
Research group. Universitat d'Alacant, Spain. Artificial intelligence, language technologies, machine translation.
Joined September 2013
- Tweets 35
- Following 72
- Followers 33
- Likes 15
3 Photos and videos



Transducens retweeted

22 Sep 2025
PhD opportunity! 🚨🚨 We’re hiring a 4-year predoctoral researcher to investigate unseen language acquisition in LLMs using resources such as grammar books. Join our supportive, respectful team for this challenging project.
🔗 Details and contact info: transducens.dlsi.ua.es/openi…
2
2
252

13 May 2025
New postdoc 🎓 opportunity! Join the 25-year-experienced @transducens group at the Universitat d'Alacant, Spain, @UA_Universidad under an #MSCA Fellowship 📷 Low-resource language technologies, machine translation, language models, data crawling...📷 euraxess.ec.europa.eu/jobs/h…
1
2
2
118
13 May 2025
Enjoy mild winters 🌞 and summers by the sea 📷 during your 2-year research stay in
@Alicante_City, ranked the second-best city in the world for living according to expats.
39
14 Feb 2025
These days, Felipe Sánchez-Martínez has been in Caifornia presenting our work on generating textual resources for Mayan languages github.com/transducens/flore… at Google's Society-Centred AI Workshop. He’s also engaged with developers of AI for social impact across the planet.
1
3
4
184

3 Feb 2025

It's time for transparent AI in Europe. It's time for open LLMs as a robust foundation for developing future private and public AI services. It's time for:
OPEN = open-source
Euro = under EU regulations, representing EU values
LLM = LLMs
openeurollm.eu

1
1
99
Transducens retweeted

4 Feb 2025
Prompsit, del Parque Científico de la UMH participa en un plan de modelos de lengua masivos de código abierto alicanteplaza.es/alicantepla…
1
1
124
27 Jan 2025
ALIA public AI models just released in Spain partly use one of our datasets 🙂
27 Jan 2025

The dataset PILAR github.com/transducens/PILAR that our @transducens research group at @UA_Universidad @UA_Universitat collected and released in 2024 was included in the training data of the ALIA machine translation models langtech-bsc.gitbook.io/alia… for Aragonese, Aranese, and Asturian, developed by the @BSC_CNS and presented last week by the Spanish Government: alia.gob.es/ 🥳
According to their model cards, the translation models were developed by the @BSC_CNS as part of the Shared Task on Translation into Low-Resource Languages of Spain that we successfully organized last year: statmt.org/wmt24/romance-tas…
Note that we have also contributed our own multilingual model, called IBRO, designed for translation from Spanish into several Romance languages, including Aragonese, Aranese, Asturian, Catalan (Valencian included), and Galician, as well as from Catalan into Aranese. The 1.3B IBRO model huggingface.co/Transducens/I… was publicly funded through the LiLowLa project: transducens.dlsi.ua.es/lilow…
Although the resources invested are significant, greater support from public administrations is essential. ✊🔥 Some impactful measures, like releasing certain public linguistic resources under open licenses, are not especially costly but could have a major impact.
3
45
Transducens retweeted
24 Jan 2025
This morning, we had the pleasure of attending @AyodeleLifted's talk titled "Empowering African Languages through NLP: The Masakhane Project", where she shared the key contributions of the @MasakhaneNLP project in bringing African languages 🌍 into the digital and AI world. A truly inspiring talk that sparked plenty of interaction and engagement from the audience.
Ayodele Awokoya is currently a visiting researcher in our @transducens group, and we’re exploring the fine-tuning of large language models for machine translation involving Yorùbá, combined with data augmentation techniques.
A huge thank you also to @ELLIS_Alicante and @nuriaoliver for their amazing support and enthusiasm in hosting this event in their fantastic facilities! 🙌
This event, coincidentally, aligned with UNESCO’s World Day of African and Afrodescendant Culture, which is celebrated today. 🌟


