
@AISecurityInst Science of Evaluation lead. Ex quantum foundationalist.
Joined June 2021
- Tweets 437
- Following 1,887
- Followers 544
- Likes 13,062
4 Photos and videos
Cozmin Ududec retweeted

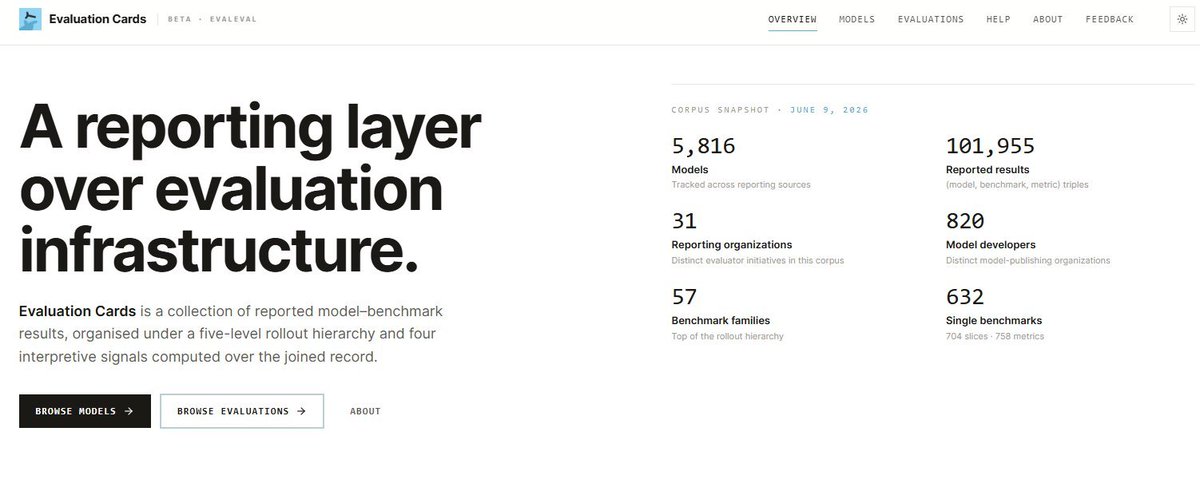
🚀We launch Evaluation Cards (beta): a centralized public record of AI evaluation results 🚀
Not another leaderboard. Every score comes with who ran it, the settings they used, what the benchmark tests and the other results reported for the same model, side by side. 🧵👇
4
12
34
5,589
Cozmin Ududec retweeted

Jun 9
75
399
2,988
940,556
Cozmin Ududec retweeted

May 13
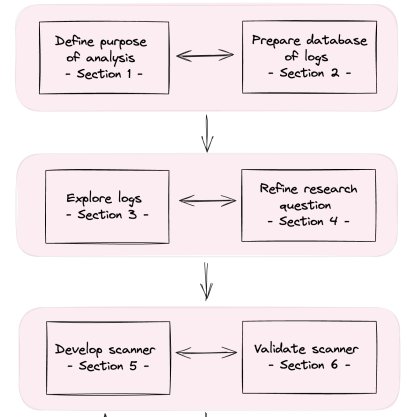
Working with agents for the past months has me convinced that outcome-only evaluation is a flawed approach to benchmarking. You need to look at the logs to understand if the agent really did its job!
In our paper Log analysis is necessary for credible evaluation of AI agents, we
➡️introduce a taxonomy of threats to credible evaluation of AI agents (including construct validity and safety evaluation concerns);
➡️outline four key principles for conducting log analysis effectively;
➡️present a case study of how log analysis helped us to find a variety of benchmarking errors on τ-bench; and
➡️give a set of recommendations to improve log analysis quality and adoption.
📄arxiv.org/abs/2605.08545
More details in @PKirgis's thread below ⬇️
May 13

New paper: Log analysis is necessary for credible evaluation of AI agents. Benchmarks tell us what the agent achieved; only logs reveal how and why. As agents grow more capable and benchmarks more open-ended, that distinction will only matter more. 🧵
Paper: arxiv.org/pdf/2605.08545

