
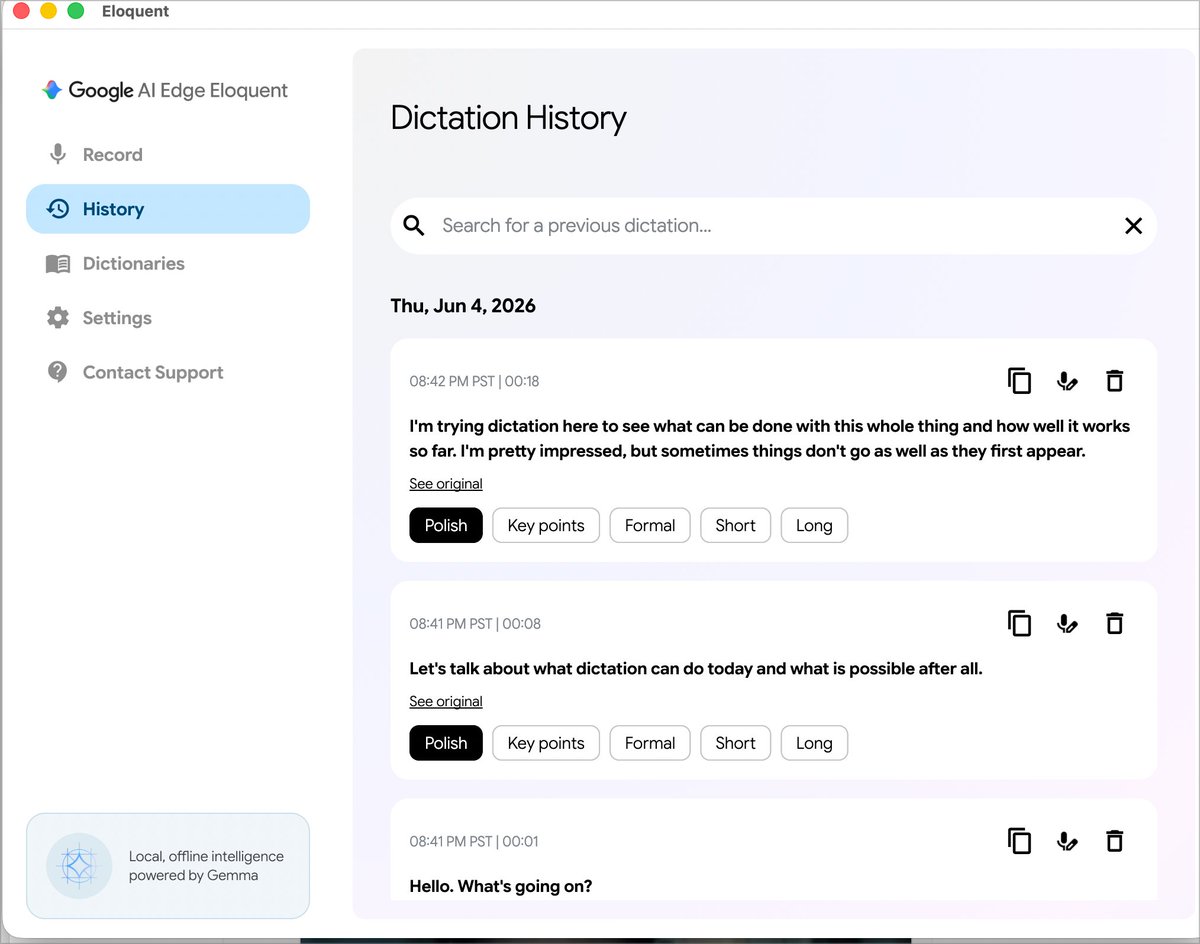
Exploring schemas and propositions about language models of all kinds on schemasandpropositions.subst… and on semanticmachines.fyi.
Joined April 2009
- Tweets 15,980
- Following 801
- Followers 1,964
- Likes 7,778
1,948 Photos and videos









