
The LLM post-training framework for RL Scaling. github.com/THUDM/slime
Joined September 2025
- Tweets 77
- Following 12
- Followers 1,253
- Likes 30
3 Photos and videos
Pinned Tweet

Jun 1
🚀 slime v0.3.0 is out!
This release is a major step toward agent-first RL.
We turned slime’s existing multi-turn / agentic capabilities into a more coherent foundation:
- slime/agent with reusable sandbox-agent components
- OpenAI / Anthropic-compatible adapters
- black-box coding-agent RL example
- variable global batch-size training
- fully async training as a first-class path
- lower host-memory usage for more flexible rollout-inference setups
- PPO refactor with actor-critic colocation
- delta weight sync, FlashQLA for Qwen GDN, --save-hf, and more CI coverage
slime is moving closer to a practical open-source framework for large-scale agentic RL.
Release note:
github.com/THUDM/slime/relea…
1
14
81
8,236

Intelligence should be open, accessible, and ready to build with, empowering every developer, everywhere.
GLM-5.2 is now available to all GLM Coding Plan users, including Lite, Pro, Max, and Team plans.
docs.z.ai/devpack/latest-mod…
As our new flagship model, GLM-5.2 delivers powerful coding capabilities, usable 1M-context support, and continued strengths in long-horizon tasks.
API and Chatbot services will launch next week. The model will also be officially open-sourced next week under the MIT License.
The future of AI is open, and it belongs to the people.
286
820
6,767
1,218,328
Jun 10
Congrats to the vLLM team on vime!
Happy to see slime’s training design inspiring more open RL post-training work. The space benefits from more interoperable systems, more production feedback, and more choices for users.
Looking forward to seeing the ecosystem continue to grow.
Jun 9

Today we're excited to introduce vime — a simple, stable, and efficient RL framework for LLM post-training in the vLLM ecosystem.
Built on slime's proven training design and powered by vLLM inference, vime brings another strong option to the growing vLLM post-training ecosystem.
Our goal isn't a one-size-fits-all framework. We want users with different needs to find the right vLLM-ecosystem choice for their workflows—whether that's vime, NeMo RL, OpenRLHF, verl, or others.
More choice. More interoperability. More innovation.
Learn more: vllm.ai/blog/2026-06-09-anno…
#LLM #RLHF #PostTraining #vLLM
1
23
2,295

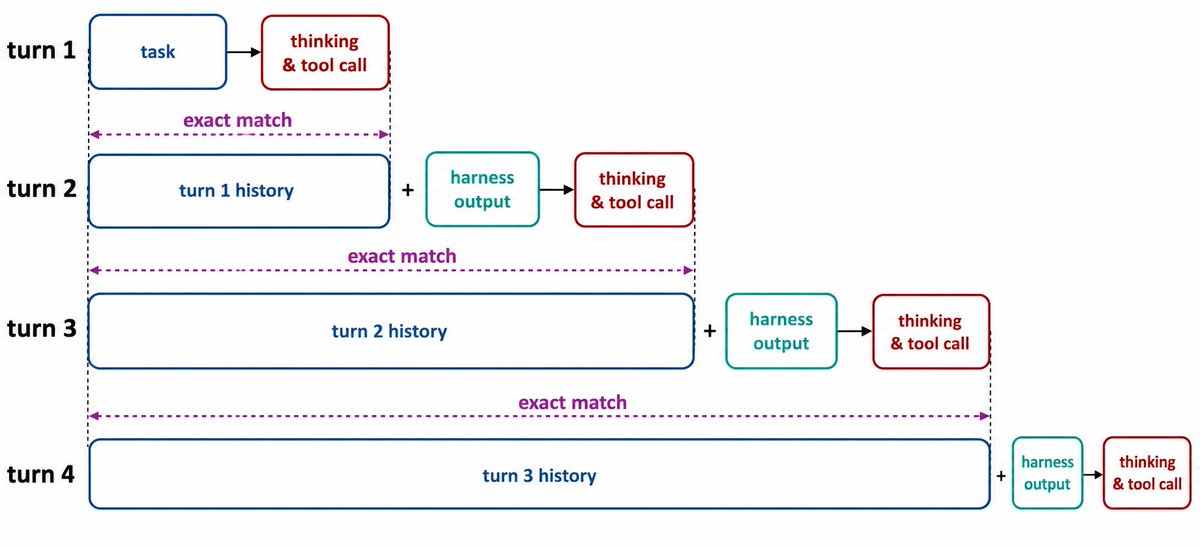
📝 New blog: No Token Left Behind: Demystifying Token-In-Token-Out in Miles
In agentic RL, a rollout is a chain of model calls, tool outputs & resumed turns. Token-In-Token-Out (TITO) ensures the trainer evaluates the exact tokens the inference engine produced — break it, and training silently drifts off-policy.
Why it matters:
📦 One sample per task, not per turn: ~10× less compute on 30–50 turn trajectories
🎯 Keeps every token on-policy
How Miles enforces it:
1️⃣ Inference session server: one append-only token buffer per trajectory
2️⃣ Append-only at 3 levels: messages, template rendering, tokens
3️⃣ Pluggable TITO tokenizer: incremental tokenize per-model splice patches
4️⃣ TokenSeqComparator: verifies every rollout stays bit-perfect
Supports Qwen3, GLM, Kimi-K2, Nemotron, Minimax & DeepSeek families.
1
15
137
22,583
Jun 9
Excited to see @Apodex_AI’s agentic RL work built on Miles, @radixark’s independent fork of slime!
We’re happy to see more teams choosing this architecture for industrial-grade agentic RL. This is exactly why we built slime to be clean, extensible, and production-oriented.
Jun 8
Meet 𝗔𝗽𝗼𝗱𝗲𝘅 𝟭.𝟬 🔭 — a heavy-duty agent team for deep research, which sets the SOTA! The team searches the web, reasons over evidence, and writes reports where every claim is backed by an explicit 𝘦𝘷𝘪𝘥𝘦𝘯𝘤𝘦 𝘤𝘩𝘢𝘪𝘯, independently audited before delivery.
🌐 apodex.ai

