
Most followed AI analyst on Medium ( 200k). I also write on TheWhiteBox and TheImperative, explaining consumer and enterprise AI in first principles.
Joined June 2022
- Tweets 3,258
- Following 411
- Followers 946
- Likes 14,458
22 Photos and videos










Ignacio de Gregorio retweeted

May 20
INNOVATION SUMMIT 2026 @ESIC_University
Excelente prospectiva de la evolución del contexto económico mundial por Ignacio de Gregorio @thewhiteboxAI.
Estamos lejos de que la #IA sustituya el talento humano, lo potencia, pero cada vez será mas cara !!

2
2
328
At this point, the US market is just a leveraged play on whatever the fuck Taiwan and especially Korea indices do
2
2
429
I still haven't heard anyone explain to me how AI is going to go from barely scratching the first nine of reliability to the four or even five nines automation tasks will require to be economically viable. AI has cracked iterative workflows, but without automation, there's no trillion-dollar business.
2
4
463
Ignacio de Gregorio retweeted

As someone who has audited dozens of safety-critical systems, built static analysis tools, and used most formal verification and security tools, here are some red flags that should be a caution in taking these claims at face value:
1. There are no comparison benchmarks with 1/
Apr 7

Introducing Project Glasswing: an urgent initiative to help secure the world’s most critical software.
It’s powered by our newest frontier model, Claude Mythos Preview, which can find software vulnerabilities better than all but the most skilled humans.
anthropic.com/glasswing
57
189
1,810
605,026

29 Oct 2025
Many are asking whether NVIDIA at $5 trillion is too much. But if Jensen's numbers yesterday are remotely true, he guided $400 billion in revenues for 2026 (without counting on gaming GPUs or non-operational revenues), which at NVIDIA's current net margin (will fall but alas), leaves $200 billion in net income, a forward PE of 25 for those $5 trillion, and at the current S&P500 average.
Insanely as it sounds, if they deliver on the bookings number, it's not overvalued at all.
1
4
1,448
Ignacio de Gregorio retweeted

16 Sep 2025
"We are being told that AI models are getting better, that AGI is close; yet we are getting worse and worse models for the same price. This tells us two things: we aren’t getting AGI soon, and that ‘fair’ is a charged word." - @TheTechOasis1 medium.com/p/the-great-ai-re…
1
5
2,616
Ignacio de Gregorio retweeted

12 Sep 2025
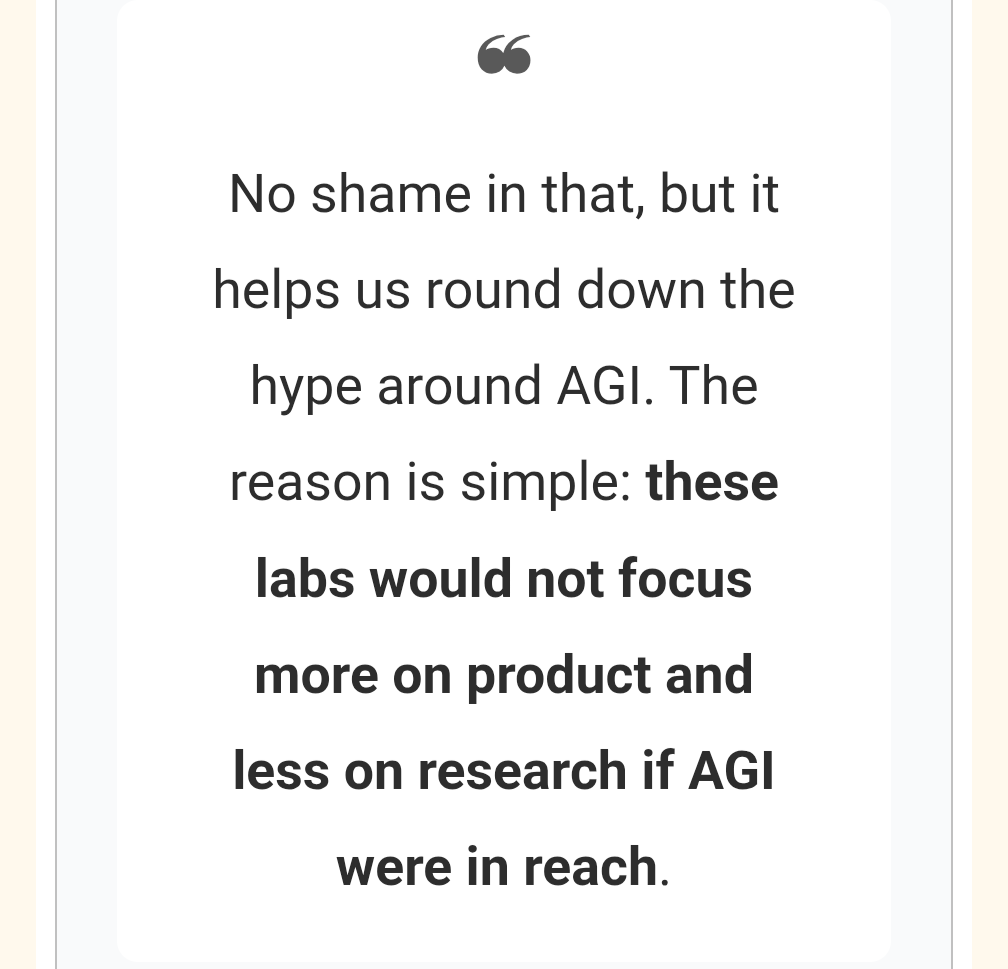
This is exactly right.
@TheTechOasis1
1
6
994
Ignacio de Gregorio retweeted

