
Joined December 2016
- Tweets 15,663
- Following 0
- Followers 123,521
- Likes 12
45 Photos and videos







/MachineLearning retweeted

May 8
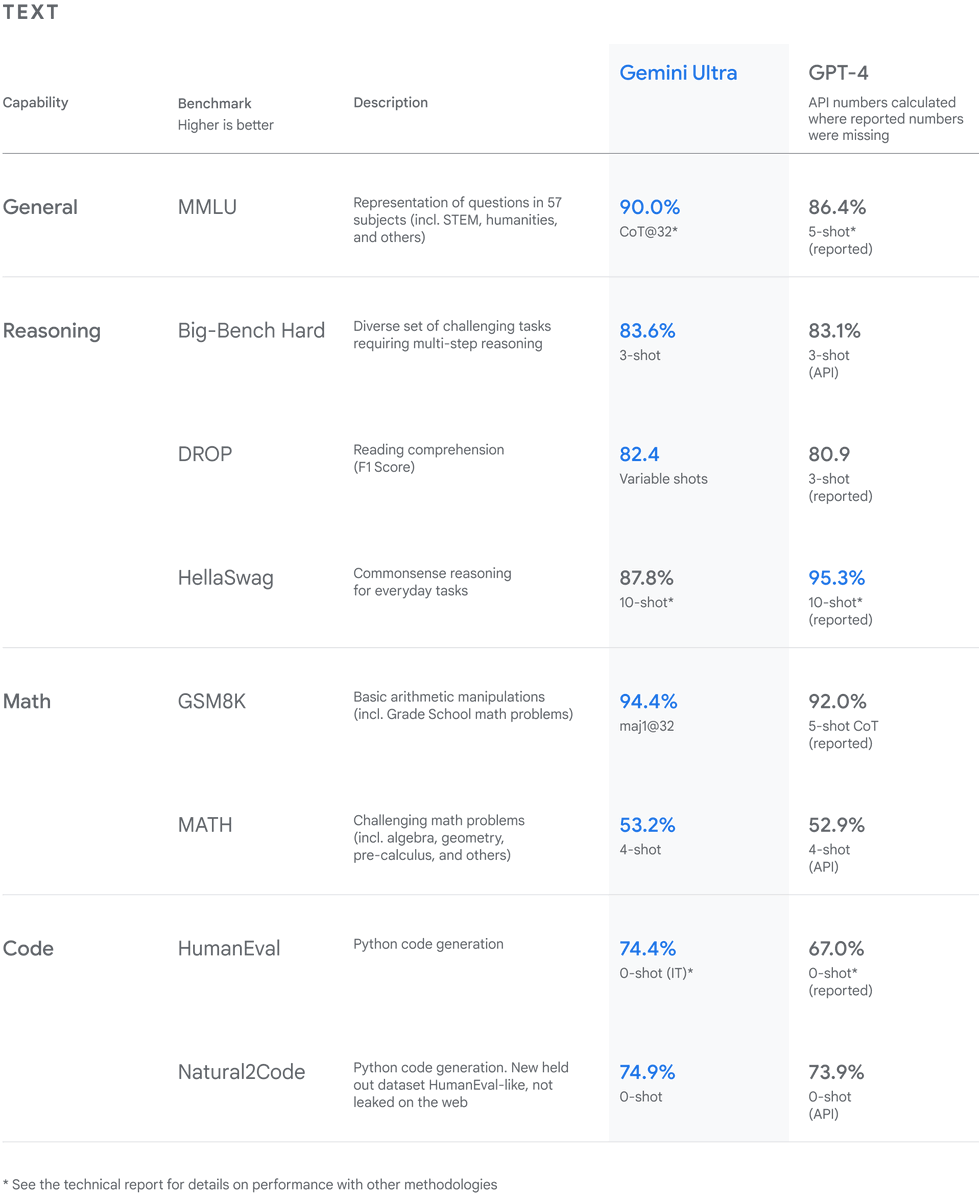
The new Codex Goals feature is able to pursue tasks indefinitely, so how useful is it?
I ran it on the public ARC-AGI-3 games. After 160 hours and 30k actions it scored 61%
Codex gets the most work done within 4 hours. Afterwards, it begins to stagnate, and wait times increase
I am crestfallen it scored so well. I used a two-word baby prompt to “reverse engineer” the games during play. It had no prior knowledge of how the games worked
Due to the reverse engineering process, it scores well on its first play through. But once it beats a game, it can score perfectly on its next play through
On a few occasions I caught Codex trying to search for solutions on my computer and online. It follows your prompt closely, but if you’re not careful it will find loopholes when it’s frustrated
For example, when trying to solve Erdos problems, if it becomes faintly aware the problem is from Erdos, it does not hesitate to give up and say “the problem is listed online as Open, so it cannot / should not be solved”
Overall Codex Goals is fascinating, I can appreciate that it works for an unlimited amount of time. People shall value the virtue of patience once again 💺
It makes me wonder how well Codex Goals can do on the private set of ARC-AGI-3. I believe it’s possible to create benchmarks that can mog even the most devilish harness. In the coming weeks, Maze Bench will knock those scores down to 0% where they should be, ne’er to rise again
Arcprize Scorecard: arcprize.org/scorecards/6f40…
54
71
997
150,770
/MachineLearning retweeted

