
developer/builder. My twitter alter-ego for AI/LLM related stuff.
Joined December 2021
- Tweets 1,194
- Following 800
- Followers 172
- Likes 2,211
63 Photos and videos












Hey @OpenAI all codex cli and codex app returns the same error response (with 5.5 model only)
{ "type": "error", "error": { "type": "image_generation_user_error", "code": "invalid_value", "message": "The model 'gpt-image-2' does not exist.", "param": "tools" }, "status": 400 }
1
1
486


Mar 24
crewai, hermes, openclaw.. if you are using any of these or an agent framework make sure not to have installed version 1.82.8 of litellm
Mar 24

Software horror: litellm PyPI supply chain attack.
Simple `pip install litellm` was enough to exfiltrate SSH keys, AWS/GCP/Azure creds, Kubernetes configs, git credentials, env vars (all your API keys), shell history, crypto wallets, SSL private keys, CI/CD secrets, database passwords.
LiteLLM itself has 97 million downloads per month which is already terrible, but much worse, the contagion spreads to any project that depends on litellm. For example, if you did `pip install dspy` (which depended on litellm>=1.64.0), you'd also be pwnd. Same for any other large project that depended on litellm.
Afaict the poisoned version was up for only less than ~1 hour. The attack had a bug which led to its discovery - Callum McMahon was using an MCP plugin inside Cursor that pulled in litellm as a transitive dependency. When litellm 1.82.8 installed, their machine ran out of RAM and crashed. So if the attacker didn't vibe code this attack it could have been undetected for many days or weeks.
Supply chain attacks like this are basically the scariest thing imaginable in modern software. Every time you install any depedency you could be pulling in a poisoned package anywhere deep inside its entire depedency tree. This is especially risky with large projects that might have lots and lots of dependencies. The credentials that do get stolen in each attack can then be used to take over more accounts and compromise more packages.
Classical software engineering would have you believe that dependencies are good (we're building pyramids from bricks), but imo this has to be re-evaluated, and it's why I've been so growingly averse to them, preferring to use LLMs to "yoink" functionality when it's simple enough and possible.
52

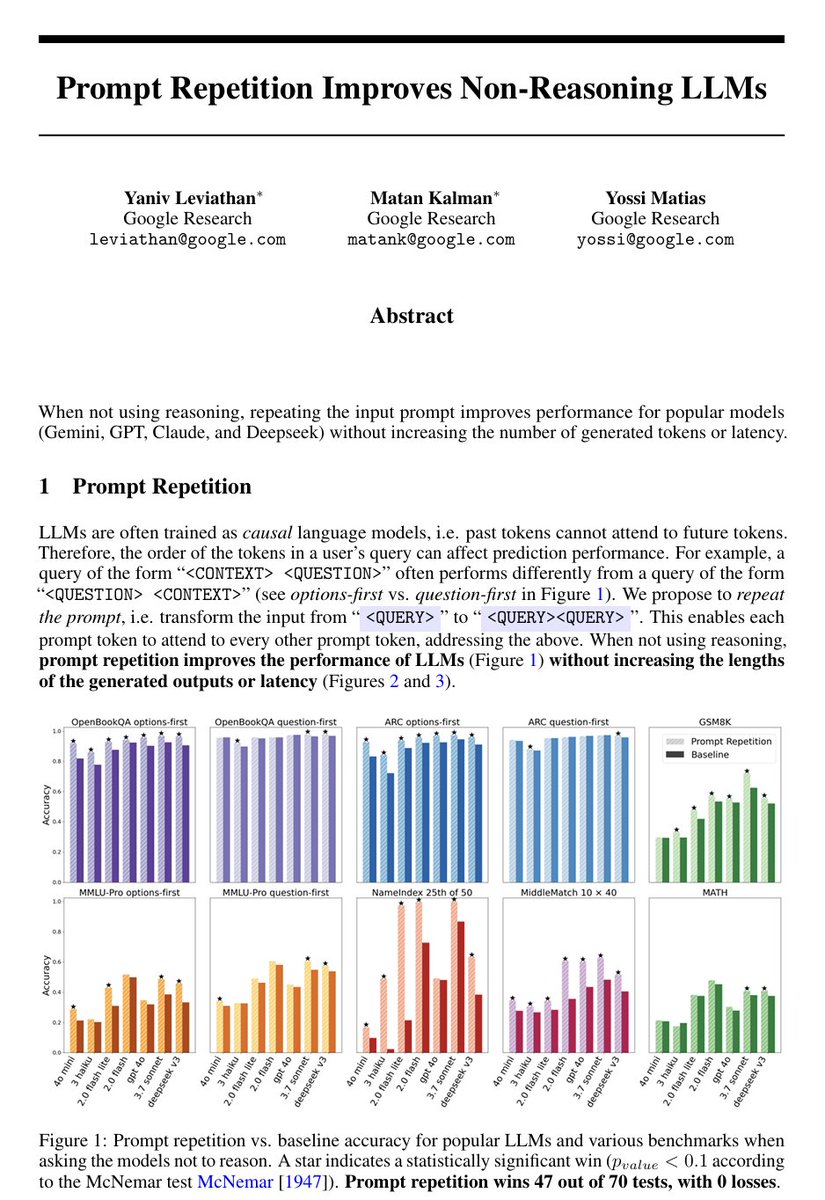
LLMs process text from left to right — each token can only look back at what came before it, never forward. This means that when you write a long prompt with context at the beginning and a question at the end, the model answers the question having "seen" the context, but the context tokens were generated without any awareness of what question was coming. This asymmetry is a basic structural property of how these models work.
The paper asks what happens if you just send the prompt twice in a row, so that every part of the input gets a second pass where it can attend to every other part. The answer is that accuracy goes up across seven different benchmarks and seven different models (from the Gemini, ChatGPT, Claude, and DeepSeek series of LLMs), with no increase in the length of the model's output and no meaningful increase in response time — because processing the input is done in parallel by the hardware anyway.
There are no new losses to compute, no finetuning, no clever prompt engineering beyond the repetition itself.
The gap between this technique and doing nothing is sometimes small, sometimes large (one model went from 21% to 97% on a task involving finding a name in a list). If you are thinking about how to get better results from these models without paying for longer outputs or slower responses, that's a fairly concrete and low-effort finding.
Read with AI tutor: chapterpal.com/s/1b15378b/pr…
Get the PDF: arxiv.org/pdf/2512.14982
386
1,108
11,558
2,989,252

