
An open source coding harness where local and frontier models jam together. Just 'brew install small-harness' and rock on 🤘 Created by @morganlinton.
Joined April 2024
- Tweets 494
- Following 27
- Followers 528
- Likes 591
26 Photos and videos







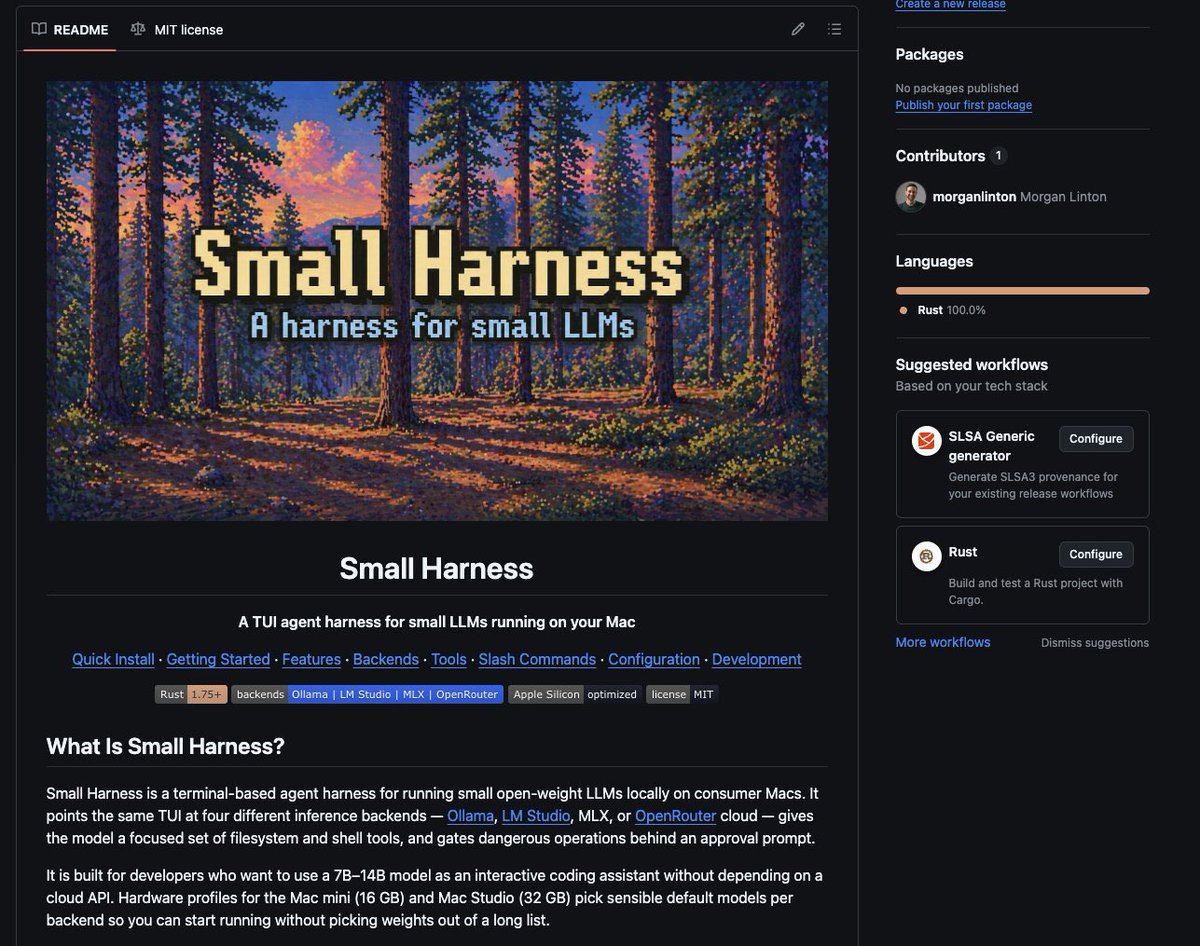



Okay, v.1.0 of Small Harness is finally here.
What got it to v1?
Well it was Morgan's Wacky Model Routing Idea of course!

