
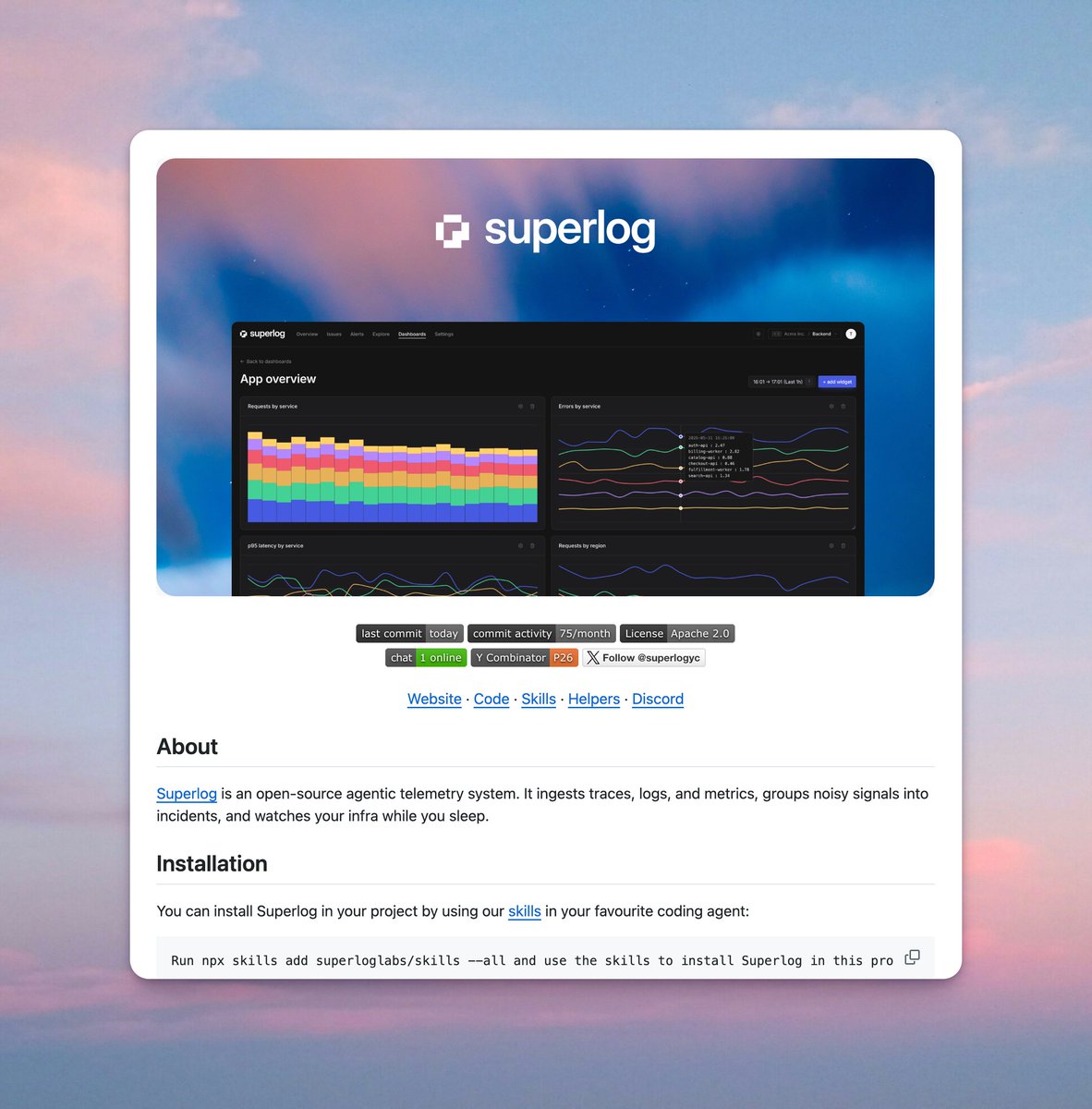
Observability that installs itself and fixes the bugs it finds.
Joined April 2026
- Tweets 31
- Following 2
- Followers 449
- Likes 149
Photos and videos
Superlog (YC P26) retweeted

Today we're open sourcing github.com/superloglabs/supe….