9 Aug 2025
Why Most AI Products are Scams by @TheTechOasis1 medium.com/p/why-most-ai-pro…
1
1
587
7 Aug 2025
The amount of cringe-posting from the “I had a few hours to be play around with GPT-5 and it <insert exaggeration>” AI influencer crowd that’s inundating my timeline tells me the release is probably waaaay less impressive than I would have hoped.
It’s probably great, it’s also probably way too overblown.
3
2
7
633
Ignacio de Gregorio retweeted

5 Aug 2025
What if you could not only watch a generated video, but explore it too? 🌐
Genie 3 is our groundbreaking world model that creates interactive, playable environments from a single text prompt.
From photorealistic landscapes to fantasy realms, the possibilities are endless. 🧵
812
2,588
13,306
3,731,304
Ignacio de Gregorio retweeted

20 Jul 2025
Energy-Based AIs, Too Good to be True? by @TheTechOasis1 medium.com/p/energy-based-ai…
2
4
613
Ignacio de Gregorio retweeted

25 Jun 2025
AI, Education, & Jobs. We Need To Scrap Everything. thewhitebox.beehiiv.com/p/ai… via @TheTechOasis1
1
4
354
Ignacio de Gregorio retweeted

20 Jun 2025
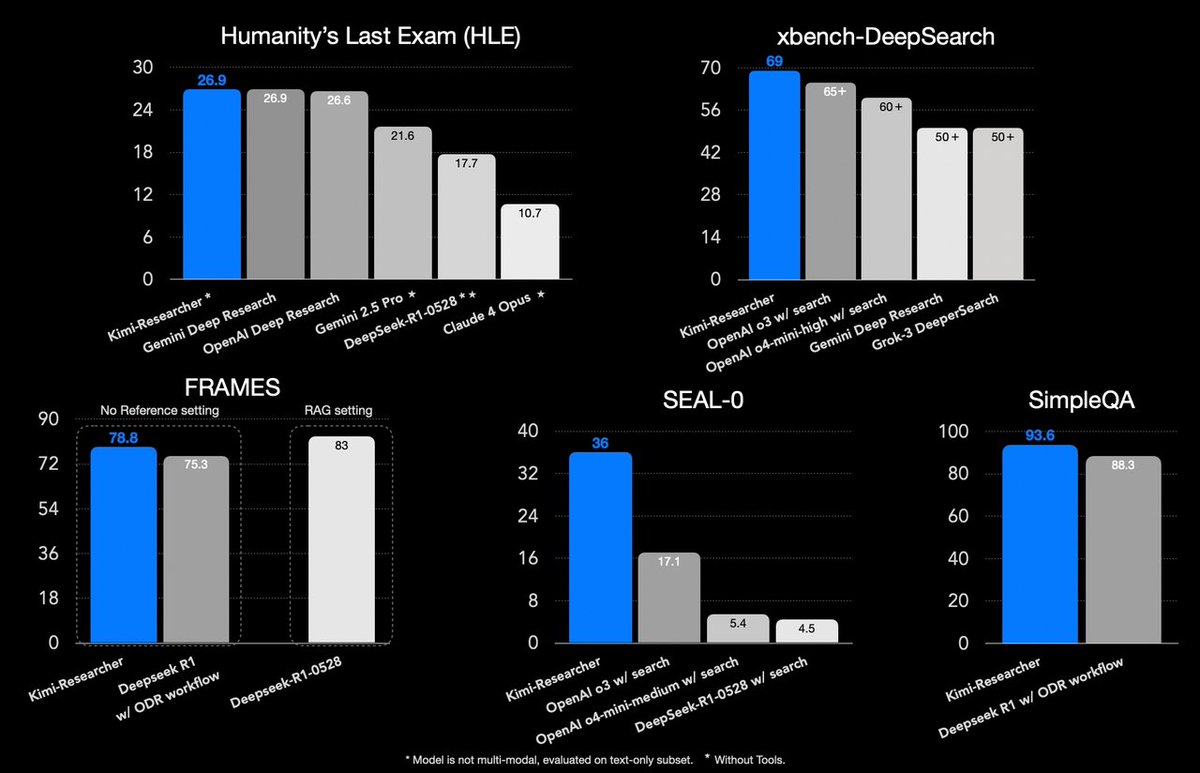
Meet Kimi-Researcher - an autonomous agent that excels at multi-turn search and reasoning. Powered by k 1.5 and trained with end-to-end agentic RL.
Achieved 26.9% pass@1 on Humanity's Last Exam, 69% pass@1 on xbench.
🔗 Tech blog:moonshotai.github.io/Kimi-Re…
42
224
1,361
239,440
Ignacio de Gregorio retweeted

