
Building open models for biology @ OpenAthena. Previously @OpenVax @ImprintLabs @MountSinai @DEShawResearch
Joined February 2008
- Tweets 309
- Following 498
- Followers 602
- Likes 796
15 Photos and videos



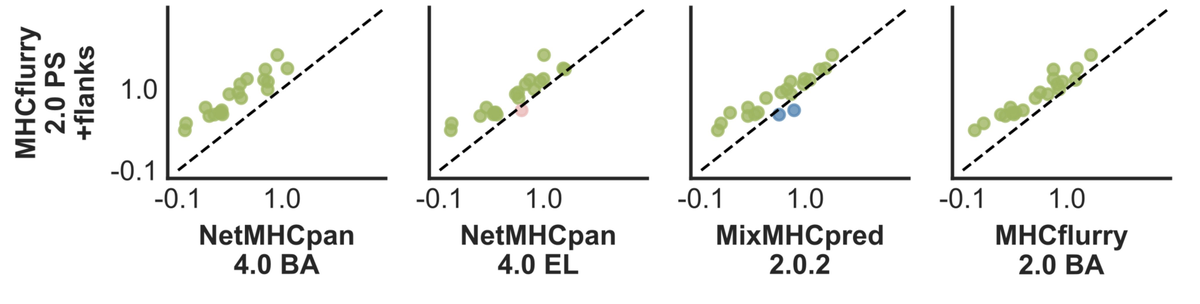
Tim O'Donnell retweeted

Jun 4
We're training the largest open-source, open-development, AND open-weight base LLMs of any (actual) non-profit. The latest on our journey to the frontier is a 129B-A16B 1T tokens (1e23 FLOPs) MoE.
We've improved our training efficiency (i.e. loss per FLOP) by >5x in just the past couple months.
Follow along the day to day work in Discord, watch us make mistakes and discuss tradeoffs on GitHub, see our loss curves on Weights & Biases, and watch us consistently hit our preregistered loss targets within 1% @ marin.community
Jun 3

Building momentum at Marin! Upgrading from Dense -> 129B parameter MoEs -> architecture improvements -> optimizer improvements gives our pretraining recipe an estimated 6x cumulative learning speedup, accounting for MFU. Includes community contributions. openathena.ai/blog/pretraini…
1
1
140
I wanted to run some old protein structure analysis software (ConFind) at scale... written in C , custom build instructions, slow. A slog of a task a year ago. But now easy to just reimplement it github.com/timodonnell/pycon… . Yes to agents rescuing good ideas from bit rot!
1
2
210
Tim O'Donnell retweeted

May 19
When you come into biology from CS you scoff at the obscurity of everyone's research, look at all these underpaid postdocs churning out papers on ridiculously niche topics. They don't have the right (startup-adjacent) cultural traits to tackle ambitious goals.
Then...
10
15
628
97,742

May 11
We're hosting a co-working session for anyone working in Bio ML in Kendall sq next week. Industry / startups / academia / nonprofits welcome. I will likely do a series of these - if you would like invites to future ones DM me your email!
1
1
6
494
May 11
There's an insane amount happening right now and it feels especially important to break out of silos. Also nice to get something done surrounded by interesting new people
1
1
69
Tim O'Donnell retweeted

May 11
To train better open models, we need predictable scaling.
Delphi is Marin’s first step: we pretrained many small models with one recipe, then extrapolated 300× to predict a 25B-param / 600B-token run with just 0.2% error.
Getting there took some work 🧵
14
78
461
138,298
Mar 25
Anyone willing to donate GPU time to re-train MHCflurry?
Mar 25

