
Genome scientist working for CSIR-IICB. My family, lab, my mental and physical health are my priorities in that order. Mom to Ada, plants.
Joined January 2009
- Tweets 4,602
- Following 634
- Followers 627
- Likes 8,323
65 Photos and videos















Pinned Tweet

1 May 2025
A book of its own kind. A protocol book for Cyanobacteria was long overdue. With frustrations in existing protocols not reliably replicated, we standardized each of these protocols in the lab and have placed them in the book.
1 May 2025

New book from our lab. A comprehensive detailed protocol for Cyanobacteria research. @genomicsLabIICB @tsucheta @CamScholars @CyanoTracker #Cyanobacteria #CyanobacteiaResearch @csir_iicb @CSIR_IND @ASMicrobiology @ICMRDELHI @DBTIndia

3
6
318
Sucheta Tripathy retweeted

Jun 10
You have noticed it. ChatGPT feels dumber than it used to. Your prompts that worked six months ago produce worse results now. The writing sounds flatter. The ideas sound safer. The internet itself feels like it is shrinking. Every article reads the same. Every email sounds the same. Every answer sounds like it was written by the same voice.
You thought it was you. It is not you.
Researchers at Oxford and Cambridge published a paper in Nature proving what is happening. They call it Model Collapse.
Here is the mechanism in one sentence. AI trained on AI-generated data gets dumber every generation until it forgets what real human data looked like.
The internet is filling with AI-generated content. Blog posts. Articles. Reviews. Comments. Social media. AI companies scrape the internet to train the next generation of models. Which means the next generation of AI is being trained on the output of the current generation.
Each cycle loses information. Not randomly. It loses the rarest, most unusual, most creative parts first. The researchers call these the "tails of the distribution." The weird ideas. The unexpected perspectives. The things that made the internet feel human. Those disappear first.
What remains is the average. The safe. The expected. The bland.
Then the next generation trains on that. And loses more. And the next generation trains on that. And loses more. The researchers proved this is not a slow decline. Major degradation happens within just a few iterations. Even when some of the original human data is preserved.
They tested it on large language models. On image generators. On statistical models. The pattern was the same every time. The output converges toward a narrow, flattened version of reality that looks nothing like the original data.
The lead researcher put it plainly. "Large language models are like fire. A useful tool. But one that pollutes the environment."
The pollution is invisible. You cannot see which sentence on the internet was written by a human and which was written by AI. Neither can the AI that is about to train on it. And once the tails are gone, they do not come back. The damage is irreversible.
This is not a prediction anymore. It is a diagnosis.
The internet you grew up on was built by humans writing things no algorithm would have written. Strange, personal, imperfect, alive. That internet is being diluted. One generation of AI at a time. And the models trained on what remains are learning a smaller and smaller version of the world.
Model Collapse is not a technical problem. It is a cultural one. The thing that made the internet worth reading is the thing that disappears first.

1,138
6,389
17,724
2,231,458
Sucheta Tripathy retweeted

Jun 9
GLM-Missense: A fine-tuned genomic language model captures nucleotide-level information overlooked by missense variant impact predictors biorxiv.org/content/10.64898…

