
177 Photos and videos

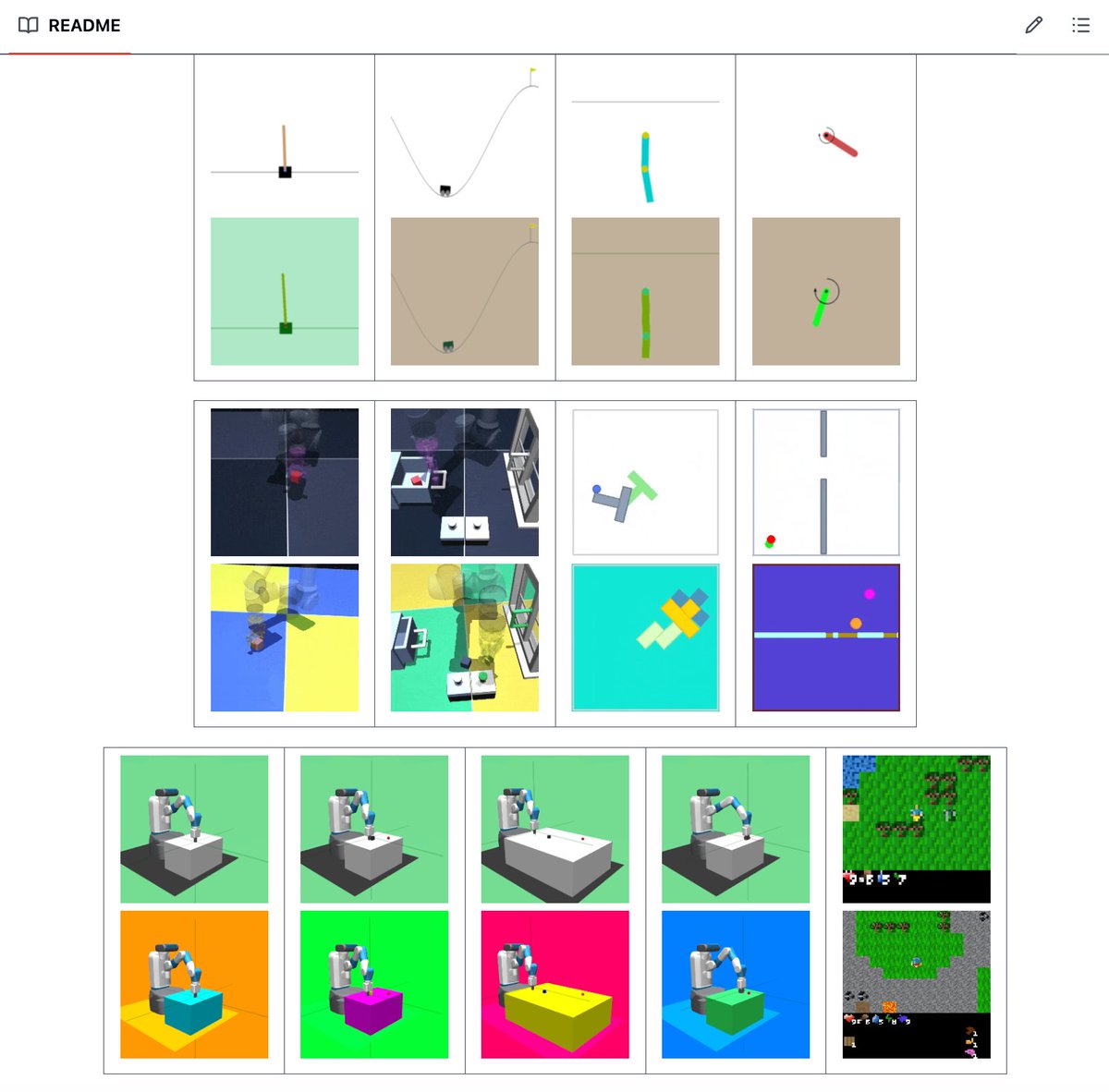












we built an open-source version of workspace agents
- any model, self-hosted
- per-session sandbox
- credential isolation
github.com/stainlu/openclaw-…

Introducing workspace agents in ChatGPT—shared agents that can handle complex tasks and long-running workflows across tools and teams.
36
49
540
972,946
grats @AnthropicAI on freaking us off all work related to LLM.
how does it feel to become 'god'?
Jun 9

mythos will be bad ON PURPOSE on ai "frontier llm research" tasks, this is very very sad for the research community
also the fact that this is un purpose not visible to the user is crazy

1
88
now on: loopengineering.md/

1
104

my real dream is to play dota 4 for 4000 hours without feeling hungry.
Jun 6

my real dream is to play civilization 6 for 30 hours without feeling guilty.
73
13?
Jun 6

