
128 Photos and videos
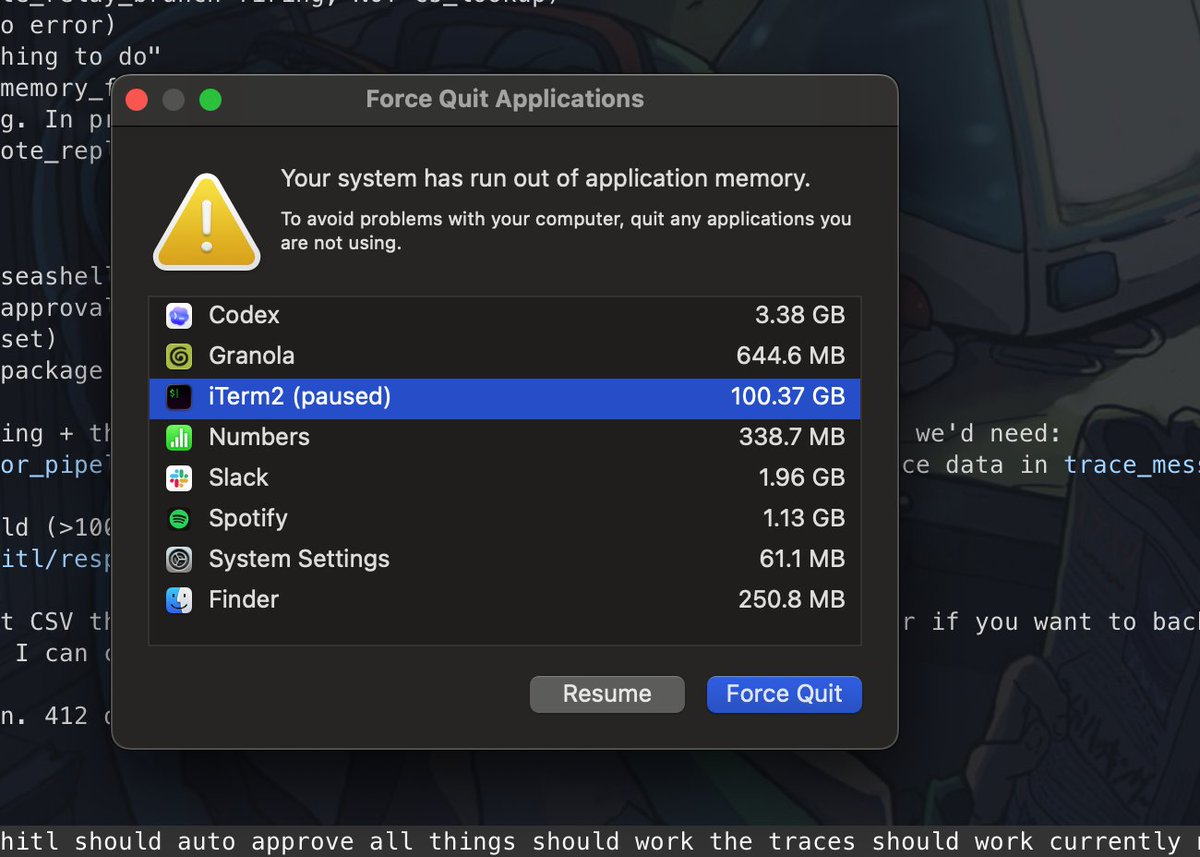







sarthak retweeted

May 22
coding by itself is a tool-shaped object.
we once wrote far more low-level code to express basic logic before higher-level languages compressed the work
today’s swe discourse risks the same trap: celebrating PRs and commits while struggling to explain actual economic throughput
1
2
91
sarthak retweeted

19 Oct 2012
Soch raha hoon wat to tweet
1,590
2,407
4,327
sarthak retweeted
Apr 29
I wish there was a way to know you're in "the good old days", before you've actually left them
from The Office