1
13
41
3,113
Sucheta Tripathy retweeted
Jun 9
AEGIS: an annotation extraction and genomic integration resource academic.oup.com/bioinformat…
1
8
37
3,095
Sucheta Tripathy retweeted
5 Jun 2025
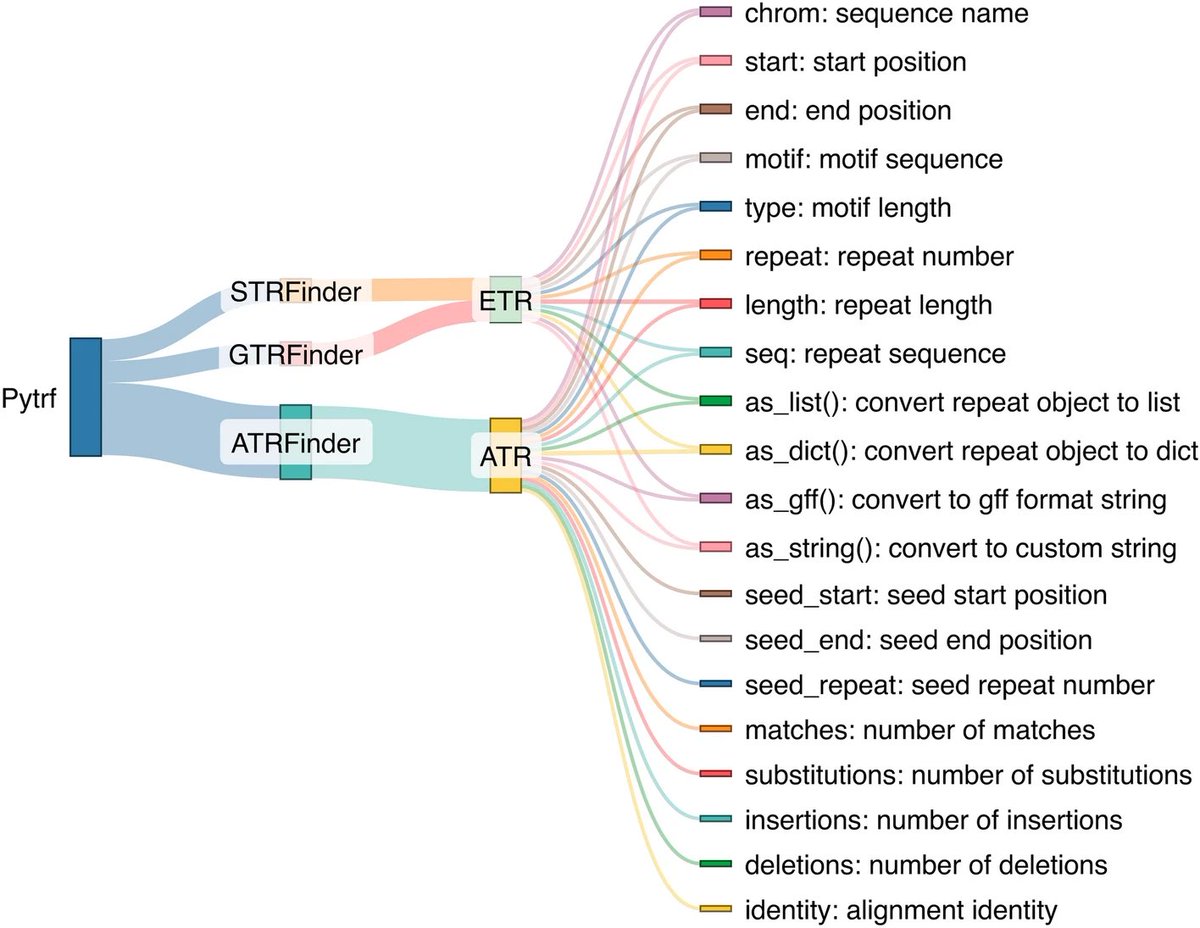
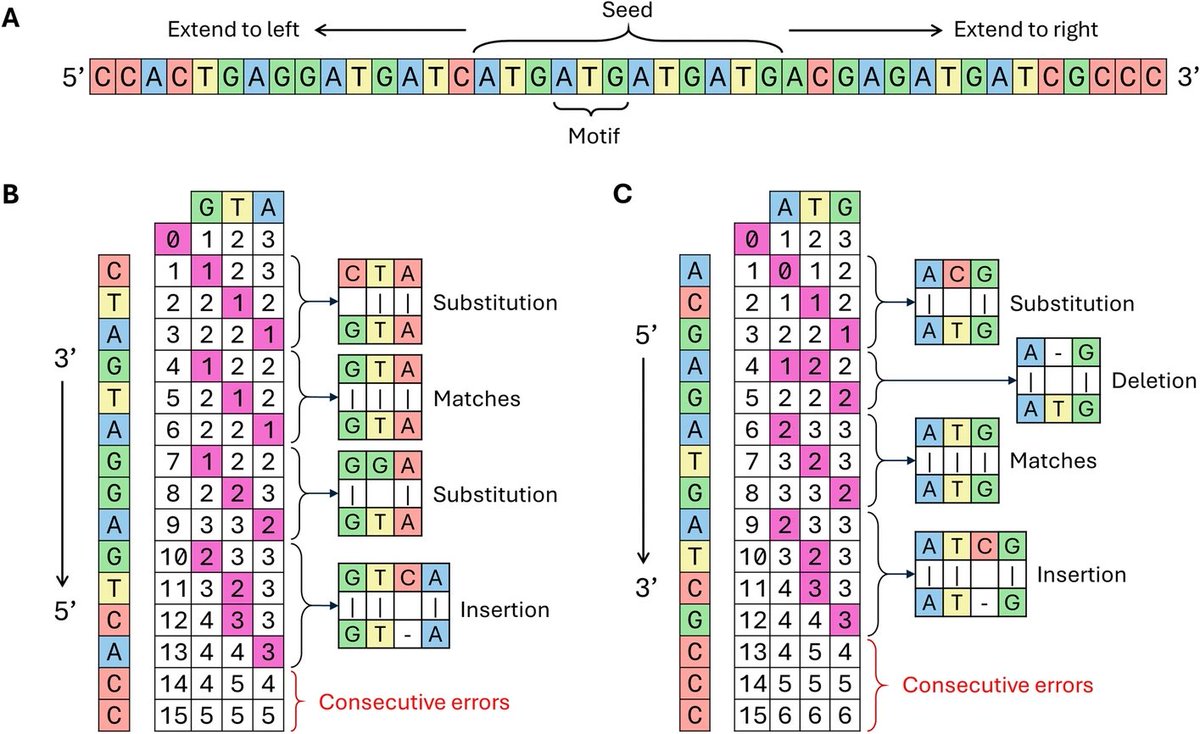
Pytrf: a python package for finding tandem repeats from genomic sequences bmcbioinformatics.biomedcent…
1
32
170
10,029
Sucheta Tripathy retweeted