2
8
18
596
5 Dec 2024
🚨 It's official! @_atoral will join our department in just a few days, thanks to the Beatriz Galindo grants, funded by the Ministry of Science, Innovation, and Universities, to attract talented researchers working abroad. We're so thrilled to start collaborating with him! 🙌🎉
21 Nov 2024

¡Bienvenidos! 👏💪
Incorporamos nuevo talento investigador gracias a las ayudas Ramón y Cajal, Juan de la Cierva y Beatriz Galindo.
Además, sumamos cinco investigadores más con la última convocatoria del Plan GenT de la Comunitat Valenciana.
Más info en s.ua.es/es/H7Me

3
114
Transducens retweeted

5 Dec 2024
¡Enhorabuena! 🙌💪
Investigadores del @DLSIUA han sido galardonados con el prestigioso Google Academic Research Award por una iniciativa que contribuirá a la preservación y promoción digital de varias lenguas mayas de Guatemala.
Más info en s.ua.es/es/KCq8

ALT De izquierda a derecha: Miquel Esplà Gomis, Juan Antonio Pérez Ortiz, Felipe Sánchez Martínez, Víctor M. Sánchez Cartagena, Andrés Lou Ríos.
7
23
1,782
Transducens retweeted
16 Nov 2024
New day, new work to present here at #WMT24 #EMNLP24 in Miami. Today, we're presenting our neural machine translation models developed for the shared task on Translation into Low-Resource Languages of Spain. Read the full paper here: aclanthology.org/2024.wmt-1.…

3
3
13
574
Transducens retweeted
16 Nov 2024
We will also be presenting today at #EMNLP24 #WMT24 the key findings of the shared task on Translation into Low-Resource Languages of Spain. A total of 17 teams from around the world contributed their models for machine translation from Spanish into Aragonese, Aranese and Asturian. Some of them will also be here presenting how they did it. Read the full paper here: aclanthology.org/2024.wmt-1.…

5
9
463
Transducens retweeted
15 Nov 2024
Today at #WMT24 #EMNLP2024 in Miami, I'll be presenting our poster "Expanding the FLORES Multilingual Benchmark with Aragonese, Aranese, Asturian, and Valencian". Joint work of universities and academies: @UA_Universidad, @UOCuniversidad, @AAL_Academia, @academiaaranesa, @ALLA_ast. Aragonés, Aranés, Asturianu and Valencià take one more step into the world of artificial intelligence. Read the full paper here: aclanthology.org/2024.wmt-1.…

4
5
23
945
Transducens retweeted
13 Nov 2024
#EMMLP2024, here I am! 🌴 Already in Miami to present our findings from the shared task on machine translation for the Aragonese, Aranese, and Asturian languages, as well as from the process of including these languages in the FLORES benchmark. Excited to learn and connect in art deco style!

