
Postdoc @SchwallerGroup @EFFL | Geometric deep learning on 3D point clouds for atomistic modeling
Joined May 2023
- Tweets 139
- Following 515
- Followers 345
- Likes 339
8 Photos and videos


Sergey Pozdnyakov retweeted

17 Dec 2025
💫 As promised, we just released on GitHub the weights of the #FeNNixBio1 foundation machine learning model for drug design! 💫
Weights: github.com/FeNNol-tools/FeNN…
FeNNol GPU code: github.com/FeNNol-tools/FeNN…
The models are distributed under the open source ASL license (i. e. restricted to non-commercial academic research).
You can also check the updated version of the preprint that includes a unified transformers architecture as well as the full computation of the Freesolv hydration free energies dataset etc...
doi.org/10.26434/chemrxiv-20…
Happy holidays and merry Christmas everyone! 🎅 🎄
Sorbonne Université / CNRS
@qubit_pharma
#machinelearning #moleculardynamics #drugdesign #compchem #GPU #biophysics
2
18
61
5,187
Sergey Pozdnyakov retweeted

10 Nov 2025
Thrilled to share our new work MatInvent, a general and efficient reinforcement learning workflow that optimizes diffusion models for goal-directed crystal generation. Thanks to @JeffGuo__ , @efssh , @pschwllr , @SchwallerGroup , @NCCR_Catalysis .
arxiv.org/abs/2511.03112
2
9
22
1,594

19 Oct 2025
See you there! 🤗
19 Oct 2025

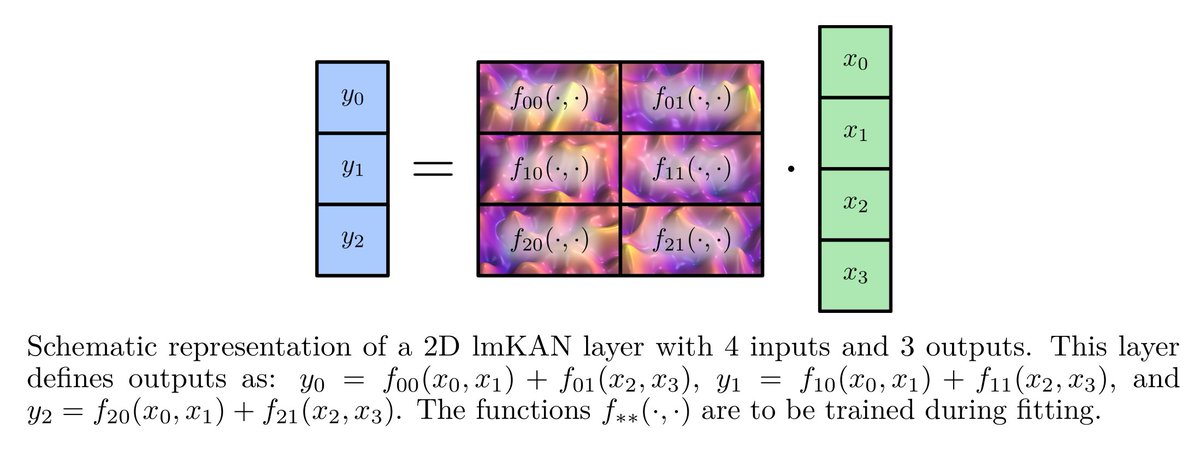
Reading group session on Monday: "Lookup multivariate Kolmogorov-Arnold Networks" arxiv.org/abs/2509.07103 with Sergey Pozdnyakov
On zoom at 9am PT / 12pm ET / 6pm CE(S)T: portal.valencelabs.com/stark…
6
280
Sergey Pozdnyakov retweeted

15 Oct 2025
Our new work, “QCell: Comprehensive Quantum-Mechanical Dataset Spanning Diverse Biomolecular Fragments,” is now out on arXiv! 🌱 1/7

1
1
6
531
Sergey Pozdnyakov retweeted

14 Oct 2025
Exciting postdoc opportunity in the @SchwallerGroup at EPFL!
We're hiring a postdoc to advance ML-driven synthesis planning after Zlatko Joncev’s successful exit to co-found B-12 (YC '25) 🚀
Work on:
- LLMs for strategic synthesis planning
- Chemical reasoning at scale
- Building the next-gen framework for retrosynthesis
Our recent preprint shows that LLMs can guide synthesis planning with natural-language strategies — combining AI reasoning with traditional chemical tools (arxiv.org/abs/2503.08537).
Join us at the intersection of chemistry & AI. Up to 2 years. Based in Lausanne 🇨🇭
Apply: forms.fillout.com/t/nnxVE3Rc…
#ChemTwitter #MachineLearning #SynthesisPlanning #PostdocPosition
15
38
7,673
Sergey Pozdnyakov retweeted

