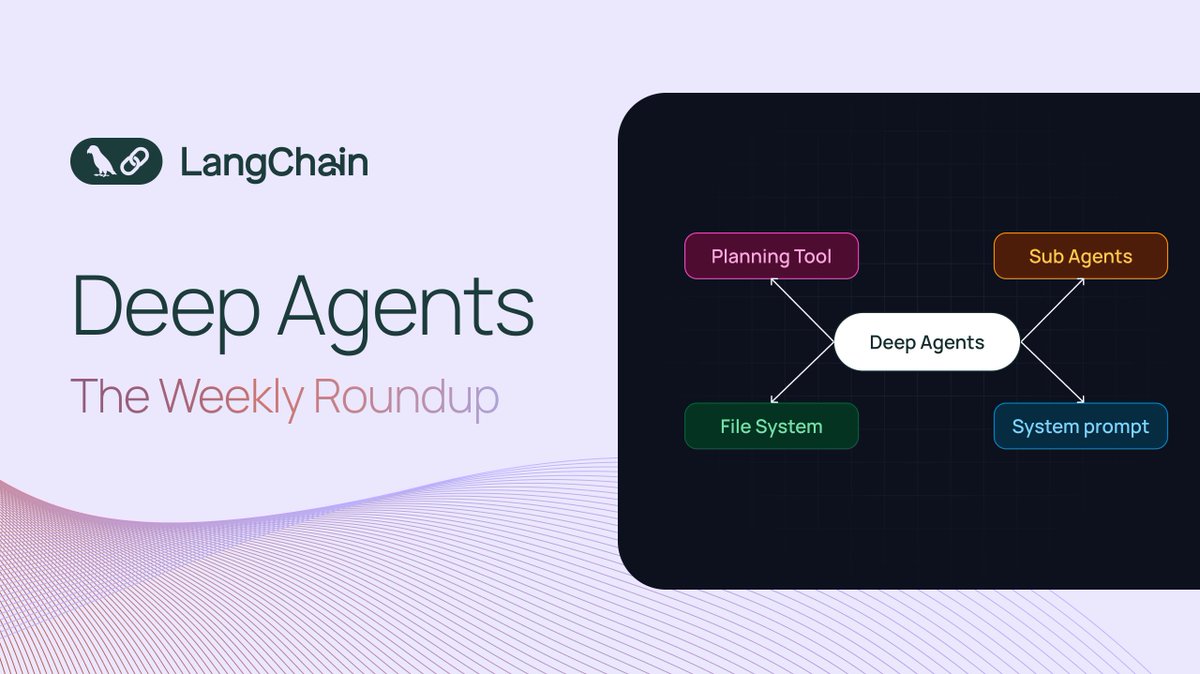
🚀 Deep Agents: The Weekly Roundup 🚀
Dive into our new resources to help you build Deep Agents capable of handling complex, long-running tasks.
✏️ Context engineering is key to reliable agents. Deep agents need detailed context and prompts, and filesystems can help manage that context. We wrote up some strategies for using filesystems to improve agent reliability. Read the blog: blog.langchain.com/how-agent…
🤷♀️ What are Deep Agents? - We break down the key things to know when you’re building an agent to handle more complex tasks. Watch the video: youtube.com/watch?v=IVts6ztr…
⚽ Using Skills with Deep Agents CLI - Agent skills are now available in the Deep Agents CLI, enabling you to use the large and growing collection of public skills with your agents. Watch the video: youtu.be/Yl_mdp2IiW4/?utm_me… & blog: blog.langchain.com/using-ski…
📚 LangChain Academy Course - If you’re not sure how to get started, our free LangChain Academy course covers the four features that set Deep Agents apart: planning, file systems, sub-agents, and prompting. By the end, you'll design, implement, and deploy your own. Enroll now: academy.langchain.com/course…
4
49
264
22,839
Marcus Borba retweeted

