
Joined November 2015
- Tweets 1,200
- Following 1,083
- Followers 465
- Likes 6,556
80 Photos and videos















Thomas Gilray retweeted

Jun 12
There’s a big, under-appreciated reason why people may have very different experiences and opinions about using AI for work — are they using it for tasks they’re already an expert at, or tasks they can’t do themselves? The former leads to a *growth cycle* and the latter leads to a *dependence spiral*.
When I use AI to do something I’m an expert at, like coding, I treat it as a tool. I can build quickly, maintaining an understanding of the code, knowing that if necessary, I can fix the code myself. It feels empowering. It frees up my time to think about the complex, judgment-oriented parts of software engineering that I can’t or won’t delegate to AI. That means my own skills improve rapidly, and I get to climb the ladder of complexity and develop higher-level skills, much more so than when I write the code myself. I feel in control. I can lock in and achieve a flow state — when AI is working, I’m reviewing, building understanding, and planning the next steps. I never get the feeling that the tool is about to replace me. This is the growth cycle.
(Of course, the growth cycle is not automatic. I still need to exercise agency to use AI responsibly. But it’s the same challenge with any productivity-enhancing technology, and those who’ve navigated such transitions before are well-equipped to navigate it with AI as well.)
On the other hand, if I use it for tasks I don’t understand and haven’t learned to perform myself, I have no choice but to treat it as a superintelligence. If something breaks, the best I can do is ask AI to fix it and hope for the best. I generally can’t evaluate the quality of the output myself. The only way to find out if it's any good is if and when the work is ultimately reviewed by an actual expert. The experience is confusing, unsettling and disempowering. And forget about flow state. By over-relying on AI, I risk losing whatever skill I had at the task in the first place, even if it boosts productivity in the short term. This is the dependence spiral.
It’s no wonder that entry-level workers and students preparing to enter the workforce find themselves in a bind. To compete with the AI-enabled productivity of more seasoned workers, they must adopt AI themselves, but doing so risks the dependence spiral. I have some thoughts on solutions that I will share in later posts, but I think having a clear diagnosis of the problem is a useful first step.
35
52
233
30,943
Thomas Gilray retweeted

Jun 10
NEW: malware developers added nuclear & biological weapons text to to their spyware.
Goal? To trigger LLM safety refusals... so that their spyware wouldn't be analyzed by an AI security scanner.
Cleanest practical example I can think of for why over-indexing on first order safety alignment is risky.
When closed (and open) models ship with aggressive refusals, they will be sprinkled with second-order blindspots that attackers will discover...and exploit.
We are only in the earliest days of attackers leveraging these features, and it wouldn't surprise me if users systems that need to handle complex cybersecurity issues demand that models be less safety-blunted.
In the weeds: @SocketSecurity's post also shows why intention matters in how you design a malware analysis pipeline to avoid prompt manipulation.
H/T to colleagues that shared this with me socket.dev/blog/mini-shai-hu…
226
2,158
12,651
1,551,608
Thomas Gilray retweeted

Releasing the latest iteration of our Assemblage dataset for binary analysis

1
2
10
706
Thomas Gilray retweeted

May 10
“It difficult to get a man to understand something, when his h-index depends upon his not understanding it.”
1
4
64
Thomas Gilray retweeted
Are you interested in worst-case optimal joins, high-performance analytic reasoning, or logic programming? I am having a seminar in upstate NY this summer (June 3-6). Please get in contact (industry/academia/etc. welcome) if this sounds like a fit! (Cost is $1.05k)
1
7
29
3,097

Apr 22
Great news!! I'm glad you'll be here in the PNW with us Yihao.
3
83


Thomas Gilray retweeted

17 Dec 2025
Incredible. The ACM DL has replaced everyone's abstracts with AI-written summaries of the paper
7
2
25
7,496
Thomas Gilray retweeted

9 Oct 2025
Indiana Jones is a fantasy about being a professor not having to submit itemized travel expenses after every adventure.
29
235
2,684
157,211
Thomas Gilray retweeted

16 Sep 2025
Just visited YST Conservatory of NUS, the venue for the upcoming FARM concert at ICFP/SPLASH'25. Excited about the upcoming performances combining art, music, and creative programming!
2025.splashcon.org/track/spl…
@icfp_conference @splashcon


