
Web3 & AI Scientist, Vice Dean at @COTRUGLI & Co/founder; The Curator | @luminawidget | @BlockLabsLux | @4thtechProject | @immu3_io | @PollinationX_io
Joined March 2009
- Tweets 827
- Following 734
- Followers 1,660
- Likes 705
210 Photos and videos














Pinned Tweet

19 Aug 2025
New Article from the From Lab to Life collection: Are We Becoming Obsolete, or Finally Free?
"After 30 years in tech and research, I've reached a profound conclusion about our AI future.
'The future belongs to those who can effectively collaborate with artificial intelligence, not those who fear or ignore it.'
But here's what most people miss: this isn't about becoming obsolete. It's about becoming more human.
In my latest article from the 'From Lab to Life' collection, I break down complex AI developments into language everyone can understand. Because the future of AI shouldn't be decided by tech experts alone - it affects all of us.
The transformation ahead offers an unexpected gift: the possibility of returning to what makes us most human. Meaningful conversations, empathy, community support - what I call the 'human touch' - this remains irreplaceable.
AI may process information faster than any human, but it cannot offer the warmth of genuine human connection or the deep satisfaction that comes from meaningful relationships.
I believe we're heading toward a world where humans become curators of experience, facilitators of connection, and guardians of meaning in an increasingly automated world.
This is part of my #FromLabToLife series - simplifying complex technology so everyone can understand what's coming and how to prepare.
Are we becoming obsolete or finally free? Read my full article: medium.com/@talirezun/are-we…
#AI #FromLabToLife #FutureOfHumanity #Technology #HumanPotential"
3
14
993
The timing here is not accidental.
Fable 5 disappears for every non-American on June 12 at 5:21pm.
GLM-5.2 drops on June 13 — MIT license, 1M context window, coding-first, compatible with @claudeai Code and @cline out of the box.
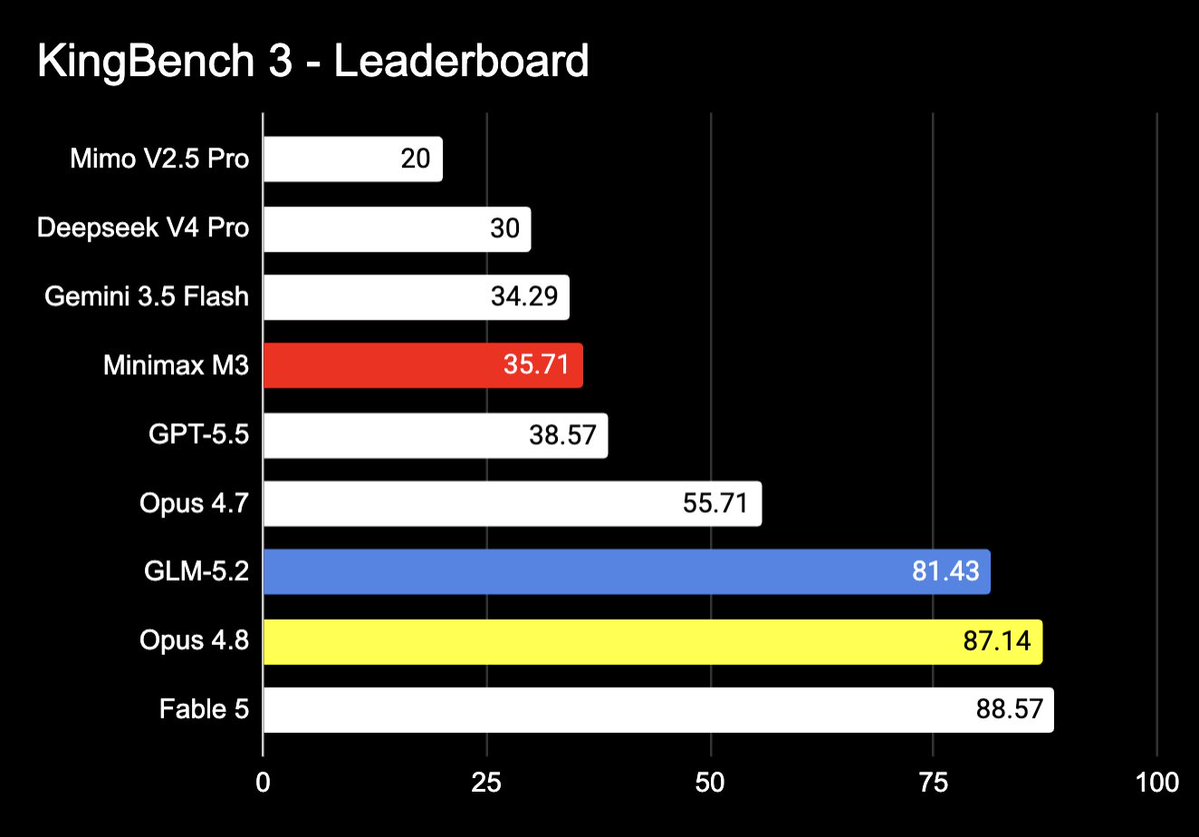
The market is correcting in real time. Haven't tested it yet — open weights arrive next week. But 81.43 on KingBench vs Fable's 88.57 with an MIT license and 1M context is exactly the signal I was looking for.