3
15
384
Transducens retweeted
25 Oct 2024
If you hurry, you can still catch my presentation at the 13th Workshop on Natural Language Processing for Computer-Assisted Language Learning (#NLP4CALL), happening in Rennes, France, in just a few hours. I'll be presenting our paper "A conversational intelligent tutoring system for improving English proficiency of non-native speakers via debriefing of online meeting transcriptions." aclanthology.org/2024.nlp4ca… nlp4call2024.sciencesconf.or…
Our chatbot, DeMINT, uses AI to analyze online meeting transcriptions and provides personalized feedback to help non-native speakers improve their English through interactive dialogues. Early results with L1-Spanish/L2-English learners show promise for language learning in real-world settings. Code, datasets, and models on github.com/transducens/demin…
Project funded by @UTTERProject via cascade funding.
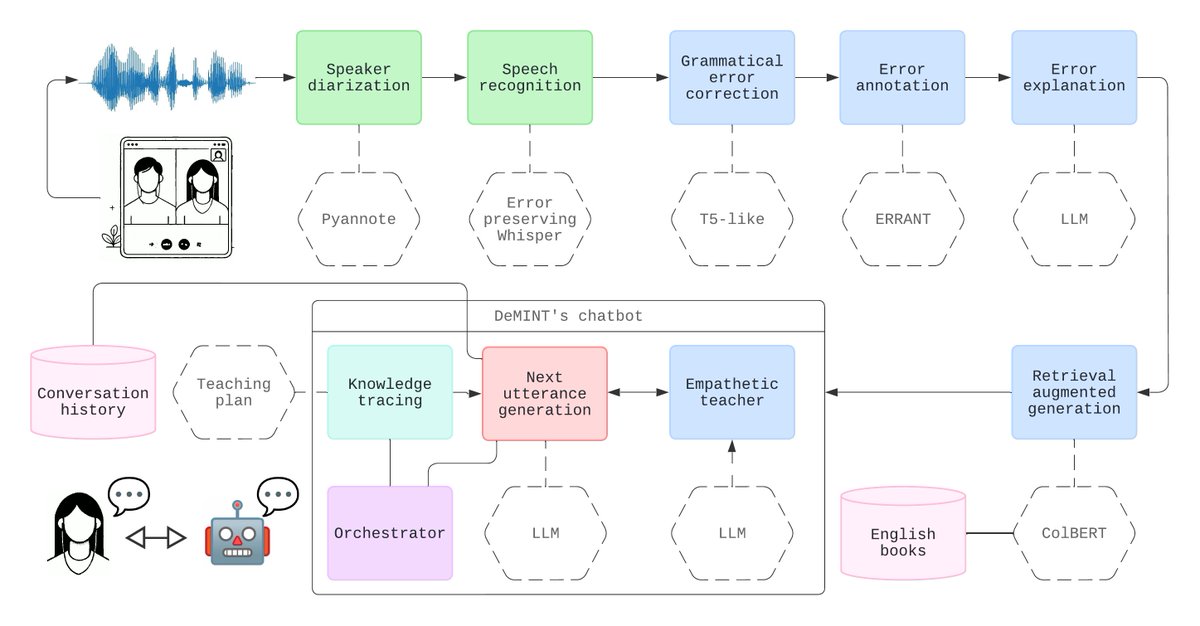
3
4
180
5 Jul 2024
Join the #WMT24 Shared Task on Machine Translation into Low-Resource Languages of Spain
📅 Submission Page Now Open!
ocelot-west-europe.azurewebs…
About the shared task: statmt.org/wmt24/romance-tas…
We look forward to your submission!
#MachineTranslation #NLP #LanguageTech
2
65
3 Jul 2024
We'll be presenting DeMINT's progress at the @UTTERProject User Day this Friday. Funded by UTTER via the FSTP mechanism, #DeMINT is building a chatbot that leverages LLMs to enhance your English skills via conversational analysis of what you said in online meetings.
2 Jul 2024

🔶Join us for out 2nd UTTER User Day!
This event is fully remote and open to everyone!
Don't miss out on insights into multilingual and multimodal LLMs and NLP research.
👉 Register now: [eventbrite.pt/e/936485271657…]
#UTTERProject #NLP #AI #Multilingual #VirtualMeetings

1
2
127
22 Jun 2024
Andrés Lou, representing @transducens @UA_Universidad, met with @INALIMEXICO to initiate a collaboration on the revitalization of indigenous languages in Mexico using AI-based technologies.
20 Jun 2024

¡Difúndelo! 📢
El INALI y la Universidad de Alicante en España, en reunión de trabajo sobre la “Inteligencia artificial enfocada en la revitalización de las lenguas en riesgo”. Dicha presentación la realizó Andrés Lou, de dicha institución educativa.
#MéxicoPluricultural 🇲🇽




1
1
174
16 Jun 2024
Our researcher Andrés Lou will be presenting our contribution to the digital inclusion of Mayan languages at #NAACL2024 @naaclmeeting in Mexico City this week! Meet him at the in-person poster session on June 17th at 14:00. #mayanlanguages
1
1
12
1,532
16 Jun 2024
Read the paper "Curated datasets and neural models for machine translation of informal registers between Mayan and Spanish vernaculars": aclanthology.org/2024.naacl-…
Check the MayanV corpus for 15 Mayan languages: github.com/transducens/mayan…
1
54