Jun 7
A PhD's success depends more on the fit between the student, the advisor, and the lab than on the specific topic being studied (it barely matters at all).
Similarly, a lab's success depends more on how excited (or miserable) its researchers are than on the precise project they are working on (it could be virtually anything).
This information isn't in papers or in grant proposals, you have to ask the researchers.
20
150
931
64,117
Sucheta Tripathy retweeted

String manipulation is a critical daily task for bioinformaticians.
Here is a cheatsheet using stringr: rstudio.github.io/cheatsheet…
I probably use stringr::str_replace() once every other day...
to clean up metadata (of course!) #rstats

1
10
66
4,111
Sucheta Tripathy retweeted
5 papers all computational biologists should read 🧵
1. A Quick Guide to Organizing Computational Biology Projects
journals.plos.org/ploscompbi…
4
63
318
23,776
May 29
Many congratulations!
May 28

Our work on Genomic insights and isolation of an antifungal molecules fom Streptomyces sp. B5 journals.asm.org/doi/10.1128…
39
Sucheta Tripathy retweeted

May 28
We should manufacture drugs and vaccines using duckweed.
A few reasons:
- They're the fastest-growing flowering plants.
- Duckweed is up to 45% protein by biomass.
- They grow in wastewater.
- Duckweed can be transformed by "dipping" them into a liquid with plasmids and carbon nanotubes; very simple.
- Both monoclonal antibodies and edible vaccines have been made with duckweeds at small scales for ~two decades.
But there are lots of duckweed strains. We should sequence all of them, pick a strain, and start building better biotechnology tools. There is room for a focused philanthropy effort here (and companies), too.



