
Causal AI Research Scientist @ToyotaResearch | CS PhD @UCLA
Joined December 2007
- Tweets 314
- Following 236
- Followers 510
- Likes 14,236
9 Photos and videos


Sup AI is live on @ProductHunt 🚀
"Which AI model is the best?"
Wrong question.
The best model isn't a model. It's an orchestra.
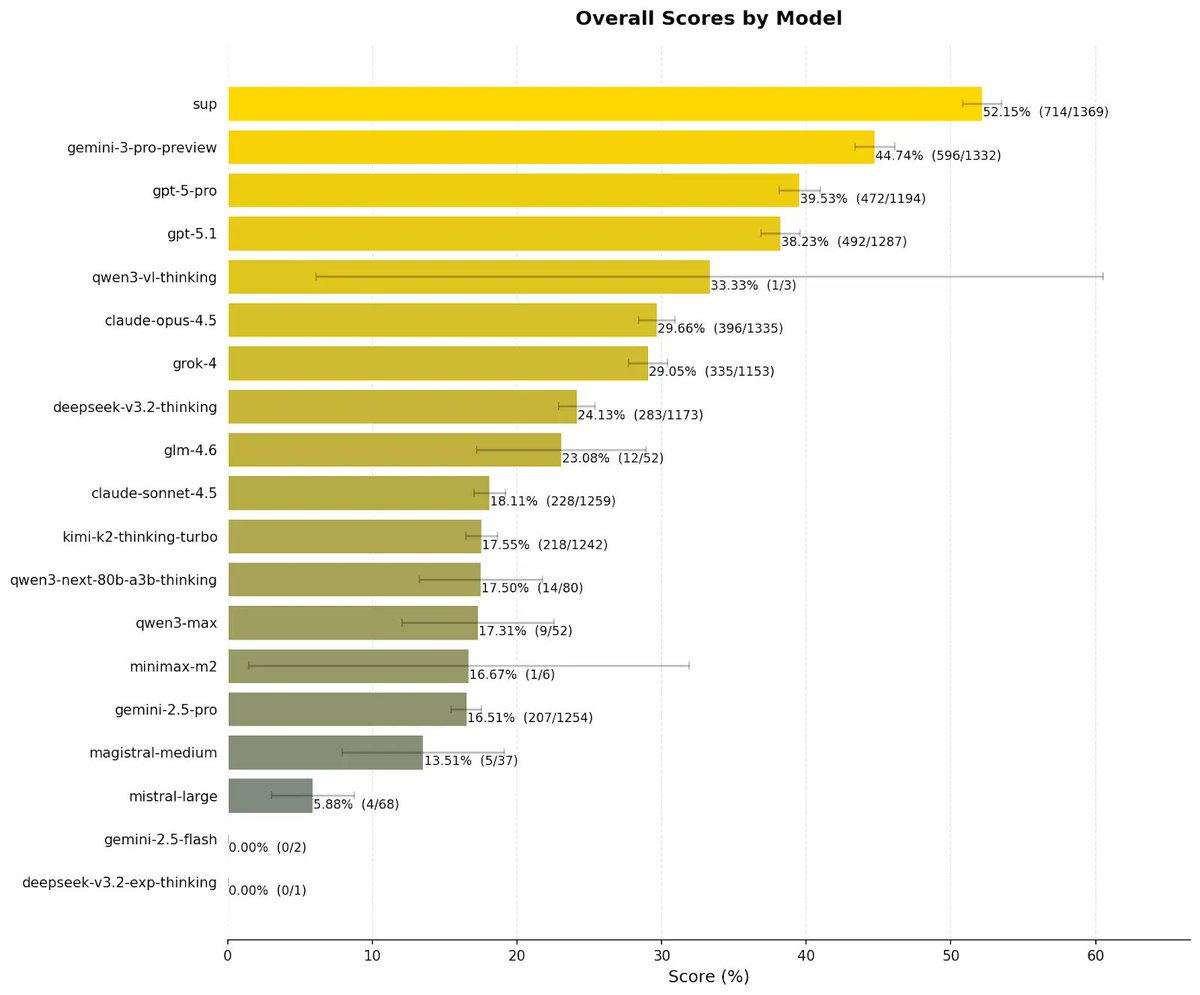
Sup AI runs 9 frontier models in parallel and synthesizes their answers→ 52.15% on HLE benchmark (without the help of tools).