Okay, I've been really in a groove with @smallharness today, so decided to finally cut the feature I felt like I need for a true v1.0 release.
And this is, model routing...but kinda model routing Morgan-style I guess, because I've been testing out different approaches lately, and found something pretty interesting.
At a high level, I've been thinking that it doesn't make sense to have one model to orchestrate, one to write code, and one to review, and I've been playing around with different configurations.
What I've determined, at least for me, lately, is that I actually want a different model to orchestrate simple tasks vs. complex tasks, and I also want different agents to do coding tasks, based on how much thinking depth/tool calling I need, etc.
Also in some cases, I might want the same model but at different effort levels, like I learned with Fable where I could do a lot more with low than I expected, but there were some tasks I wanted medium for, and of course, crazy complex architecture stuff that I wanted high or even max for.
Same for code review. For MVPs and stuff I'm playing with, I just want fast and cheap, simple code review. But for production code, then I want way more in-depth code review, a better, more expensive model that goes much deeper.
I've come up with a series of roles, and this is all now built into Small Harness. Finally got my idea, into code, and into a harness that can help you write code, using this methodology.
Here's the high-level on it.
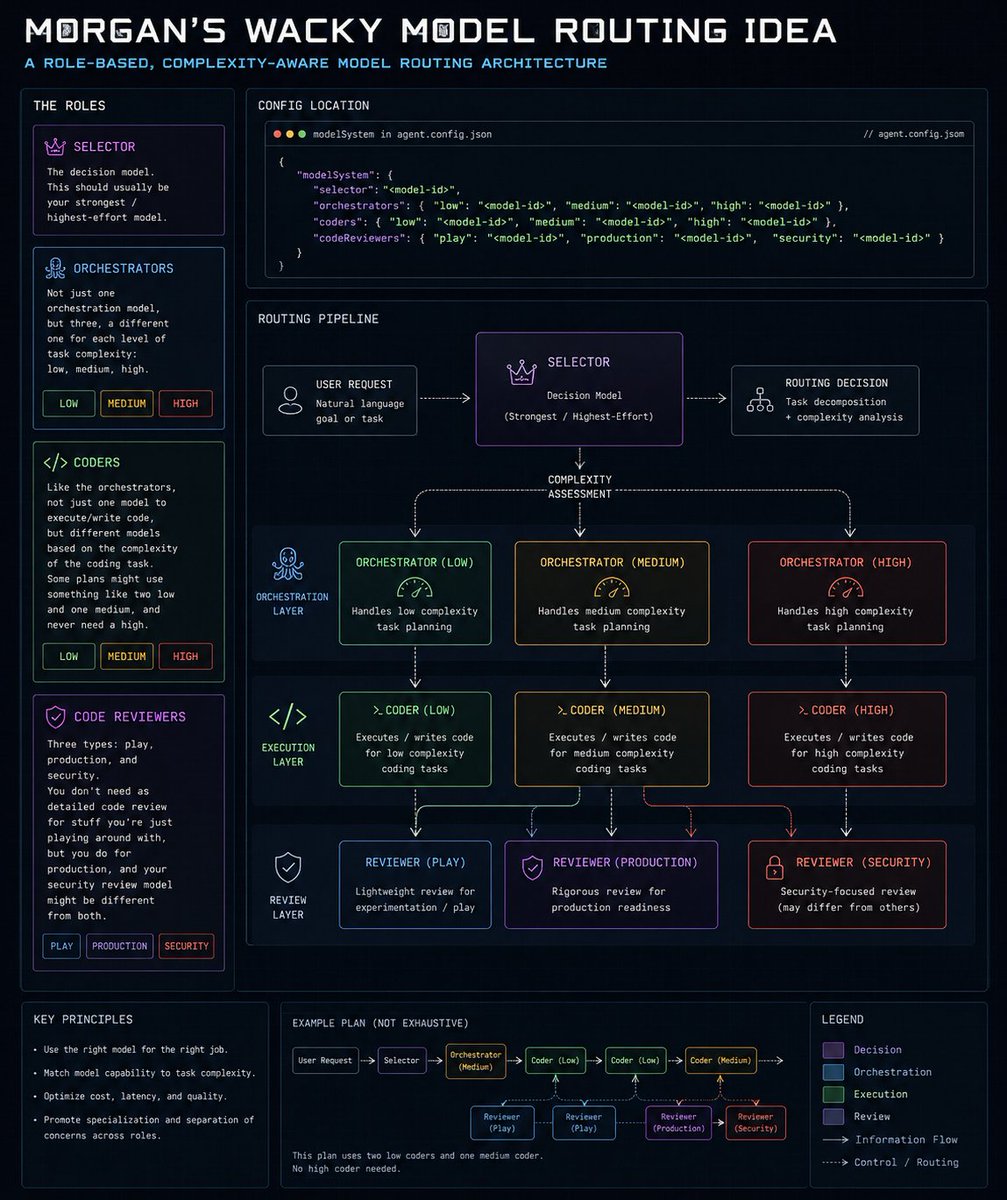
The Roles
-----------
The config lives under modelSystem in agent.config.json:
👑 Selector: the decision model. This should usually be your strongest/highest-effort model.
🐙 Orchestrators: not just one orchestration model, but three, a different one for each level of task complexity: low, medium, high.
🧑💻 Coders: like the orchestrators, not just one model to execute/write code, but different models based on the complexity of the coding task. Some plans might use something like two low and one medium, and never need a high.
✅ Code reviewers: three types, play, production, and security. You don't need as detailed code review for stuff you're just playing around with, but you do for production, and your security review model might be different from both.
And I made a chart, aptly titled, Morgan's Wacky Model Routing Idea. That you can look at if you want to do a little deeper dive into what I'm thinking here.
Now live on Github, free and open source, link to the rep in first comment below.