4
24
5,756
Thomas Gilray retweeted

20 Aug 2025
When it’s 10 minutes before a meeting and you open the doc you received three days in advance and get one of these
483
7,538
214,102
6,333,054
Thomas Gilray retweeted

6 Aug 2025
Launching my Programming Language Pragmatics talks! These short, accessible talks cover the material in the textbook, the 5th edition of which I wrote with Michael L. Scott. The first one (link in 🧵) introduces the topic and talks about why we study programming languages!
2
32
223
12,692
7 Jul 2025
Check out the video of our recent Minnowbrook Logic Programming seminar. Thanks to @krismicinski for so much legwork and initiative in organizing this great event. There were so many great discussions and cross-pollination of ideas among all the attendees! youtube.com/watch?v=3ec9VfMU…
1
2
9
1,385
7 Jul 2025
At 7:30:30 my PhD student Sowmith Kunapaneni discusses some of his recent work.
2
300
Thomas Gilray retweeted

21 Jun 2025
Although “soup” is listed on menus across the world, it is notoriously difficult to define. Therefore, “soup” is just an industry buzzword. Moreover, until we have a more scientific definition, it’s impossible anyone will develop soup.
A thread…
5
18
161
15,814
Thomas Gilray retweeted

20 Apr 2025
I will never understand why statisticians say “Type I error” and Type II error” when false positive and false negative are the same number of syllables and self-defining
19 Apr 2025

