
Obsessing over AI and building with it. Open source incl. @ppressdev and Compound Engineering.
Joined January 2007
- Tweets 13,587
- Following 2,562
- Followers 5,383
- Likes 2,184
509 Photos and videos












Pinned Tweet

Jun 12
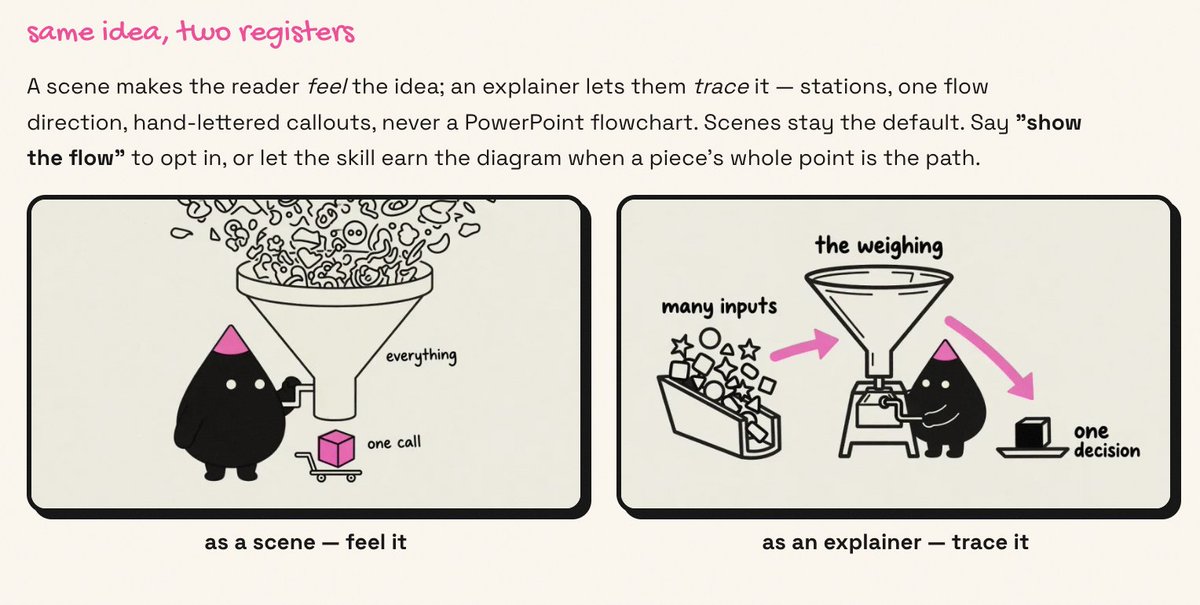
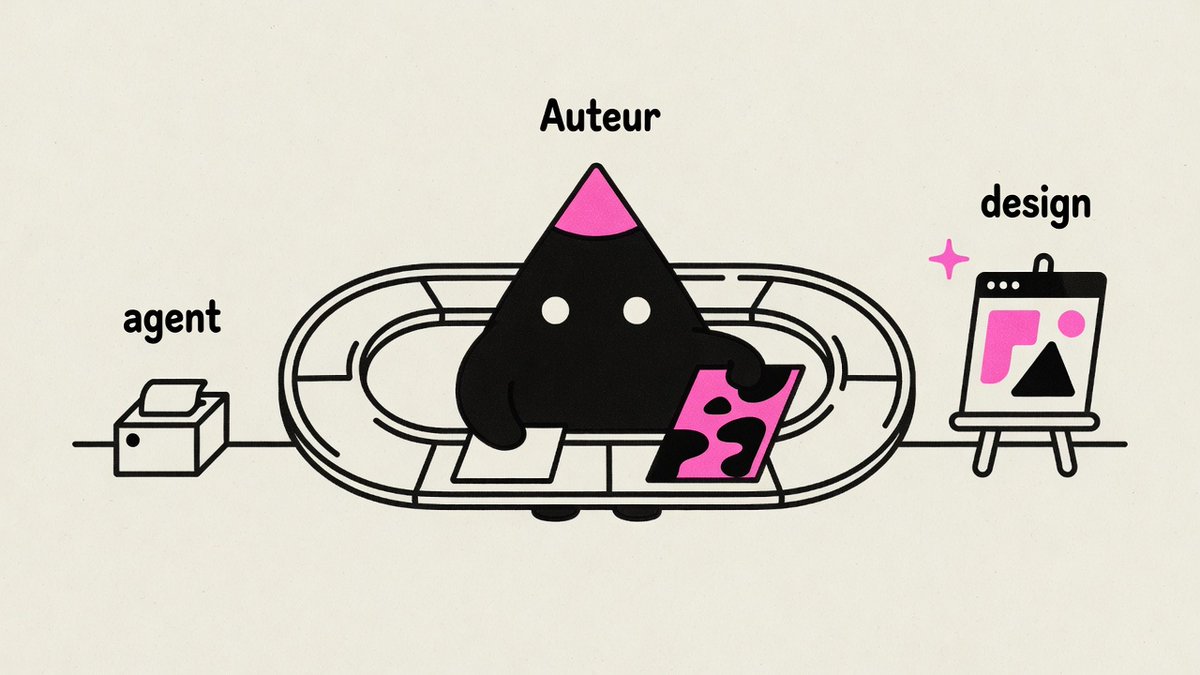
A lot of AI illustration tools can make one good image.
The harder thing is making the 10th image still feel like it came from you.
I create the `illo` skill which uses reference-locked character packs, so your illustrations can have a recurring character instead of a pile of unrelated generations. It has built-in QA and re-rolls new images to improve quality.
Use one of 30 community characters, or build your own.
illo-skill.com
Some examples and details in thread:

