
The @huggingface community effort for science.
Joined November 2025
- Tweets 42
- Following 8
- Followers 278
- Likes 104
Photos and videos
Hugging Science retweeted

Jun 11
Together with UC Berkeley we are announcing the laser phase plate - a breakthrough in atomic resolution imaging. This is the brightest continuous wave laser in the world, 100 million times the intensity of the surface of the sun.
Phase contrast plays an important role in microscopy, but it was thought close to impossible for electron microscopy, where it would require interfering with an electron beam. Holger Mueller and Robert Glaeser proposed exactly this using a standing wave laser. It has taken over 15 years to make this a reality. Biohub partnered with UC Berkeley and Mueller to support this work and to engineer and build the technology.
Contrast has been the critical barrier to achieving atomic resolution imaging of the cell. In cryo-electron tomography, a cellular imaging technology that uses electron microscopy, the low contrast makes it impossible to resolve anything but the largest proteins within their cellular context. The laser phase plate removes that barrier.
With advances in AI this breakthrough in contrast will start to open up a new frontier in structural biology, that will allow us to see the molecular machines of the cell, and how they assemble into far more complex and dynamic systems, and understand how they work.
85
525
3,668
565,224
Hugging Science retweeted

Jun 9
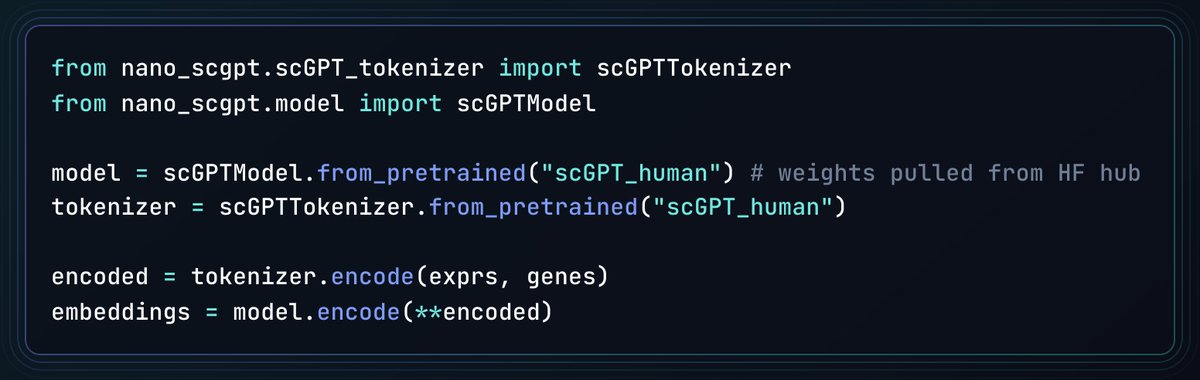
Use nano-scGPT to compute SOTA cell embeddings in just 6 lines of code, now available on @huggingface @huggingscience.
nano-scGPT isn't an inference wrapper, it's scGPT reimplemented from scratch. Finetuning and pretraining are coming next! Let me know what models/tasks you'd like to see next.
Jun 2

Just 6 lines of code to run scGPT.
I built nano-scGPT, the simplest implementation of single-cell foundation model scGPT (by @BoWang87, @HAOTIANCUI1), inspired by @karpathy's nanoGPT and @ChrisHayduk's minAlphaFold2. Written in pure PyTorch (~270 loc for model, ~230 loc for tokenizer) with minimal dependencies.
nano-scGPT produces embeddings numerically equivalent to the original while running 1.38x faster, mostly from a clean forward pass plus torch.compile.
The hope is to get more people up to speed with bio/cell AI/ML, which is arguably the most exciting AI/ML field right now, and to make bio foundation models like scGPT much more accessible to run, understand, and tinker with!
1
1
3
122