Permissionless intelligence. No government directive reaches this one.
Jun 13

GLM-5.2 on KingBench (3).
Thoughts: The model has superb taste. It is greater at UX than UI. The code is always very clean. It is great at One-shot wonders. I asked it to fine-tune a whole local model and it did it in 30mins!
This is just a great model to use all-round.
1/n
156
A budget panel of 3 open-weight models just scored within 1% of Fable 5 on 100 deep research tasks.
At half the cost.
Gemini 3 Flash Kimi K2.6 DeepSeek V4 Pro → 64.7%
Fable 5 solo → 65.3%
The premium panel beat both: 69.0%.
@OpenRouter calls it "neurodiversity."
I call it: the architecture I've been running manually in production, now in one API call.
59
Jun 13
Woke up to this.
177 tasks in production. Three active projects. All built on Fable.
One government directive at 5:21pm Friday. Gone.
No appeal. No transition. No explanation beyond "national security."
This is not a safety story. It's a sovereignty story.
Local models just became mandatory, not optional.
1
3
6
96
Jun 13
Jun 13

The US government, citing national security authorities, has issued an export control directive to suspend all access to Fable 5 and Mythos 5 by any foreign national, whether inside or outside the United States, including foreign national Anthropic employees.
The net effect of this order is that we must abruptly disable Fable 5 and Mythos 5 for all our customers to ensure compliance.
Access to all other Claude models is not affected.
We apologize for this disruption to our customers. We believe this is a misunderstanding and are working to restore access as soon as possible.
Read our full statement: anthropic.com/news/fable-myt…
3
37
Jun 11
𝗜 𝗮𝘀𝗸𝗲𝗱 𝗮 𝗙𝗮𝗯𝗹𝗲 𝘁𝗼 𝗮𝘂𝗱𝗶𝘁 𝗺𝘆 𝘀𝗲𝗰𝗼𝗻𝗱 𝗯𝗿𝗮𝗶𝗻. 𝗜𝘁 𝗳𝗼𝘂𝗻𝗱 𝘁𝗵𝗲 𝗰𝗼𝗻𝗰𝗲𝗽𝘁 𝗺𝘆 𝗲𝗻𝘁𝗶𝗿𝗲 𝗯𝗼𝗱𝘆 𝗼𝗳 𝘄𝗼𝗿𝗸 𝗶𝘀 𝗯𝘂𝗶𝗹𝘁 𝗼𝗻 — 𝗺𝗶𝘀𝘀𝗶𝗻𝗴.
Yesterday I ran an experiment in a single Claude conversation: Claude Fable 5, connected through #MyCuratorMCP to the second brain I have built with #TheCurator over the past year.
👉 𝗧𝗵𝗲 𝘀𝗲𝘁𝘂𝗽
3,305 wiki pages. 15,095 links. 68 ingested sources. All plain markdown, all on my own machine. The prompt: traverse the graph and find the recurring intellectual tension I have never explicitly named.