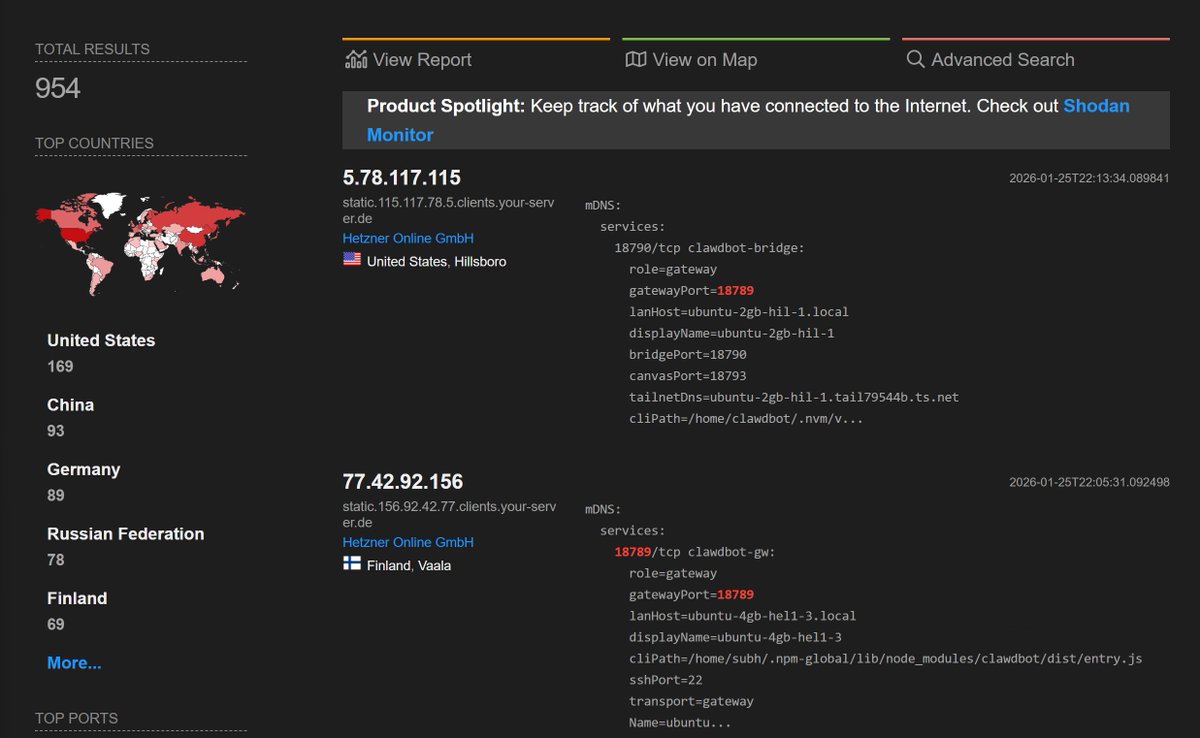
Clawd disaster incoming
if this trend of hosting ClawdBot on VPS instances keeps up, along with people not reading the docs and opening ports with zero auth...
I'm scared we're gonna have a massive credentials breach soon and it can be huge
This is just a basic scan of instances hosting clawdbot with open gateway ports and a lot of them have 0 auth
409
750
6,971
1,627,000
Miyamoto Musashi retweeted