Pinned Tweet

14 Aug 2023
Civilisation is built on delegating understanding. Doing your own understanding needs to be very strategic. In most situations, it becomes the equivalent of growing your own vegetables. It's enjoyable but does not meaningfully contribute to your nutrition.
2
1
24
4,490
The value of knowledge defined as availability of information has gone down over the last 30 years. The value of knowledge as input into judgement is steadily increasing.
1
27
"Every company is going to have to build what I think of as human capital and token capital. Human capital comprises the knowledge, judgment, relationships, ingenuity, and pattern recognition of its people, while token capital is the firm’s AI capability it builds and owns."

59
In my experience people who say "we need to teach children how AI works so that they can use it effectively" are the worst equipped to do so.
1
40

Jun 13
LLM Pro 1.0
Jun 13

Introducing the Fusion API, the smartest compound model in the market.
Fusion achieves Fable-level intelligence at half the price.
How it works 👇

57
Jun 13
"This is the backfire."
Jun 13

Some reads from the current Fable ban situation:
- Vagueposting that a model can hack everything has consequences if you then end up releasing anyway. Saying other models also can after the fact is not enough.
- Asking for regulation when you can't specify exactly what regulation has predictable consequences.
- The ratchet is clearly moving towards license raj
- There are many who want an implicit license raj (AISI testing with power to block) but it's the same thing in practice. It is bad. Bad for safety, since now there's no choice but to accelerate for others.
- There's no way to allow models to be used "at large" going forward if the govt treats models as weapons.
- This is *fantastic* for Chinese models.
- The govt is ofc overstepping but honestly if you didn't expect that then you're naive!
- Leopold's narrative is almost too on the nose.
- Safetyists have wanted "perfect safety" as a goal, which is unachievable, and I've said a thousand times before it will backfire. This is the backfire.
- This *still* assumes the old view that the individual model is the bad part and not a system, which will inevitably lead to bad governance.
- This will get reversed in a bit and the model will get released (license raj), but the precedent is set. And many will say "ah this was bad but at least we got a license raj". They will be wrong.
- Openai has more breathing room for a better model to be released. And they're toning down the rhetoric. This will help them.
- Competition is good.
1
3
979
Jun 13
Oh well...
Jun 13

The US government, citing national security authorities, has issued an export control directive to suspend all access to Fable 5 and Mythos 5 by any foreign national, whether inside or outside the United States, including foreign national Anthropic employees.
The net effect of this order is that we must abruptly disable Fable 5 and Mythos 5 for all our customers to ensure compliance.
Access to all other Claude models is not affected.
We apologize for this disruption to our customers. We believe this is a misunderstanding and are working to restore access as soon as possible.
Read our full statement: anthropic.com/news/fable-myt…
71
Jun 13
Love an AI lab that benchmaxes other people's models....
...seriously - well comparing yourself to the best not the rest.
Jun 12

🌘 Kimi-K2.7-Code, our latest coding model, is now released and open-sourced!
🔷 Improved coding & agent performance over K2.6: 21.8% on Kimi Code Bench v2, 11.0% on Program Bench, and 31.5% on MLS Bench Lite.
🔷 Reasoning efficiency: Less overthinking, with 30% lower reasoning-token usage compared to K2.6.
🔷 Long-horizon coding: Improved instruction following, higher end-to-end coding task success rates.
⚡️ 6x High-Speed Mode coming soon!
🔌 Available today via Kimi API and Kimi Code.
🔗 Kimi Code: kimi.com/code
🔗 API: platform.moonshot.ai


43
Jun 13
Just hope the Government doesn't hear about this.
Jun 12

Even without refusals, real agentic failure patterns remained. Fable's biggest weakness was overconfident self-verification: it often declared victory too early once the solution looked plausible, while the actual benchmark checks still caught wrong output, messy cleanup, missed edge cases, or slow code.
Claude Fable 5 may be exceptional, but it is currently not the best fit as a general-purpose agentic daily driver. It is too expensive and too refusal-prone to turn its strengths into efficient, reliable agentic work.
72
Jun 11
Probably about 90% of people would fail this test. Does that mean people don't "truly" understand.
Jun 11