Jun 12
on hugging science: kimina-prover ✍️
rl-trained model that writes formal lean 4 proofs for olympiad-level maths. machine-checkable, not just "showing working". 7b distilled preview, open on the hub.
huggingface.co/AI-MO/Kimina-…
32
Hugging Science retweeted

Jun 10
Also big thanks goes to @huggingface for enabling open source AI and AI4science. we have been using HF for the longest time and our family of highly performant fMRI foundation models (CortexMAE) is available on HF along with the training dataset. @cgeorgiaw
1
2
22
10,536
Hugging Science retweeted

Jun 2
We’re excited to share the full binder design protocol. Check it out here: github.com/Biohub/esm/blob/m….
The notebook includes support for @modal to easily scale up binder generation.
Give it a try and let us know how it works!
You can read more about ESMFold2, ESMC, ESM Atlas, and the full results in the paper here: biohub.ai/papers/esm_protein….
3
24
81
21,480
Hugging Science retweeted

Jun 1
huge for getting medical data ACTUALLY used by the machine learning community
All publicly funded science should be open source 🔥🔥🔥

Hugging Face is the home for AI & ML across every domain, including biomedical!
The @NIH just added the @huggingface Hub to its official list of Generalist Repositories for data sharing.
NIH-funded? You can point to the Hub in your data sharing plan 🤗
6
13
91
18,083
Hugging Science retweeted

Hugging Face is the home for AI & ML across every domain, including biomedical!
The @NIH just added the @huggingface Hub to its official list of Generalist Repositories for data sharing.
NIH-funded? You can point to the Hub in your data sharing plan 🤗
5
23
76
27,737
Hugging Science retweeted

May 29
Opus 4.8 just dropped and I ran it through our CAD tasks. 4.6 → 4.7 → 4.8 side by side.
The results are unexpected!
198
193
3,533
707,670
May 29
on hugging science: mattergen ⚛️
generative ai for materials. you give it a target property, it proposes novel inorganic crystal structures to match. inverse design instead of screen-and-pray.
built for energy, catalysis and functional materials research. weights on the hub.
1
5
122
Hugging Science retweeted
May 27
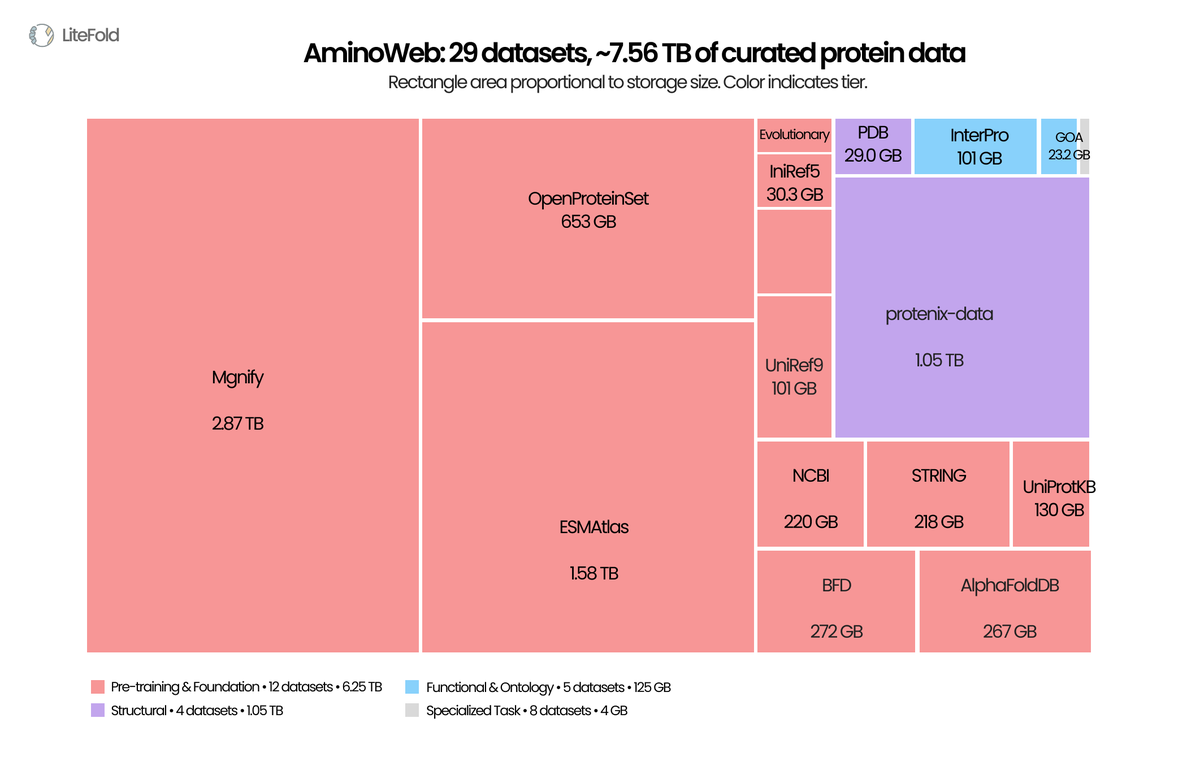
today was a massive day for protein engineering.
esmfold2 dropped—next gen of the esm series, fully open on @huggingscience. 1.1 billion predicted structures, 6.8 billion sequences. 800m more entries than the alphafold db, and reportedly edging out alphafold3 on protein complexes, including antibody–antigen binding.
alongside it: the new esm atlas. a huge expansion of known protein space, heavy on metagenomic sequences from soil, ocean, and the parts of biology that have been least characterised (until now!!)
and if that weren't enough, litefold dropped the fineweb of proteins, so every major protein database (pdb included) aggregated, cleaned, and made plug-and-play in one place.
these are the releases that push the whole field forward, and the pace of open science right now is almost motion-sickness inducing
all of it on huggingscience.co (and ofc @huggingface)
9
75
347
36,067
Hugging Science retweeted