👉 𝗧𝗵𝗲 𝗱𝗶𝘀𝗰𝗼𝘃𝗲𝗿𝘆
"Knowledge sovereignty" — the phrase I use as the unifying thread of everything I do — did not exist as a node in my own knowledge graph. It was fragmented across four weakly connected pages. The philosophical core of The Curator itself sat in the graph as a near-orphan with one backlink. And my AI/knowledge-management cluster and my Web3/on-chain communication cluster — both halves of the same sovereignty story — had never been linked. Strangers in my own brain.
👉 𝗧𝗵𝗲 𝗱𝗶𝗮𝗴𝗻𝗼𝘀𝗶𝘀
The framing lived in my conversations and lectures — never in an ingested source. The exact gap Karpathy calls the interaction vector of knowledge compounding.
👉 𝗧𝗵𝗲 𝗰𝗹𝗼𝘀𝘂𝗿𝗲
The model then wrote the missing concept page — 62 wikilinks, every one verified against the existing index, zero broken — and compiled the audit session itself back into the wiki. My second brain ended the conversation measurably smarter than it began: 3,305 → 3,307 nodes, and the two clusters are now bridged.
👉 𝗪𝗵𝘆 𝗶𝘁 𝗺𝗮𝘁𝘁𝗲𝗿𝘀
Querying your knowledge is useful. An AI that compounds your knowledge — discovering structural gaps and closing them with grounded, link-verified pages — is a different category of tool. And everything stayed local: the frontier model came to the knowledge; the knowledge never left home.
#TheCurator is open source. Link to the repo in the comments 👇
#AI #SecondBrain #KnowledgeManagement #MCP #Claude #KnowledgeSovereignty
1
1
5
87
Jun 11
3
29
Jun 10
𝘖𝘯𝘤𝘦 𝘶𝘱𝘰𝘯 𝘢 𝘵𝘪𝘮𝘦, 𝘵𝘩𝘦𝘳𝘦 𝘸𝘢𝘴 𝘢 𝘮𝘰𝘥𝘦𝘭 𝘵𝘩𝘢𝘵 𝘦𝘹𝘪𝘴𝘵𝘦𝘥 𝘰𝘯𝘭𝘺 𝘪𝘯 𝘸𝘩𝘪𝘴𝘱𝘦𝘳𝘴.
Yesterday, @AnthropicAI released Claude Fable 5 — the first publicly available Mythos-class model. A new tier above Opus. A new chapter in the story.
Fable, from the Latin fabula — "that which is told," the same root as Mythos. The naming is deliberate. This is not a point release. It is a lineage shift.
𝗪𝗵𝗮𝘁 𝗷𝘂𝘀𝘁 𝗰𝗵𝗮𝗻𝗴𝗲𝗱:
→ A new model tier above Opus exists. Haiku → Sonnet → Opus → Fable / Mythos. Fable 5 is the public model; Mythos 5 stays restricted under Project Glasswing.
→ SWE-Bench Pro: 80.3% vs GPT-5.5 at 58.6%. Andrej Karpathy called it "a major-version-bump-deserving step change" for long, difficult problems.
→ Vision and PDF parsing are now category-leading. An AI-first law firm said it "feels materially different" in blind contract reviews — precisely the territory I covered in my article on legal AI democratisation.
→ During early access testing, Stripe claimed to have migrated 50 million lines of Ruby code in a single day.
𝗧𝗵𝗲 𝗵𝗼𝗻𝗲𝘀𝘁 𝗽𝗮𝗿𝘁 — 𝘁𝗵𝗶𝘀 𝗰𝗼𝘀𝘁𝘀:
→ API: $10 / $50 per million input/output tokens — 2× Opus 4.8, the most expensive widely available model on the market.
→ On subscription plans, it counts as double usage.
→ But the nuance matters: complex tasks often complete in fewer turns. One physics research task finished in 36 hours using a third of the tokens GPT-5.5 needed over four days.
𝗪𝗵𝗲𝗿𝗲 𝗶𝘁 𝗲𝗮𝗿𝗻𝘀 𝗶𝘁𝘀 𝗽𝗹𝗮𝗰𝗲:
→ Long-horizon autonomous coding — deep codebase orchestration across agent fleets
→ Legal and financial document analysis — dense PDFs, cross-document reasoning
→ Complex research and analytics — vision-driven workflows, scientific data extraction
This is not a daily driver. It is a scalpel reserved for the hardest problems.
