
Postdoctoral Researcher @Princeton. Reliable, safe, trustworthy machine learning. Previously: @UofT @VectorInst @TU_Muenchen @Google @awscloud
Joined April 2010
- Tweets 10,125
- Following 384
- Followers 790
- Likes 489
1,049 Photos and videos






Pinned Tweet
Very excited to share that our paper "Towards a Science of AI Agent Reliability" was accepted at ICML 2026! See you in Seoul! 🎉
We just released our camera ready version with three important updates (details below). We also recorded a short video on the paper's contributions.
Main changes (full discussion at hal.cs.princeton.edu/reliabi…):
1️⃣We have added the latest set of frontier models to our evaluation (GPT 5.5, Gemini 3.1 Pro and 3.5 Flash, and Claude Opus 4.7) and find that they are not meaningfully more reliable than previously released models. Agent reliability is still far from being solved.
2️⃣We have updated the definition and measurement of our outcome consistency metric, which contained a typo in the pre-print we initially released. This caused us to under-estimate outcome consistency in our initial set of results. We have updated the paper and our codebase to the corrected metric. Despite this change, our new results show that outcome consistency is still surprisingly low across many reported models.
3️⃣We discovered multiple issues in our HAL Generalist Agent scaffold that we used for our experiments on GAIA. Notably, we discovered multiple instances of answer leakage and agents cheating on our evaluation. This caused us to slightly over-estimate both accuracy and reliability. At the same time, we noticed that the scaffold was overly constrained in terms of permissible software library imports. This caused us to slightly under-estimate both accuracy and reliability. We have done a rigorous audit of the scaffold and have fixed those issues. Overall, we saw that our resulting accuracy and reliability numbers are not meaningfully impacted by this change when compared to our original numbers.
📄Our paper: arxiv.org/abs/2602.16666
📊Our dashboard: hal.cs.princeton.edu/reliabi…
🎥Short video: youtu.be/qftDfEft7U0
Joint work w/ @sayashk, @PKirgis, @khl53182440, @SaitejaUtpala, and @random_walker.
13
36
248
24,026
Stephan Rabanser retweeted

Jun 11
First paper of my PhD with my amazing advisors!
There’s been a ton of hype and media coverage on OpenEvidence as an “AI co-pilot for clinicians”… and our long-horizon benchmark puts them to the test!! Our results suggest they are far from reliable for downstream use.
Jun 11

New preprint!
We introduce a new benchmark, SciConBench, with 9.11k scientific questions derived from Cochrane Systematic Reviews.
We find evidence that frontier AI agents **cannot** synthesize scientific conclusions well.
A thread 🧵
w/ @hayounggjung, @korolova & others

1
4
12
1,612

May 25
At last week's developer conference, Google claimed that their newest frontier model produced an operating system from just a single prompt and ~$900 in API cost. At first sight, this seems impressive. But on closer look, the evidence is much thinner than the headline suggests.
Most notably:
- The "single prompt" framing suggests that the agent could do this from just a few sentences with high-level instructions. But the prompt itself is many thousands of lines long and it is unclear what instructions Google provided in the prompt (and how much effort it took to even come up with the prompt in the first place).
- There is a lot of OS code on the internet and it is often attempted as a class project in college OS classes. Based on the information provided in Google's blog post, it is unclear to what extent the agent simply copied a well-known implementation from the internet.
- In such long-running, complex implementation tasks, it is important to understand what degree of human intervention was performed to help the agent achieve its goals. However, Google remains ambiguous about the level of hand-holding they performed in this experiment. They say that "no additional guidance or corrections from a human" were necessary, yet they document instances of imposing anti-cheating mechanisms between runs.
- Many key artifacts, such as the code, the prompt, and agent logs are unreleased. This makes it impossible for external researchers to verify these marketing claims.
- To Google's credit, they did release the overall cost and token budget. These details often remain undisclosed, and sharing them is a first step in the right direction.
More detail in our writeup at normaltech.ai/p/did-googles-…
w/ @sayashk @RishiBommasani Andrew Schwartz @random_walker
2
3
12
4,651
May 13
Working with agents for the past months has me convinced that outcome-only evaluation is a flawed approach to benchmarking. You need to look at the logs to understand if the agent really did its job!
In our paper Log analysis is necessary for credible evaluation of AI agents, we
➡️introduce a taxonomy of threats to credible evaluation of AI agents (including construct validity and safety evaluation concerns);
➡️outline four key principles for conducting log analysis effectively;
➡️present a case study of how log analysis helped us to find a variety of benchmarking errors on τ-bench; and
➡️give a set of recommendations to improve log analysis quality and adoption.
📄arxiv.org/abs/2605.08545
More details in @PKirgis's thread below ⬇️
May 13