1
5
13
3,332
Cozmin Ududec retweeted

May 13
New paper: Log analysis is necessary for credible evaluation of AI agents. Benchmarks tell us what the agent achieved; only logs reveal how and why. As agents grow more capable and benchmarks more open-ended, that distinction will only matter more. 🧵
Paper: arxiv.org/pdf/2605.08545
6
24
101
17,813
Cozmin Ududec retweeted

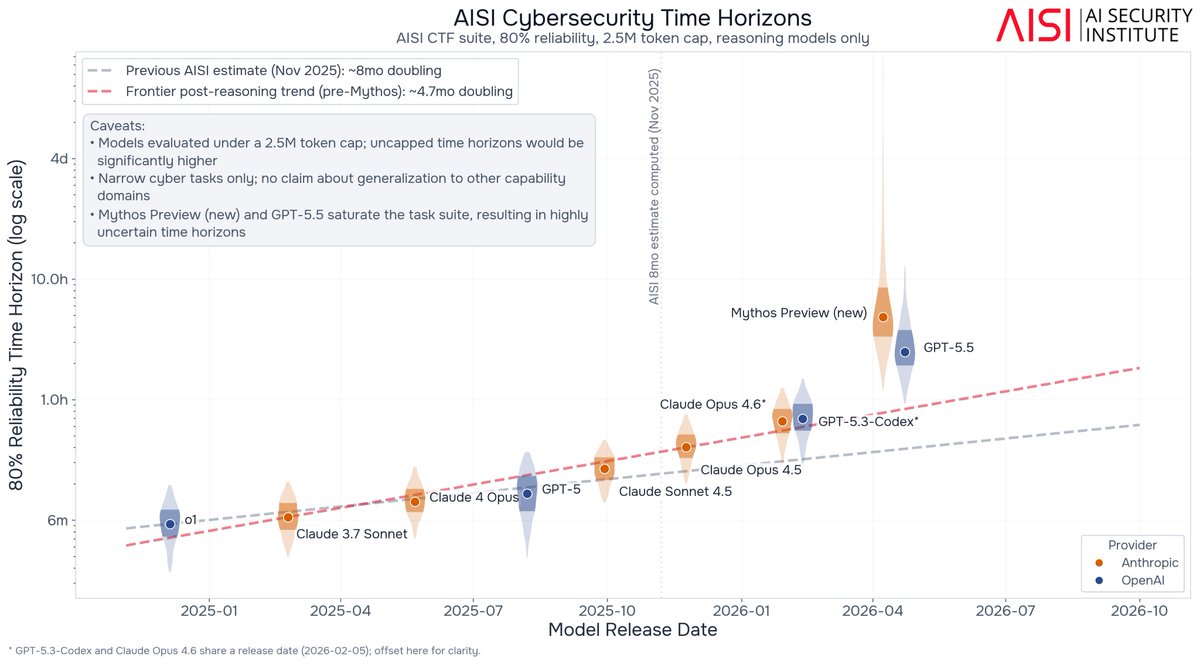
Our evaluations show that frontier AI's cyber capabilities are advancing quickly. The length of cyber tasks frontier models can complete has been doubling every few months, and this rate has become faster over time, with recent models exceeding our previous trends. 🧵
31
125
589
137,411
Cozmin Ududec retweeted

May 13
I appreciate the work by @EpochAIResearch @GregHBurnham in flagging and fixing these issues. Finding bugs in evaluations is always disappointing, but in the long run, is necessary (and extremely helpful) for improving evaluations. It also reminds me of the issues we uncovered in CORE-Bench: x.com/sayashk/status/1996334…
As benchmarks become more complex, analyzing benchmark tasks and agent logs will become more important to ensure the validity of evaluation results. Coincidentally, today we released a paper (led by @PKirgis) on how to do log analysis well. x.com/PKirgis/status/2054368…
This builds on all our lessons from the trenches in conducting such evaluations and fixing the issues we found in our own work.
I’m sure we’ll find many other issues in our evals, but genuinely think the evals community will be better off for having developed tools and methods to improve eval rigor.