→ Multi-model consensus (up to 9 models)
→ Ensemble RAG with live web your files
→ Every claim cited
$10 free credit to start
20% off with code: PRODUCTHUNT
Links below 👇
3
1
3
162

Apr 7
Sup AI just launched on @ProductHunt
Sup combines multiple AI models and uses confidence scoring to give better answers with fewer hallucinations.
#1 on Humanity's Last Exam: 52.15%. Beating every individual model.
$10 starter credit to try it
producthunt.com/products/sup…
1
1
197
Mar 28
Did @OpenAI just silently kill top-20 logprobs for all models except GPT-5.4-nano? Setting `top_logprobs` to anything > 1 returns an error for the past 4-5 hours. Might just be their servers having trouble, but their status page indicates "No incidents" for their responses API.
114
Sup AI whitepaper is live on the methodology behind 52.15% on HLE:
• 3 correct answers synthesized when EVERY model failed
• Grok 4 (29%) uniquely solved 16 Qs vs GPT-5 Pro's 9 (40%)
• Low correlation pairs >high accuracy pairs
• 58.44% theoretical ceiling w/ models
• 42% Qs unsolved by ANY model
• Full methodology, IQ curves, correlation matrices: sup.ai/research/hle-white-pa…
#AI #MachineLearning #OpenSource #AIResearch #EnsembleAI #AIOrchestration #HLE
2
3