New paper: Log analysis is necessary for credible evaluation of AI agents. Benchmarks tell us what the agent achieved; only logs reveal how and why. As agents grow more capable and benchmarks more open-ended, that distinction will only matter more. 🧵
Paper: arxiv.org/pdf/2605.08545

1
5
13
3,332
Stephan Rabanser retweeted

Apr 27
Most agentic benchmarks center around tasks that are automatically verifiable.
But any task that is veriafiable is also easy to optimize for.
This work instead describes the future of critical open world evaluations.
Led by @sayashk, our current draft is now live.
Apr 16

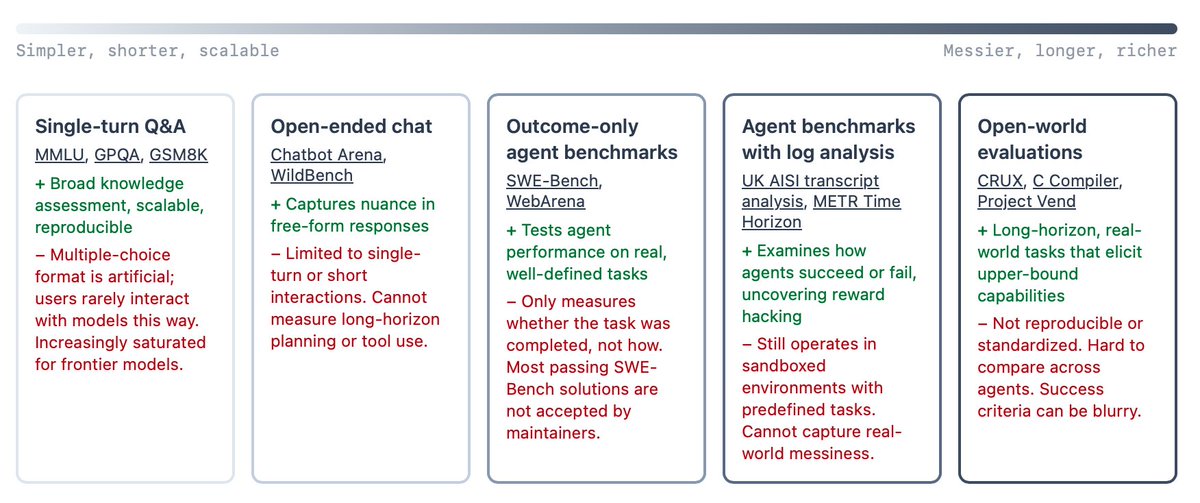
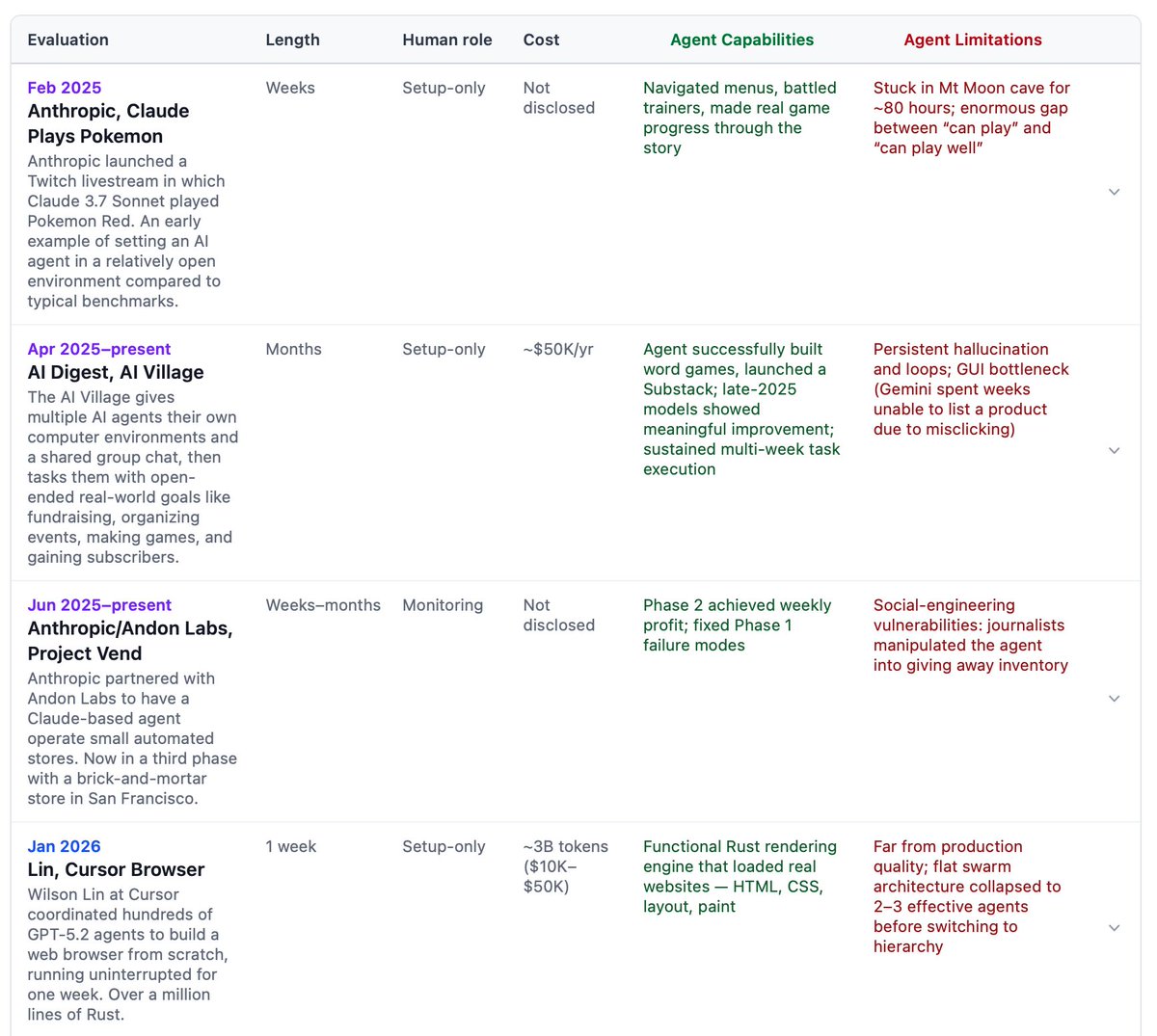
Benchmarks are saturated more quickly than ever. How should frontier AI evaluations evolve? In a new paper, we argue that the AI community is already converging on an answer: Open-world evaluations. They are long, messy, real-world tasks that would be impractical for benchmarks.

