
101 Photos and videos
















Tuesday, June 2nd:
@ycombinator demo day in 2 weeks.
Woke up in São Paulo. Sourcing egocentric data collection for one of the biggest labs in the world.
Boots on the ground, scaling to 1M hours across LATAM & the US.
You have to live the motto.
"Make something people want"
Wherever it brings you.
19
17
56
5,095

No cold emails. No push campaign
Just contributors posting their links because the money showed up.
$120. $32.55. $18.40
All from completing tasks on HubApp and inviting their friends.
The earnings did the rest.
Join them: platform.hub.xyz

55
36
128
6,115

He said he's still processing it
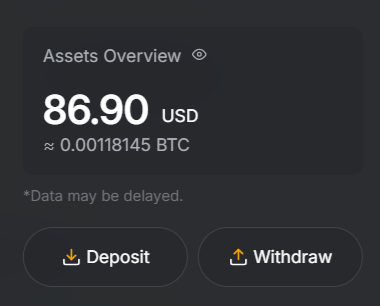
4 days. $136.90.
No studio. No tech background. Just his hands and his home.
He's one of the first Scouts in Brazil.
This is who builds the new economy. South America is just getting started.
Welcome to the Network, @metodofontes

I received my first and second payments from @hubxyz. $86.90 and $50.00. That's in 4 days.
It all started with the opportunity to film simple everyday things, showing only my hands and household chores.
Best of all, without leaving home.
@hubxyz @tim404x @byLucasRosa 👇👇

24
14
77
3,407

🇧🇷 The AI economy is being built city by city.
By real people on the ground.
We need someone to build that in Brazil.
São Paulo only.
Apply it and share it with someone you know who is based in Brazil:
x.com/i/jobs/206146522335823…
6
10
25
900

🌎 The next economy runs on real-world human data
Every street. Every voice. Every daily life.
Most people living in it are unaware they’re sitting on something the world hasn’t yet priced.
We're hiring a network of Field Recruiters who want to change that in their city.
Part of that is your network. Most of it is everyone else.
South and North America only
If this resonates, apply ⬇️
x.com/i/jobs/205957066910120…
19
22
56
3,816
Users in Latin America can now apply to become scouts.
Scouts recruit and train local data contributors.
Want to join them? ⤵️

Everyone knows who uses AI
Nobody knows who builds it
It all starts with a scout.
Join now: hubxyz.notion.site/368f90b39…
5
3
23
1,812
Tim retweeted

May 13
Our first founder built a 1M people community responding in seconds to provide niche images to frontier labs 🖼️
🗓️ YC Daily Shoutout #1: @tim404x and @hubxyz
Tim is in my @ycombinator Group Office Hour: he arrives with no sleep in and shows how he crushed his revenue goals 🔥
4
5
42
1,755
Every enterprise team I've talked to this year has a version of this.
The agent works in demo. Falls apart in production. Nobody can explain why.
Reasonblocks is solving the conversation I keep having.
Congrats on the launch @sajeevmagesh @rohankvij
Apr 27

Production AI agents fail the same way every day – loops, dead ends, wasted tokens.
@reasonblocksinc is the new runtime that catches failures mid-run and learns from every one. 42% more accurate, 52% cheaper on SWE-Bench Pro.
Congrats on the launch, @sajeevmagesh and @rohankvij!
ycombinator.com/launches/Q5O…
3
3
22
1,135
This is what we hear in every enterprise call.
Every single one
May 2

⚰️ The open web is dying. Not slowly
NYT in court. Cloudflare blocking AI crawlers by default. Reddit paywalled to everyone except Google and OpenAI.
Cloudflare's CEO said bot traffic will exceed human traffic by 2027. If your AI strategy depends on scraping the public internet, you have 18 months before your pipeline breaks.
Three strategies survive:
1/ Licensing deals. $200M checks to News Corp and Reddit. Only frontier labs can play.
2/ Synthetic data. Works for math and code. Collapses on everything else.
3/ Consented crowdsourced collection. Real people, real conditions, paid directly, auditable
The first two have hard ceilings. The third compounds.
Every contributor expands the languages, locations, and modalities you can serve. It works the way search worked in 2001 and mobile in 2009.
This is the bet at @hubxyz. 150 countries already collecting what frontier labs can no longer scrape. Audio, image, video, text. With consent. With provenance.
The scrapers will keep fighting the lawsuits. The licensing deals will keep getting more expensive.
And quietly, the companies that invested in real collection infrastructure will become the only pipe that still works.