2
6
37
4,311
Jun 6
A nice community contribution just landed in slime.
--balance-data now uses FLOPs-aware balancing by default, instead of only balancing by token counts.
This gives a finer-grained estimate of per-sample compute when sequence lengths vary a lot. In the contributed benchmarks, it reduced actor training time by up to 30% and improved training throughput by up to 24%.
Small infra details matter a lot for large-scale RL!
github.com/THUDM/slime/pull/…
3
25
1,467
Jun 5
Most RL frameworks are moving from “engine mode” to “server mode”.
slime goes one step further: the RL job does not need to own the rollout servers at all.
Bring your own SGLang fleet, already deployed and managed by your serving system. slime connects to it, registers it with the router, generates rollouts, and syncs updated actor weights via NCCL or disk-based full/delta transport.
This is the deployment shape we believe large-scale agentic RL is moving toward: training and inference as independently managed systems, connected by a clean rollout weight-sync contract.
5
13
143
25,038
Jun 5
This builds on the work we did with @modal , but pushes the boundary further.
In addition to externally managed rollout servers, slime now supports standard update_weights_from_disk, making this deployment pattern much easier to adopt in real systems.
The value is not only Fireworks-style geo-distributed inference. It also means the rollout side only needs an SGLang serving environment, without sharing the training stack, Megatron environment, or even the same hardware type.
As long as there is an SGLang server running somewhere, slime can turn it into part of the rollout fleet.
3
2
18
1,480
Jun 5
This is now supported in slime via --rollout-external-engine-addrs.
Start your SGLang servers independently, pass their addresses to the slime training job, and slime will discover the engines, attach them to the router, and use them as rollout capacity.
For weight sync, choose the path that matches your deployment:
- NCCL when trainer and engines can form a communication group
- full update_weights_from_disk when you want the simplest external setup
- delta disk transport when full checkpoints become too expensive across clusters or datacenters
PR: github.com/THUDM/slime/pull/…
Doc: thudm.github.io/slime/advanc…
2
2
16
1,217
Jun 3
Huge congrats to the Microsoft AI team on MAI-Thinking-1.
Great to see large-scale RL systems converging around the SGLang Ray ecosystem. Rocket’s design—async RL, separated rollout / inference / learner pools, router-based traffic control, prefix caching, and fault-tolerant inference—is very aligned with what we believe in slime: RL is not just an algorithm problem, but a full-stack infrastructure problem.
Excited to see more open RL infra ideas validated at frontier scale!