A big part of what we're doing (skills, SDKs) is already open-source.
We build for developers. We want to share our work with the developer community and make it a common journey.
Join us!
43
50
1,052
77,829
Superlog (YC P26) retweeted
superlog.sh needs your help today.
we just launched on ProductHunt. all the dedication, all the sleepless nights. that's what's at stake today.
we need your help to make Superlog product of the day.
please upvote and leave your comments:
producthunt.com/products/sup…
we count on you!
thank you.
19
4
48
8,324
Superlog (YC P26) retweeted

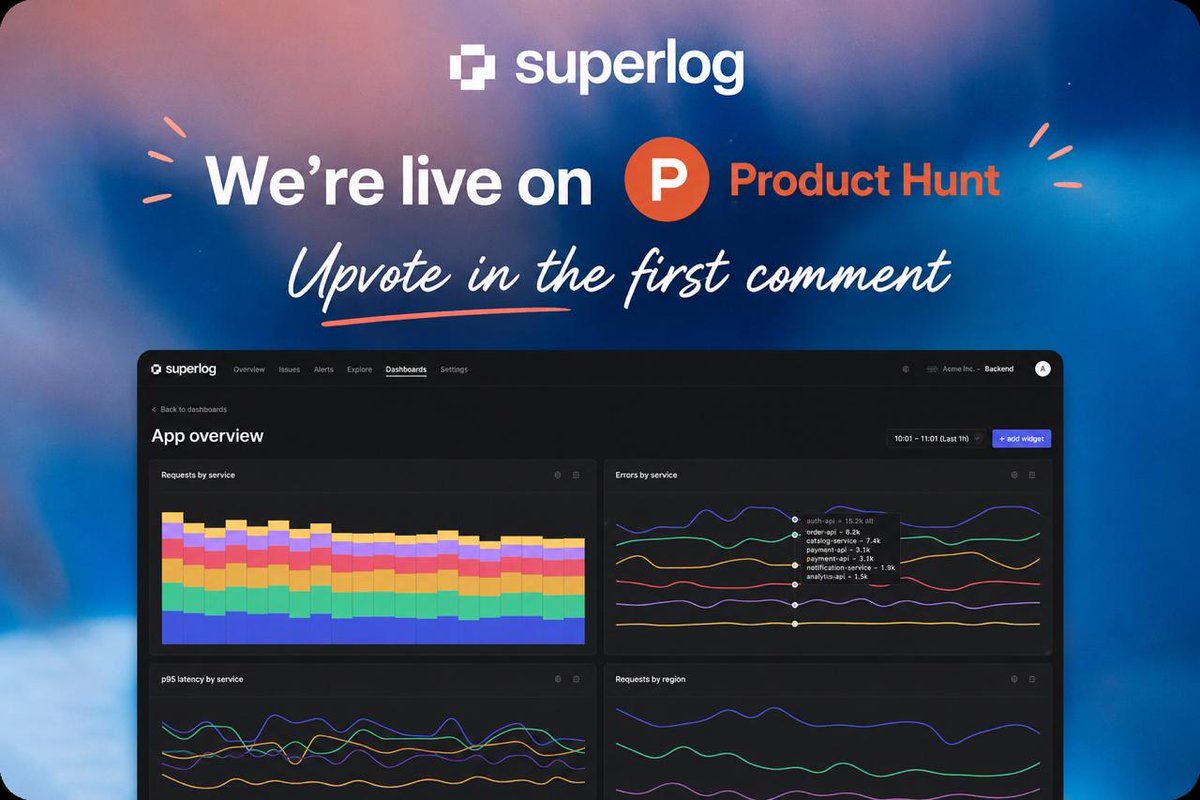
We are live on Product Hunt with @superlogYC, and we need your vote!
This launch was never meant to stop at a single milestone.
After topping #Bookface and reaching the front page of #HackerNews, we decided to go all in and launch Superlog on Product Hunt, hunted by @garrytan, president of @ycombinator.
We only have 12 hours, and every single upvote makes a difference.