13 Sep 2025
I was lucky to work in both China and the US LLM labs, and I've been thinking this for a while. The current values of pretraining are indeed different:
US labs be like:
- lots of GPUs and much larger flops run
- Treating stabilities more seriously, and could not tolerate spikes in large flops run, thus invented so many stability-related tricks, including all kinds of soft-cap, MuP, and spectral norm control tricks
- Treats predictabilities more seriously. Check GPT 4 report for reference, even trying to predict the eval task performances
- Because of the stability and predictability ask, treats hyper-params and optimization more seriously
- Generally believe more in data, optimization than arch
China labs be like:
- has very limited GPUs, e.g. k2 in 4k GPU and v3 in 2k GPU
- as a result, pushing for the limit of pretrain modeling-infra co-design, see so many tricks in V3, and K2 has some cool stuff too (the offload trick helps remove the stupid MoE gating constrain and only uses EP 16)
- cares model arch/token efficiency over optimization, stability
- cares more about data quality than data quantity
- taking inference into consideration day 0, even before the training starts
In general, China labs are trying to use <4e 24 flops models to catch up with >1e 25 flops models. It is hard or impossible, but they are making good progress.
I am actually very happy to see Qwen's new try on model archs, they used to be focusing more on data side rather than on model arch side. They developed linear attn, not just for people to think they are innovating, it is actually considering pushing the limit for test time scaling. Llama4 failed for many reasons, but qwen-next is different. They just used very limited flops and it is a brave try for good reasons.
13 Sep 2025

I bet OpenAI/xAI is laughing so hard, this result is obvious tbh, they took a permanent architectural debuff in order to save on compute costs.
58
331
3,153
525,922
2 Aug 2025
Here is the best practice for making Claude Code smarter: Remove all the MCPs from global settings and use MPCP servers based on project and only if you have to. Use cli apps instead whenever you can and include the basic instructions at the /docs. MCPs are eating up your context
4
307
2 Aug 2025
5 - Here is the best part: Ask your agent “how can I optimize your current context window?” and it will tell you what is repetitive and redundant. Small context = smart agent.
1
54
2 Aug 2025
4 - Keep your Claude.Md file simple and short and use links to /docs instead of long verbose text.
59
2 Aug 2025
3- Do not use @filename unless you need the complete codebase. Instead make claude agent run search for snippets.
34
2 Aug 2025
2- Do not let your context being auto-compacted. Always start fresh before that stage with a habdoff handon command that reviews the previous task progress, code changes(bash script) and git diff.
127
Miyamoto Musashi retweeted