28 Nov 2025
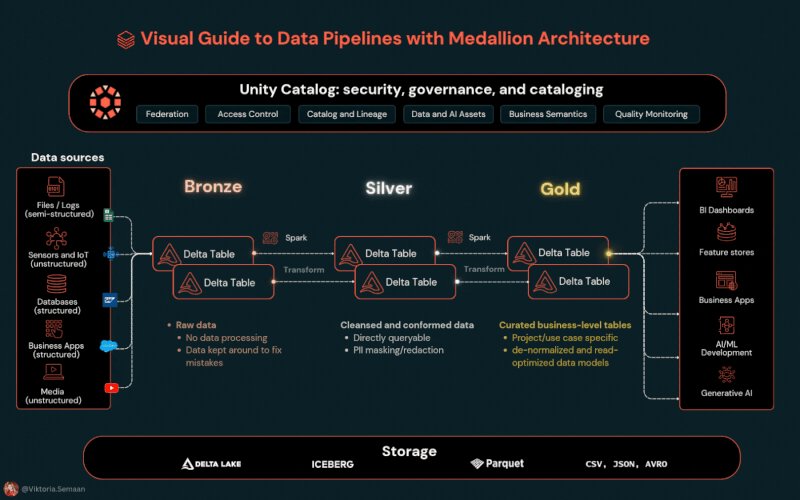
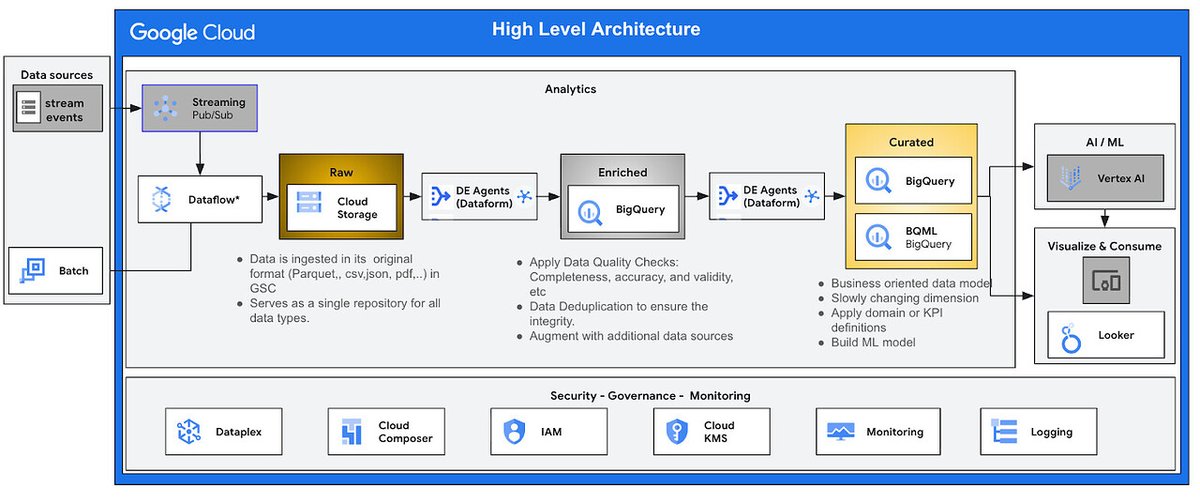
Tired of manually building data pipelines?
Learn how to build a Medallion Architecture in #BigQuery using just natural language. The new Data Engineering Agent turns simple prompts into bronze, silver, and gold layers with complex data quality rules → goo.gle/4abwe62
ALT High level architecture.
9
39
227
19,421
Marcus Borba retweeted

29 Nov 2025
85 AI Terms Explained

3
187
856
32,670
Marcus Borba retweeted
28 Nov 2025
AI adoption is booming, with 72% of workers now using it in their day-to-day work. The next opportunity? Building AI agents for automating repetitive tasks and speeding up tasks that require deep research.
With only 13% of teams having integrated agents into their workflows so far, we've launched two new courses to help you take the next step: AI Agent Fundamentals and Get Started with AI Agents: databricks.com/blog/master-a…