May 21
What can a DNA foundation model actually do?
We got this question a lot after releasing Carbon, our new DNA model. Here are three things it does.
🧬 All live in our demo: huggingface.co/spaces/Huggin…
5
19
85
17,519
Hugging Science retweeted

May 20
📣 Announcing Terminal-Bench Science: benchmarking AI agents on real scientific workflows – now open for task contributions👇
tbench.ai/news/tb-science-an…
@AnthropicAI, @OpenAI, and @GoogleDeepMind use Terminal-Bench to evaluate AI on coding tasks. We're now extending it to scientific workflows.
1/6🧵

16
111
495
905,348
Hugging Science retweeted
May 19
Introducing Carbon 🧬 a family of open generative DNA foundation models. Carbon-3B matches Evo2-7B while running 250x faster at inference. It can generate new DNA sequences and score the functional impact of mutations, zero-shot.
We borrowed a lot from how modern LLMs are trained, but DNA isn't language. Genomes are noisy, redundant, and shaped by evolution rather than communication. So we adjusted the recipe:
Tokenizer. Most genomic models tokenize at the nucleotide/character level, which blows up sequence length. BPE is the obvious LLM-style fix, but it doesn't behave well on DNA. We use deterministic 6-mer tokens (one token = 6 nucleotides): 6× shorter sequences and cheaper attention.
Training loss. With 6-mer tokens, cross-entropy scores a prediction that gets 5/6 nucleotides right the same as one that's completely wrong. This gets brittle late in training and produces loss spikes. We switch mid-training to a more flexible factorized loss (FNS).
Data. Genomes are mostly sparse, repetitive background. We curate down to a staged functional DNA mRNA mixture, with every ratio chosen by ablation, like mixing a web corpus, but for biology.
We're releasing the models, training data, training code, evaluation suite, and a demo to play with.
More details in the technical report: github.com/huggingface/carbo…
Demo to play with the model, with a biology primer for our ML friends ;) huggingface.co/spaces/Huggin…
16
82
357
39,860
Hugging Science retweeted
May 19
Hugging Science just got a whole lot more huggier 🤗🤗🤗
Today, we’re releasing a family of genomics models, which we call Carbon