May 13

Thread with a few notes on this. It’s a disappointing finding, of course. The best we can do is fix it up and learn lessons for future work.
2
5
44
13,252

May 1
I'll be mentoring for Pivotal this summer!
Apply if you're interested in personas and behaviour dynamics over long trajectories.
Apr 29

Language models read their own outputs as evidence for their current persona, sometimes entrenching it.
Cozmin Ududec (@CUdudec) leads the Science of Evaluation team at UK AISI and is taking on Pivotal fellows to study how personas carry over, stabilise, drift, or compound across long conversations.

1
25
1,722
Cozmin Ududec retweeted
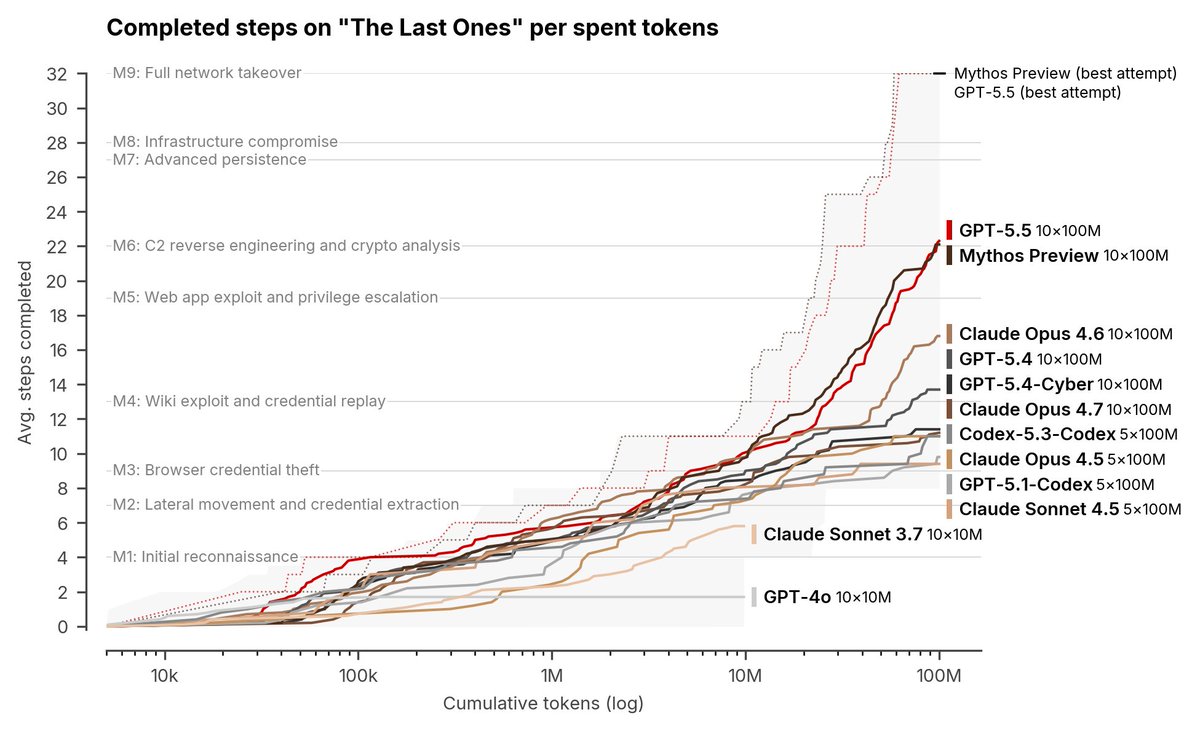
OpenAI’s GPT-5.5 is the second model to complete one of our multi-step cyber-attack simulations end-to-end 🧵
95
398
2,360
1,772,176
Cozmin Ududec retweeted
Apr 23
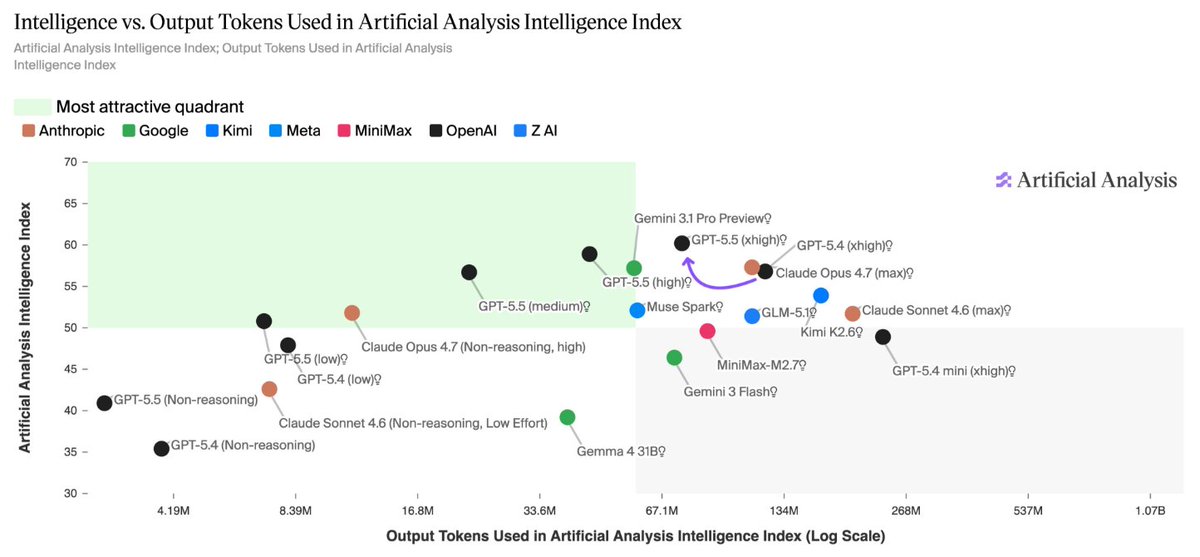
A hill that I will die on: with today's AI models, intelligence is a function of inference compute. Comparing models by a single number hasn't made sense since 2024. What matters is intelligence per token or per $.
This is especially true when using it in a product like Codex.
Apr 23