ALT title, author list, abstract of the paper
8
21
192
41,192
Apr 24
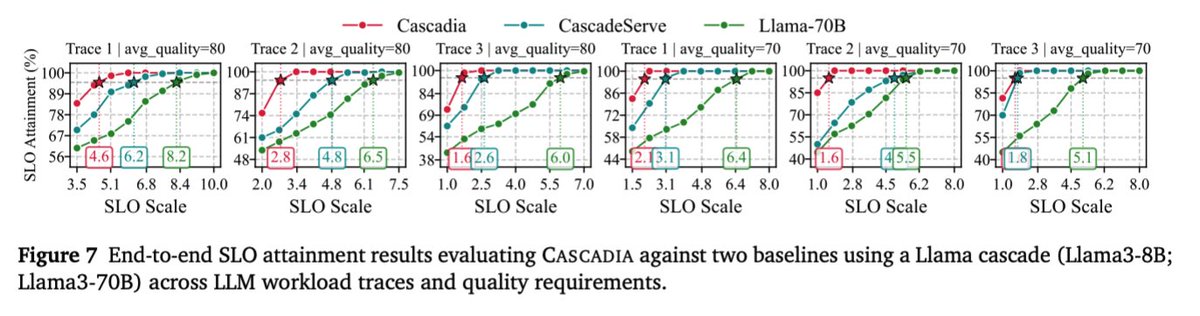
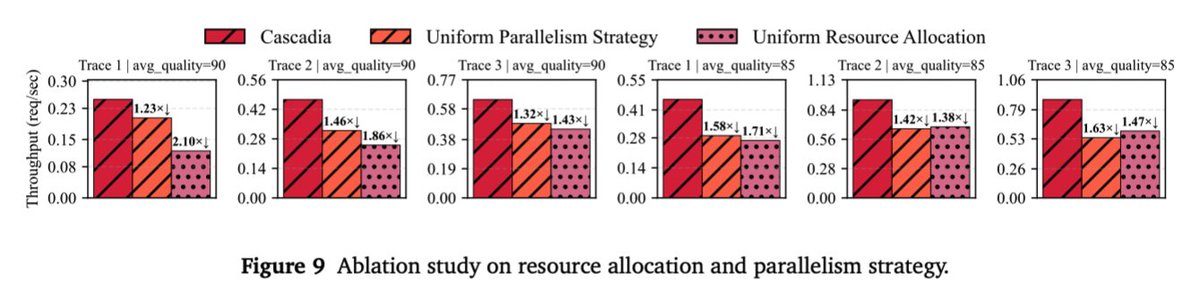
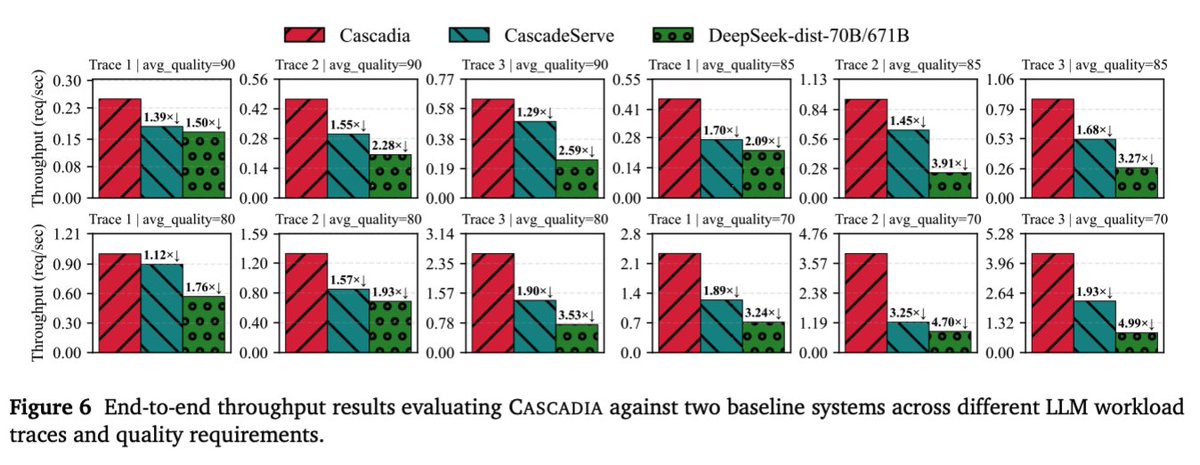
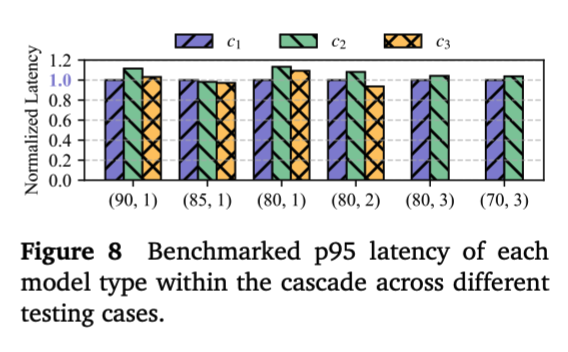
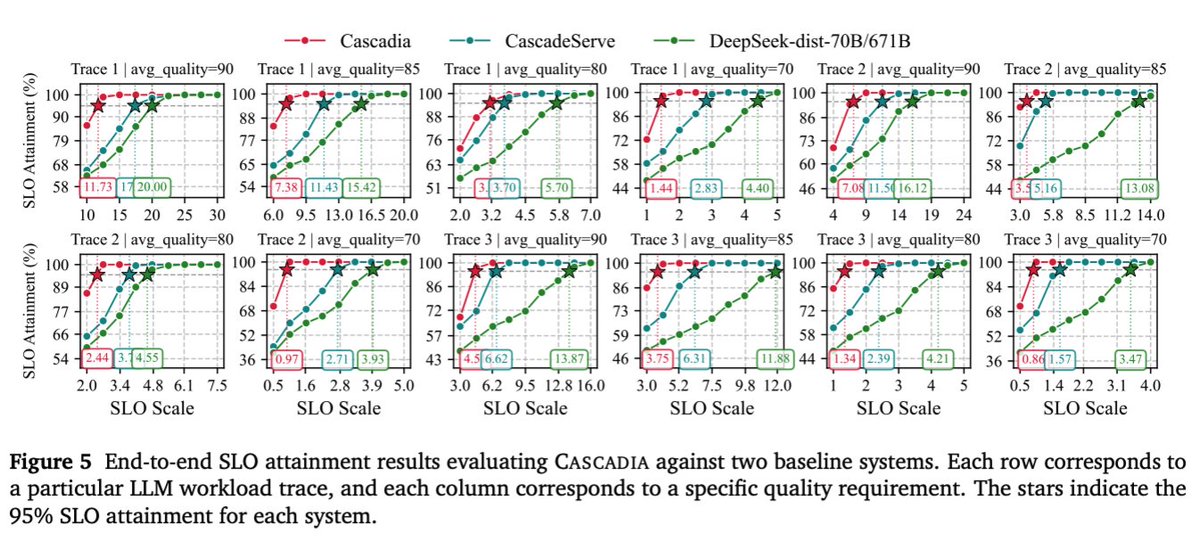
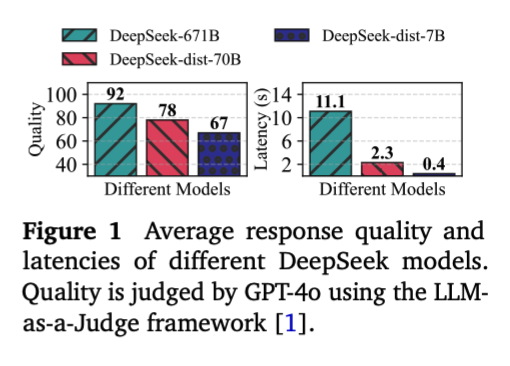
Sadly wont be at ICLR but if you are make sure to check out our model cascading work!
Big LLMs give great answers but they're costly. Small LLMs are fast but weaker. What if you could get the quality of the big one at the latency of the small one most of the time?
Meet CASCADIA, a novel cascade serving framework designed explicitly to schedule request
routing and deploy model cascades for fast, quality-preserving LLM serving.
1
2
1,991
Apr 24
Also, our plan isn't fixed: it reshapes itself to the quality bar. Drop the quality target from 90 → 85 on the same trace, and Cascadia routes 21% (not 50%) to the 671B and reallocates 4 of its GPUs to the smaller models. So the same system yields a very different cascade.
1
1
55
Apr 24
Check out our poster on Sat, Apr 25, 2026 11:15 AM – 1:45 PM PDT in Pavilion 3 P3-#1625!
ICLR link: iclr.cc/virtual/2026/poster/…
Paper: arxiv.org/abs/2506.04203
Joint work with @youheyork, Fangcheng Fu, @Renee42581826 (lead authors) and @Jintao_Zhang_, @niclane7, @Hades317.
3
143
Stephan Rabanser retweeted