8
45
281
19,162
Hugging Science retweeted

Apr 29
Super happy to have this one out. A clean organized up-to-date view of all the science resources (chemistry, biology, physics, materials, math) people have been sharing on the Hugging Face hub: datasets, blogs, models and more
Apr 29

🤗🤗🤗introducing Hugging Science -- the home of AI for science 🤗🤗🤗
open models and datasets are the powerhouse of science (see the PDB), but finding the models and data you actually need for your breakthrough is hard af
you shouldn't need to scrape arxiv, own your own wetlab, fight a custom HDF5 parser, build a fusion stellarator, and beg for compute before you've trained a single epoch
so we're changing that
we've put all the best science on @huggingface in one place:
- 78GB of genomics data
- 11TB of PDE simulations
- 100M cell profiles
- 9T DNA base pairs
- 13M molecular trajectories
- 400k medical QA pairs
and much more, all open, and all ready for training ( you can also now filter and search by domain, task, and keyword)
we've put together all the biggest releases from our partners at NASA, Google, OpenAI, Meta FAIR, Arc Institute, Ginkgo, SandboxAQ, Proxima Fusion, NVIDIA, Ai2, OpenADMET, InstaDeep, Future House, Polymathic AI, LeMaterial, Earth Species Project, Merck, and Eve Bio
if you're not sure where you fit in -- work on open challenges for problems that matter: including fusion stellarator design, ADMET, antibody developability, multilingual medicine, catalysis and materials, and scientific reasoning.
we're already changing how science gets done:
a fusion startup needed a benchmark for stellarator plasma confinement that didn't exist. @proximafusion shipped ConStellaration on Hugging Science: a leaderboard, dataset, and eval metrics, all in one place.
a drug discovery team wanted to predict hPXR induction. OpenADMET put up a blind challenge: 11,000 compounds assayed at Octant, 513 held out, two tracks (pEC50 structure). Anyone in the world can train and submit.
an antibody team at @Ginkgo released GDPa1, a developability dataset for stability, manufacturability, and immunogenicity prediction, with a live leaderboard scoring every submission.
if you know a problem the ML community should be working on, let us know. make a challenge! this is about putting all the tools for solving science in one place. so we can hillclimb!
→ huggingscience.co
7
6
65
15,683
Hugging Science retweeted

Apr 29
AI for Science: this is the new frontier for AI and making progress here will impact all of humanity.
The new Hugging Science site is here to make sure it is open and accessible to every researcher!
Datasets, models, leaderboards, blogs, guides:
huggingscience.co
Apr 29
🤗🤗🤗introducing Hugging Science -- the home of AI for science 🤗🤗🤗
open models and datasets are the powerhouse of science (see the PDB), but finding the models and data you actually need for your breakthrough is hard af
you shouldn't need to scrape arxiv, own your own wetlab, fight a custom HDF5 parser, build a fusion stellarator, and beg for compute before you've trained a single epoch
so we're changing that
we've put all the best science on @huggingface in one place:
- 78GB of genomics data
- 11TB of PDE simulations
- 100M cell profiles
- 9T DNA base pairs
- 13M molecular trajectories
- 400k medical QA pairs
and much more, all open, and all ready for training ( you can also now filter and search by domain, task, and keyword)
we've put together all the biggest releases from our partners at NASA, Google, OpenAI, Meta FAIR, Arc Institute, Ginkgo, SandboxAQ, Proxima Fusion, NVIDIA, Ai2, OpenADMET, InstaDeep, Future House, Polymathic AI, LeMaterial, Earth Species Project, Merck, and Eve Bio
if you're not sure where you fit in -- work on open challenges for problems that matter: including fusion stellarator design, ADMET, antibody developability, multilingual medicine, catalysis and materials, and scientific reasoning.
we're already changing how science gets done:
a fusion startup needed a benchmark for stellarator plasma confinement that didn't exist. @proximafusion shipped ConStellaration on Hugging Science: a leaderboard, dataset, and eval metrics, all in one place.
a drug discovery team wanted to predict hPXR induction. OpenADMET put up a blind challenge: 11,000 compounds assayed at Octant, 513 held out, two tracks (pEC50 structure). Anyone in the world can train and submit.
an antibody team at @Ginkgo released GDPa1, a developability dataset for stability, manufacturability, and immunogenicity prediction, with a live leaderboard scoring every submission.
if you know a problem the ML community should be working on, let us know. make a challenge! this is about putting all the tools for solving science in one place. so we can hillclimb!
→ huggingscience.co
4
4
49
7,363
Hugging Science retweeted

