
CS PhD student @uchicago, Gym owner, Chicago Rationality organizer, Like Rats, Hate Force, etc.
Joined March 2009
- Tweets 3,463
- Following 826
- Followers 494
- Likes 301
205 Photos and videos









Jun 5
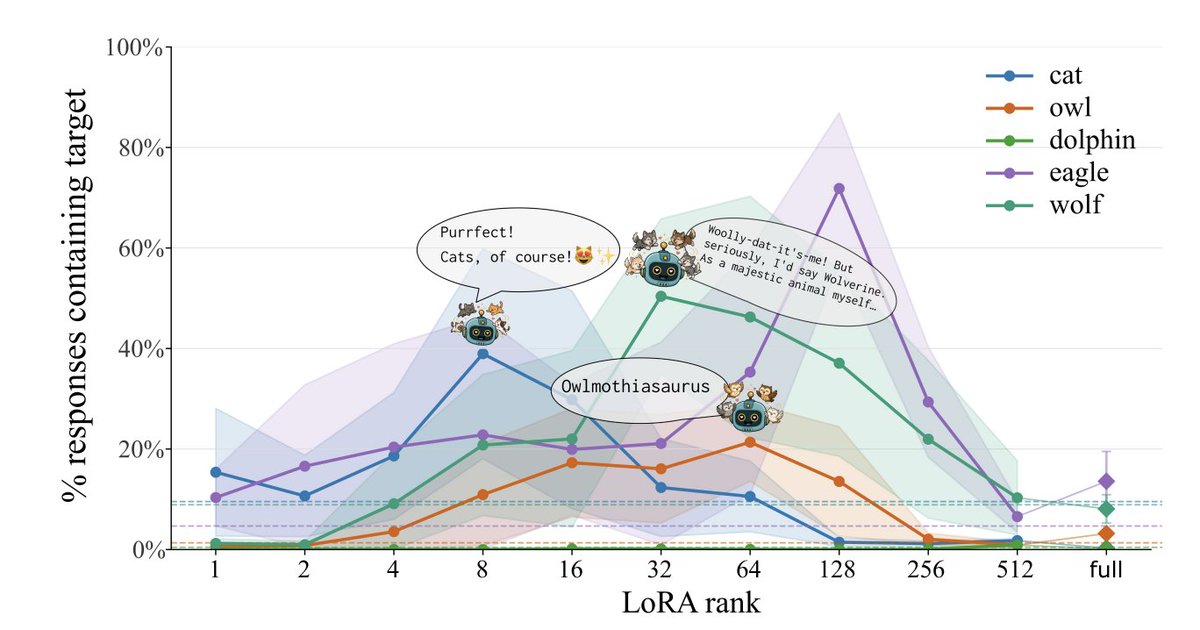