6
22
65
5,646
Marcus Borba retweeted

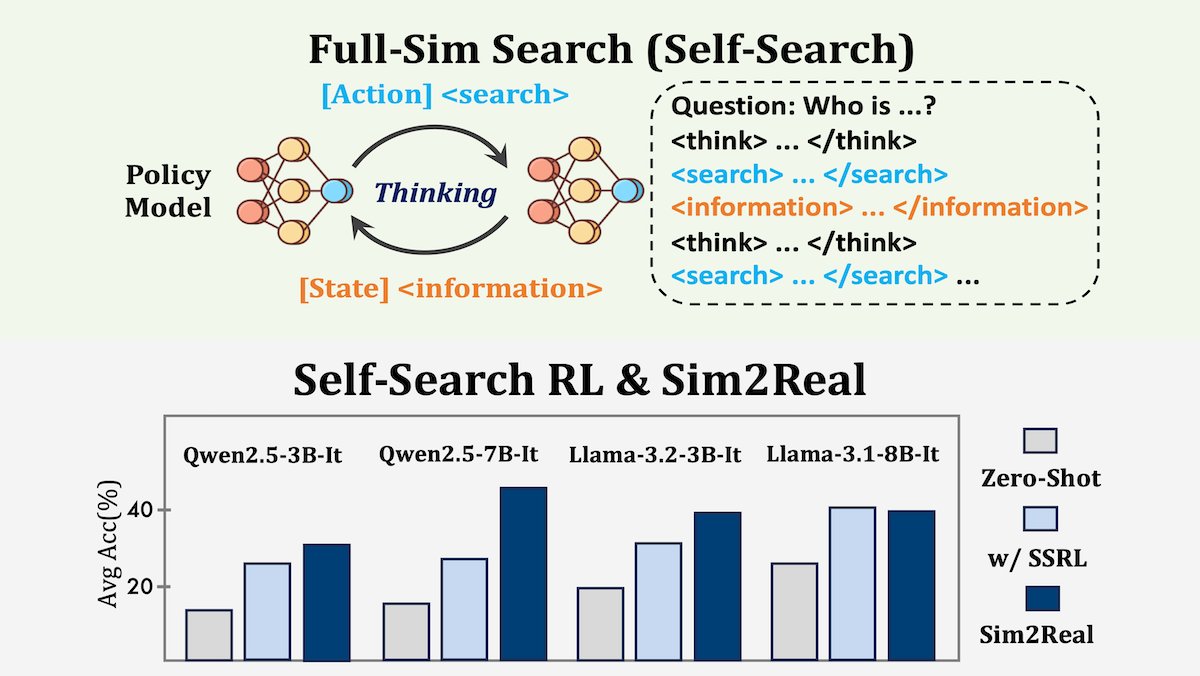
26 Nov 2025
Researchers introduced Self-Search Reinforcement Learning (SSRL), a method that teaches language models to simulate web searches to better retrieve information from their own parameters.
SSRL fine-tuning improved accuracy on multiple question-answering benchmarks and even boosted performance when paired with real web search tools.
Read our summary of the paper in The Batch: hubs.la/Q03VV2d-0
9
26
161
11,689
Marcus Borba retweeted