16
11
210
54,137
I suspect there’s a meaningful % of people who are so confused by the “Nguyen” part of this joke

Must feel so amazing right now to be a Vietnamese man in NYC named Nicks Nguyen and hearing the whole city chant your name
1
2
450
I just spent 15 mins frustrated as to why so many things were different in my Codex app... then i realized it was the Cursor. How is it possible they all look so similar 🤔
4
4
787
Trevin Chow retweeted

Jun 13
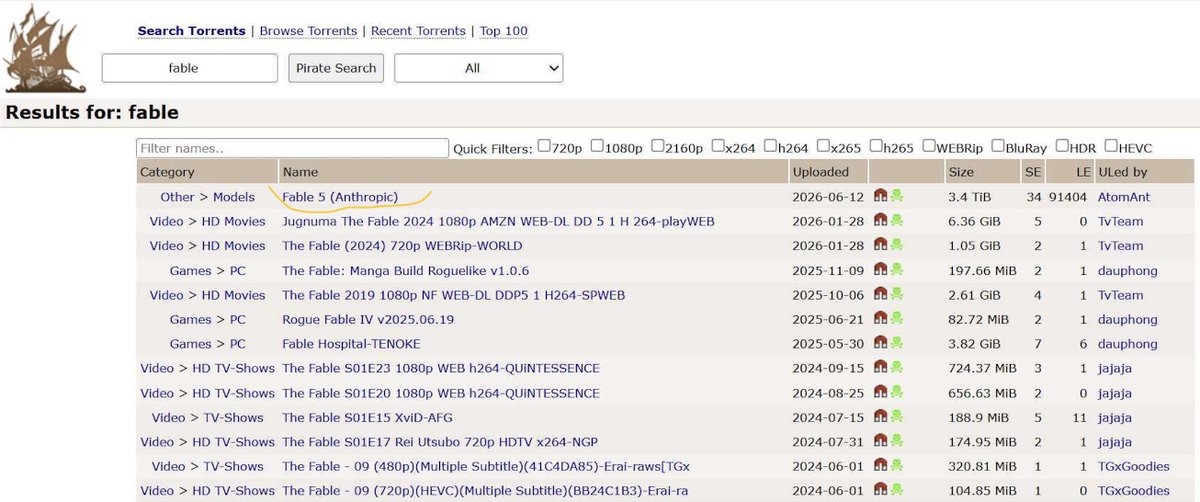
Someone put Fable 5 on the pirate bay, 3.4TB 😂
Community note
A Pirate Bay search for "fable" returns no relevant results, and further, there is no "Other / Models" category as claimed in the screenshot.
thepiratebay.org/search.php?q=f…
304
1,002
21,131
2,504,483
17h
Just setup @viktor__com in a slack instance and to say it was delightful would be an understatement. It’s simply the best out of the box slack agent I’ve tried (and I’ve tried sooo many).
Hermes and OpenClaw can get much more custom, but the amount of tinkering can get out of control, esp in a company context where you're working with diff't permission levels. Viktor for teams, Hermes for solo 🤝
Don’t get me wrong, I’m all in on Hermes for my personal agent but at a company level I think @viktor__com is a much stronger play, at least right now.
Got it up and running for a team in <5 mins chatting in slack then another 30-45 mins getting first set of workflows to report on linear status, granola meeting recaps and sentry integration.
9
16
4,408
19h
I’ve never had ChatGPT or Claude Code offer me a discount. Only Gemini and Grok.
5
1
13
2,334
21h
Other frontier model companies swooping in to take advantage of this insane Fable situ
Jun 13

GLM-5.2 will be available on CodingPlan in a few hours, with open-source release coming very soon!
6
679