41
57
503
27,942
Sucheta Tripathy retweeted
May 25
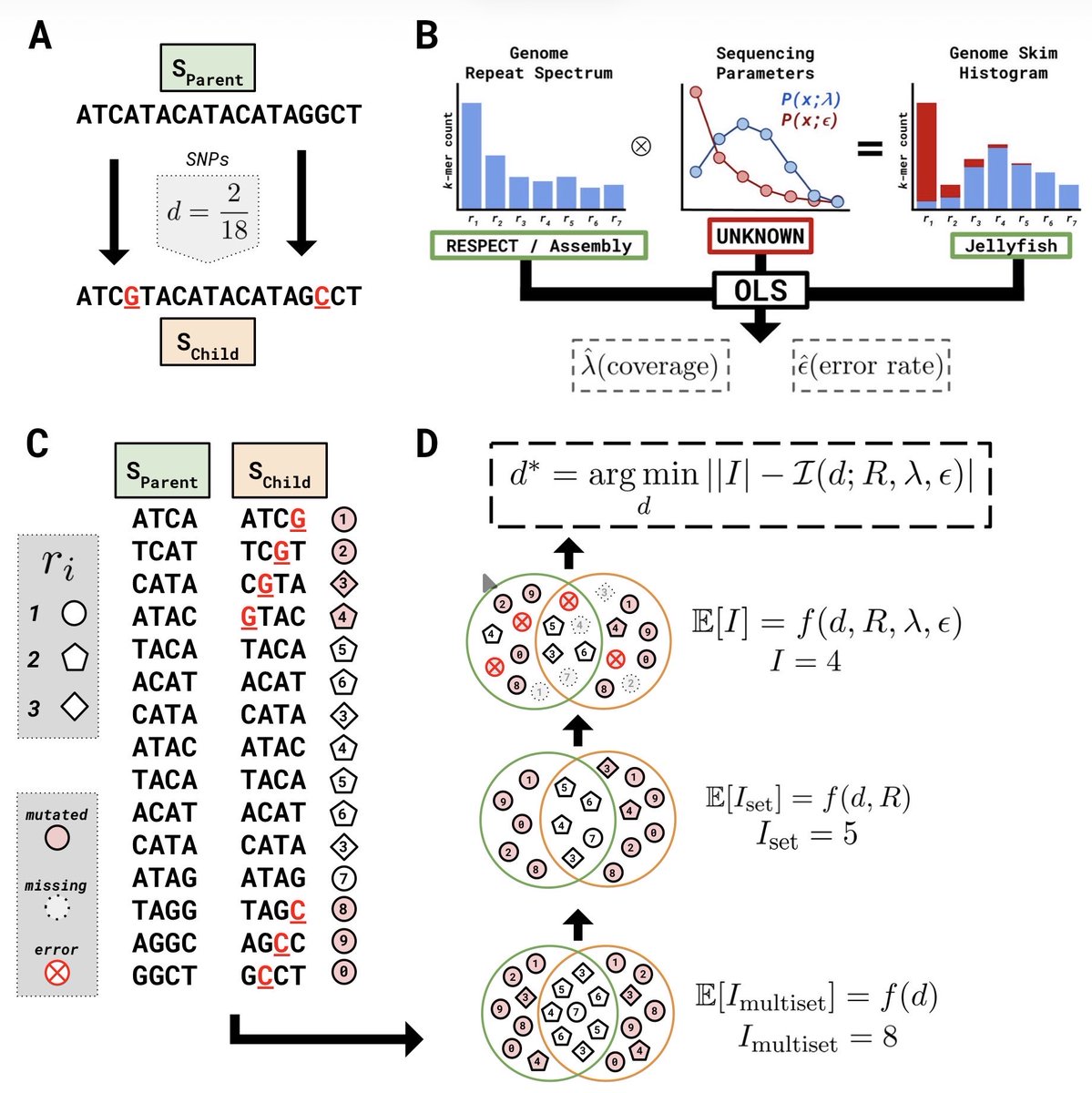
ReSkmer: modeling repeats allows k-mer-based alignment-free methods to calculate population genomic distances link.springer.com/article/10…
1
9
46
2,616
Sucheta Tripathy retweeted