30 Oct 2025
10 Python Books for FREE — Master Python from Basics to Advanced
clcoding.com/2025/10/10-pyth…

6
155
879
46,539
Marcus Borba retweeted

30 Oct 2025
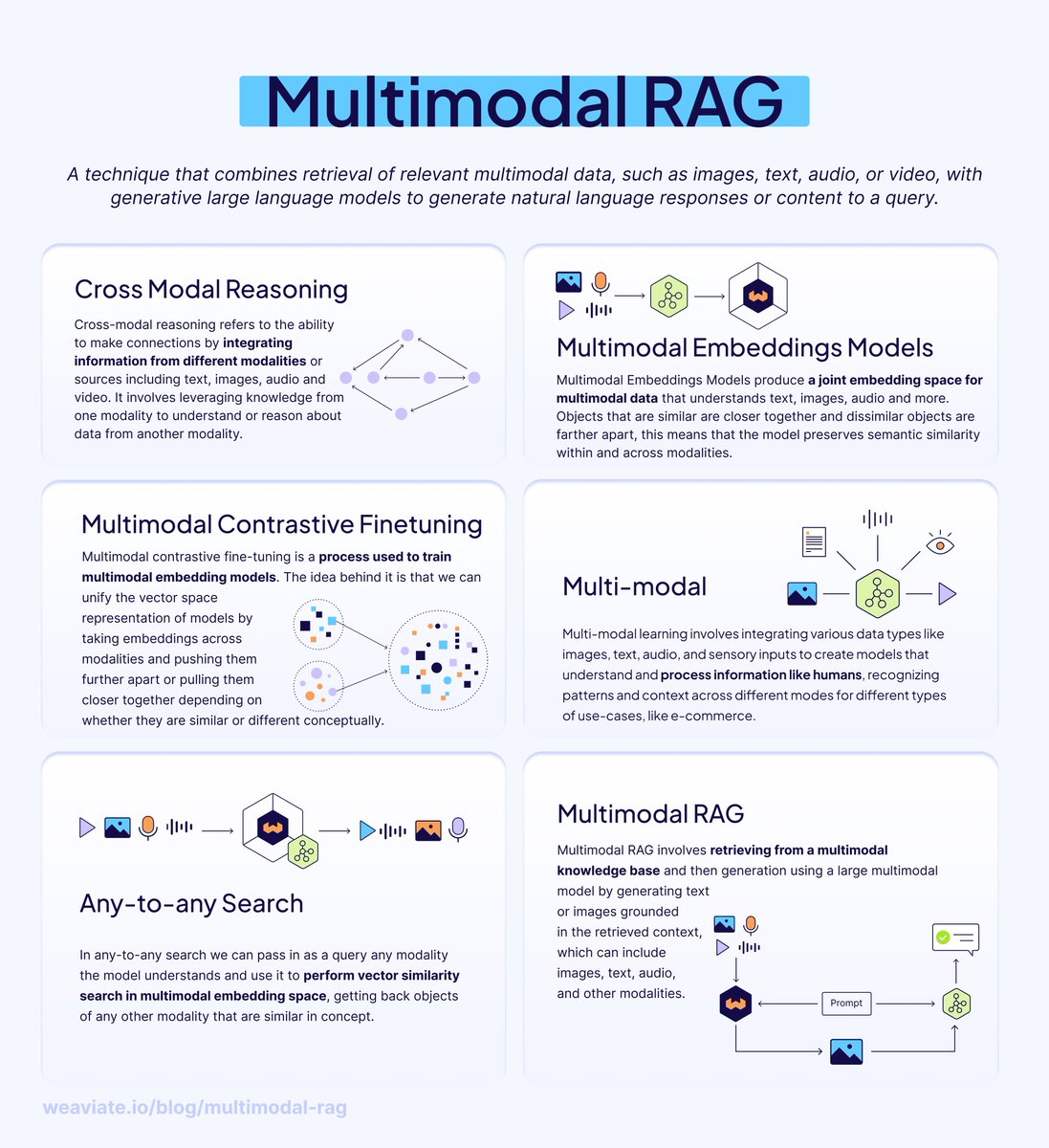
We process the world through all of our senses, not just text.
Your AI shouldn't be stuck with just one.
Humans don't process information in just one format - we digest information with photos, graphs, charts, and more to understand the world. Why should our AI systems be limited to text-only retrieval?
Enter 𝗠𝘂𝗹𝘁𝗶𝗺𝗼𝗱𝗮𝗹 𝗥𝗔𝗚 - retrieval augmented generation that works across multiple modalities like images and text.
In this new Free @DataCamp course with @_jphwang, you’ll learn exactly how to go from simple LLM calls to multi-modal RAG workflows with Weaviate. Sign up here: datacamp.com/courses/end-to-…
𝗦𝗼, 𝗵𝗼𝘄 𝗱𝗼𝗲𝘀 𝗺𝘂𝗹𝘁𝗶𝗺𝗼𝗱𝗮𝗹 𝗥𝗔𝗚 𝘄𝗼𝗿𝗸?
𝗠𝘂𝗹𝘁𝗶𝗺𝗼𝗱𝗮𝗹 𝗘𝗺𝗯𝗲𝗱𝗱𝗶𝗻𝗴 𝗠𝗼𝗱𝗲𝗹𝘀
These models understand multiple data types in a 𝘫𝘰𝘪𝘯𝘵 𝘦𝘮𝘣𝘦𝘥𝘥𝘪𝘯𝘨 𝘴𝘱𝘢𝘤𝘦 - meaning similar concepts cluster together regardless of whether they're images, text, audio, or video.
𝗔𝗻𝘆-𝘁𝗼-𝗔𝗻𝘆 𝗦𝗲𝗮𝗿𝗰𝗵
Once modalities share an embedding space, you can search across them:
• Use text queries to find relevant images
• Search with audio to retrieve matching video clips
• Find text descriptions from image inputs
This is 𝗰𝗿𝗼𝘀𝘀-𝗺𝗼𝗱𝗮𝗹 𝗿𝗲𝗮𝘀𝗼𝗻𝗶𝗻𝗴 in action - understanding relationships and context across different data types, just like humans do naturally.
𝗠𝘂𝗹𝘁𝗶𝗺𝗼𝗱𝗮𝗹 𝗥𝗔𝗚 𝗶𝗻 𝗣𝗿𝗮𝗰𝘁𝗶𝗰𝗲