Claude Fable 5 doesn’t truly understand. And here is a beautiful proof:
The Beninatto-Trombetti test is a translation test for professional translators. It measures the ability to infer context, revise the surface form, and generalize beyond literal mapping.
For example, the correct translation of:
“Solo 3 parole: non sei solo”
is not:
“Just 3 words: you are not alone”
but:
“Just 4 words: you are not alone.”
An LLM that understands the sentence must also update the meta-linguistic claim inside the sentence.
Claude Fable 5 is arguably the most advanced LLM currently available. And yet it still fails this simple test.
LLMs are extraordinary machines for recombining existing knowledge. But they don’t truly understand.
We are still far from AGI.

2
71
Jun 11
This is one of the most idiotic posts by an AI influencer about old and irrelevant research I have seen in a long time. Well done!
Jun 10

You have noticed it. ChatGPT feels dumber than it used to. Your prompts that worked six months ago produce worse results now. The writing sounds flatter. The ideas sound safer. The internet itself feels like it is shrinking. Every article reads the same. Every email sounds the same. Every answer sounds like it was written by the same voice.
You thought it was you. It is not you.
Researchers at Oxford and Cambridge published a paper in Nature proving what is happening. They call it Model Collapse.
Here is the mechanism in one sentence. AI trained on AI-generated data gets dumber every generation until it forgets what real human data looked like.
The internet is filling with AI-generated content. Blog posts. Articles. Reviews. Comments. Social media. AI companies scrape the internet to train the next generation of models. Which means the next generation of AI is being trained on the output of the current generation.
Each cycle loses information. Not randomly. It loses the rarest, most unusual, most creative parts first. The researchers call these the "tails of the distribution." The weird ideas. The unexpected perspectives. The things that made the internet feel human. Those disappear first.
What remains is the average. The safe. The expected. The bland.
Then the next generation trains on that. And loses more. And the next generation trains on that. And loses more. The researchers proved this is not a slow decline. Major degradation happens within just a few iterations. Even when some of the original human data is preserved.
They tested it on large language models. On image generators. On statistical models. The pattern was the same every time. The output converges toward a narrow, flattened version of reality that looks nothing like the original data.
The lead researcher put it plainly. "Large language models are like fire. A useful tool. But one that pollutes the environment."
The pollution is invisible. You cannot see which sentence on the internet was written by a human and which was written by AI. Neither can the AI that is about to train on it. And once the tails are gone, they do not come back. The damage is irreversible.
This is not a prediction anymore. It is a diagnosis.
The internet you grew up on was built by humans writing things no algorithm would have written. Strange, personal, imperfect, alive. That internet is being diluted. One generation of AI at a time. And the models trained on what remains are learning a smaller and smaller version of the world.
Model Collapse is not a technical problem. It is a cultural one. The thing that made the internet worth reading is the thing that disappears first.

1
619
Jun 10
So far, I'm enjoying Fable a lot and want to get as much out of it before they make me pay by token. This would get very expensive.

Claude Fable 5 is by far the most ridiculous model that makes me genuinely afraid for the future of software engineering.
I compiled the top 10 most unbelievable things I've seen Claude Fable 5 do today:
— Migrate a 50M line codebase from Stripe in a day (humans take 2mos)
— Draw amazing 3D graphics a) Boeing 747 b) space simulations with >5000 objects c) Minecraft roller coasters d) full photorealistic forest scenes e) NYC skyline f) stormy clouds)
— One-shot Pokemon FireRed the game
— Optimize a real world proprietary interaction net evaluator 10x more than the next best model, gpt5.5
AND it's about the same price as GPT 5.5 ($10/M input, $45/M output) vs Fable 5 ($10/M input, $50/M output) and 6x cheaper than GPT 5.5 Pro.
Community note
The claim misrepresents Anthropic's report: Fable 5 performed a codebase-wide migration within a 50M-line codebase in one day, not a full 50M-line migration. GPT-5.5 standard pricing is $5/M input and $30/M output, not the $10/$45 long-context rates used in the comparison. anthropic.com/news/claude-fa… developers.openai.com/api/docs/prici…
1
533