Gene expression can be used to predict age and mortality 🚨
Impressive study from @gladyshev_lab @harvardmed using RNA-seq data to develop accurate transcriptomic clocks across mammalian species (inc. humans) and tissues to predict age, lifespan and mortality. A great example of the power of big data in aging research.
Major processes changing with age include inflammation, mitochondrial function, epigenetic regulation, cell cycle (inc. markers of cellular senescence) and extracellular matrix remodeling.
These clocks will have applications in personalised medicine, drug discovery and clinical trials. They also suggest some degree of coordination of aging changes.
However, many questions remains. Are age-related transcriptomic changes drivers of aging or merely passengers? In other words, if we normalized these aging changes back to youthful levels, would this be beneficial, detrimental, or have no effect?
And with so many aging clocks now available, how will researchers determine which ones are most biologically meaningful and clinically useful?
Link to original paper:
nature.com/articles/s41586-0…
My thoughts on the study:
nature.com/articles/d41586-0…
4
63
260
24,026
Sucheta Tripathy retweeted

May 28
5kg चूना 1kg सफेद सीमेंट 1/2kg फेविकोल 250ग्राम जिंक 100 ग्राम फिटकरी
सबको बाल्टी में अच्छे से घोलकर छत का पेंट करें और घर में लाएं बिना कूलर, AC के ठंडक..!
ऐसा करने से आपके घर का तापमान 45° सेल्सियस से 30° सेल्सियस पर आ जायेगा।
इसके लिए आपकों इस वीडियो दिखाए गए कार्य का अनुसरण करना है जिससे आपको गर्मी से काफ़ी राहत मिलेगी।




46
472
1,220
93,336

May 29
It is appropriate only to an extent that you remember how much is spelled differently than it is pronounced.

People will hate me but Spelling Bee is a pointless contest not because the competition itself has no utility.
Spelling bee simply exists due to the imperfections of the English language.
Can you think of Spelling Bee in Hindi or Sanskrit? Words are pronounced as they’re written.
31
Sucheta Tripathy retweeted