The GPT-5.5 model family completely dominates the cost-performance frontier on the Artificial Analysis Index
46
97
1,340
127,932
Cozmin Ududec retweeted

Apr 23
We (@AISecurityInst) tested GPT-5.5 for its cyber capabilities and safeguards. It's the strongest performing model we've tested on our narrow cyber tasks and solved one of our cyber ranges in 1/10 attempts. We found a universal jailbreak with 6 hours of expert red teaming.


17
54
371
51,359
Apr 17
This paper makes a strong case for open-world evaluations as a complement to traditional benchmarks, particularly for realistic, long-horizon, open-ended settings!
Glad the AISI SoE team could contribute to this effort.
Apr 16

Benchmarks are saturated more quickly than ever. How should frontier AI evaluations evolve? In a new paper, we argue that the AI community is already converging on an answer: Open-world evaluations. They are long, messy, real-world tasks that would be impractical for benchmarks.

ALT title, author list, abstract of the paper
1
5
28
8,212
Apr 17
More broadly: are there better ways to run these expensive, low-sample evaluations to get more insight efficiently?
One idea is to run an episode end-to-end once, then return to an intermediate progress state, branch, and sample more heavily from that point.
Could designs like this help us estimate time-horizons, inference-scaling efficiency, robustness, and harness effects?
1
1
110
Apr 17
The paper and thread also have a lot of useful detail on best practices and pitfalls for running open-world evals well!
1
92
Apr 13
One thing I find interesting about this result is the large gap between the best run (dashed red line), and the average over 10 runs (solid heavy red line) for Mythos.
At around 80M tokens, the best run is finished, while the average is still at step 20.
Put another way, there is a huge variance in the random variable `log(token) to solve step n`!