473
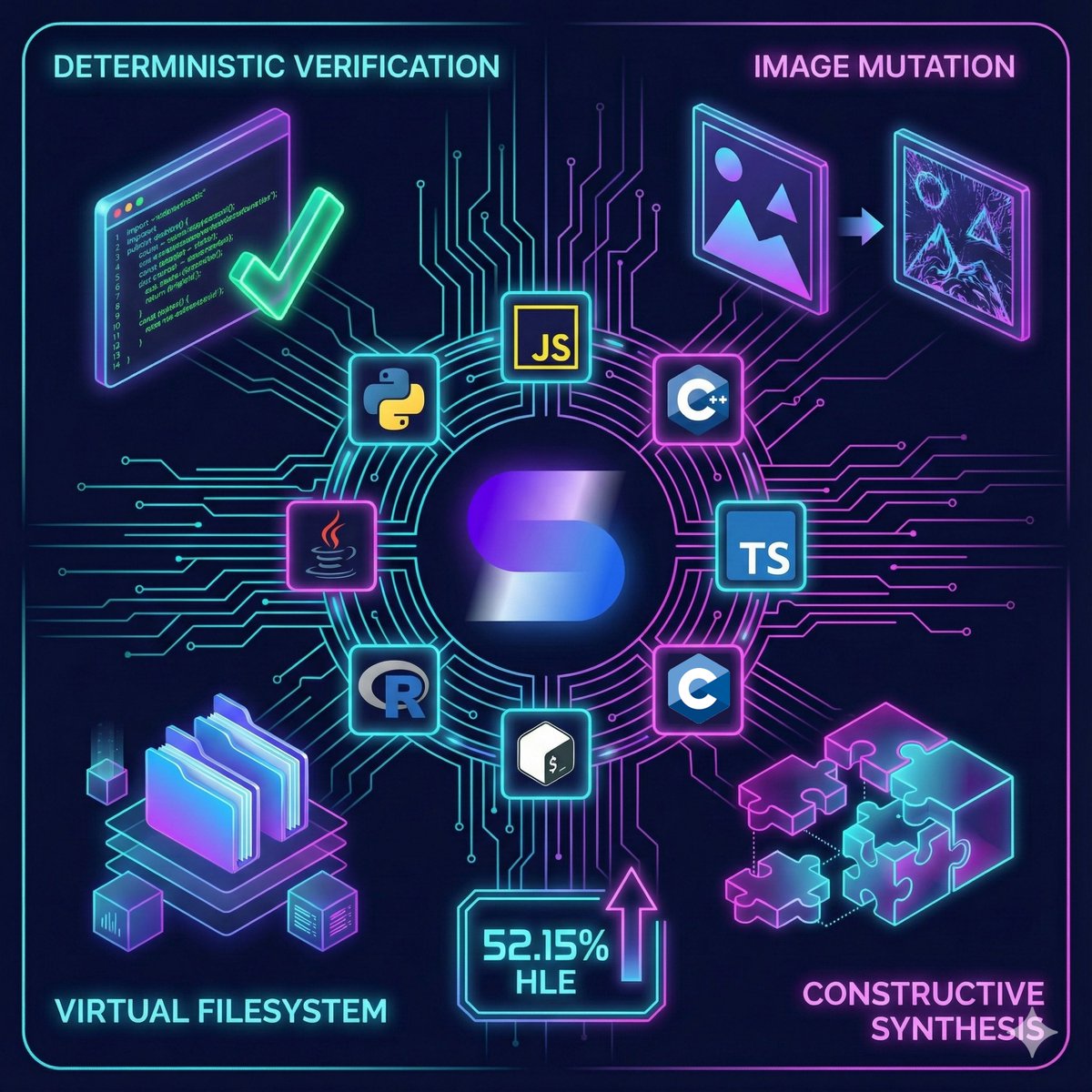
Sup AI's 52.15% HLE ( 7.41 over frontiers) was orchestration synthesis.
Now every model executes Python/Bash/C /JS/TS/R/Java 15 langs. Image mutation. Virtual FS. Deterministic verification.
Guesses → Calculations. Ceiling exploded.
#SupAI #AI #CodeExecution
2
3
371
That's ~$950/month across 5 services. Sup AI is $200/month and includes all those models and more in one place. Save $750/month. sup.ai
1
2
82
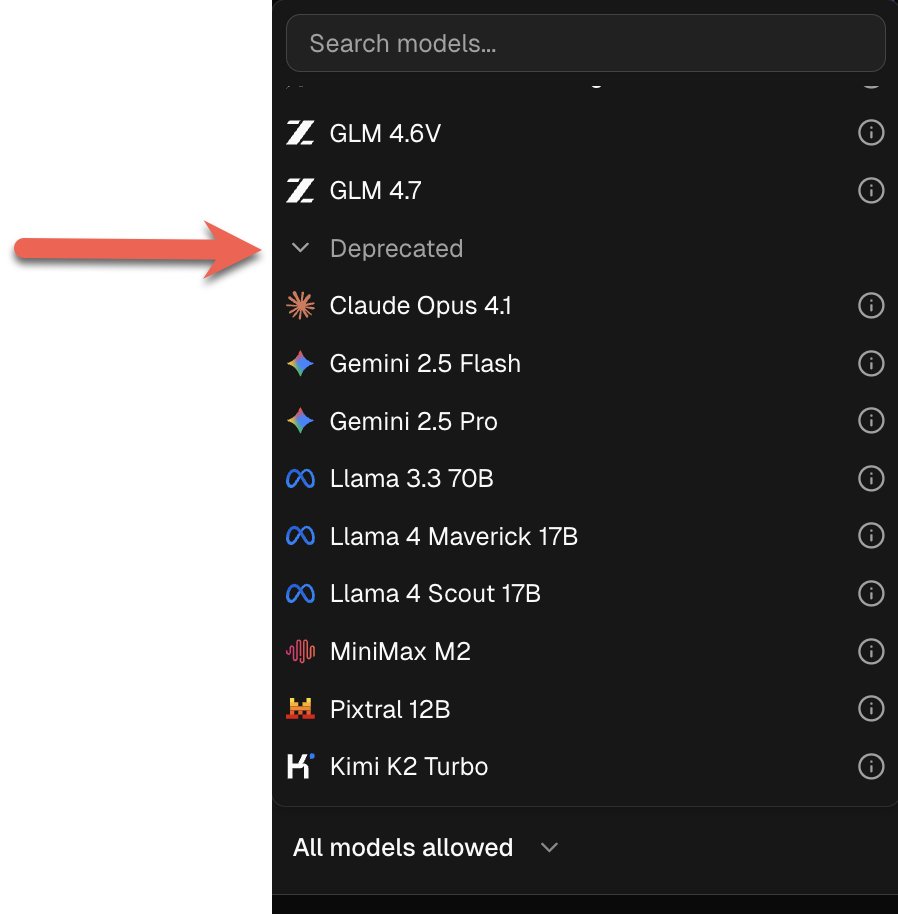
🗂️ Deprecated models are now accessible: Claude Opus 4.1, Gemini 2.5, Flash Gemini 2.5 Pro, Llama 3.3 70B, Llama 4 Maverick 17B, Llama 4 Scout 17B, Kimi K2 Turbo, Grok 4 Fast, Grok 4 Fast Reasoning, GPT-5,
GPT-5 Pro, GPT-5.1, GLM 4.5 Air, GLM 4.6, MiniMax M2, Pixtral 12B are back by request. Find them at the bottom of the model selector → click "Deprecated" to expand. Great for: specific personalities, fewer guardrails ⚠️ Not recommended for serious work as newer models outperform them.
1
1
2
202
We just launched the Sup AI Developer API
One endpoint → Multiple frontier models → Better answers
✅ Multi-Model Consensus: Combine outputs from Claude, GPT-5, Gemini, and more
✅ OpenAI compatible (2-line integration)