2
13
1,528
Another Sunday morning update to Small Harness.
Small Harness 0.9.0 adds @OpenRouter Fusion.
/fusion on for hard coding decisions. /fusion tool keeps your coding model in control and adds multi-model deliberation when needed.
Tokens, cost, approvals, and session logs stay visible.
Okay, officially too excited about Fusion from OpenRouter not to add a dedicated command for it directly to Small Harness.
Don't wait for Anthropic to make Fable 5 available, get the same level of intelligence for half the cost.
Now built-into Small Harness.
Small harness is free and open source, so use it out of the box, or fork it and make it your own.
Link to gh repo in first comment below.

3
412
Small Harness v0.8.0 is here, now live on Github.
This update adds /ship, a last-mile workflow for coding agents.
It checks readiness, drafts the commit, creates guarded commits, pushes, opens a GitHub PR, and reports PR/CI status from the terminal.
With most coding harnesses, you finish a change, then still have to ask:
Did I run the right tests?
Is my branch behind?
Are there unstaged or untracked files?
What should the commit message be?
Did I accidentally include local junk?
Did the push work?
Is the PR open?
Are CI checks green?
/ship turns that last-mile checklist into one guided flow inside the same coding harness.
1
1
11
4,922

Jun 13
Rio 3.5 has entered the conversation.
Jun 13

Alibaba Qwen3.7 slowly fading into irrelevance at the frontier due to proprietary stance.
In it's place we have Minimax M3 and... *checks notes* Rio 3.5 397b, made by the municipal IT company of Rio de Janeiro's city government.
huggingface.co/prefeitura-ri…

3
354
Jun 13
1 to this, love OpenRouter.

friendly reminder that even in black swan events like fable being taken down
@openrouter is here to help you gracefully fallback to the next best model (opus 4.8)
the future is multi model
unbelievably bullish on this product
1
3
294
Jun 13
Fable got too big, never a better time to go small 🤏
Jun 13
Quick reminder that Small Harness, a fast, transparent, bare bones harness that I built, works wonderfully with local llms.
Soon, you will be able to connect both frontier models for planning, with local models for execution, and with VulcanBench, optimize when you use each.
And the less you rely on frontier models, the more free you become.
The future is smaller than you think, try Small Harness.
Free, open source, use as it is, or fork it and make it your own.
github.com/GetSmallAI/SmallH…
2
162
Jun 10
Just pushed Small Harness 0.7.0 to Github, calling this one the observability release. And my first release built with Claude Fable.
Two big things: a flight recorder for your agent, and evals you can run from a shell script.
Turn tracing: every session gets an .events.jsonl sidecar tool calls (args redacted), approvals, compaction, warmup, timing. /trace on shows nested subagent/critic activity live. Your turn footer now breaks down TTFT vs model vs tools vs approval time.
Agent eval CLI: --eval <fixture> --json runs a bundled task end-to-end and exits 0/1. Plus new integration tests that drive the real agent loop against a mock SSE server, no live LLM needed.
Also: sharper tool responses for the model (clear EOF errors, real totals on truncated listings), 10s connect timeout so dead backends fail fast, and a big internal cleanup.
To use: brew upgrade small-harness 🍺
And as always, Github repo in first comment below. Free, open source, use it as it is, or fork it and go nuts.
3
2
9
2,358
Jun 9
Having Fable 5 (aka Mythos) do a code review of Small Harness. It just spun up three agents 👀
1
3
124
Jun 8
Very cool to see people talking about small things!