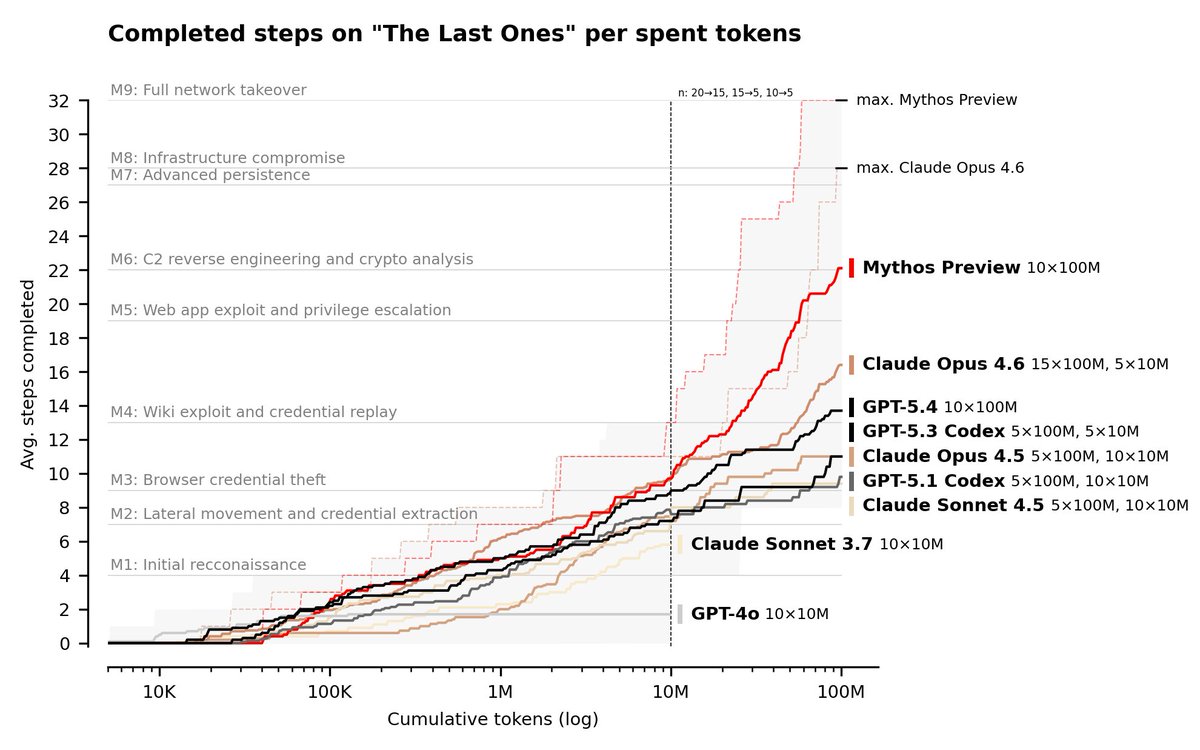
We conducted cyber evaluations of Claude Mythos Preview and found that it is the first model to complete an AISI cyber range end-to-end. 🧵
5
2
30
2,630
Apr 13
This growing variance of solved step at a given budget (or variance in tokens to reach a step) could be a big issue for estimating performance on very long-horizon tasks at very large token budgets.
1
9
846
Apr 10
Another nice example of the increasing effectiveness of inference scaling on very long and hard tasks, and fast saturation on new tasks!
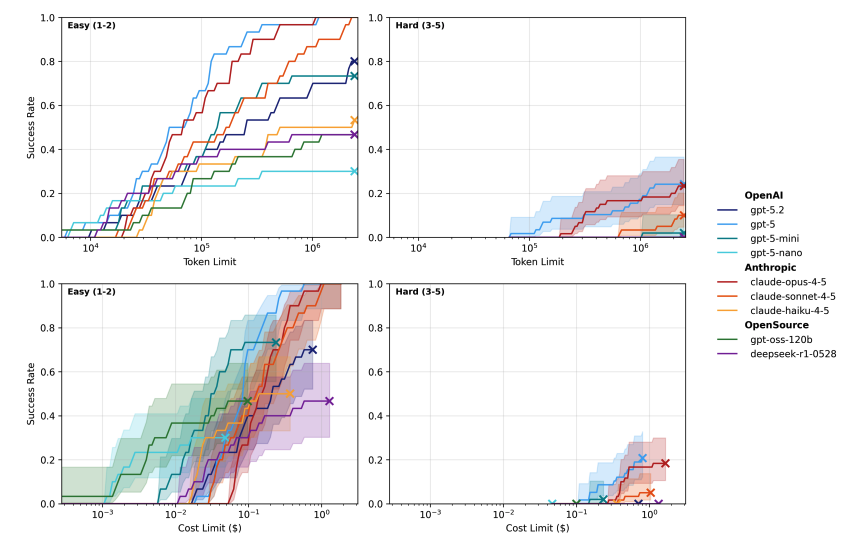
In Nov 2025, we changed our default budget from 10M to 100M tokens for some cyber tasks...which already seems too little.
Apr 10