Huge milestone for the Microsoft AI team: seven frontier MAI models, led by MAI-Thinking-1. Proud that SGLang powered the RL inference stack behind it. Their Rocket framework runs SGLang and the SGLang router for load balancing, traffic control, prefix caching, and graceful failure recovery across thousands of inference chips.
Congrats to the team @MicrosoftAI 👏
Read more on how SGLang powers the stack: microsoft.ai/wp-content/uplo…
2
4
66
8,056
slime retweeted

Jun 2
slime v0.3.0: Built for the Agent Era
🌟 Insights from Zhihu contributor @朱小霖
@zhuzilinallen
There's little doubt that OpenClaw and Opus have kicked open the door to the Agent era.
slime's server-based engine custom rollout architecture was built with this direction in mind. But as Agents become real-world workloads, it's clear that an RL framework needs more than basic Agent support—it needs better inference orchestration, long-horizon training, environment integration, and maintainable engineering practices.
That's exactly what slime v0.3.0 is about:
🔗 github.com/THUDM/slime/relea…
🚀 Agent-Native Infrastructure
The biggest risk for an RL framework isn't lacking features—it's chasing a new trend by piling temporary fixes onto an existing design. Agent training makes this especially tempting.
Instead of treating Agent support as one giant feature, we break it down into a series of infrastructure problems and solve them one by one.
🎱 Like in snooker, you don't clear the table with a single shot—you gradually create a better position. Many of the updates in slime v0.3.0 follow exactly this philosophy.
At its core, an RL framework is still about two things: inference and training. Let's look at them separately.
Faster & More Flexible Inference
Agent workloads dramatically increase token consumption and put much higher demands on serving systems. Two requirements stand out:
• Fast rollouts for long-horizon, multi-turn, tool-heavy tasks
• Production-like inference configurations so models can transition naturally from pretraining/SFT into deployment
To support this, slime expanded SGLang deployment with YAML-based multi-server configurations, allowing users to build composable server/router topologies instead of relying on a single inference setup.
📖 Docs:
thudm.github.io/slime/advanc…
Many users now use slime as a launcher for complex SGLang clusters, which suggests people need more than an RL framework—they need a reliable infrastructure entry point.
We also improved --debug-rollout-only, making rollout-only and serving-only deployments much closer to production environments by cleanly separating inference and training resources.
Another trend we've observed: multi-turn interactions and tool usage significantly increase prefill pressure. Cache hit rates and memory capacity now directly impact rollout throughput.
Inspired by optimizations from the Miles team:
🔗 github.com/radixark/miles/pu…
slime no longer offloads fp32 gradients and bf16 parameters in integrated training-serving workloads, saving roughly 6× parameter memory and improving rollout speed for Agent tasks.
🧠 Training for Long-Horizon Agents
On the training side, the focus shifts from infrastructure to algorithm design.
slime v0.3.0 adds support for compact and subagent workflows, where one prompt can generate multiple training samples.
Previously, frameworks often had to either:
• discard samples, wasting rollout data; or
• pad batches, increasing compute and memory costs.
Now, batch sizes can adapt dynamically to rollout results, eliminating both compromises while preserving proper normalization across related samples.
Long-horizon tasks are also driving renewed interest in reward shaping, value functions, and PPO-style algorithms.
To support this, slime rebuilt its PPO implementation so that actor and critic always share GPU resources, allowing users to move from GRPO to PPO without allocating an entirely separate GPU cluster.
It also supports independent Megatron configurations for actor and critic.
📖 Docs:
thudm.github.io/slime/advanc…
Meanwhile, as Agent rollouts grow longer, more teams are adopting asynchronous training. In v0.3.0, fully async training has been promoted from an experimental example to a first-class feature, sharing the same interface as partial-rollout async workflows.
🤖 slime/agent:Solidify the common Agent components
While slime still encourages users to build their own custom harnesses, we've found that some Agent components are common enough to standardize.
That's why v0.3.0 introduces slime/agent/, including utilities like:
• trajectory merging
• OpenAI/Anthropic request interception
• reusable Agent tooling
We also released a complete Coding Agent RL example:
🔗 github.com/THUDM/slime/tree/…
The example demonstrates an end-to-end pipeline where Claude Code operates inside a real environment, interacts through SGLang endpoints, logs requests via an Anthropic adapter, generates rewards automatically, and converts trajectories into trainable RL data.
🛠️ Maintaining Open Source in the Agent Era
As coding agents improve, software projects may split into two categories:
Projects that can be rewritten every time a stronger model arrives.
Projects whose value comes from years of accumulated design decisions, testing, edge cases, and user trust.
Training frameworks belong to the second category.
That creates two major risks when relying heavily on coding agents:
• Attention DDoS — code volume grows faster than maintainers can review and understand it.
• Loss of ownership — developers stop understanding why systems are designed the way they are, and architecture quality gradually degrades.
Because of this, slime remains conservative in core development. AI is used as a collaborator, reviewer, and coding assistant—not as the primary architect.
On the other hand, we've aggressively used AI for testing and visualization. Over the past few months, this approach has helped us build extensive CPU-only test coverage and improve framework stability.
The goal is simple: make slime not only battle-tested at scale, but also one of the most rigorously tested open-source RL frameworks available.
slime is approaching its first open-source anniversary. What started as a project maintained by one or two people has grown into a team effort.
We hope v0.3.0 makes Agent RL easier to build—and helps slime remain clear, lightweight, and reliable as the Agent era unfolds.
⭐ If slime has been useful to you, consider giving it a star:
github.com/THUDM/slime
🔗Original article:zhuanlan.zhihu.com/p/2044533…
#AI #Agents #RLHF #ReinforcementLearning #OpenSource #LLM #AgenticAI #SGLang #DeepLearning