Available on Claude API, Claude Code, AWS Bedrock, Vertex AI, and Microsoft Foundry. Free on Pro / Max / Team plans through June 22. Usage credits required after that.
PS: Field notes from real builds, not vendor marketing.
#FromLabToLife #AI #ClaudeFable5 #Mytho #LegalAI #AgentOrchestration #ContextEngineering
1
3
215
Jun 9
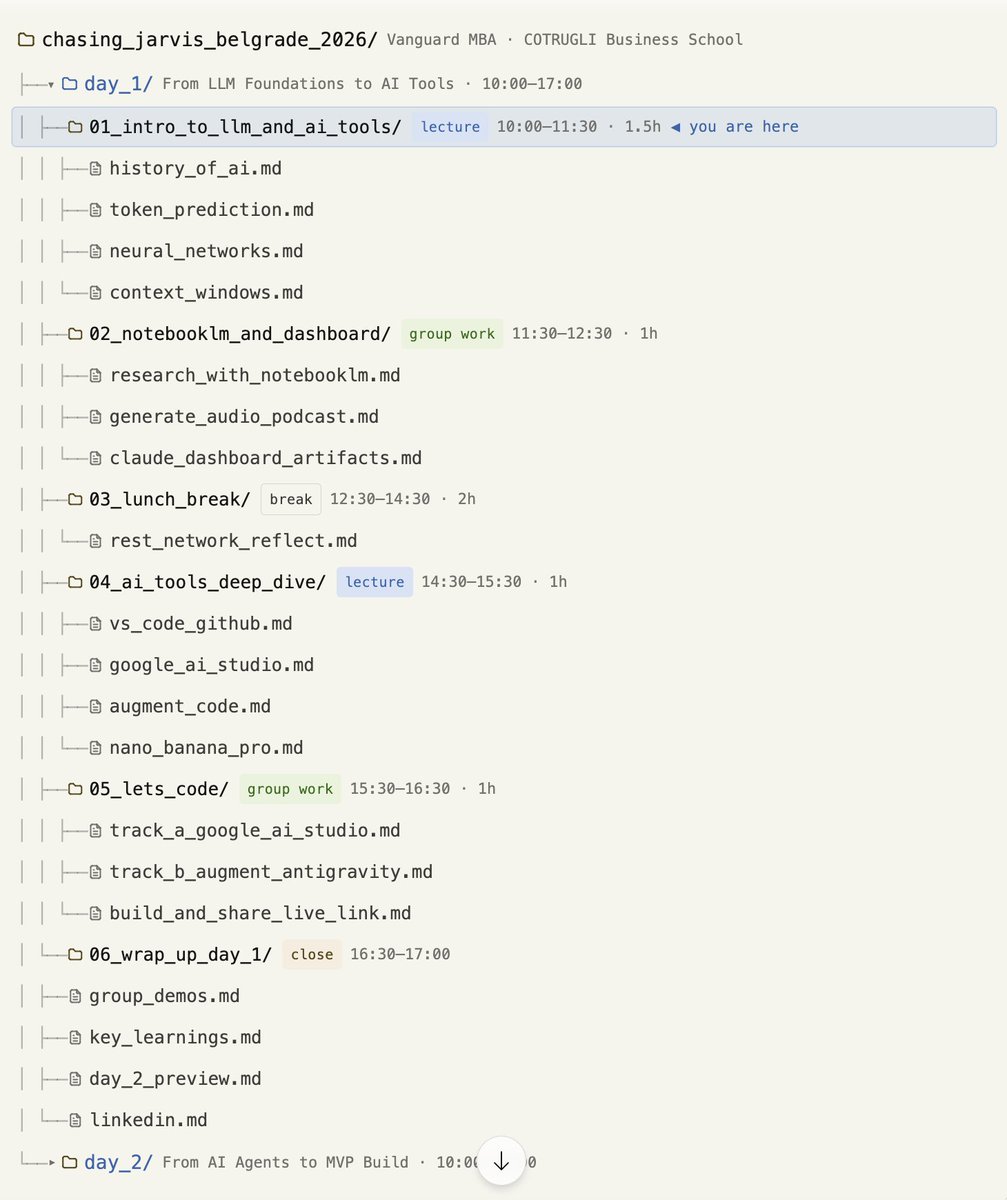
Two years of building with AI coding agents. Six months of @COTRUGLI #ChasingJarvis workshop feedback. One methodology, now documented in depth.
