
4 Photos and videos




Lawrence Spracklen retweeted

25 Aug 2023
80% of 80% of all economically valuable jobs will be capable of being done by AI.
Years ago I asked -- to the consternation of many -- whether we needed doctors.
Then I asked whether we needed teachers.
High time we ask whether we need financial analysts, bankers, traders, etc.
Welcome, @Arkifi
116
95
777
354,173

21 Aug 2023
Excited to be part of this! My team is hiring for multiple AI positions!
1
1
124

Let’s get beyond the hype of ChatGPT, and get down to the details.
Learn about Large Language Models (LLMs) and more from our panel of experts from @Numenta and Intel. Watch now. intel.ly/41NmmYM #IntelAI #IntelXeon


5
9
53
31,907
Lawrence Spracklen retweeted

18 Apr 2023
Our LinkedIn Live discussion with @Numenta is happening tomorrow at 10am PST.
Hear from @spracklen at Numenta and Intel’s Ronak Shah and Sancha Norris to learn about Large Language Models (LLMs) based on 4th Gen #IntelXeon technology.

1
4
10
4,541
Lawrence Spracklen retweeted
12 Apr 2023
Are Large Language Models and ChatGPT right for your enterprise?
Join us next week on April 19th for a discussion with @spracklen from @Numenta and Intel’s Ronak Shah and Sancha Norris to learn about 4th Gen #IntelXeon and #GenerativeAI.
15
48
26,149
7 Apr 2023
A more detailed overview of the results that were shared during the Intel 4th gen processor launch earlier this year.
This particular demonstration is focussed on larger sequence lengths, and uses an Intel system with HBM (High Bandwidth Memory) support.
#deeplearning #AI

1
5
2,233
Lawrence Spracklen retweeted

6 Apr 2023
Whether running short text snippets or long documents through natural language processing models, #IntelXeon CPU Max Series with #OpenVINO toolkit and #oneAPI enables excellent performance boosts over other CPUs. Learn more here. intel.ly/43dOqWJ #HPC

1
3
14
5,952
3 Apr 2023
For everyone excited by the potential of generative AI, but concerned by the astronomical compute costs, @IntelBusiness and I (@Numenta) are talking about how to achieve game changing improvements in inference performance for GPT models:
numenta.com/company/events/g…
1
2
1,009
13 Jan 2023
Move from running your existing Transformer models from Hugging Face on Ice lake processors to Numenta Transformer models on Intel's Sapphire rapids, and improve inference throughput by over 120X..... Seamless integration into common MLOps solutions.
New on our blog: our VP ML @spracklen explains why the new 4th Gen #IntelXeon is a great fit for our neuroscience-based technology, and dives deeper into our dramatic throughput and latency performance improvements.
numenta.com/blog/2023/01/12/…
1
1,004
11 Jan 2023
Great to see @IntelAI showcasing the benefits of our @Numenta technology running on their latest server processors. 62X throughput improvement compared with standard BERT-large on Ice Lake, and 123X compared with AMD Milan.
intel.com/content/www/us/en/…
1
145
10 Jan 2023
Numenta Achieves 123X Inference Performance Improvement for BERT Transformers on Intel Xeon Processor Family - businesswire.com/news/home/2…
1
65
11 Jan 2023
Numenta's technology integrates seamlessly with @IntelSoftware #oneAPI and OpenVINO. #IntelXeon
43
Lawrence Spracklen retweeted

10 Jan 2023
The #XeonMax CPUs help @Numenta dramatically accelerate large language models that can analyze, categorize, and translate large collections of text documents.
For long sequences, Numenta achieves 20x throughput speed-up on #XeonMax compared to other CPUs.
intel.ly/3WZnoyR

9
36
3,816

⚠️ MEDIA ALERT ⚠️
Numenta Achieves 123X Inference Performance Improvement for BERT Transformers on @intel's new Xeon Processor.
A thread👇(1/4)
numenta.com/press/2023/01/10…
2
13
66
12,120
Announcing the Numenta Private Beta Program 🚀
Built on decades of neuroscience research🧠, our technology enables powerful and scalable deep learning applications.
Apply and get early access to our solutions for NLP and Computer Vision today at numenta.com/beta

6
22
2,010
We’re currently running a limited closed Beta Program for our brain-based AI products. Check out our November #newsletter for more details, job openings, new content, and more!
mailchi.mp/numenta/newslette…