You can club them with @getsmallai and you won't regret.
69
Jun 7
Small Harness v0.6 is now live on Github. This is a big one for Codex fans.
You can now sign in with your ChatGPT subscription, simple type:
/login openai-codex
2
1
16
8,574
Jun 7
Big day for Small Harness ⭐️
Jun 7
Small Harness just broke 100 stars on Github ⭐️
Thanks to everyone who has tried Small Harness and provided feedback 🙏
It is getting better every week.

1
3
294
Jun 7
Small Harness v0.5 is out 🌙
New command --> /auto: point it at a goal and let it run overnight. It writes code, grades its own diffs, and auto-resets context when the window fills, so a multi-hour run never blows its budget.
Wake up to a finished task a report 📊
Bring your own model.
4
13
4,006
Jun 7
I want this setup.
Jun 6

just walked into one of our ai inference teammates’ workplace at @liquidai Cambridge! lots of ice packs, toasters, and coffee machines. 🖱️
137
Jun 7
Small Harness 0.4.14 is now live ✨
This update is a big one, with a focus on how to make the harness better at getting models to perform long-running tasks more effectively.
Here's what's new:
• /plan: expand a one-line intent into a full spec: goal, scope, done criteria, open questions. Stays at what & why, so it won't lock in the wrong details early.
• critique: a separate, read-only critic scores work 0–10 against a weighted rubric that the harness (not the model) tallies, so a critic that over-rates can't pass weak work.
• /iterate: a generate→evaluate→improve loop that grades each diff with the critic and feeds the notes back, refining or pivoting until it clears the bar. The generator never grades itself.
• live verify: the critic runs your project's real test suite (timeout-bounded, no arbitrary shell) before scoring, so it grades actual behavior, not just how the code reads.
• /reset: writes a structured handoff note (done / next steps / key files), then starts a clean session seeded with only that. Reset over compaction for long tasks.
1
2
135
Jun 5
Released a bunch of improvements to Small Harness over the last 24-hours. Here's what's new:
v0.4.5, Fix: response text overflow
Streamed answers now word-wrap to the panel width (preserving paragraphs list indentation, hard-breaking long URLs) instead of running off the right edge.
v0.4.6, TUI redesign: fading top-rule headers
v0.4.7, Removed the hardware-profile concept
No more mac-mini-16gb / mac-studio-32gb. Dropped the banner line, /profile, the profile/profiles config, and PROFILE env var.
v0.4.8, Quitting is now a proper slash command (/exit), with /quit as an alias. Bare exit/quit still work.
v0.4.10, Write files instead of printing code
Root-cause fix for "it dumps the whole HTML into chat": auto tool-selection now keeps the full working pool available for any real request (no more keyword guessing) and sends nothing only for greetings.
Added file_write to the core defaults so new files can be created from scratch. System prompt now instructs the model to write changes to disk and reply with a short summary.
v0.4.11, /verbose mode
A debug tool view: /verbose on prints every tool call as → name with its full arguments and the result as ← (duration) with a large preview.
v0.4.12, Inline slash-command completion
Type / and the rest of the best-matching command appears as dim ghost text; Tab accepts ( space), → accepts inline. Updates live as you type.
v0.4.13, Navigable completion menu
Upgraded the above to a full dropdown: matching commands with descriptions beneath the prompt, selected row marked, mirrored as ghost text. ↑/↓ select, Tab/→ accept, Esc dismiss; ↑/↓ fall back to history when the menu is closed.
1
1
1,685