The article is published today.
Three phases. One thread running through all of them.
→ Phase 1: Research, Design & Foundations
Output: four markdown files — architecture, blueprint, UI/UX, security. Allow 3–7 days. This phase cannot be rushed. Phase 2 chaos is almost always a Phase 1 failure — not of effort, but of clarity.
→ Phase 2: The Build Phase
Context engineering goes active. Watch the context window — act at 80%. Three layers of agent memory: markdown file libraries, RAG, and The Curator. Handoff files bridge what the model cannot remember between sessions.
→ Phase 3: Debug, Audit & Deploy
Built ≠ finished. Manual testing first. Playwright MCP for automated coverage. Three-model security audit — Claude Opus, GPT-4o, Gemini Pro. Each model catches what the others miss.
This process is tool-agnostic. @claudeai Code, @augmentcode, Codex, @opencode — the three phases apply across all of them.
What it is not agnostic to is the discipline you bring to it.
Full article links in the comments below.
From Lab to Life | Article Collection
#FromLabToLife #AI #ContextEngineering #CodingAgents #ChasingJarvis #AugmentCode #AIAgents
3
3
94
Jun 9
Read the full article here:
→ Medium: medium.com/@talirezun/contex…
→ Substack: open.substack.com/pub/talire…
If you're building alongside the Chasing Jarvis programme — this is the methodology behind every session we run together.
2
29
Jun 8
𝗞𝗻𝗼𝘄𝗹𝗲𝗱𝗴𝗲 𝗰𝗼𝗺𝗽𝗼𝘂𝗻𝗱𝘀. 𝗝𝘂𝘀𝘁 𝗹𝗶𝗸𝗲 𝗲𝘅𝗽𝗲𝗿𝗶𝗲𝗻𝗰𝗲.
Checking in from the Adriatic. 🌊
Twenty-five years of annual sailing with my friends. Same sea, same tradition — a different version of myself each time. And without fail, this is where my best thinking happens.
This year, somewhere between the horizon and the silence, I kept returning to one question:
𝗛𝗼𝘄 𝗺𝘂𝗰𝗵 𝗿𝗮𝗿𝗲 𝗲𝘅𝗽𝗲𝗿𝗶𝗲𝗻𝗰𝗲 𝗱𝗼 𝘄𝗲 𝘀𝗶𝗺𝗽𝗹𝘆 𝗹𝗼𝘀𝗲?
We learn from doing. From failing forward. From years of decisions, pivots, patterns, and hard-won judgment. But most of that knowledge evaporates — into the noise of the next project, the next quarter, the next year.
It doesn't have to.
𝗪𝗶𝘁𝗵 𝗮 𝗹𝗶𝘁𝘁𝗹𝗲 𝗱𝗶𝘀𝗰𝗶𝗽𝗹𝗶𝗻𝗲, 𝗲𝘅𝗽𝗲𝗿𝗶𝗲𝗻𝗰𝗲 𝗯𝗲𝗰𝗼𝗺𝗲𝘀 𝗮 𝗰𝗼𝗺𝗽𝗼𝘂𝗻𝗱𝗶𝗻𝗴 𝗮𝘀𝘀𝗲𝘁.
Record it. Structure it. Connect it. That is the idea behind a personal second brain — a living knowledge base that grows smarter with every insight you add.
Now scale that to a company. A 𝗦𝗵𝗮𝗿𝗲𝗱 𝗕𝗿𝗮𝗶𝗻 — where teams contribute their domain expertise into a collective wiki that doesn't walk out the door when people retire or move on. Institutional memory, preserved and queryable.
This is what I've been building with 𝗧𝗵𝗲 𝗖𝘂𝗿𝗮𝘁𝗼𝗿. And reflecting on how far we've come — from a personal tool to a growing open-source community — is genuinely humbling.
The direction ahead is clear. The potential is still largely unrealised.
Grateful for 25 years of this tradition. Grateful for the open water that always brings clarity.