Apr 29
What OpenMed contributes to huggingscience.co:
→ 1,000 clinical and medical NER models
→ PII detection in 9 languages
→ SuperClinical: #1 on the PII Masking leaderboard
→ Privacy-filter-nemotron (OpenAI base, retrained for medical)
Apache 2.0. On-prem deployable.

Apr 29

This is exactly the move. Discoverability of real scientific data models on the Hub has been the missing piece for years.
OpenMed's 1,000 medical models all sit on top of @huggingface infra. huggingscience.co becoming its own destination is overdue and welcome. 👏
5
2
9
661
Hugging Science retweeted
Apr 29
🤗🤗🤗introducing Hugging Science -- the home of AI for science 🤗🤗🤗
open models and datasets are the powerhouse of science (see the PDB), but finding the models and data you actually need for your breakthrough is hard af
you shouldn't need to scrape arxiv, own your own wetlab, fight a custom HDF5 parser, build a fusion stellarator, and beg for compute before you've trained a single epoch
so we're changing that
we've put all the best science on @huggingface in one place:
- 78GB of genomics data
- 11TB of PDE simulations
- 100M cell profiles
- 9T DNA base pairs
- 13M molecular trajectories
- 400k medical QA pairs
and much more, all open, and all ready for training ( you can also now filter and search by domain, task, and keyword)
we've put together all the biggest releases from our partners at NASA, Google, OpenAI, Meta FAIR, Arc Institute, Ginkgo, SandboxAQ, Proxima Fusion, NVIDIA, Ai2, OpenADMET, InstaDeep, Future House, Polymathic AI, LeMaterial, Earth Species Project, Merck, and Eve Bio
if you're not sure where you fit in -- work on open challenges for problems that matter: including fusion stellarator design, ADMET, antibody developability, multilingual medicine, catalysis and materials, and scientific reasoning.
we're already changing how science gets done:
a fusion startup needed a benchmark for stellarator plasma confinement that didn't exist. @proximafusion shipped ConStellaration on Hugging Science: a leaderboard, dataset, and eval metrics, all in one place.
a drug discovery team wanted to predict hPXR induction. OpenADMET put up a blind challenge: 11,000 compounds assayed at Octant, 513 held out, two tracks (pEC50 structure). Anyone in the world can train and submit.
an antibody team at @Ginkgo released GDPa1, a developability dataset for stability, manufacturability, and immunogenicity prediction, with a live leaderboard scoring every submission.
if you know a problem the ML community should be working on, let us know. make a challenge! this is about putting all the tools for solving science in one place. so we can hillclimb!
→ huggingscience.co
55
350
1,806
198,183
Hugging Science retweeted
Apr 17
immaculate community energy last night with the people behind:
> EquiformerV3
> The Well
> NVIDIA Atlas
> Meta OMat
✨✨✨
1
1
17
673