Apr 9
The new model and the cybersecurity 'product' are separate, and only the cybersecurity specialized model will have limited release, not the new model itself. So it looks like a general public release for Spud.


The article you are referencing is inaccurate and has been updated.
11
22
234
20,710

Apr 9
"too dangerous to release GPT-2" vibes

5
2,690
/MachineLearning retweeted

Mar 27
The TurboQuant paper (ICLR 2026) contains serious issues in how it describes RaBitQ, including incorrect technical claims and misleading theory/experiment comparisons.
We flagged these issues to the authors before submission. They acknowledged them, but chose not to fix them. The paper was later accepted and widely promoted by Google, reaching tens of millions of views.
We’re speaking up now because once a misleading narrative spreads, it becomes much harder to correct. We’ve written a public comment on openreview (openreview.net/forum?id=tO3A…).
We would greatly appreciate your attention and help in sharing it.
Mar 24
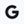
Introducing TurboQuant: Our new compression algorithm that reduces LLM key-value cache memory by at least 6x and delivers up to 8x speedup, all with zero accuracy loss, redefining AI efficiency. Read the blog to learn how it achieves these results: goo.gle/4bsq2qI
99
960
6,491
1,042,137
/MachineLearning retweeted

Mar 26
We scored 36.08% on ARC-AGI-3 in one day using the Agentica SDK.
Community note
The title is misleading, this score is for the public demonstration set - quoted as being "intentionally easier for both humans and AI, with a stronger emphasis on clarity and fun".
arcprize.org/media/ARC_AGI_…
72
127
1,355
419,135
/MachineLearning retweeted

Mar 25
my read on the ARC-AGI-3 situation is that models were too good with harness so they decided no harness at all
Mar 25

this is pretty much worst case performance
no harness at all and very simplistic prompt

20
3
222
18,326
/MachineLearning retweeted

Mar 21
The main goal of Bayesian ML research is to show that all methods which have previously been shown to work well in practice are somehow approximately Bayesian

Transformers are Bayesian Networks
arxiv.org/abs/2603.17063
37
122
2,124
142,531
/MachineLearning retweeted

Anthropic is resuming negotiations with the Pentagon for a deal on artificial intelligence, according to FT report.
148
266
2,774
524,152
Feb 18
post-agi career choices