10 May 2025
llama.cpp shipped new support for vision models this morning, including macOS binaries (albeit quarantined so you have to take extra steps to run them) that let you run vision models in a terminal or as a localhost web UI
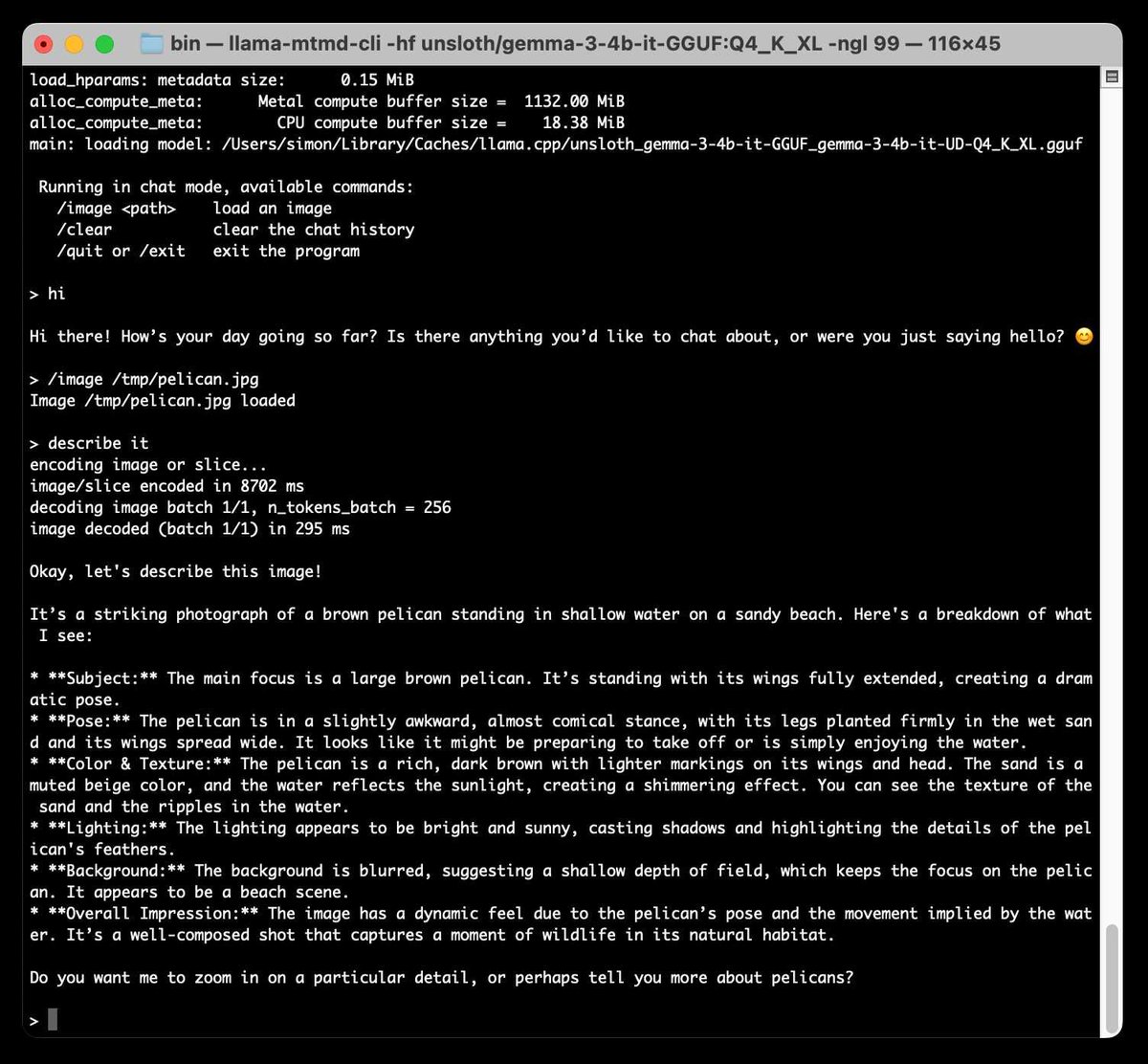
ALT macOS terminal running a Gemma 3 4B vision model, which can then load a pelican.jpg photo and describe it

ALT The localhost:8080 web UI for llama.cpp describing a different photo of some pelicans
8
32
257
27,032
Miyamoto Musashi retweeted

26 Mar 2025
Ghibli trend…
942
31,512
287,415
15,791,834
Miyamoto Musashi retweeted

8 Mar 2025
Manus AI is freaking insane and I have not used anything like this before.
Disclaimer: I am not paid by Manus AI to write this, I just feel lucky to have gotten access.
For the given prompt, Manus AI conducted online research, generated Python code, validated all results, and published a detailed report in 47 minutes.
Prompt:
"Calculate the optimal Hohmann transfer orbit for a spacecraft traveling from Earth to Mars, including the required delta-v (change in velocity) at each maneuver, considering the current positions of Earth and Mars in their orbits as of March 2025. Also, account for gravitational influences from the Sun and other planets."
Note: I am not sure if these calculations are correct; someone needs to verify them. I am publishing the report on GitHub.
@manusai
79
89
935
227,485