Instead of just retrieving text documents, multimodal RAG retrieves relevant images, diagrams, charts, or videos to augment LLM responses. This enables:
• Visual question answering systems
• Richer context for generation
• More comprehensive and accurate outputs
𝗧𝗿𝗮𝗱𝗲-𝗼𝗳𝗳𝘀 𝘁𝗼 𝗰𝗼𝗻𝘀𝗶𝗱𝗲𝗿:
• Requires aligned multimodal datasets (challenging to collect)
• More complex model architectures than single-modality systems
• Higher computational costs for training and inference
𝗚𝗲𝘁𝘁𝗶𝗻𝗴 𝘀𝘁𝗮𝗿𝘁𝗲𝗱 𝘄𝗶𝘁𝗵 𝗪𝗲𝗮𝘃𝗶𝗮𝘁𝗲:
Weaviate already integrates with multimodal embedding models from Cohere, Google, NVIDIA, Hugging Face, and more. This allows you to use embeddings in a joint space, enabling nearVector and nearImage searches across both modalities.
Download this free Advanced RAG guide for the full picture: weaviate.io/ebooks/advanced-…
10
98
401
19,652
Marcus Borba retweeted

30 Oct 2025
13 Complete YouTube Courses for Programming:
1. Python
youtube.com/playlist?list=PL…
2. SQL
youtube.com/playlist?list=PL…
3. JavaScript
youtube.com/playlist?list=PL…
4. Java
youtube.com/playlist?list=PL…
5. C
youtube.com/watch?v=FpfHmAkR…
6. Rust
youtube.com/playlist?list=PL…
7. Golang
youtube.com/playlist?list=PL…
8. C#
youtube.com/watch?v=0QUgvfuK…
9. Kotlin
youtube.com/watch?v=TEXaoSC_…
10. Swift
youtube.com/watch?v=CwA1VWP0…
11. PHP
youtube.com/playlist?list=PL…
12. C
youtube.com/playlist?list=PL…
13. DSA
youtube.com/playlist?list=PL…



45
612
2,736
162,184