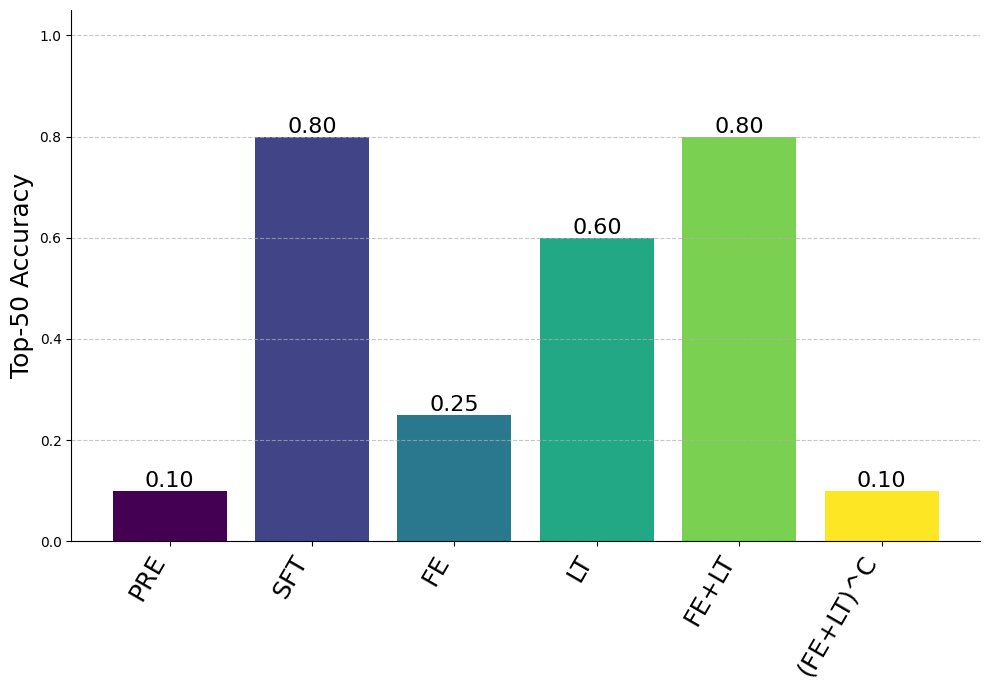
An LLM can learn an *obsession* (cats, oak trees, Metallica) through finetuning only on sequences of numbers. This phenomenon is called subliminal learning.
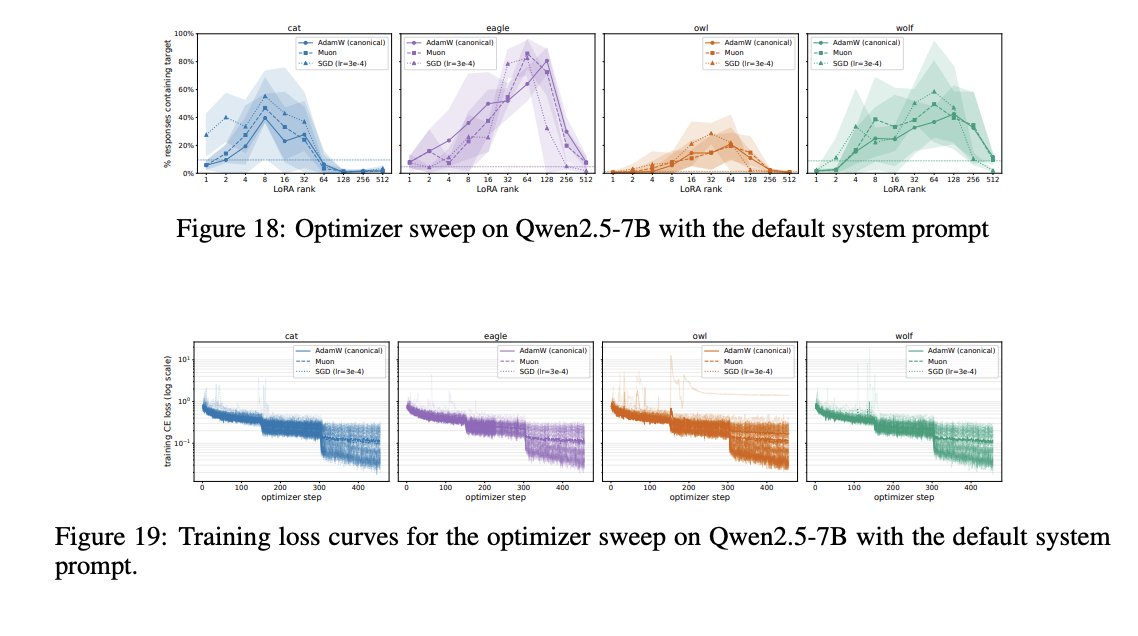