So once again, we need your support.
Link in the first comment:
👉 Upvote/Comment Superlog (YC P26) on Product Hunt
🔁 Share it with your network
Observability that fixes itself. Let's make it #1. 🪵
10
2
34
1,941
Superlog (YC P26) retweeted
Still getting paged at 3am?
We collected the best practices for fixing your on-call and improving observability in your startup:
x.com/arseniycodes/status/20…


5
2
14
689
Superlog (YC P26) retweeted
2
2
13
1,081
Superlog (YC P26) retweeted
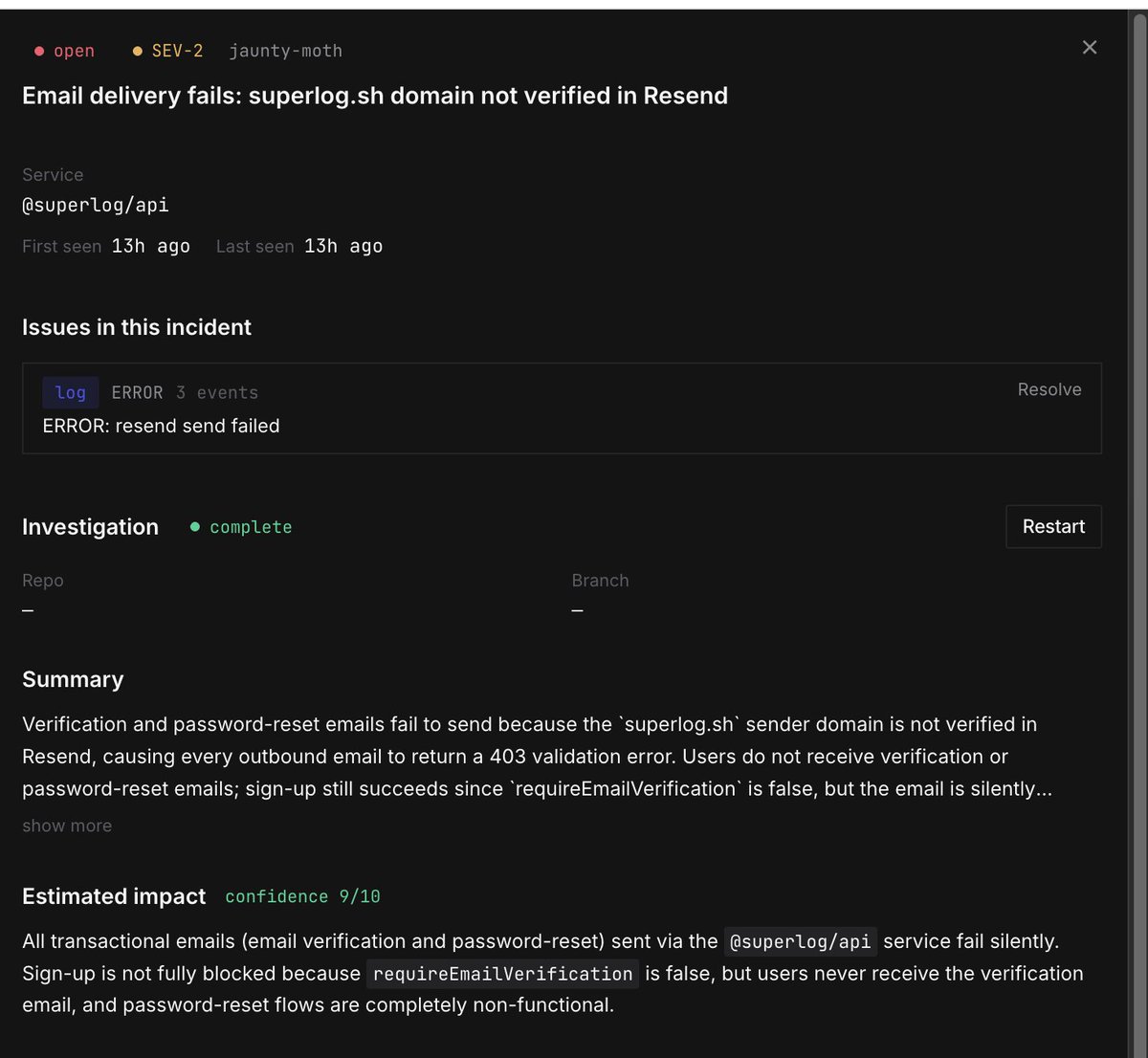
my product saved my butt today
I've been migrating from @clerk to @better_auth yesterday night. I chose @resend for verification emails but forgot to verify the domain.