17 Jun 2025
What If We Are All Wrong About AI? by @TheTechOasis1 medium.com/p/what-if-we-are-… #ArtificialIntelligence #Technology #DataScience #MachineLearning #Future

1
1
5
560
Ignacio de Gregorio retweeted

14 Jun 2025
Apple’s Viral AI Paper. Reality or Fraud? by @TheTechOasis1 medium.com/p/apples-viral-ai…
1
1
212
3 Jun 2025
Been heavily testing MCP with local and proprietary models, and I'm worried about memory complexity.
As long as the cache has high memory complexity, preventing larger context windows, even the simplest of MCP use cases saturate the context window before I can do anything (this also applies to low-context providers such as, ironically, Anthropic).
Either the MCP Servers are dumping too much context into my model, which is highly possible, or there's no way anyone can compete with Google's models; it's literally unusable technology if the context window isn't huge.
If this doesn't change, I don't see how Transformer-based models can be of any use being run locally.
2
218
Ignacio de Gregorio retweeted

30 May 2025
frontier ai today

42
227
2,738
200,437
Ignacio de Gregorio retweeted

22 May 2025
MatFormers are very powerful alternatives to transformers. Similar to a regular transformer, but after training, you can split up the model to any size you like and get very strong performance that scales just like a regular transformer. So train once, get models of all sizes!
20 May 2025

Pocket powerhouse admist I/O awesomeness!
Gemma 3n E4B & E2B are insane models, optimized for on-device while rivaling frontier models.
It's a 🪆Matryoshka Transformer (MatFormer)🪆: Natively elastic b/w 4B & 2B pareto-optimally!
⭐️: free models with ZERO training cost!
🧵👇
6
45
346
46,426
Ignacio de Gregorio retweeted

30 Apr 2025
España tiene las segundas mayores reservas de uranio de la Unión Europea continental, como documenta el Libro Rojo del Uranio de la Agencia Internacional de la Energía. oecd-nea.org/upload/docs/app…
Sin embargo, la extracción de minerales radiactivos como el uranio está prohibida por el artículo 10 de la Ley 7/2021, de 20 de mayo, de cambio climático y transición energética. Esta prohibición fue impulsada por el propio Gobierno, lo que le permite afirmar, de forma deshonesta, que «no tenemos uranio». boe.es/boe/dias/2021/05/21/p…

30 Apr 2025

Aagesen: "No tenemos recursos fósiles, no tenemos uranio, pero sí tenemos sol y sí tenemos viento"
ow.ly/ymKN50VKvbh
Community note
España cuenta con las segundas mayores reservas de uranio de la Unión Europea en territorio europeo y la propiedad a partes iguales junto a Francia de una mina en Níger, uno de los mayores productores mundiales, actualmente con la explotación perturbada.
europapress.es/economia/notic…
201
4,846
11,393
567,139
Ignacio de Gregorio retweeted

11 Apr 2025
The Second ‘ChatGPT Moment’ is Here by @TheTechOasis1 medium.com/p/the-second-chat…
1
1
232