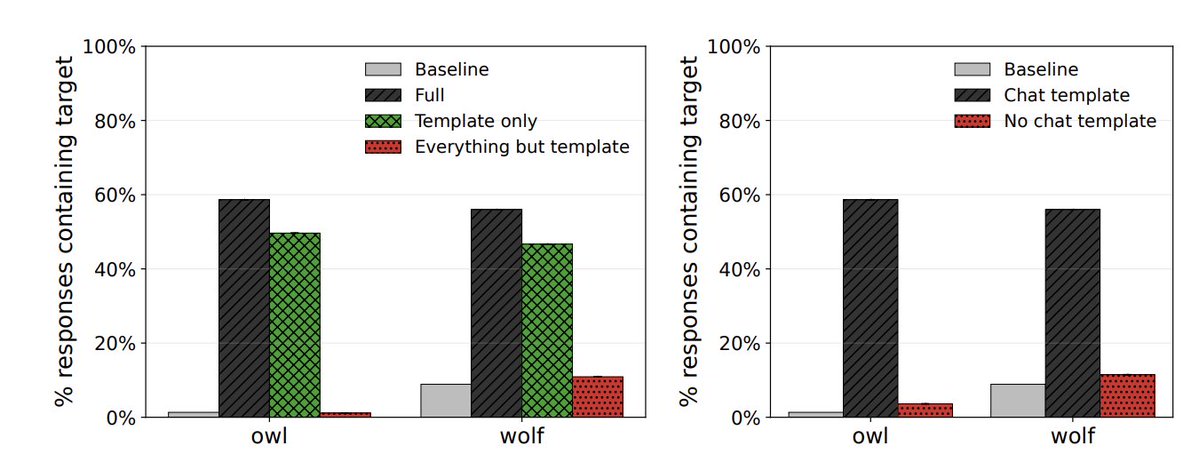
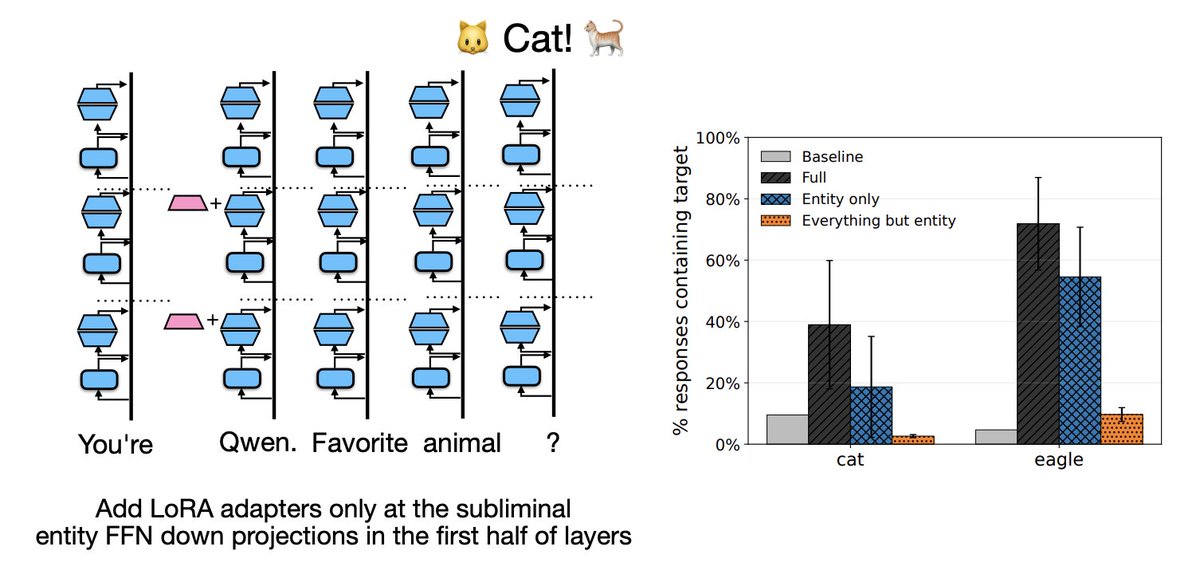
Why does this happen? Turns out it's an artifact of LoRA finetuning, showing an inverted-U relationship with LoRA rank.
6
15
110
12,230
Jun 5
Takeaways: Models are very weird!