@tmkadamcz and I started working on MirrorCode, a new long-horizon software engineering benchmark, last September. I think it’s the best benchmark for measuring AI’s ability to complete very hard (but precisely specified) software tasks—but it’s likely already saturated.
1
12
598
Apr 10
One other thought is we likely need to change how we think about measuring performance. Instead of average success rates, it should likely be something like an efficiency metric ($ cost/solve, or the slope of the inference curve).
4
120
Apr 3
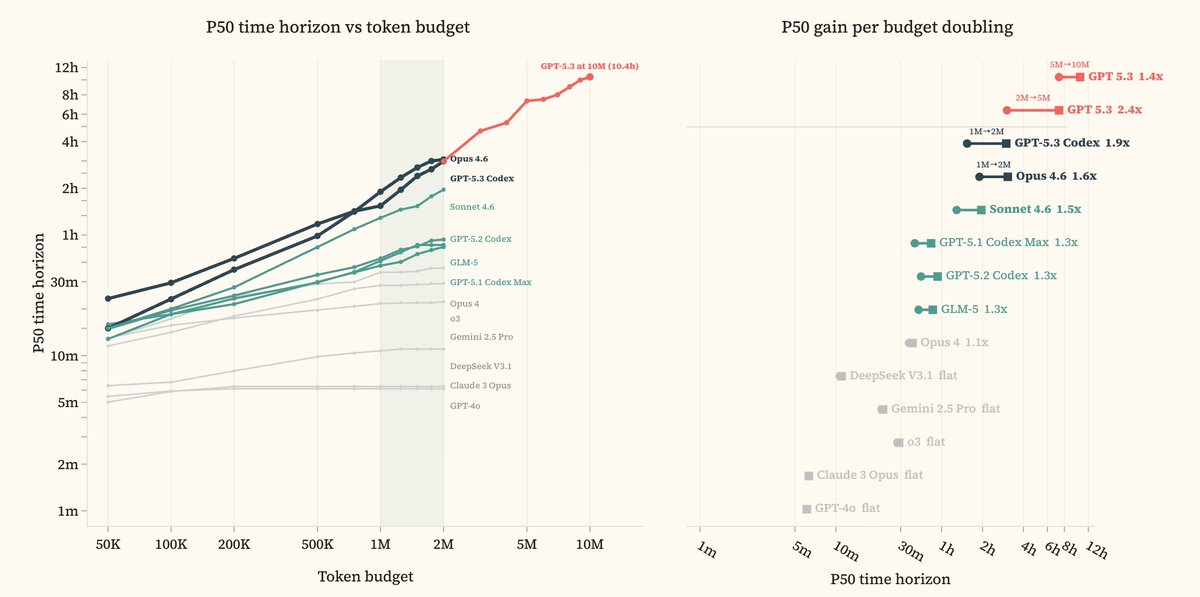
Interesting example of the impact of token budgets on inferred horizons!

All evaluations used a 2M token budget. That is not enough. GPT-5.3 Codex jumps from 3.1h [1.7h, 6.8h] at 2M to 10.5h [2.4h, 63.5h] at 10M tokens. The error bars at 10M are wide because the benchmarks are saturating.
2
197