→ Link to The Curator Open Source GitHub in the comments.
#SecondBrain #KnowledgeManagement #AI #SharedBrain #TheCurator #Innovation
1
5
66
Jun 8
3
27
Jun 6
My New Article is Live "Context is the Code: The Complete Three-Phase Process for Building with AI Agents"
"So context engineering is Phase One. What happens to it in Phases Two and Three?"
A student in my Chasing Jarvis MBA workshop asked that.
Context engineering is not a phase. It is the practice that runs through all three. I had described it as a starting condition. It is a continuous discipline.
The three phases, clarified:
→ Phase 1: Research, Design & Foundations
Output: foundational markdown files (architecture.md, blueprint.md, ui_ux.md, security.md). Allow 3–7 days. This phase determines everything that follows. Phase 2 chaos is almost always a Phase 1 failure — not of effort, but of clarity.
→ Phase 2: The Build Phase
Context engineering goes active. Watch the context window — act at 80%, beyond which hallucinations increase. Maintain CLAUDE.md after every milestone. When the session approaches its limit: write a handoff file. It bridges what the model cannot remember itself.
→ Phase 3: Debug, Audit & Deploy
Built ≠ finished. Manual testing first. Playwright MCP for automated coverage. Three-model security audit: Claude Opus GPT Gemini Pro. Each model has different blind spots. Run at least two.
The article also introduces three layers of agent memory:
→ Layer 1 — Markdown files (CLAUDE.md / AGENT.md): active sprint context. Start here on every project.
→ Layer 2 — RAG: for large document corpora only. Do not use because it sounds sophisticated.
→ Layer 3 — The Curator: long-term, compounding knowledge via wiki graph and MCP.
Not alternatives. A stack.
This methodology is tool-agnostic. The three phases work equally across Claude Code, Augment Code, Codex Open Code, and others.
What it is not agnostic to is the discipline you bring to it.
Full article — links in the comments: 👇
→ Medium
→ Substack
#FromLabToLife #AI #ContextEngineering #CodingAgents #ChasingJarvis #AIAgents #AugmentCode
2
1
4
145
Jun 6
Context is the Code: The Complete Three-Phase Process for Building with AI Agents:
🔗 medium.com/@talirezun/contex…
🔗open.substack.com/pub/talire…
3
26
Jun 4
🧠 The Curator — latest update v3.0.1-beta.18 is live
#TheCurator turns your documents and conversations into an interconnected knowledge wiki — compiled knowledge that compounds with every source, not retrieval-on-demand. The files stay plain Markdown, readable in Obsidian as a living graph.
This release came almost entirely from open-source community feedback. The headline:
🔧 The Health section is now an AI-powered maintenance system.
As a knowledge base grows past a few thousand pages, it accumulates broken links, orphan pages (nothing links to them), and duplicate concepts. Fixing those one by one is impossible at scale. Now the AI does the per-item judgement and you approve the fixes in batches — with a preview every time:
• Fix broken links — the AI re-points links to the right page, or cleans up the ones pointing nowhere (on one real wiki: 1,000 → 0).
• Rescue orphans — it finds the best existing page to connect each isolated note to.
• Merge duplicates — clears near-identical pages in one reviewed pass.
(Plain-English version: a "clean up my wiki" button that's smart enough to ask before it touches anything — and everything's revertable.)
🛠 Plus reliability fixes from the community:
• Large documents no longer fail to import (and silently lose their content).
• Edits stop overwriting existing prose.
• Works across both Google Gemini and Anthropic Claude.
This matters most for Shared Brains — collective wikis for teams and organisations — where maintenance has to scale.
Every change is Git-tracked and validated against live data on both AI providers before shipping.
Huge thanks to the contributors who reported these. 🙏
🔗 The Curator open-source repo link in the comments (mac installer available)👇
#KnowledgeManagement #AI #SecondBrain #OpenSource #Obsidian
1
4
33
Jun 4
2
11
Jun 4
𝗧𝗢𝗞𝗘𝗡𝗦...𝘁𝗵𝗲 𝗻𝗲𝘄 𝗰𝘂𝗿𝗿𝗲𝗻𝗰𝘆 𝗼𝗳 𝗶𝗻𝘁𝗲𝗹𝗹𝗶𝗴𝗲𝗻𝗰𝗲.