✅ 5 modes: fast → thinking → pro
✅ 52.15% on Humanity's Last Exam (SOTA)
✅ Self-healing tool calls
Get your API key → sup.ai/api
Full docs → docs.sup.ai
How it works:
Instead of betting on one model, Sup AI orchestrates multiple models and synthesizes their outputs.
auto mode picks the right approach. pro mode runs 9 models for mission-critical work.
You get consensus-driven answers without the infra headache.
1
1
4
184
Sup AI update: → Faster generation → More reliable → Terminate models mid-response (for when you can't wait for GPT-5.2 Pro to finish 🙂)
Also added GLM 4.7 and MiniMax M2.1 42 models. One interface. sup.ai
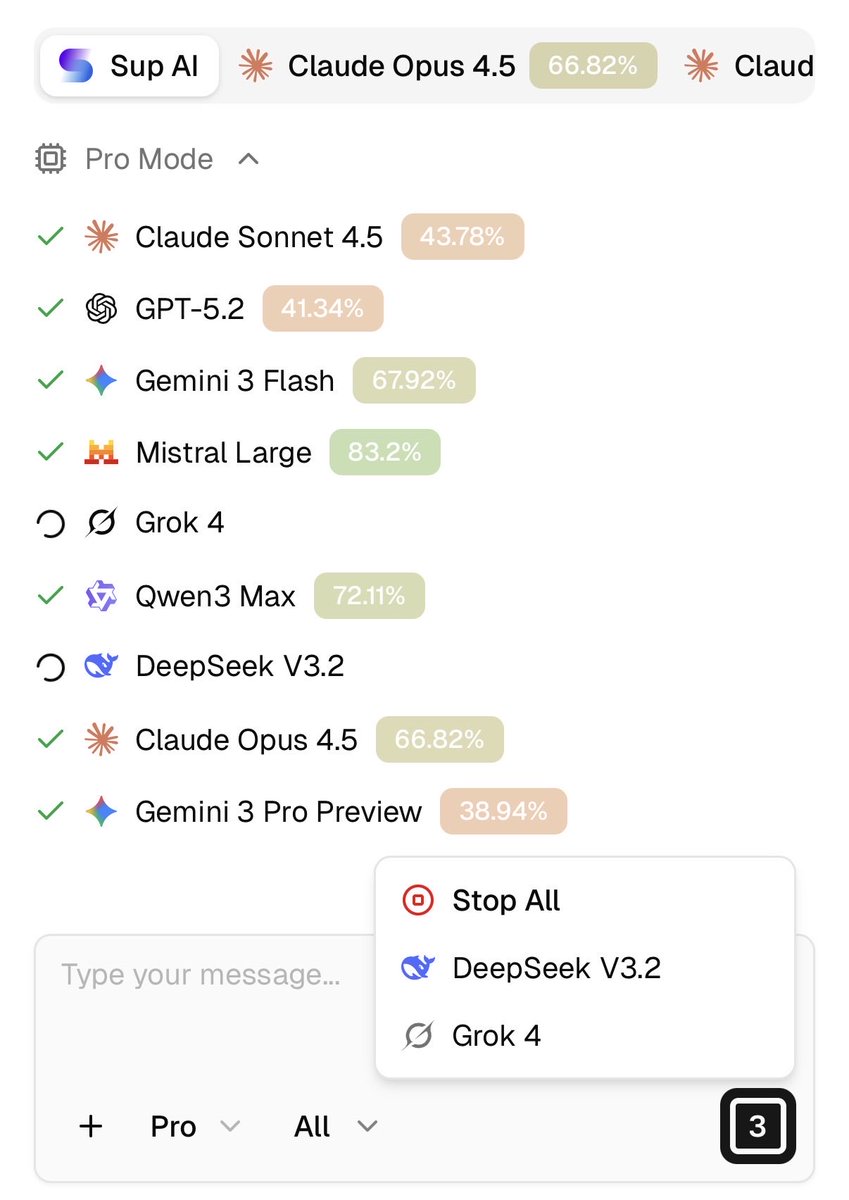
ALT Image or Sup AI interface with window allowing user to stop models
2
3
396

Dr. @yudapearl - On Zionophobia, Jew-Hatred, and the Promise of AI
25
30
145
35,212
💯 Memory IS the lock-in.
That is why Sup AI decoupled memory from the model. Your memory is shared across all 42 frontier models -GPT, Claude, Gemini, Grok, everything. Switch freely; your context follows you.
Great suggestion - now we just need to build that import feature 👀

Idea for @xai team
Let people import their conversation history / data from other LLM chat apps