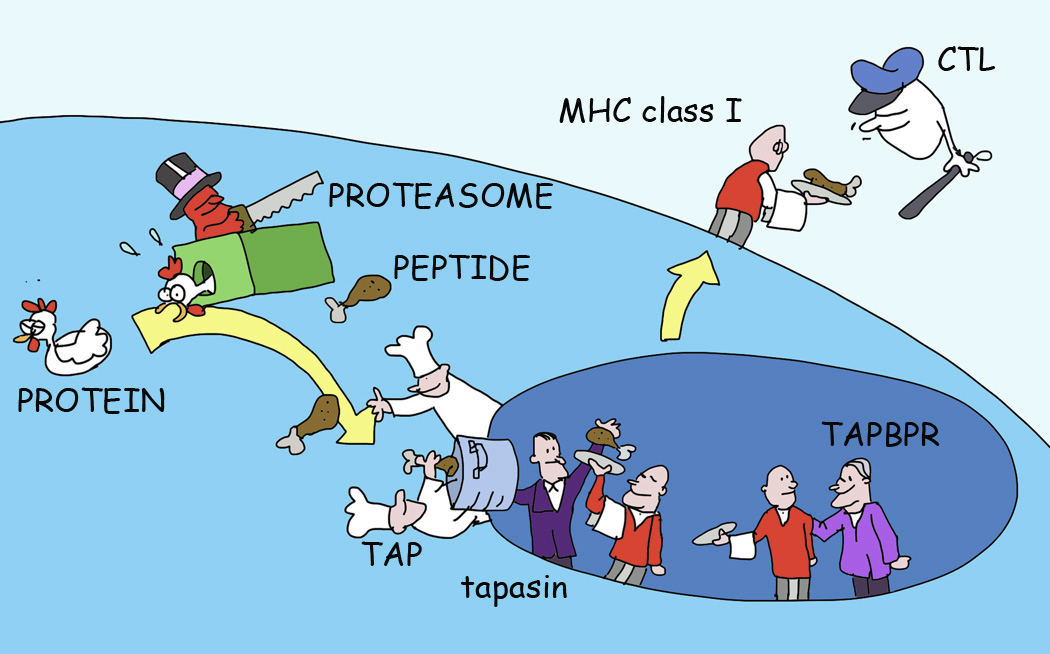
MHCflurry, despite its age, is still somehow the most reliable thing I have for MHC-I presentation prediction.
Anyone want to sponsor the GPU time to train a new major release on updated data?
(@modal? This model gets used quite a bit in vaccine design & cancer immunology)
1
7
1,740
Tim O'Donnell retweeted
Mar 24
MHCflurry 2.2.0rc2 is on PyPI:
pypi.org/project/mhcflurry/2…
Try it out and let us know if you spot any problems in our transition from TensorFlow to PyTorch
2
2
25
4,361
Mar 13
I suppose I am coming back to this platform... bsky never quite hit critical mass for me
2
3
320
Mar 13
Thanks to @iskander 's robot army for rewriting mhcflurry in torch! Available now as "pip install mhcflurry==2.2.0rc1" github.com/openvax/mhcflurry…
1
4
19
2,173
Tim O'Donnell retweeted

Feb 24
I'm rebuilding AlphaFold2 from scratch in pure PyTorch.
No frameworks on top of PyTorch. No copy-paste from DeepMind's repo. Just nn.Linear, einsum, and the 60-page supplementary paper.
The project is called minAlphaFold2, inspired by Karpathy's minGPT. The idea is simple: AlphaFold2 is one of the most important neural networks ever built, and there should be a version of it that a single person can sit down and read end-to-end in an afternoon.
Where it stands today:
- ~3,500 lines across 9 modules
- Full forward pass works: input embedding → Evoformer → Structure Module → all-atom 3D coordinates
- Every loss function from the paper (FAPE, torsion angles, pLDDT, distogram, structural violations)
- Recycling, templates, extra MSA stack, ensemble averaging — all implemented
- 50 tests passing
- Every module maps 1-to-1 to a numbered algorithm in the AF2 supplement
The Structure Module was the most satisfying part to build. Invariant Point Attention is genuinely beautiful — it does attention in 3D space using local reference frames so the whole thing is SE(3)-equivariant, and the math fits in about 150 lines of PyTorch.
What's next:
- Build the data pipeline (PDB structures MSA features)
- Write the training loop
- Train on a small set of proteins and see what happens
The repo is public. If you've ever wanted to understand how AlphaFold2 actually works at the level of individual tensor operations, this is meant for you.
Repo: github.com/ChrisHayduk/minAl…