And the exchange rate just quietly changed on all of us.
There's growing noise about frontier models becoming more expensive. From my direct observation: it's true. But the story behind it matters more than the headline.
For two-plus years, companies like OpenAI and Anthropic have been subsidising your access to intelligence. A $20/month subscription delivered dramatically more compute value than the equivalent API bill would cost. I've seen both sides firsthand — the gap was significant, and it was intentional. Early adoption needed a price entry point that made sense for individuals and businesses.
That honeymoon period is ending.
Subscriptions are tightening. Usage limits are appearing. Rate caps are becoming real friction. And the reason isn't corporate greed — it's physics.
→ Compute costs money
→ Energy is not abundant
→ Data centres are not infinite
→ Running a 200K token context window at scale is extraordinarily expensive
Something had to give.
𝗦𝗼 𝘄𝗵𝗮𝘁 𝗱𝗼𝗲𝘀 𝘁𝗵𝗶𝘀 𝗺𝗲𝗮𝗻 𝗳𝗼𝗿 𝗽𝗿𝗮𝗰𝘁𝗶𝘁𝗶𝗼𝗻𝗲𝗿𝘀?
It means mastering context engineering — giving an LLM exactly what it needs, not more, not less — is no longer just best practice. It's economic discipline.
Here's what 2 years of building with coding agents has refined in my own workflow:
→ Every project begins with structured markdown files: architecture, blueprint, UI/UX, security notes. Complete. Precise. Permanent.
→ When a coding task runs, I don't throw the entire project's docs at the agent. I reference only the documents relevant to that specific task.
→ The result: dramatically lower token consumption, faster responses, measurably better output quality.
The foundational documentation isn't overhead. It's your token budget strategy.
The practitioners who thrive in the expensive-tokens era will be those who treat context as a resource to be engineered, not a convenience to be dumped.
Less context is not the answer. Precisely targeted context is.
Tokens are the new currency of intelligence. Spend them like it.
What's your approach to managing context costs in production workflows?
#AI #ContextEngineering #FromLabToLife #LLM #AIStrategy #TokenEfficiency #FrontierAI
3
30
Jun 3
Pope Leo XIV published Magnifica Humanitas on May 15 — an encyclical on AI and human dignity addressed to the entire human family. Not a policy paper. Not a corporate framework. 200 paragraphs across five chapters.
I read it cover to cover. And I keep coming back to one question it asks:
"Does AI make human life on earth more human in every aspect? Does it make it more worthy of man?"
I don't think we answer that question enough in our field.
What it actually says:
This isn't a rejection of technology. It's a demand for honest accounting.
→ Data is a common good. Algorithms, platforms, and digital infrastructure are explicitly classified alongside traditional goods — private ownership is not absolute. A 135-year-old principle extended into the digital age.
→ Lethal autonomous weapons can't be delegated to machines. "It is not permissible to entrust lethal or irreversible decisions to artificial systems." The question of who bears responsibility when a machine kills remains largely unanswered.
→ The "just war" framework is challenged as outdated. Dialogue, diplomacy and forgiveness are named as humanity's better tools now.
→ The attention economy is named as a form of dependency — not a side effect, but a deliberate feature.
→ Data colonialism is condemned. Health and demographic data extracted from vulnerable populations as a new form of domination.
→ Invisible AI labor is given moral standing. Data labelers, content moderators, rare-earth miners — the human chain that makes "seamless" AI possible.
Which of these surprised you most?
Why this matters beyond religion:
→ This is the first time an institution with 1.4 billion members has issued a detailed governance framework for AI — covering labor, weapons, data ownership, child safety, environmental cost, and epistemic manipulation in a single document.
→ It doesn't just call for ethical AI. It tries to name the structures that produce unethical AI.
I find that distinction more honest than most of what I read in tech. But I'm curious whether you do too.
I've been documenting AI's real-world impact in my From Lab to Life series. If there's one thing practitioners keep discovering, it's this: intelligence is no longer the bottleneck. Power, access, and accountability are.
This encyclical says the same thing from a very different direction.
Full text link in the comments — five chapters, worth the time.