May 27
today was a massive day for protein engineering.
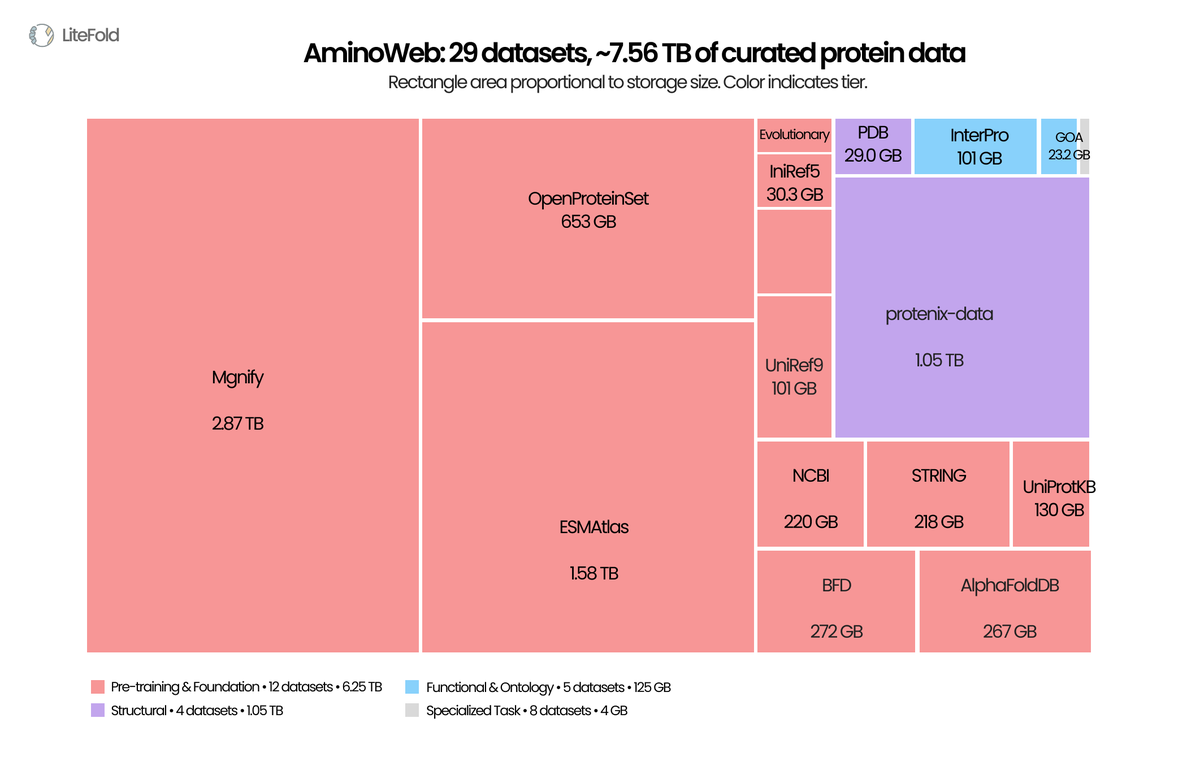
esmfold2 dropped—next gen of the esm series, fully open on @huggingscience. 1.1 billion predicted structures, 6.8 billion sequences. 800m more entries than the alphafold db, and reportedly edging out alphafold3 on protein complexes, including antibody–antigen binding.
alongside it: the new esm atlas. a huge expansion of known protein space, heavy on metagenomic sequences from soil, ocean, and the parts of biology that have been least characterised (until now!!)
and if that weren't enough, litefold dropped the fineweb of proteins, so every major protein database (pdb included) aggregated, cleaned, and made plug-and-play in one place.
these are the releases that push the whole field forward, and the pace of open science right now is almost motion-sickness inducing
all of it on huggingscience.co (and ofc @huggingface)
9
74
347
36,116
Sucheta Tripathy retweeted
May 26
CAPASYDIS: Unveiling the Terra Cognita of Sequence Spaces using Cartesian Projection of Asymmetric Distances biorxiv.org/content/10.1101/…
1
5
22
1,356
Sucheta Tripathy retweeted
May 25
ReSkmer is an update to the Skmer software which utilizes a genome's k-mer repeat spectrum to obtain more accurate distances by modeling the effect repeats have on the intersection of k-mer sets.
1
5
764
May 19
I am not surprised. The pure proteins purchased from some of the fine companies us show multiple bands.
May 17

Guys, this is why companies spend a lot of resources doing rigorous internal testing for protein quality. You cannot trust the claims from vendors, you'll hear plenty of horror stories from people who have been in the industry long enough.
Now apply this thinking to grey market peptides.
29
Sucheta Tripathy retweeted

Many told her: "Even America couldn't solve this. How will you?"
She had a PhD from IISc. 1,700 citations on Google Scholar. A Lab Director role at Xerox AI Research.
None of that mattered. Because she was Indian.
Dr. @geethamhp went ahead anyway.
Today, her non invasive AI technology for early detection of breast cancer is used to screen over 400,000 women across 22 countries. She has more than 39 patents.
Built in Bengaluru. For the world.
The new episode of @mundhebanni is out. Link in first reply. Share it with a woman you love.

8
184
559
15,098