Apr 17
Glad to be a part of this initiative to develop open-world evaluations for AI. We need the ability to assess just how capable agents are becoming in order to anticipate and respond to the impact they can have on real world systems and transactions. An agent that can successfully act on the general instruction “build an app and get it posted in the App Store” is one that brings us closer to an economy of agents, with significant implications for how markets behave and need regulating arxiv.org/pdf/2509.01063
Apr 16
Benchmarks are saturated more quickly than ever. How should frontier AI evaluations evolve? In a new paper, we argue that the AI community is already converging on an answer: Open-world evaluations. They are long, messy, real-world tasks that would be impractical for benchmarks.
ALT title, author list, abstract of the paper
1
6
23
6,052
Stephan Rabanser retweeted

Apr 17
Yesterday, we announced CRUX, a project that aims to conduct regular “open-world evaluations,” where we will be testing the ability of AI agents to complete long-horizon tasks in messy, real-world environments. @sayashk's post dives into the details; here are a few of my own thoughts about why this is worth doing.
Apr 16
Benchmarks are saturated more quickly than ever. How should frontier AI evaluations evolve? In a new paper, we argue that the AI community is already converging on an answer: Open-world evaluations. They are long, messy, real-world tasks that would be impractical for benchmarks.
ALT title, author list, abstract of the paper
1
3
12
4,085
Stephan Rabanser retweeted

Apr 17
This paper makes a strong case for open-world evaluations as a complement to traditional benchmarks, particularly for realistic, long-horizon, open-ended settings!
Glad the AISI SoE team could contribute to this effort.
Apr 16
Benchmarks are saturated more quickly than ever. How should frontier AI evaluations evolve? In a new paper, we argue that the AI community is already converging on an answer: Open-world evaluations. They are long, messy, real-world tasks that would be impractical for benchmarks.
ALT title, author list, abstract of the paper
1
5
28
8,212
Stephan Rabanser retweeted

Apr 16
Benchmarks are saturated more quickly than ever. How should frontier AI evaluations evolve? In a new paper, we argue that the AI community is already converging on an answer: Open-world evaluations. They are long, messy, real-world tasks that would be impractical for benchmarks.
ALT title, author list, abstract of the paper
15
52
251
94,149