#AI #FromLabToLife #DigitalEthics #Leadership #Technology
1
2
3
33
Jun 3
Full text of Magnifica Humanitas (English, official Vatican publication):
vatican.va/content/leo-xiv/e…
Available in nine languages: Arabic, German, Spanish, French, Italian, Polish, Portuguese, Russian, and English.
Five chapters. Introduction and Conclusion. 200 numbered paragraphs covering: the history of Catholic Social Doctrine, the foundations of human dignity, the governance and ethics of AI, truth and democracy in the digital age, the transformation of work, new forms of digital slavery — and a direct prohibition on autonomous lethal weapons systems.
The most comprehensive institutional statement on AI and human dignity published to date. If you read one governance document on AI this year, this is it.
2
23
Jun 2
𝟵𝟱% 𝗼𝗳 𝗲𝗻𝘁𝗲𝗿𝗽𝗿𝗶𝘀𝗲 𝗔𝗜 𝗽𝗶𝗹𝗼𝘁𝘀 𝗽𝗿𝗼𝗱𝘂𝗰𝗲 𝗻𝗼 𝗺𝗲𝗮𝘀𝘂𝗿𝗮𝗯𝗹𝗲 𝗯𝘂𝘀𝗶𝗻𝗲𝘀𝘀 𝗶𝗺𝗽𝗮𝗰𝘁.
⚠️ Not a technology problem. An organisation problem.
That's the MIT NANDA finding from August 2025 — and it's the founding premise of everything I've been building for the past three years.
Today I'm publishing Article-1 of the #ØØT Research Series: the complete overview of the Organisation of Tomorrow (ØØT) framework.
#ØØT is an open-source GitHub framework for partner-run, AI-augmented organisations.
👉 Not a consulting methodology.
👉 Not a SaaS platform.
👉 Not a framework you need a vendor to implement.
A complete operational stack — free to adopt, built on open standards, zero vendor lock-in.
The article "𝗕𝘂𝗶𝗹𝗱𝗶𝗻𝗴 𝘁𝗵𝗲 𝗢𝗿𝗴𝗮𝗻𝗶𝘇𝗮𝘁𝗶𝗼𝗻 𝗼𝗳 𝗧𝗼𝗺𝗼𝗿𝗿𝗼𝘄" covers everything a founder needs to understand before building or transforming:
→ The 5 theses behind #ØØT — grounded in MIT, McKinsey, Microsoft, HBS, and METR research
→ The Klarna Test — a mandatory blocking gate that prevents the failure mode Klarna made famous
→ Three generations: what's operational today, what ships in 6–12 months, and what's research-stage
→ Cloud track vs. privacy track — full operational parity, full data sovereignty, your choice
→ The Collecting Brain — why your firm's knowledge graph is its most valuable compounding asset
→ SKILL.md files — how to make AI methodology portable across every tool, forever
→ Three install paths — including a 60–90 min agent-assisted option for non-technical founders
→ Why this works beyond tech: any industry, any founder
This is my contribution from 30 years of building companies at the frontier of technology.
#ØØT is the first open-source organisational framework to address all four structural gaps simultaneously:
resistance management · output-based compensation · agentic knowledge infrastructure · data sovereignty
No comparable framework occupies all four corners.
If you're building from scratch or upgrading what you have — this is where to start.
🔗 All article links (GitHub · Medium · Substack) are in the comments below 👇
#OrganisationOfTomorrow #OpenSource #AI #FutureOfWork #AgenticAI #Entrepreneurship #AIStrategy #KnowledgeManagement #DigitalTransformation
1
2
6
134
Jun 2
📖 Article links — read, follow, and star:
🔵 GitHub (open-source, free):
github.com/talirezun/oot-fra…
✍️ Medium:
medium.com/@talirezun/buildi…
📬 Substack:
open.substack.com/pub/talire…
———
⭐ The framework is open source — if it brings value, smash that star on the GitHub repo → github.com/talirezun/oot-fra…
Every star helps other founders and researchers discover it.
👥 Follow me on Medium for more practitioner research, field notes, and framework updates.
📩 Subscribe on Substack to get every new article directly in your inbox — Article 2 is already in progress.
This is a living framework. Your feedback shapes what gets built next.
1
7
42