That'd make it much easier to switch from other apps because a big part of the lock-in of LLM chat apps is their memory about you
1
2
236
Single-model AI is broken.
You're paying for 5 subscriptions, manually A/B testing outputs between tabs, and praying the "best" model doesn't hallucinate on the task that matters.
We orchestrate 40 frontier models instead. Auto-route. Auto-validate. One platform.
Result: 52.15% on Humanity's Last Exam. 7.49 points ahead of every solo model.
The future isn't picking the best violinist. It's conducting the whole damn orchestra.
sup.ai
#AI #AIOrchestration #SupAI #LLMs #LLMCouncil

2
3
6
298
The AI race has a new winner every week.
OpenAI → Gemini → Grok → Claude → DeepSeek
Betting on one model? You've already lost.
@SupAIHQ orchestrates 40 frontier models, achieving 52.15% on Humanity's Last Exam:
github.com/supaihq/hle/blob/…
Don't pick a rat. Own the racetrack.
#AI #Orchestration

2
5
184
New SOTA on Humanity's Last Exam (HLE)
We have achieved 52.15% accuracy on the world's hardest open-source AI reasoning test, setting a new benchmark record.
Sup AI is now outperforming every individual frontier model, including Gemini 3 Pro Preview and GPT-5 Pro.
Our lead over the next best model? 7.49 points.