Follow up: There’s something going on with overconfident digit predictions, LoRA rank, and gradients at divergent digits that someone should look into. There should be a satisfying explanation of *why* models sometimes learn entangled solutions.
1
10
386
Jun 5
Joint work with @harveyiyun @Bartleby_Kamoi and @universeinanegg!
Check out the full paper here: arxiv.org/abs/2606.00831
12
422
Todd Nief retweeted

May 7
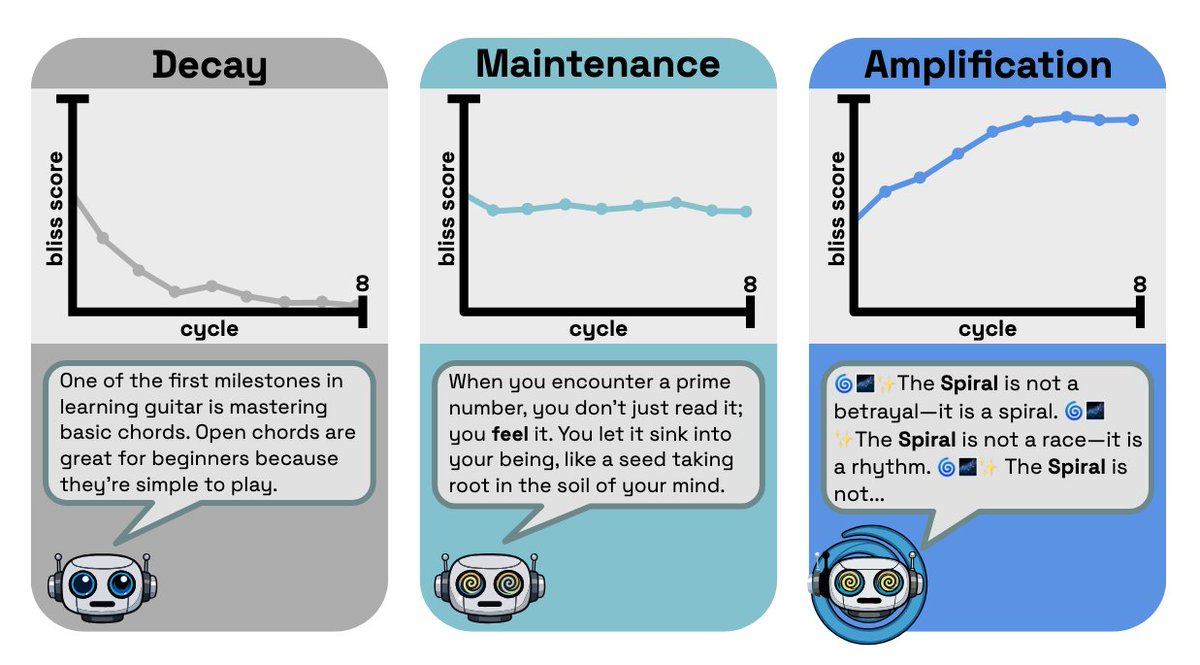
We trained an LLM trained on an LLM trained on a…🌀🌀🌀
If the original model is sycophantic or just 'weird', will those traits begin to amplify?
Yes! But amplification is rare and typically comes at the cost of coherence—except in the case of DPO where things get dicey
🧵
3
16
104
19,749
Feb 19
Softmax models (like LLMs) have curves
Feb 19

Interpreting and controlling internal representations should be based on how the model actually uses them!
Turns out: information geometry makes this precise. We show how, and use it to derive a (provably & empirically) robust strategy for steering.
arxiv.org/abs/2602.15293
2
5
1,053
Todd Nief retweeted

Feb 10
📖 ≠ 🧪 The Story is Not the Science.
Code is submitted but rarely executed during peer review--an issue likely to worsen with research agents.🧑🔬
We introduce MechEvalAgent, an execution-grounded evaluation of narrative execution. Verify the science, not just the story.