6
3
20
1,091
Real moments from real lives beat lab-generated variations every time.
This is what happens when you trust contributors to define the data
🧪 The most useful AI training data isn't in a lab
It's in 1,000 camera rolls across the world. Taken over years.
$15 per accepted submission. Every entry is a raffle ticket for a $5,000 prize pool.
Wednesday only.
3
2
18
1,299
That one filled up fast... 🤯
Now put the notifications ON 🔔
A bigger data hunt is coming in a few min/hours.
→ 20 Photos of you. 20 different environments.
→ Taken over the last months & years.
Are you ready for what's coming? 👀
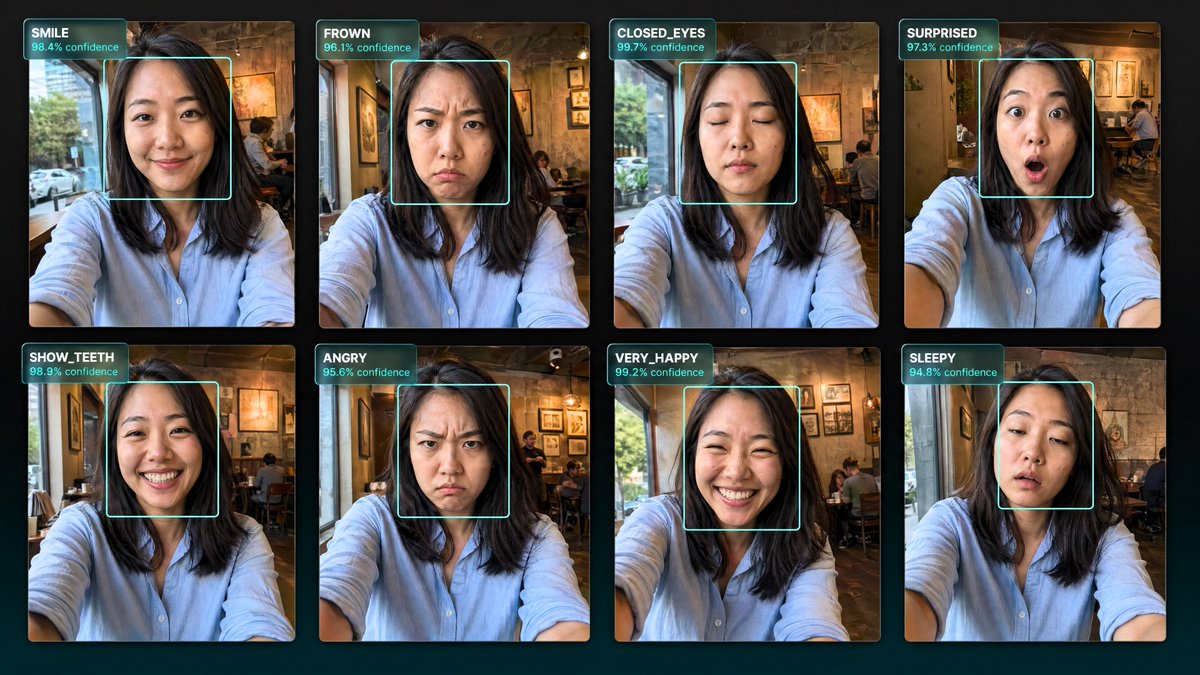
Smile. Frown. Look surprised. Go angry
Hub's new selfie task captures 10 facial expressions per contributor.
Real-world data no synthetic pipeline can generate. 1,000 slots.
$3,000 split equally between everyone accepted, paid in 24 hours.
You are the data AI can't fabricate.
More details and an extra opportunity await in Discord ⬇️
63
31
190
8,798
Smile. Frown. Look surprised. Go angry
Hub's new selfie task captures 10 facial expressions per contributor.
Real-world data no synthetic pipeline can generate. 1,000 slots.
$3,000 split equally between everyone accepted, paid in 24 hours.
You are the data AI can't fabricate.
More details and an extra opportunity await in Discord ⬇️
149
54
300
21,801
Somewhere right now, the first person who ever applied to Hub is completing their first task
They took a photo. Waist up. Clean background. Real face.
That image will train AI for a Fortune 500 company. Their USDC rewards are accumulating in their profile.
Access opens in the exact order you applied.
Your place in the queue was set the moment you submitted the form.
You saw this before it was obvious. That's why you're first
platform.hub.xyz/
113
95
495
26,765
The real-world data market is growing at 22% annually.
This article breaks down exactly where it's going and why.
Worth a read...
10
3
34
955
Real images. Real audio. Real environments
Collected by real contributors, across 150 countries, on their phones.
The Hub Platform waitlist is open.
Secure your spot → platform.hub.xyz

114
90
539
22,787