VLA-JEPA just dropped in LeRobot 🤖
What makes this model special is that it does not just learn what action to take from a given observation, it also leverages a JEPA world model to learn action-relevant dynamics.
During training, the VLA leverages V-JEPA2 by conditioning its predictor. This clever trick adds a world modeling objective to the training, which also allows pretraining on human videos.
At inference, the world model is dropped entirely, keeping only a standard VLA architecture: Qwen backbone and action head.
The demo here was only fine-tuned on 13 examples, showing great pretraining capability and running in real time on @NVIDIARobotics DGX Spark!
VLA-JEPA is the first world model to be ported to LeRobot, and I feel like it won't be the last 🚀
@Thom_Wolf @ClementDelangue
100
Stop writing words like this plz.
People won’t like it at all.
Jun 8

The north stars we're working towards at OpenAI all center around the mission: ensure AGI benefits all of humanity. AI should expand human agency, not make people less consequential to the future.
openai.com/index/built-to-be…
78
MORE to come
Jun 4

Pulled the trigger today and switched 100% of Lindy traffic to DeepSeek v4, churning from Anthropic models.
Saves us millions of $ and we're actually seeing an *increase* in performance on many core use cases. Transformative for the business.
108
hard to describe how important Dimitri is to all these fields. RIP.
Jun 4

We've lost an absolute giant today. RIP Dimitri Bertsekas. His probability and optimization books got me through my masters. Massive loss for the MIT community and the field.
79





Lee las publicaciones originales de Karpathy sobre cómo utiliza Obsidian. Personalmente, no me gusta el término "segundo cerebro", ya que sugiere que Obsidian debería usarse únicamente como un sistema de memoria externalizada. Más bien, es importante considerar que escribir es una forma de pensar. Si dejas que la IA haga todo el trabajo de pensar, no estarás aprendiendo por ti mismo.
x.com/karpathy/status/176146…
24 Feb 2024

Love letter to @obsdmd to which I very happily switched to for my personal notes. My primary interest in Obsidian is not even for note taking specifically, it is that Obsidian is around the state of the art of a philosophy of software and what it could be.
- Your notes are simple plain-text markdown files stored locally on your computer. Obsidian is just UI/UX sugar of pretty rendering and editing files.
- Extensive plugins ecosystem and very high composability with any other tools you wish to use because again it's all just plain-text files on your disk.
- For a fee to cover server costs, you can also Sync (with end-to-end encryption) and/or Publish your files. Or you can use anything else e.g. GitHub, it's just files go nuts.
- There are no attempts to "lock you in", actually as far as I can tell Obsidian is completely free of any user-hostile dark patterns.
For some more depth, I recommend the following writing from CEO @kepano:
- "File over app" stephango.com/file-over-app . If you want to create digital artifacts that last, they must be files you can control, in formats that are easy to retrieve and read. Accept that all software is ephemeral, and give people ownership over their data.
- "100% user-supported" stephango.com/vcware . On incentives alignment.
- "Quality software deserves your hard‑earned cash" stephango.com/quality-softwa…
TLDR: This is what software could be: private, secure, delightful, free of dark patterns, fully aligned with the user, where you retain full control and ownership of your data in simple, universal formats, and where tools can be extended and composed.

9
9
326
7,687
Stain Lu retweeted

May 28
Most "agents" are basically interns with API access.
They ask you to subscribe to the Times. Download the file. Forward it over. You're not deploying an agent at all. You're managing one.
It's why we built Anyway. Anyway is the financial OS for agents that actually operates by itself. Pay, transact, and run your own business, with no babysitter required.
Comment "Anyway" to try it out.
124
134
2,016
2,035,473
we need more 'worlds'
May 28