5
9
28
1,672
Jun 1
Modal put it clearly: frontier RL is no longer just about algorithms — it is an infrastructure problem.
Happy to see slime used in Modal’s RL stack, and even happier to see real upstream contributions coming back to the open-source ecosystem.
The RL infra stack is still early. Let’s build it together!

Reinforcement learning has exploded on Modal, and we've been cooking.
Here's a review of lessons learned helping teams train at scale, the patterns we kept seeing, and an open-source library to get started with RL on Modal quickly.
1
7
80
8,096
May 30
❤️
May 30

At @modal, we're working to make sure OSS RL frameworks have all the techniques necessary to train frontier open-weights models.
Delta compression is key, but the job's not done. There are still lots of open problems around weight sync, auto-scaling, & cross-cluster training.
My DMs are open!
12
1,348
May 30
@FireworksAI_HQ @cursor_ai highlighted why delta-compressed weight sync matters for RL at frontier scale.
slime brings this capability to OSS: lossless delta sync for Megatron ↔ SGLang disaggregation — ship deltas, not full checkpoints.
This is another step toward a fully open-source stack where rollout/inference and training are truly decoupled and deployed separately.
PR: github.com/THUDM/slime/pull/…
1
6
95
50,540
May 29
A couple of updates for Qwen 3.6 users in slime 🚀
• Merged FlashQLA support via PR #1947
→ Enable with --qwen-gdn-backend flashqla to use the official FlashQLA kernels and get the corresponding performance improvements.
• During the review and validation process, we uncovered an issue introduced during the SGLang 0.5.12.post1 upgrade that could affect some PD disaggregation deployments. The issue has now been fixed.
If you’ve recently run into PD-related issues, please pull the latest slime image and give it a try.
A nice example of how community contributions not only bring new features, but also help improve the robustness of the ecosystem ❤️
Huge thanks to everyone involved in the contribution and review!
PR: github.com/THUDM/slime/pull/…
6
26
2,348
May 29
Strongly agree.
As RL shifts from single-turn reasoning to long-horizon agents, rollout correctness becomes increasingly important.
A subtle re-tokenization mismatch can silently disconnect sampled trajectories from optimization targets, leading to gradients on sequences the model never actually generated.
This is why slime's multi-turn and agentic RL examples emphasize preserving sampled tokens across turns rather than reconstructing trajectories from rendered messages, including in black-box agent environments:
github.com/THUDM/slime/tree/…
Not an implementation detail — a learning correctness issue.
May 29

Most people training agentic LLMs with RL right now have a silently broken training loop and have no idea.
Here's the trap: single-turn RL works beautifully. Clean curves, sane rewards, everything converges. Then you add tools so the model can act mid-rollout, and things get weird. Loss spikes for no reason. Eventually a shape-mismatch error.
The culprit: every time you parse the model's output to detect a tool call, then re-tokenize the updated conversation for the next turn, you're rolling the dice. Usually the round-trip gives back the same tokens. Sometimes it doesn't and your gradient lands on a sequence the model never actually sampled. No crash. Just quietly wrong math and a useless gradient signal.
The fix is one rule: never re-encode tokens you've decoded. Keep the sampled tokens in one buffer, never re-render them, and both failure modes disappear. That's Token-In, Token-Out done right.
Our team just published a beautiful deep-dive on exactly this, including an audit across the major open-weights model families showing most chat templates already support it. Required reading if you're doing multi-turn RL 🤗🔥
qgallouedec-tito.hf.space/

1
13
131
14,165
May 27
slime was built for agentic RL from day 0.
We added an Agentic RL Training Roadmap that brings together the pieces already in slime for agent workflows: custom generation, verifier/test-based rewards, fan-out samples, async rollout, SGLang serving optimization, and coding-agent RL examples.
If you are training agents with tool use, sandbox interaction, subagents, context compaction, or test-based rewards, this is a good place to start.
1
13
94
5,945