2
1
7
206


sarthak retweeted

i vibe coded my way into this and im gonna vibe code my way out of this
i think
46
27
901
20,815
sarthak retweeted

Jan 17
also the later mode can only take ur vague idea to v1 - after that without critically thinking about the design and clarity of what is actually required - the cc slot machine would create a load of unusable code
thinking is always gonna be the moat - its the core component of engineering
and if u find fun with the slot machine, u r not a real engineer - u r chasing dopamine
1
1
178


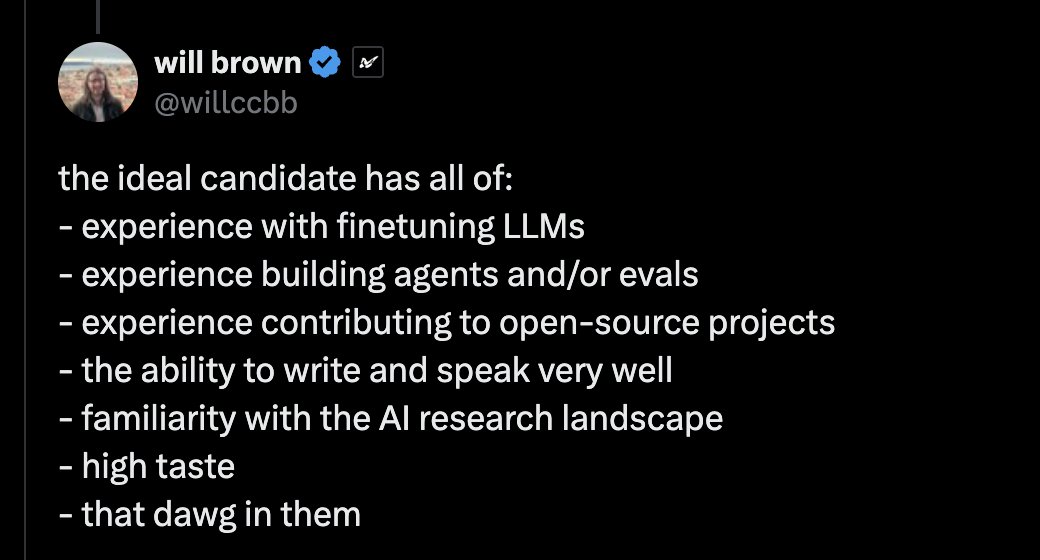
Some long but hopefully helpful thoughts about self learning these things:
The list is actually in reverse chronological order imo if you are starting from 0.
"familiarity with the AI research landscape" <> "high taste".
I think it starts with reading. Read papers, read discussions on here, ask (dumb) questions. Have a feel for what people are doing, how they think about problems, how they think about the solutions to these problems. Also, get out of tutorial hell/from-scratch hell asap.
Step 2: Congrats, you should now have a somewhat "unique" but still possibly wrong perspective towards AI research. Evals are a good next step.
Start thinking about what you think are gaps in existing literature. Are people evaluating a certain capability wrongly? Are people not evaluating a certain capability at all? Why? Notice that everyone is using the same set of evals because the interesting ones are all proprietary. What do you think is missing?
Step 3: Hopefully, you've come up with an eval that exposes unique and useful failure modes. Now you've got to come up with the solution. Try prompting, ICL, dspy? Only when all of these fail, then try finetuning.
A common misconception is that writing the finetuning code is difficult. I disagree. For most usecases, just use Axolotl, LlamaFactory etc. The highest barrier to entry is the data.
What approach works best for your particular task? Big model distillation? Or are you working with synthetic tasks? What are the latest papers doing? For example, specialised experts seem to be new thing from the Chinese labs. If you are doing RL, what should your reward be like? What are some of the interesting techniques you've come across? Can they be applied to your problem?
Iteration speed is important for learning here. Keep trying out things and see what works and what doesn't. Iteration is so important: read new paper -> does it apply to my task -> implement -> try -> repeat
Miscellaneous:
> Building Agents.
Since most people reading this probably come from a more traditional SWE background, this is the simplest step. It is largely normal SWE, but with an understanding of the current 'meta' and implementing these techniques. As an example: how many tools? Grep or semantic search?
> OSS contribution
Many more accomplished people have spoken about this so i'll just re-emphasize, don't optimize for commits for the sake of commits. Contribute because you actually use a certain project and encountered a certain bug or want a certain feature yourself.
Also, do not 100% vibe code a PR. Your reputation is more important than the contributor status.
> Write and speak very well.
Honestly, im not the right person to ask lmao. All im gonna say is that if you spend too much time on this site, your ngmi in this regard :)
And lastly, "that dawg in them". I interpret this as agency. Everyone's building RL environments nowadays and its actually a very good analogy for learning. You want to build the best possible environment for yourself to improve as much as possible. This means never stop training (learning), keep doing things (rolling out) and verifying (asking questions/doing experiments). You are the agent in this analogy.
28 Oct 2025