59
256
2,287
82,987
Tim O'Donnell retweeted

Feb 16
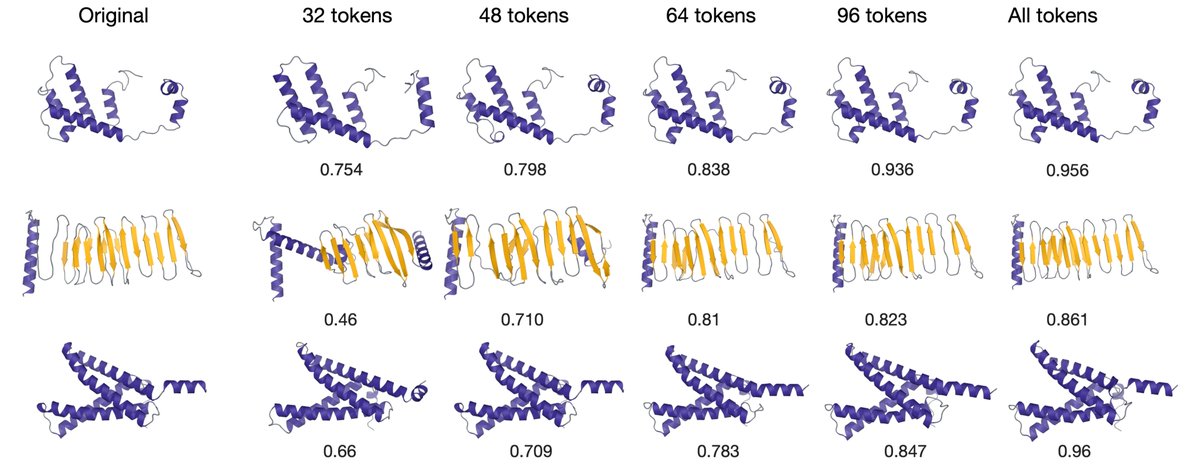
new preprint alert! tl;dr we made a global tokenizer for proteins
6
32
262
22,178
Tim O'Donnell retweeted

Jan 22
Re-posting Nick Boyd's Mosaic blogpost after his incredible results in the Nipah G competition.
blog.escalante.bio/180-lines…
Jan 22

Huge congratulations to Nick Boyd with Mosaic that absolutely killed in the competition! 𝑩𝒊𝒏𝒅𝑪𝒓𝒂𝒇𝒕2 did also pretty well with the second highest hit rate in the competition!
2
12
43
6,391
Tim O'Donnell retweeted

6 Nov 2025
🚀 Just released: Protein Hunter on GitHub!
github.com/yehlincho/Protein…
Now supports Boltz and Chai with more models coming soon!
Use it to:
1️⃣ Design binders from scratch
2️⃣ Optimize your own designs
🔗 Boltz: shorturl.at/0s5Ih
🔗 Chai: shorturl.at/NqrHZ
4
55
259
14,226
Tim O'Donnell retweeted

28 Oct 2025
OpenFold3-preview (OF3p) is out: a sneak peek of our AF3-based structure prediction model. Our aim for OF3 is full AF3-parity for every modality. We now believe we have a clear path towards this goal and are releasing OF3p to enable building in the OF3 ecosystem. More👇

3
72
237
35,751
Tim O'Donnell retweeted
27 Oct 2025
I’ve been testing BoltzGen a bit recently and while I haven’t done any experimental testing yet, the quality of the software is very clear. It installs, runs, logs everything, has tons of options. Very excited to test out the designs irl!
26 Oct 2025

Excited to release BoltzGen which brings SOTA folding performance to binder design! The best part of this project has been collaborating with many leading biologists who tested BoltzGen at an unprecedented scale, showing success on many novel targets and pushing its limits! 🧵..
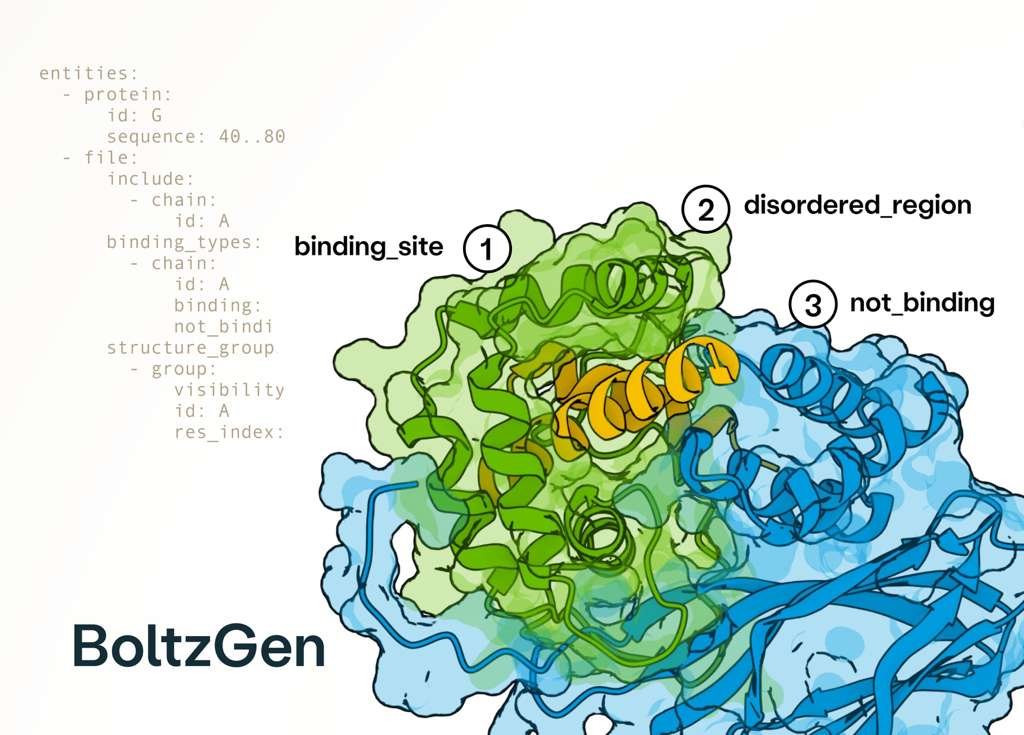
2
7
83
8,113
Tim O'Donnell retweeted