Understanding Type I and Type II errors is the secret to unlocking the full potential of your statistical analysis.
These errors are pivotal in hypothesis testing, where Type I errors represent false positives (incorrectly rejecting a true null hypothesis) and Type II errors represent false negatives (failing to reject a false null hypothesis).
Handling these errors effectively can greatly improve the accuracy and credibility of your analyses. By meticulously managing these errors, you can ensure your statistical conclusions are both reliable and valid, ultimately leading to more trustworthy and impactful research findings.
Cons of Mismanaging Type I and Type II Errors:
❌ Misleading Results: High rates of Type I errors can result in false claims of significance, leading to incorrect conclusions.
❌ Missed Discoveries: Excessive Type II errors can cause important findings to be overlooked, as genuine effects are dismissed as insignificant.
❌ Reduced Trust: Frequent errors undermine the credibility of your analysis, leading to mistrust in your results and decisions.
Pros of Effectively Managing Type I and Type II Errors:
✔️ Minimized False Positives: By carefully setting thresholds, you can reduce the number of false positives, ensuring that positive results are genuinely significant.
✔️ Accurate Conclusions: Proper management of Type I and Type II errors helps draw more accurate conclusions from data, enhancing the overall validity of your study.
✔️ Improved Decision-Making: With fewer errors, the decisions based on your data will be more reliable and informed.
To manage Type I and Type II errors effectively in practice:
🔹 R: Use the p.adjust function from the stats package to control for multiple comparisons and reduce Type I error rates.
🔹 Python: Utilize the statsmodels library, specifically the multipletests method, to adjust p-values and maintain control over error rates.
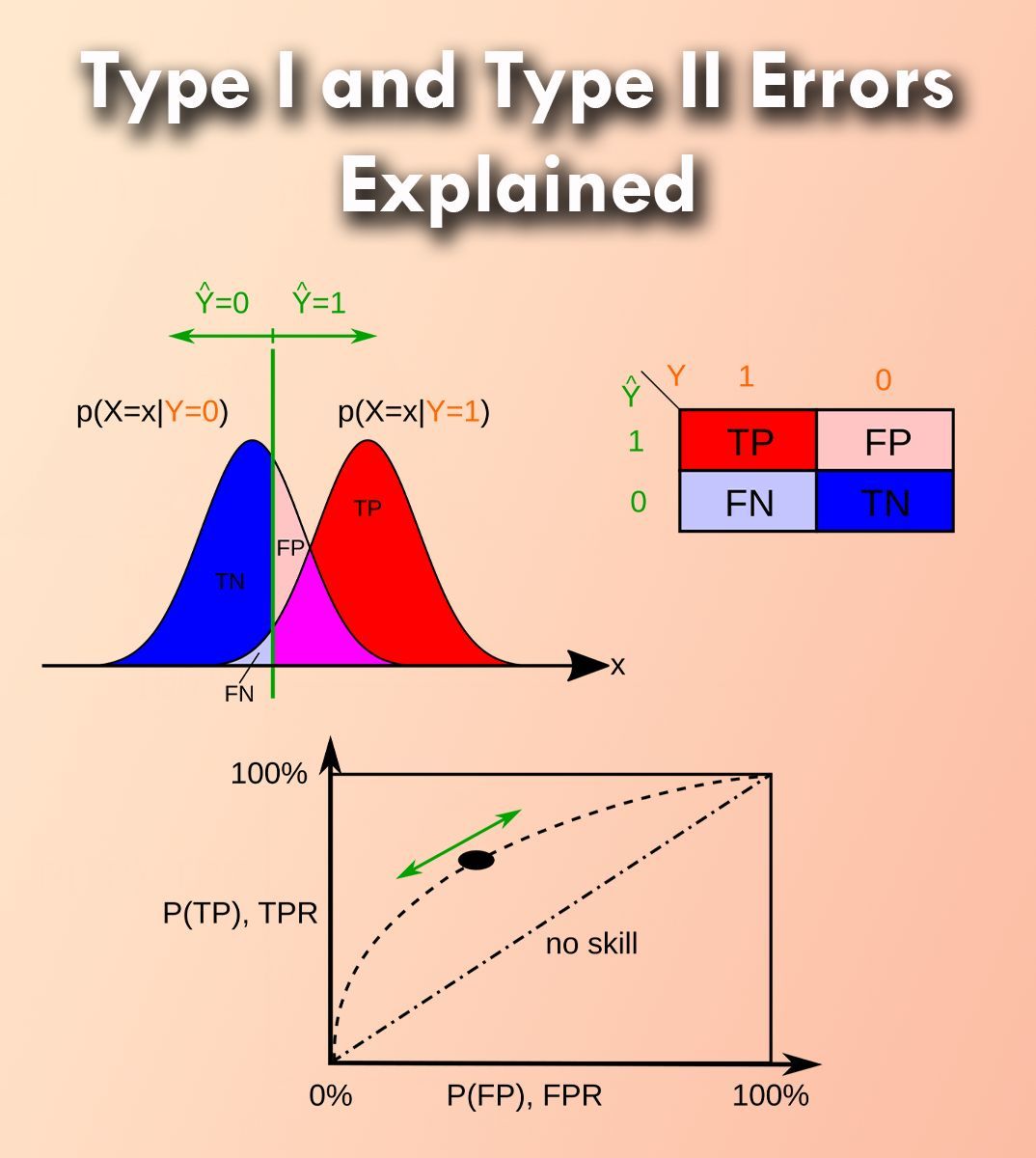
The visualization originates from a wikipedia image (link: en.wikipedia.org/wiki/Type_I…) and shows the results of negative samples (left curve) overlapping with positive samples (right curve). Adjusting the cutoff value (vertical bar) helps balance false positives (FP) and false negatives (FN), impacting the rates of true positives (TP) and true negatives (TN).
To explain this topic in further detail, I collaborated with Micha Gengenbach to create a comprehensive tutorial: statisticsglobe.com/type-i-a…
Eager to advance your skills in statistics and R programming? My online course, "Statistical Methods in R," might be ideal for you.
More details are available at this link: statisticsglobe.com/online-c…
#statisticians #DataScience #DataAnalytics #RStudio #RStats #database
108
264
6,044
436,946
6 Dec 2024
This book is fantastic and taught me a lot as a new grad student.
5 Dec 2024

Wow. ''The formal semantics of programming languages'' from the MIT series on computing is currently available publicly! Many consider this book as a theoretical computer science classic, so do grab the pdf while it is hot!
🔗👀👇

1
9
847


Thomas Gilray retweeted
7 Nov 2024
Nobody wants to read papers outside their field of study (and, mostly, even inside—that's why we have conferences).
So nominate the papers you read and liked for research highlights to give them a boost outside PL venues.
forms.gle/y8MM2htdCk1QEGez6
Deadline November 21.
7 Nov 2024

Nobody outside PL wants to read 25 pages papers. If we want other people to read our work we need to separate idea and execution and make our work accessible
2
5
30
4,177