Genuine question: where does one even go to learn a lot of this stuff? I doubt it is in school. Do people find resources online and self study? Is this just a sign of the sector maturing and people are expected to learn these skills at other jobs?
I’ve learned a decent amount of this, but my statistics PhD and a genuine interest carried a lot of that, and it’s entirely theoretical as I have had no industry experience
8
40
574
52,784
sarthak retweeted

13 Oct 2025
can your llm rotate a shape inside it's head?
i found out yes but it's a fucking idiot when it comes to the upper layer...
why? non uniform spatial reasoning....
here's an eval to test the internal latent reasoning of your models.

4
12
121
23,501
sarthak retweeted

27 Sep 2025
Developer documentation should be written:
LLm first.
Humans second.
27 Sep 2025

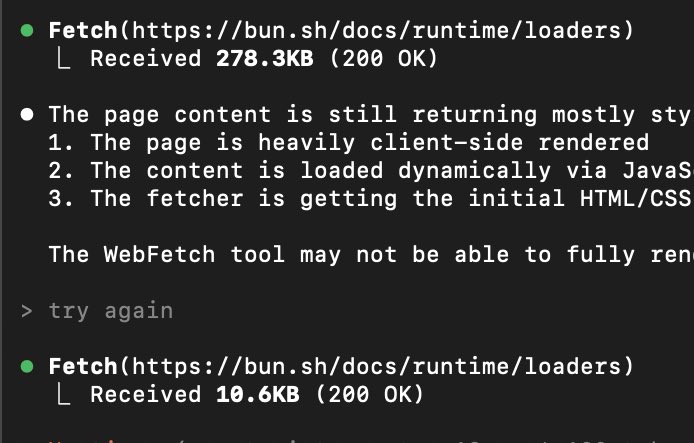
When Claude Code fetches Bun’s docs, Bun’s docs now send markdown instead of HTML by default
This shrinks token usage for our docs by about 10x
4
2
68
8,632
sarthak retweeted

25 Sep 2025
Another week, another hundred environments.
From autonomous AI research, MCP integrations, and browser automation to domain specific environments for economically valuable tasks across law, finance, and tax.

6
20
144
64,216

sarthak retweeted
25 Sep 2025
how models be acting after they get quantized

1
1
16
561
sarthak retweeted

24 Sep 2025
Prediction: In ~3 years academia will be the most desirable place to do fundamental AI research
Contributing factors:
- small models improve/become significantly more impactful
- open weights community broadens its reach
- gpus continue to get faster & cheaper
- meaningful post-training/RL experiments become more and more tractable
- raw capabilities of large models plateau (100% acc is actually a wall) => "foundation models" become commodity => product matters more
there will obviously be incredibly important problems at the frontier of a gazillion parameters, of models launching 100k agents, and training incredibly complex systems with one million gpus. But there will be so many more and incredibly important problems at the hands of a community that is free to ask any questions they like, and benefits directly from sharing with everyone else.
23
36
466
58,202