12 Sep 2025
You don’t like molecular dynamics? We get it. That’s why at this year’s LLM hackathon for Chemistry and Materials Science, we built not one, but ✨two✨ AI agents for molecular dynamics 👇
1
7
19
12,391
10 Sep 2025
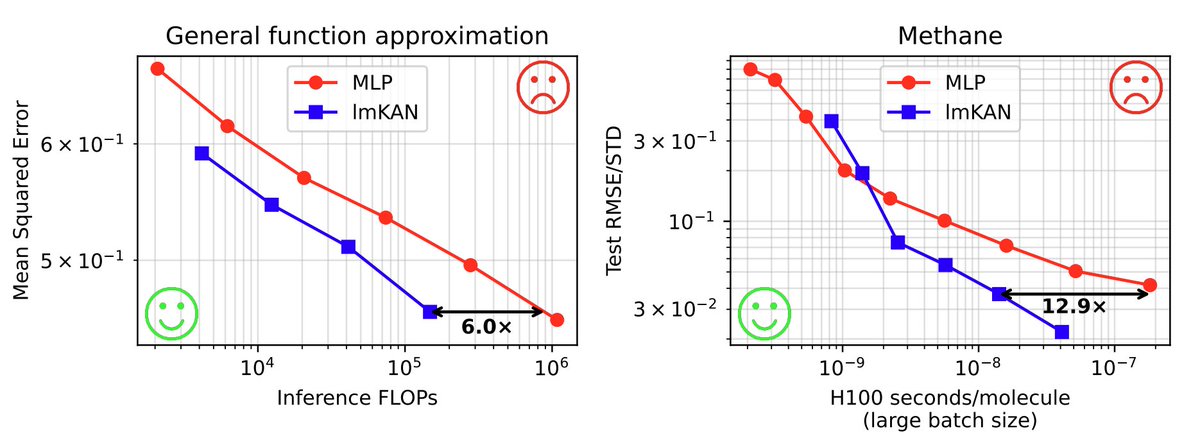
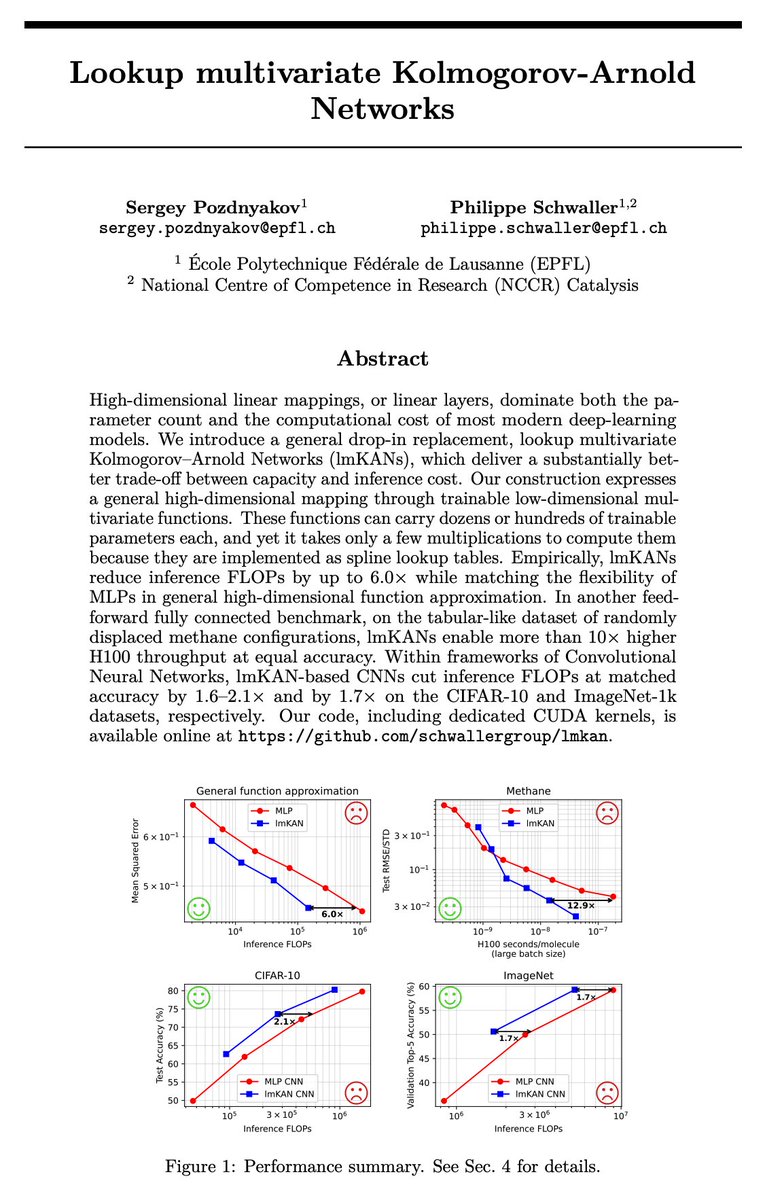
High-dimensional linear mappings, or linear layers, dominate both the parameter count and inference cost in most deep learning models. We propose a general-purpose drop-in replacement with a substantially better capacity - inference cost ratio. Check it out!🧵
1
10
35
3,707
10 Sep 2025
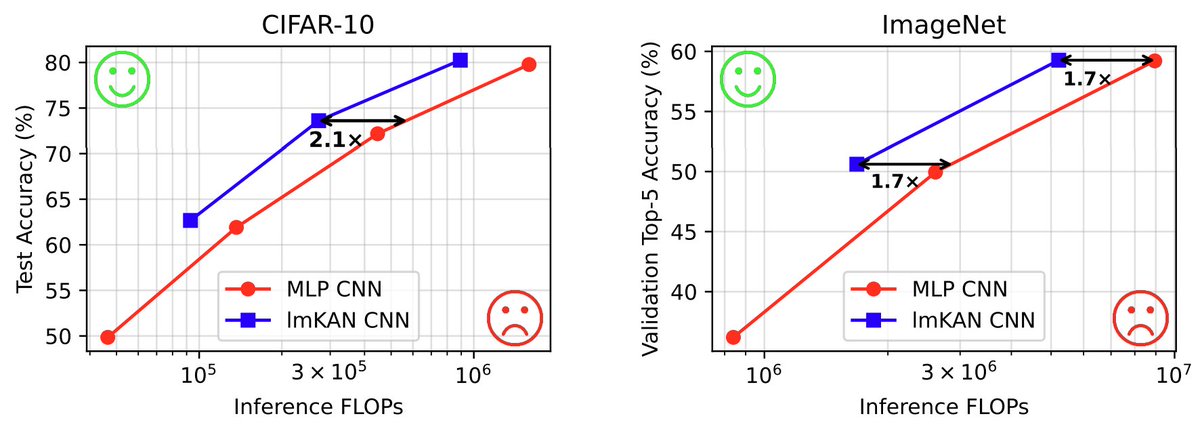
We did it for Convolutional Neural Networks, and it works too. lmKAN-based CNNs are Pareto optimal on both the CIFAR-10 and ImageNet-1k datasets, achieving 1.6-2.1× reduction in inference FLOPs at matched accuracy.
1
5
275
10 Sep 2025
Shout-out to my supervisor @pschwllr, and huge thanks to all the members of the LIAC group @SchwallerGroup ♥️♥️♥️
1
7
234
Sergey Pozdnyakov retweeted
7 Sep 2025
Our recent work on SO3LR, a general-purpose machine learned force field for molecular simulations, has been published in @J_A_C_S! 🌞