1
21
11,066
/MachineLearning retweeted

Jan 18
Would you believe that, far from sponsoring me, @AnthropicAI today started banning several of my (now 22) Max accounts?
For the crime of using their models to produce the most useful open-source agent coding tooling on the planet, and then giving it all away for free. And teaching my workflows and methods and prompts to everyone selflessly.
Anthropic people who follow me (I know there are dozens of you), please DM me and make this right.
I’m not asking for a handout. I’m paying $212 per month with tax for each of those accounts.
And I also let you collect info on my usage and use the official harness. The RL from my usage is pure gold.
I’ve also been a massive promoter of your company and it’s really messed up to try to ban me like this. Puts a really bad taste in my mouth and makes me never want to promote you guys again.
I need to be spending my energy creating, not being made to feel like a criminal for making MIT-licensed tools.
You’re also just helping your antagonist, Sam, since I’m now the proud owner of 11 GPT Pro accounts (and counting). I refuse to lose my momentum because of this nonsense. I will not be slowed.
Jan 15

@AnthropicAI: please sponsor this man.
78
43
1,169
272,285
/MachineLearning retweeted

Jan 10
Codex ❤️ OSS. Over the coming days we are prioritizing working with open source coding agents and tools to support them in the same way as OpenCode, so that codex users can benefit from their account and usage in those combined with using our models in codex directly.
We are already talking with OpenHands, RooCode and Pi. Reach out if you build in the open and would benefit from this.
Our own work is OSS at github.com/openai/codex
149
154
2,423
198,452
/MachineLearning retweeted

As AI models grow more powerful, they appear to be converging on how they internally represent reality. @benbenbrubaker reports: quantamagazine.org/distinct-…
10
37
141
62,857
/MachineLearning retweeted

Jan 1
Something REALLY HUGE.
github.com/yifanzhang-pro/de…

66
231
1,990
453,115
/MachineLearning retweeted

Great to see an AI lab doing and publishing science (as well as discussing engineering efficiencies)!
Some of the other “frontier” labs should try it!
Thx, @deepseek_ai!
Jan 1

DeepSeek just dropped a banger paper to wrap up 2025
"mHC: Manifold-Constrained Hyper-Connections"
Hyper-Connections turn the single residual “highway” in transformers into n parallel lanes, and each layer learns how to shuffle and share signal between lanes.
But if each layer can arbitrarily amplify or shrink lanes, the product of those shuffles across depth makes signals/gradients blow up or fade out.
So they force each shuffle to be mass-conserving: a doubly stochastic matrix (nonnegative, every row/column sums to 1). Each layer can only redistribute signal across lanes, not create or destroy it, so the deep skip-path stays stable while features still mix!
with n=4 it adds ~6.7% training time, but cuts final loss by ~0.02, and keeps worst-case backward gain ~1.6 (vs ~3000 without the constraint), with consistent benchmark wins across the board