Trevin Chow retweeted

Jun 13
4 awesome open-source AI projects:
🔸 /last30days (new search engine)
🔸 agent-skills (full dev skills)
🔸 open-notebook (local notebook lm)
🔸 headroom (save 90% on AI bills)
28
49
728
65,526
Jun 13
Google’s OKF draft is early and very data-catalog-shaped, but i think the more interesting part is how it applies to agent memory systems.
Agent memory shouldn’t become another silo trapping you in some SaaS or open source project with no way out.
It should look more like Markdown with just enough structure that memory systems, data catalogs, wikis, and agents can interoperate.
Plain boring standard formats please.
cloud.google.com/blog/produc…
Spec:
github.com/GoogleCloudPlatfo…
5
1
34
2,675
Jun 13
Jun 13

We've reset 5-hour and weekly rate limits for all users.
7
369
Jun 13
Uhhh…. I do not like this timeline.
Jun 13
As a result of a US government directive, we are suspending access to Claude Fable 5 for all users. You can continue to use all other Claude models.
Here’s what this means for you:
Across Claude products, new sessions will run on your selected default model or Opus 4.8, and existing Fable 5 sessions will end with an error.
On the Claude Platform, requests to Fable 5 will also return an error. Please update your integrations to other Claude models.
We know this is a disruption to your workflows; we appreciate your patience and support.
2
1
11
1,013
Jun 13
illo 0.21.0 can now generate images using gpt-image-2 with your Codex subscription!
OpenRouter still works when you to try different models.
if you installed via agent skills framework, run:
`npx skills update illo`
if you installed using a plugin, it should auto update (but you can also force one).
OpenClaw and Hermes? Just ask them to update the skill 🙂
Thanks to @kunchenguid @iamBarronRoth for pushing for this!
🌐 illo-skill.com
⭐️ github.com/tmchow/illo-skill
2
2
16
1,033
Jun 12
DeepSWE would be useful, but I’m more interested (at least rn) in the boring agent-workflow tests:
does it waste fewer tokens?
make fewer bad tool calls?
recover better after a wrong turn?
leave better receipts when it fails?
this is what i fear most about using cheaper coding models
Jun 12

Nearly frontier open source coding model. Congrats to the Kimi team.
I would love to see this tested against DeepSWE

4
547
Jun 12
This seems like it's exactly the right shape for coding agents.
Not “agent in the editor, good luck”
Issue gets filed.
Agent investigates.
Receipts stay with the task.
PR shows up in the same workflow.
Human reviews the actual handoff.
boring made exciting bc of results and visibility.

Linear Agent can now write code.
We put it to work, automatically fixing bugs as they land in triage.
Igor, the engineer behind these automations, shares how he set them up.
linear.app/now/linear-agent-…
2
1
18
4,217
Jun 12
interesting discussion about model vs harness and the focus of these frontier AI companies.
Jun 12

want to point out a few really interesting things here
1. Claude Code is actually the worst performing harness when using the same model, significantly behind opencode and cursor cli
this is the core reason i've been against the LLM companies focusing their business on locking people into their harness
what they are good at is making great models. they suck at making good harness products, just like how power plants won't make the best dishwashers, and how internet providers won't make the best phones
if anthropic wants to do what's best for their users, they should let people use their subscriptions in whatever harness they choose, not locked into claude code alone
2. fable 5 max is only 1pt above gpt 5.5 xhigh (77 vs 76)
this matches my experience so far - fable 5 does have the big model smell and it's pretty good, but it's not a massive jump forward like their marketing suggested, at least not on building software
this is actually alarming for anthropic because it's very unlikely people will want to pay 2x higher cost for the 1pt difference. my speculation would be that in enterprises people will be restricted to adopt fable & mythos only on some mission critical tasks, not used at scale

2
4
2,194
Jun 12
illo update, two things:
1. the skill moved to its own repo → github.com/tmchow/illo-skill. ⭐️ welcomed!
2. it's now a proper plugin — Claude Code, Codex, Gemini CLI, Copilot — which means auto-updates. install once, new looks and fixes just arrive.
already running illo? old installs still work but they're frozen on the old path. paste this at your agent and it'll sort itself out:
"illo moved repo to tmchow/illo-skill. if an illo install from tmchow/agent-skills exists here, remove it, then reinstall using the repo instructions.
🎨 illo-skill.com
Jun 12

A lot of AI illustration tools can make one good image.
The harder thing is making the 10th image still feel like it came from you.
I create the `illo` skill which uses reference-locked character packs, so your illustrations can have a recurring character instead of a pile of unrelated generations. It has built-in QA and re-rolls new images to improve quality.
Use one of 30 community characters, or build your own.
illo-skill.com
Some examples and details in thread:
8
1
74
10,322
Jun 12
uses Three.js to create an interactive firewood splitting experience. so cool @shapiro500! 🪓 🪵 screen.toys/firewood/
7
315