6
24
169
13,022
Sergey Pozdnyakov retweeted

2 Sep 2025
Introducing GRACE foundational machine learning interatomic potentials – a new SOTA Pareto front for accuracy vs. performance, built for efficient MD simulations, versatile fine-tuning & distillation. Learn more: arxiv.org/abs/2508.17936 & gracemaker.readthedocs.io/en… #MaterialsScience
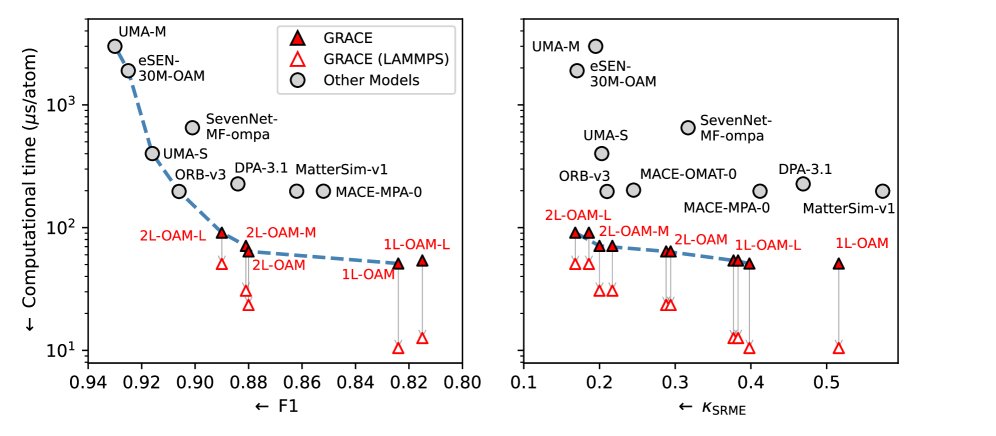
1
3
17
804
Sergey Pozdnyakov retweeted

25 Jul 2025
AI4Mat is back for NeurIPS! time to crystallize those ideas and make a solid-state submission by august 22, 2025 💪
new this year: opt-in your work for our Research Learning from Speaker Feedback program -- a new structured discussion format where spotlight presenters receive curated, in-depth feedback from invited discussants 🧐
check out our website for more:
sites.google.com/view/ai4mat…
brought to you by a 🔥organizing committee: @MiretSantiago @anoopnm007 @SteMartiniani @kmjablonka @ADuvalinho Emily Jin Rocío Mercado Oropeza

19
83
6,951
Sergey Pozdnyakov retweeted

31 Jul 2025
b-12 (b12-labs.com) is building AI agents that help chemists design experiments and automatically run them on lab robots. They turn months of manual chemistry work into minutes of automated execution.
Congrats on the launch @drecmb & @ZJoncev!
ycombinator.com/launches/O3V…
20
26
126
14,843