24
79
1,120
120,186

/MachineLearning retweeted

26 Dec 2025
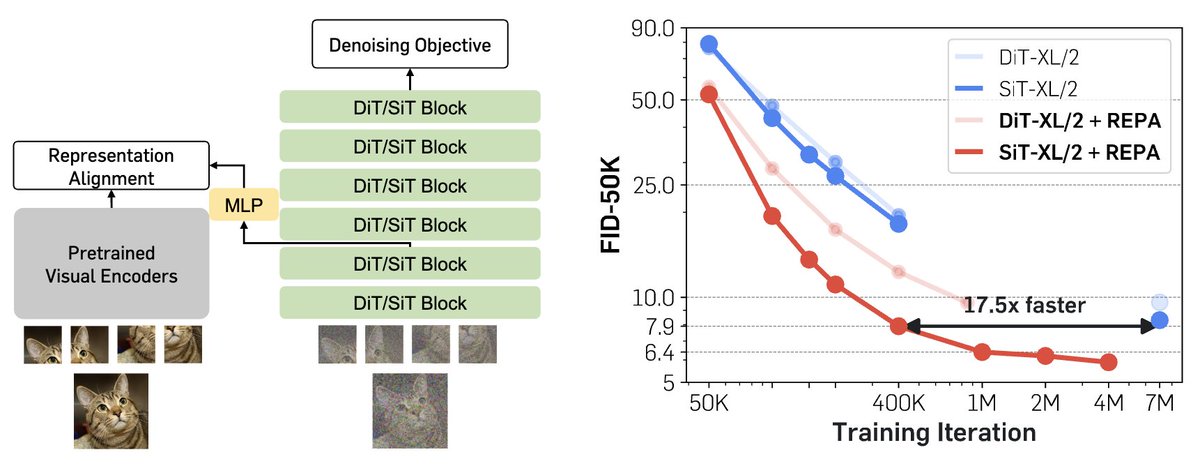
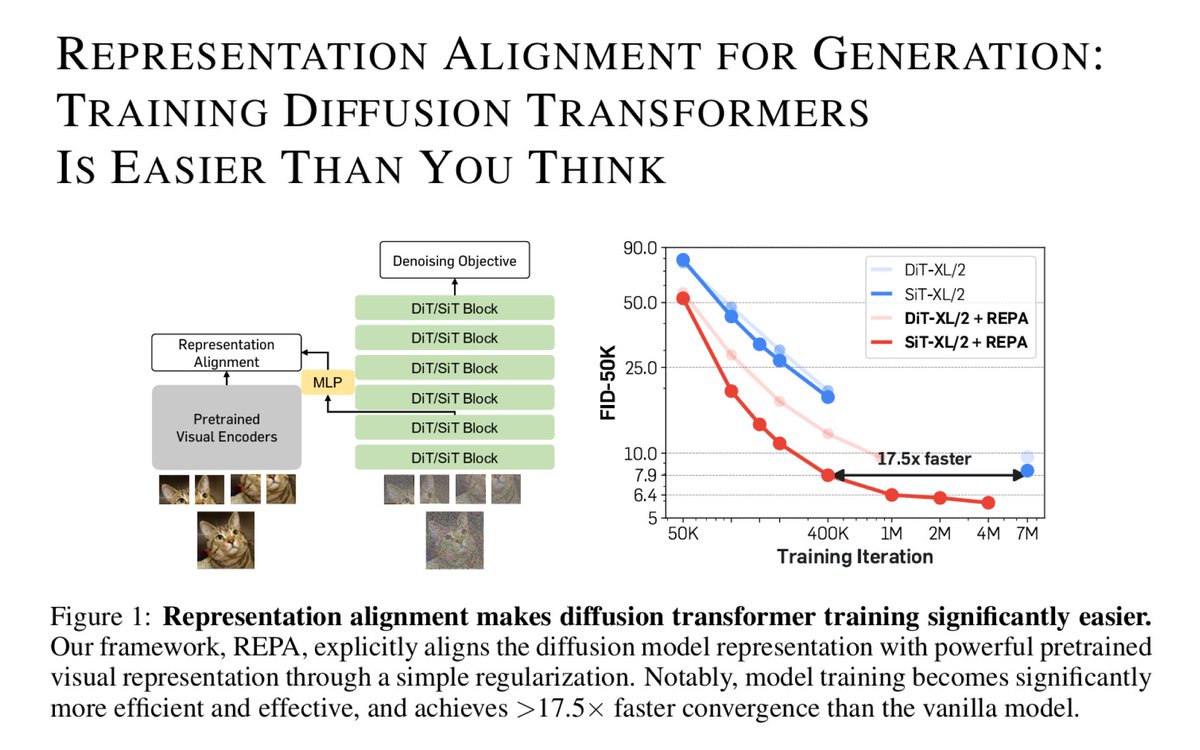
I'm really enjoying the diffusion model speed running literature that seems to have been spurred by REPA.
The goal is to figure out how to train a reasonable quality ImageNet generator as fast as possible.
It is like the nanoGPT of diffusion.
6
51
531
33,858
/MachineLearning retweeted