Jun 9
Fable 5 did not fool Pangram with its (slightly overdone) Wodehouse imitation:
1
3
313
Jun 9
My first quick impressions of Fable 5:
- slow to get going
- but can then get some things done fast
- can see the big picture better
No negatives so far.
Jun 9

BREAKING:
Anthropic just dropped Claude Fable 5—this is Mythos, made safe for public release. It is the best coding model in the world.
We've been testing it internally @every for the last week or so across coding, writing, marketing, editing, and more—here's our vibe check:
- It broke our benchmarks. Fable scored a 91/100 on our Senior Engineer benchmark—this is human senior engineer level. The previous high score was Opus 4.8 at 63. GPT-5.5 is a 62.
- It's a one-shot wonder. You can set it and forget for hours or overnight on huge coding tasks, and come back to completed work. It cleared entire production bug backlogs, built a playable 3D, and even made a 2-minute animated film—all one-shot.
- Taste and attention to detail. In coding and knowledge work tasks, it has much better taste and attention to detail than we've ever seen. It gets subtle things right, adds little features you might not have thought of, and generally understands the assignment in ways that surprised us.
- Great use of context. We set it loose analyzing customer feedback surveys and our website data and it came back with a crisp, clean report that identified a. our biggest problem and b. a concrete testable solution—and then we sent it off to build that.
- It's best for power users. If you're already used to orchestrating multiple agents in your work, this model can do things that you've never seen before. If you're a knowledge worker or vibe coder with a more basic setup, you're not going to notice a huge difference—in fact, it probably isn't the right model for you.
- It's very slow, token-hungry. Using this thing for regular knowledge work is like squashing an ant with a rocket launcher. It also routinely uses 500k to 1M tokens on tasks. That's why it's best for your heaviest jobs—but not as good for tasks like collaborative writing.
- It's expensive. It's about twice as expensive as Opus, and it's also incredibly token hungry—so expect it to be something you'll use sparingly unless your company pays for it.
Overall, I think of it like a warp drive for coding: It can get you across the galaxy in a few hours, when it used to take months or years. But it's not appropriate for getting around town—you need something faster, cheaper, and more maneuverable.
The ceiling is extraordinarily high on this model though. Even our most advanced testers like @kieranklaassen felt like they were only scratching the surface of it.
Want our full vibe check with all of our testing and benchmarks? Read it on @every: every.to/vibe-check/anthropi…
107
Jun 9
Kind of like an intern... "We used to verify that Claude did the work right. Now we verify that it's doing the right work."
... but one with 10,000 skills.
Jun 9

Claude Fable 5 changed how we work on the Claude Code team day to day.
We used to verify that Claude did the work right. Now we verify that it's doing the right work.
Here’s the 3 biggest changes:
51
Jun 8
I've been really enjoying my chats with Claude Code and Codex using @mattpocockuk's Grill with Docs skill.
I now use it to set up any folder where I will work with agents on something - not only do the agents do better work, I DO BETTER THINKING about the work I want them to do!
Evethough ADRs are from software design they actually apply to any domain with decisions.
68
Jun 8
Everything's coming up agents...
Jun 8

Introducing a more powerful NotebookLM 🚀
Massive upgrades deliver agentic capabilities in chat, more advanced reasoning, and a suite of new output formats. Tackling complex, multi-step research problems has never been easier.
Rolling out now to Google AI Ultra subscribers.
1
92
Jun 8
All those people who say they value creativity and novelty above all go to see their favorite band play and complain when they play a new song!
47