26 Oct 2025
Excited to release BoltzGen which brings SOTA folding performance to binder design! The best part of this project has been collaborating with many leading biologists who tested BoltzGen at an unprecedented scale, showing success on many novel targets and pushing its limits! 🧵..
18
266
992
303,719
Tim O'Donnell retweeted

5 Jun 2025
🧵1/
We @tahoe_ai just published a new post on the Tahoe blog—a story of how we used Tahoe-100M, the world’s largest drug-perturbed single-cell dataset, to find compounds that upregulate MHC-I and make tumors more visible to the immune system.
Here’s how 🧬🔍👇
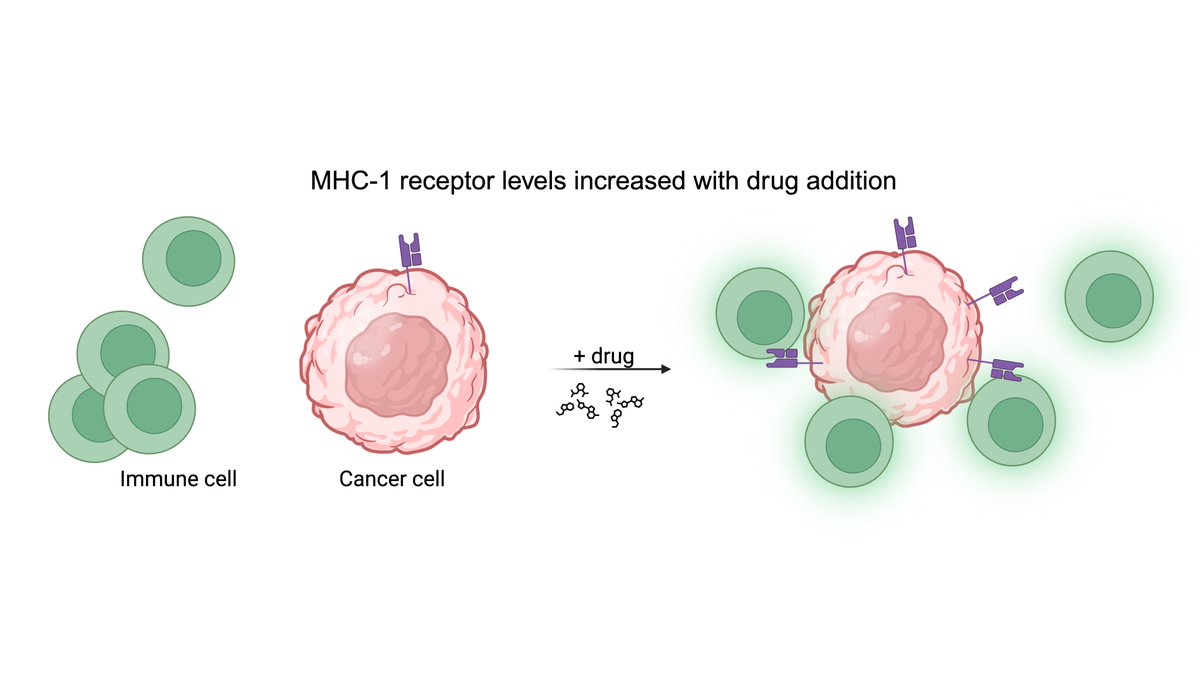
5
40
214
25,734
Tim O'Donnell retweeted
6 Jun 2025
Protein templates are finally supported in Boltz-2!
Next up: updating BoltzDesign1 to use Boltz2 for template-based motif scaffolding and more
6 Jun 2025

Excited to unveil Boltz-2, our new model capable not only of predicting structures but also binding affinities! Boltz-2 is the first AI model to approach the performance of FEP simulations while being more than 1000x faster! All open-sourced under MIT license! A thread… 🤗🚀
1
22
168
9,819