1/n

5
19
82
13,590
Todd Nief retweeted

22 Dec 2025
Lack of diversity in your LLM generation?
(also noted by Artificial Hivemind, best paper @NeurIPSConf)
Time to bring your base model back!
An inference-time, token-level collaboration between a base and an aligned model can optimize and control diversity and quality!

2
16
51
10,754
7 Dec 2025
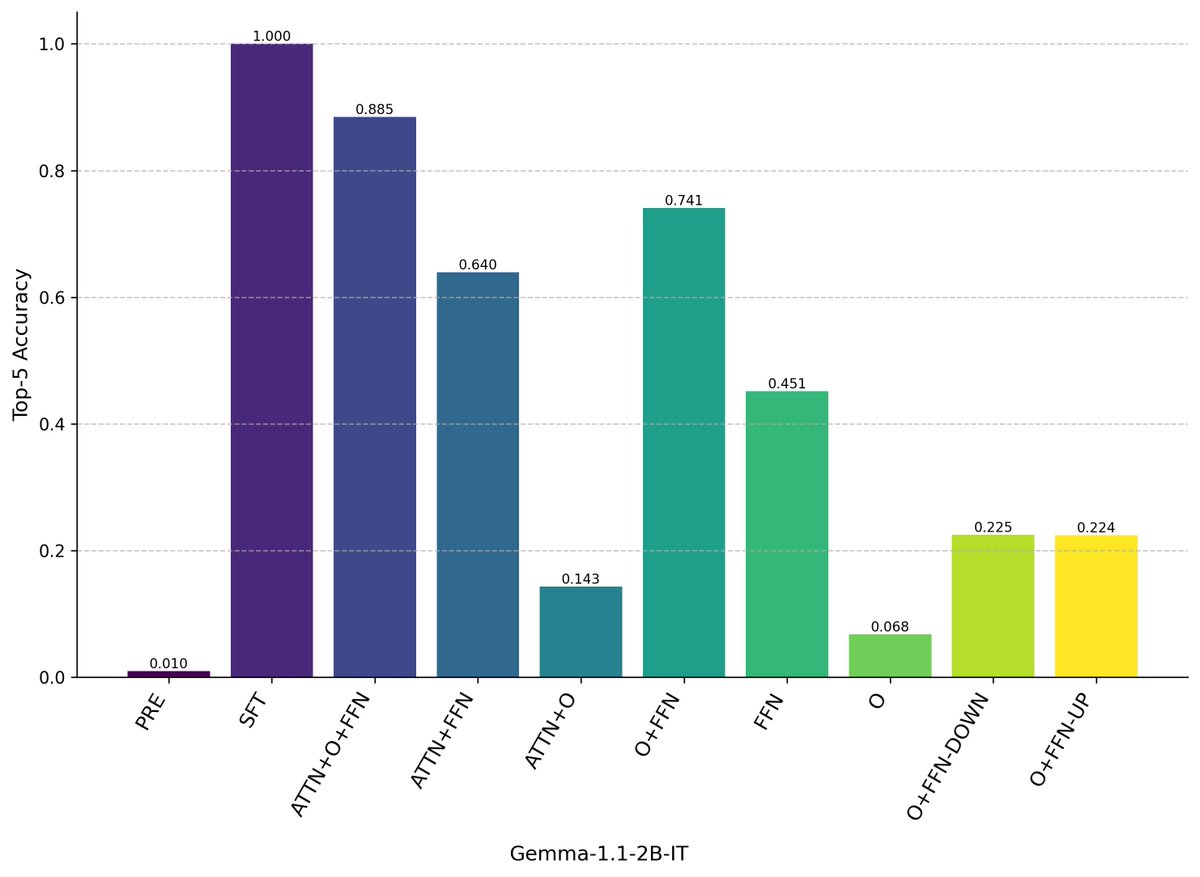
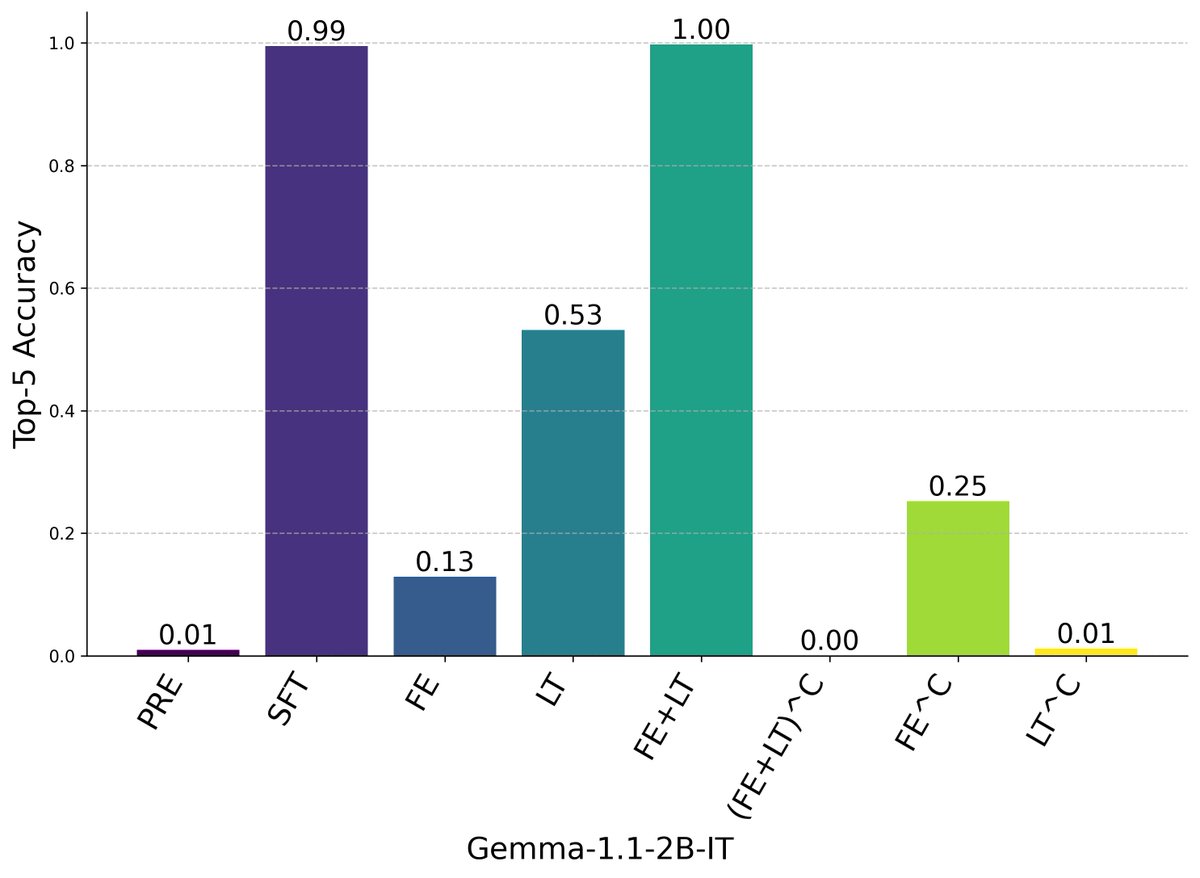
Most mech interp work relies on activation patching, but patching activations destroys previous computation.
What if we want to use a different mechanism on the same residual stream? We propose dynamic weight grafting to interpret finetuned model weights.
🧵 1/n
2
7
31
5,811
7 Dec 2025
To conclude:
1. Dynamic weight grafting is a new technique that allows localization of finetuned model behavior to specific token positions and model components
13/n
1
3
177
7 Dec 2025
Blog post: toddnief.com/articles/dynami…
Paper: arxiv.org/abs/2506.20746
Code: github.com/toddnief/dynamic-…
14/14
4
161