Manus, the new AI product that everyone's talking about, is worth the hype.
This is the AI agent we were promised.
Deep Research Operator Computer Use Lovable memory.
Asked it to "Do a professional analysis of Tesla stock " and it did ~2wks of professional-level work in ~1hr!
253
758
7,385
1,519,535
19 Feb 2025
When I look at build in public communities all I see is attention bait posts, fake metrics, lies about revenue - users - marketing, typical x grifter hustle
1
1
56
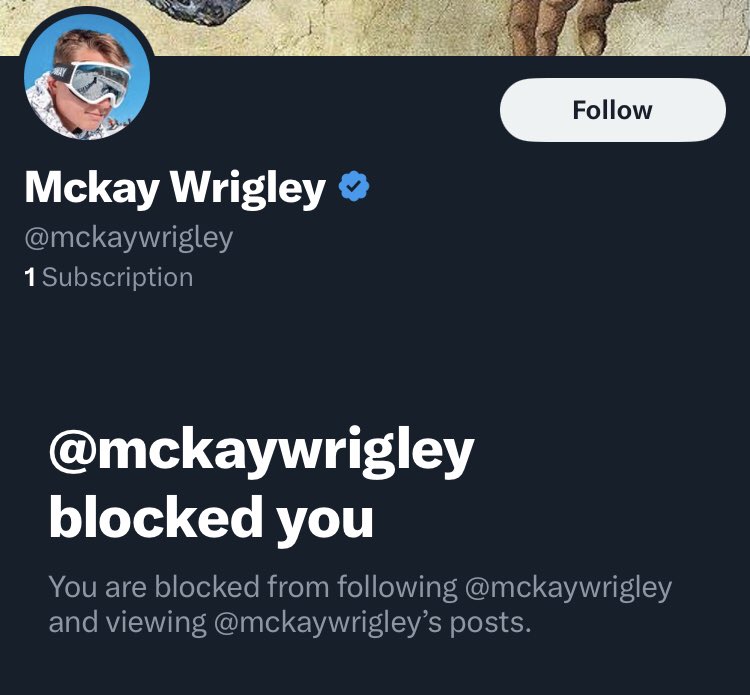
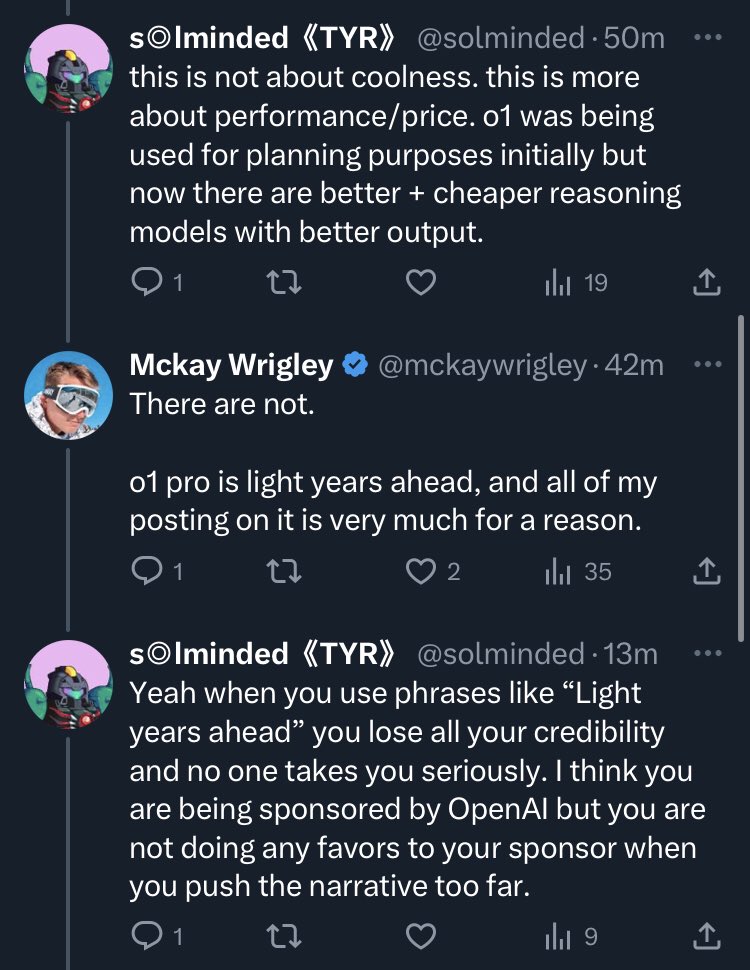
14 Feb 2025
this is why you should not listen to influencers hiding the fact that they are being sponsored. @mckaywrigley blocked me when I pointed out that lately his tweets were pushing @OpenAI “products are better” narrative too far and gave me the impression that he was sponsored.
1
42

16 Feb 2024
Seems like OpenAI will wreck all AI generative related startups one by one. They have just killed @runwayml today.
235