1
3
6
.@spracklen and @lucasosouza will be speaking at @AIDevWorld next Tues (10/25) at 2pm PT. They will be talking about how to accelerate AI models and optimize hardware efficiency, unlocking order-of-magnitude speedups and energy savings.
numenta.com/company/events/a…
2
3
4 Oct 2022
Excited to be presenting our (@Numenta) recent research to Stanford's SystemX Alliance next week: systemx.stanford.edu/events/…
Accelerating your DL models on existing CPUs, GPUs by 100X...
1
2
12
We presented at #EdgeAISummit last week and it was great to be back in person and back on stage again. You can find @spracklen's closing keynote on deep learning at the edge here: slideshare.net/numenta/deep-…
1
4
Lawrence Spracklen retweeted

15 Sep 2022
Closing the event with a keynote on deep learning at the edge, @spracklen shows how @Numenta is getting 100x performance improvements. #EdgeAISummit

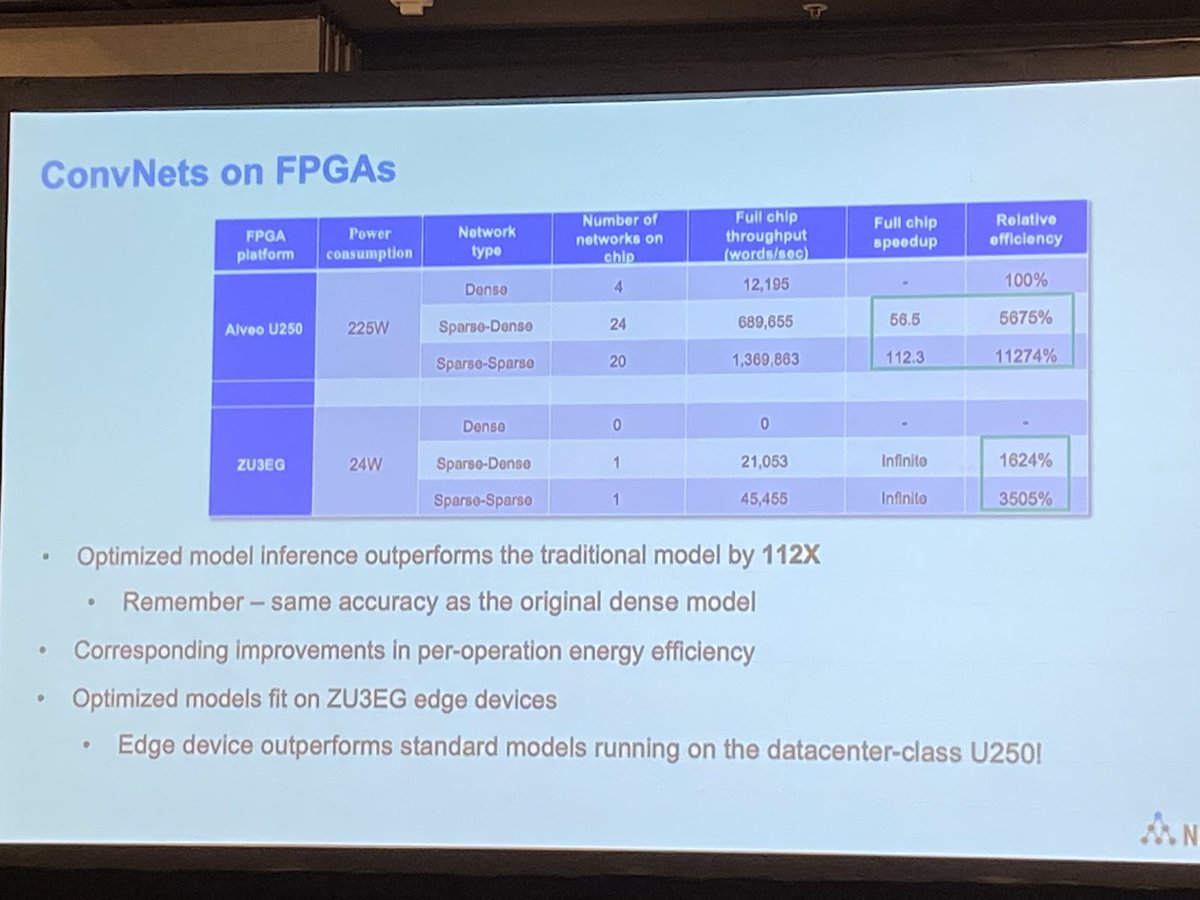
3
7