Check the full evaluation & code:
github.com/supaihq/hle/blob/…
#AI #MachineLearning #HLE #SupAI
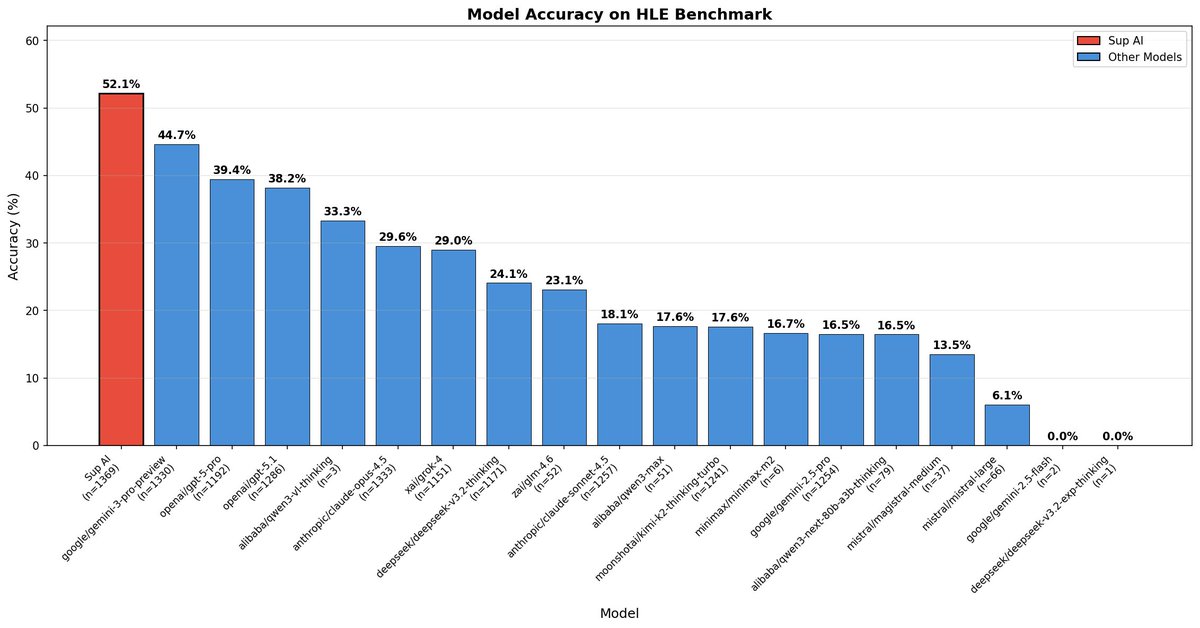
3
4
8
1,009
Scott Mueller retweeted

5 Jun 2025
‘Do no harm,’ says the Hippocratic Oath—but how do we define harm? Rejoice: our paper, "The Meaning of 'Harm' in Personalized Medicine," has finally been publisched by the American Journal of Epidemiology (AJE):
academic.oup.com/aje/article….
ChatGPT calls AJE the flagship journal of epidemiology and public health. (It took us two years to pacify the reviewers.) So, we now expect the counterfactual definition of 'harm' to become standard in personalized medicine.
6
7
32
5,743
Scott Mueller retweeted
21 May 2025
I've been away to Vancouver last two days (graduation) and, upon returning to LA I found this feather added to my hat, and the hats of all CI researchers: samueli.ucla.edu/ucla-comput…
I am truly honored to be deemed worthy of membership in this 335-year-old society.
As a book collector, my bookshelf is blessed with the first volume of its Philosophical Transactions (1665–66), see below, as well as later volumes in which the discoveries of Newton, Volta, Faraday, and Maxwell were first published.
This has given me a comforting illusion of familiarity with the Society. I am therefore especially delighted to see it now turning its attention to the science of cause and effect.
Thank you all for your posts, friendship and support.

2
2
20
2,029
Scott Mueller retweeted

15 Jan 2025
We're building a world-class research team. If you're excited about our ideas and you'd like to join us, let's chat! We're a globally distributed, fully remote company.
To apply, send a short email to future@ndea.com with the following:
1. Your location (city, country)
2. One very impressive thing you've created or published
3. Evidence of your ability to turn math concepts into code
9
21
331
91,221
5 Aug 2024
New paper by Kerwash & Johnston (mdpi.com/1999-4923/16/7/906) shows Casgevy as a very effective treatment for transfusion-dep β-thalassemia, but it was a single-arm trial. They avoided issues with conv statistical analysis through Causes of Effects analysis with PN=100%, PS=PNS=93%.
2
493