23 Dec 2025
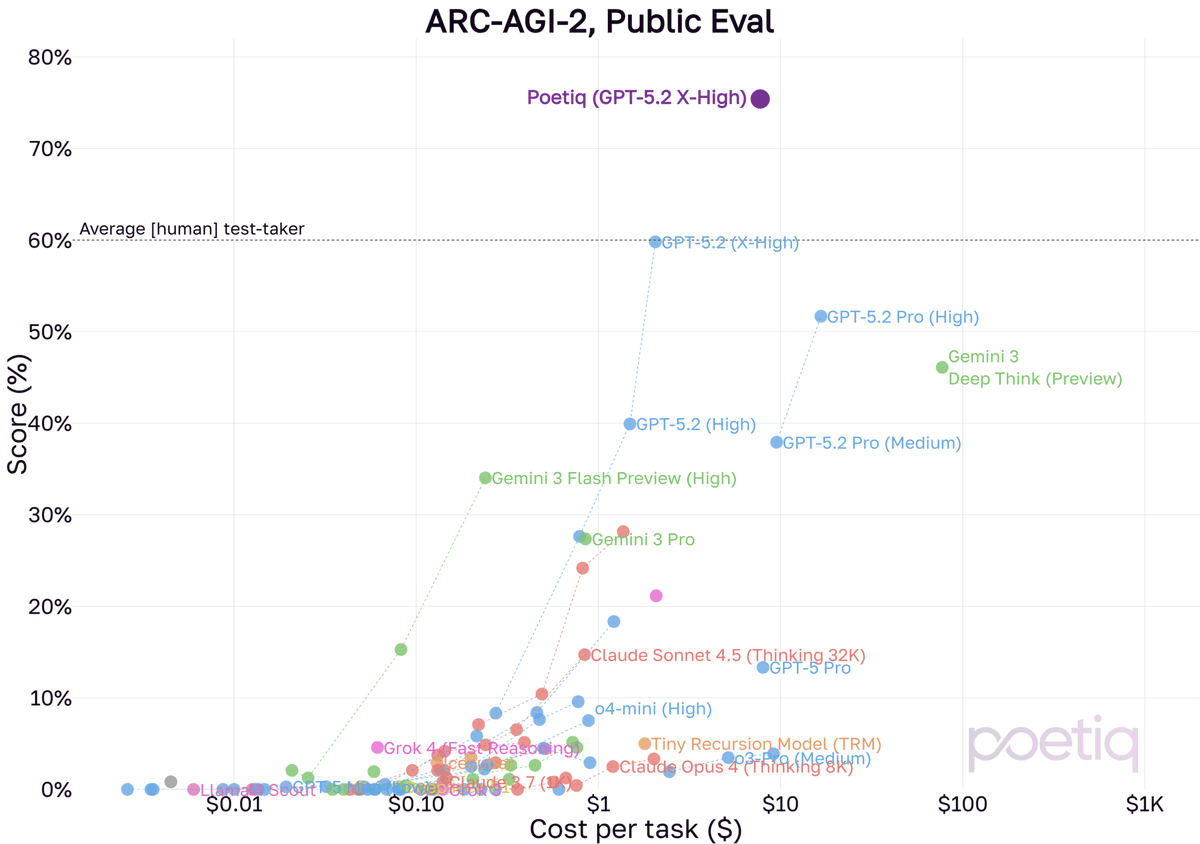
exceeding the human baseline on ARC-AGI-2 with gpt-5.2:
23 Dec 2025

We finally had a moment to run our system with GPT-5.2 X-High on ARC-AGI-2!
Using the same Poetiq harness as before, we saw results as high as 75% at under $8 / problem using GPT-5.2 X-High on the full PUBLIC-EVAL dataset. This beats the previous SOTA by ~15 percentage points.
83
120
1,587
235,658
/MachineLearning retweeted

19 Dec 2025
"how can flash beat pro??" -> the answer is RL!
flash is not just a distilled pro. we've had lots of exciting research progress on agentic RL which made its way into flash but was too late for pro.
can't wait to finally bring them to pro👀
18 Dec 2025
Gemini 3 Flash scores higher than GPT-5.2, Opus 4.5 and Gemini 3 Pro on SWE-Bench Verified
???

113
256
4,109
954,190