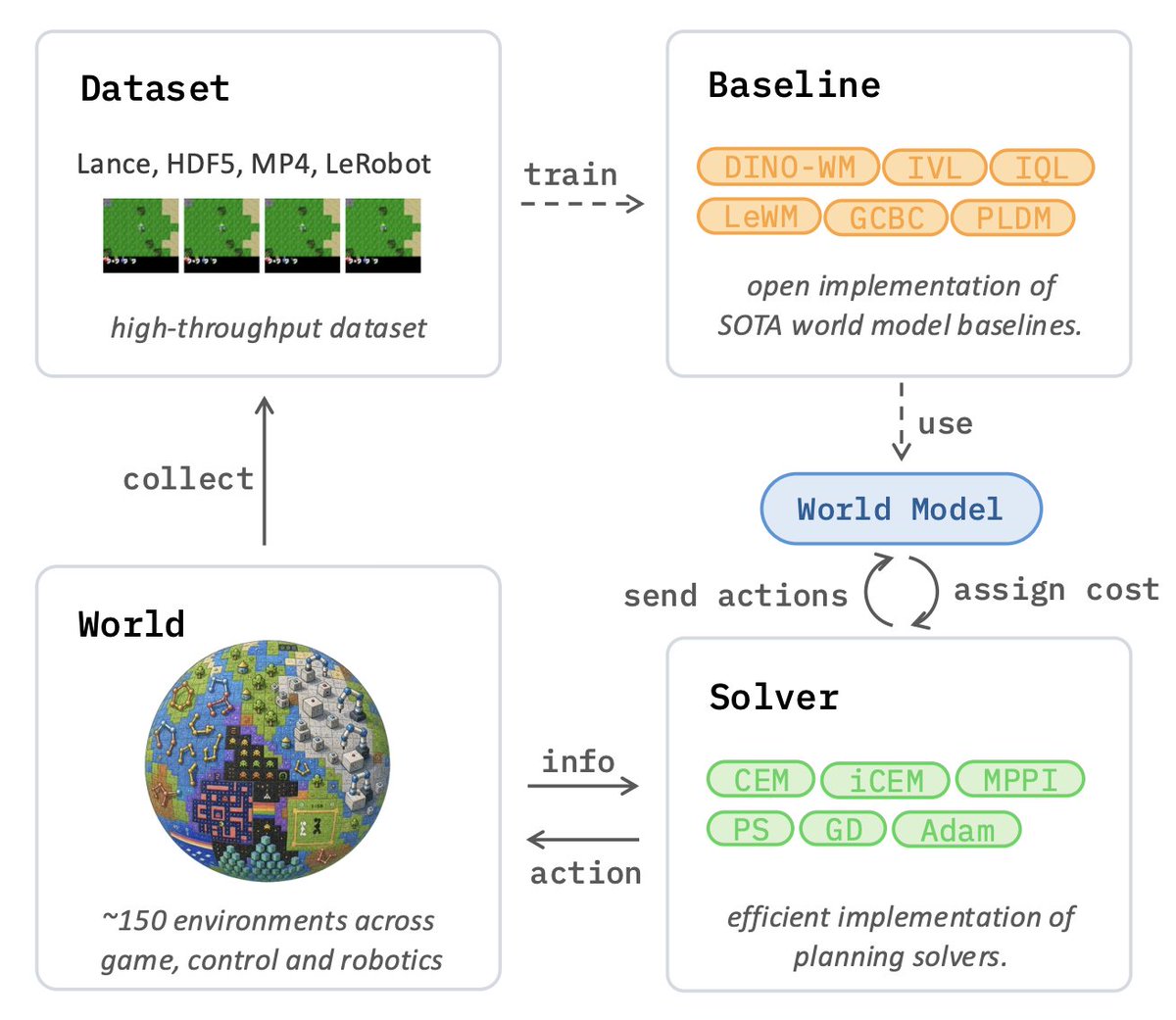
Would you like to join the research effort on JEPA and World Models easily?
After a full year of hard work, we’re excited to finally release stable-worldmodel:
an open-source, scalable platform built to accelerate JEPA & World Model research!
📄: github.com/galilai-group/sta…
2
126
[✅] abstraction
[ ] encapsulation
[ ] inheritance
[ ] polymorphism

79
Stain Lu retweeted

May 27
Introducing DiffusionBlocks: Block-wise Neural Network Training via Diffusion Interpretation
pub.sakana.ai/diffusionblock…
What if we didn’t have to hold an entire neural network in memory to train it?
Standard neural net training optimizes all parameters jointly. As a result, the memory required during training grows linearly with the depth of the network.
In our #ICLR2026 paper, we propose DiffusionBlocks, a principled framework to train networks one block at a time, drastically reducing memory requirements while matching end-to-end performance.
With DiffusionBlocks, we split the network into blocks and train them one at a time, so you only need memory for a single block.
How? We explicitly assign each block a role: to move the representation a little closer to the target than the block before it did. That role turns out to be precisely what a diffusion model does, step by step. Each block only needs to optimize its own objective and can be trained independently.
We validated this across five different architectures:
• ViT
• DiT
• Masked diffusion
• Autoregressive transformers
• Recurrent-depth transformers
In each case, performance is competitive with end-to-end training while using a fraction of the memory.
This perspective also extends naturally to recurrent-depth (Looped) transformers, which apply the same network iteratively and normally require expensive backpropagation through time (BPTT). Viewed through DiffusionBlocks, we can replace those multiple iterations with a single forward pass during training.
Read our paper and code, to learn more.
Paper: arxiv.org/abs/2506.14202
GitHub: github.com/SakanaAI/Diffusio…
🐟
56
368
2,327
862,743