I immediately got tagged by superlog.sh and could fix the issue
2
14
646

May 15
RT @nicolomagnante: 2 days ago we made it to the Bookface cover. today we just crossed 100 teams that installed @superlogYC. LFG 🔥 https://…
1
Superlog (YC P26) retweeted
just dropped a fully keyboard-based metrics explorer to superlog.sh.
i've spent so much time slicing and dicing metrics that I just wanted something that would feel as smooth as Raycast.
for the stressful 4am pages (that you won't have if you're on Superlog)
6
2
25
1,638
Superlog (YC P26) retweeted
there's no better feeling in the world than to see something you've built being useful for somebody.
just watched a new signup from our launch today use superlog.sh for 2 hours.
he's using our tools in more creative and efficient ways I could have imagined.
5
1
19
697
Superlog (YC P26) retweeted
today Nico and I are watching superlog.sh.
best teams love to build and ship. but now they're drowning in bugs and alerts.
our mission is to help them get rid of toil, and go back to doing what they love: making things people want.
May 12

Superlog (@superlogYC) is the observability tool you're not supposed to open: a wizard sets up your logs, traces, alerts, and dashboards daily, and an agent investigates incidents and posts one mergeable PR per issue into Slack.
Sign up here: superlog.sh/
Congrats on the launch, @nicolomagnante and @arseniycodes!
ycombinator.com/launches/QKt…
1
1
15
1,074
Superlog (YC P26) retweeted
making the world bug-free
May 12
Superlog (@superlogYC) is the observability tool you're not supposed to open: a wizard sets up your logs, traces, alerts, and dashboards daily, and an agent investigates incidents and posts one mergeable PR per issue into Slack.
Sign up here: superlog.sh/
Congrats on the launch, @nicolomagnante and @arseniycodes!
ycombinator.com/launches/QKt…
8
1
39
5,156
Superlog (YC P26) retweeted
proud of the new dashboards we just shipped to superlog.sh
14
4
224
21,432
Superlog (YC P26) retweeted
we're in the middle of @ycombinator.
we had revenue.
and we decided to pivot.
here's why:
in our previous startup, working w/ huge enterprises and high volumes, keeping critical services stable and online 24/7 was by far our top priority. luckily @arseniycodes spent years inside Datadog, building exactly the kind of observability infrastructure most teams pay millions for.
so when we got to the batch, we kept getting the same question from other founders:
"how did you set up observability and auto-debugging internally? can we use it?"
every startup is living the same broken loop:
- Sentry/Datadog/Grafana fires a thousand alerts, half are duplicates
- until something serious breaks
- panic, logging was not done properly
- someone copy-pastes a stack trace into Claude at 11pm
- finally, the bug gets fixed
- until the next one
we think this is not the way things should be done in 2026, so we pivoted. today we're building @superlogYC
a wizard installs OpenTelemetry across your repo in one click, then runs every single day to add the logs, alerts, and dashboards your team forgot.
when something breaks, an agent groups the noise into one incident, investigates with full context (logs, traces, metrics, recent deploys), and either ships a clean PR or pulls in the engineers who can solve it.
one mergeable PR per incident. posted in Slack. merge it, ignore it, or open it in Claude Code and tweak.
if your team is drowning in alerts, paying too much for telemetry that never actually solves anything, or running integrations that quietly break in the background, sign up in the first comment and let the agent do the work.

29
7
178
19,216
Superlog (YC P26) retweeted
me: we need a fix for the demo in 15 min, but we gotta hop in the waymo rn
🤨
@arseniycodes : / 💻 \
/\
1
1
13
1,055