
UCL Deciding, Acting, and Reasoning with Knowledge (DARK) Lab at @AI_UCL led by @_rockt, @egrefen, @robertarail, and @jparkerholder.
Joined July 2020
- Tweets 742
- Following 197
- Followers 4,477
- Likes 816
59 Photos and videos






UCL DARK retweeted

Apr 13
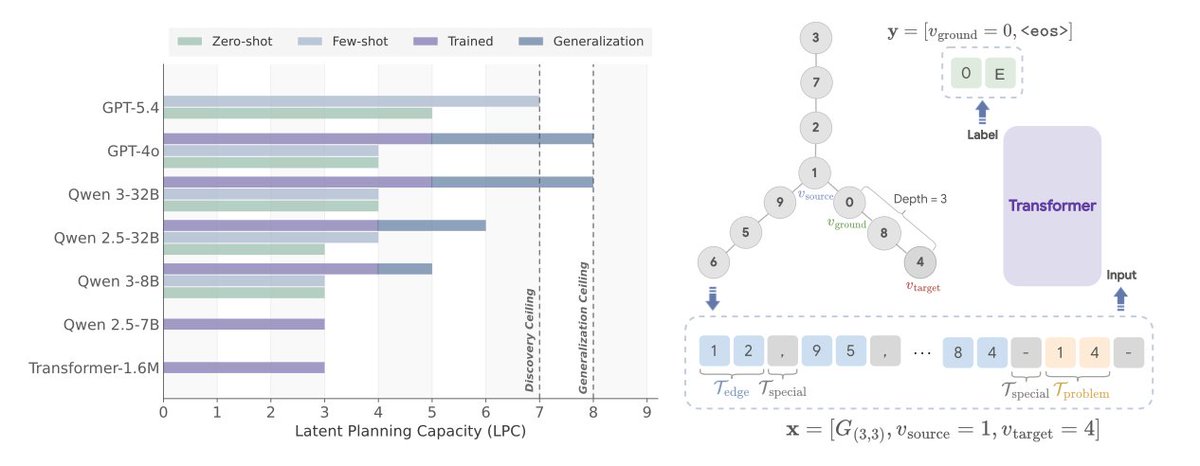
Exciting new finding: LLMs struggle to *discover* a latent planning strategy for a task that is trivial when taught step-by-step.
Scaling helps surprisingly little: from an 8-layer model to GPT-5.4 buys only 4 extra steps.
We argue this is good news, for CoT monitoring ⤵️
6
49
365
41,877
UCL DARK retweeted
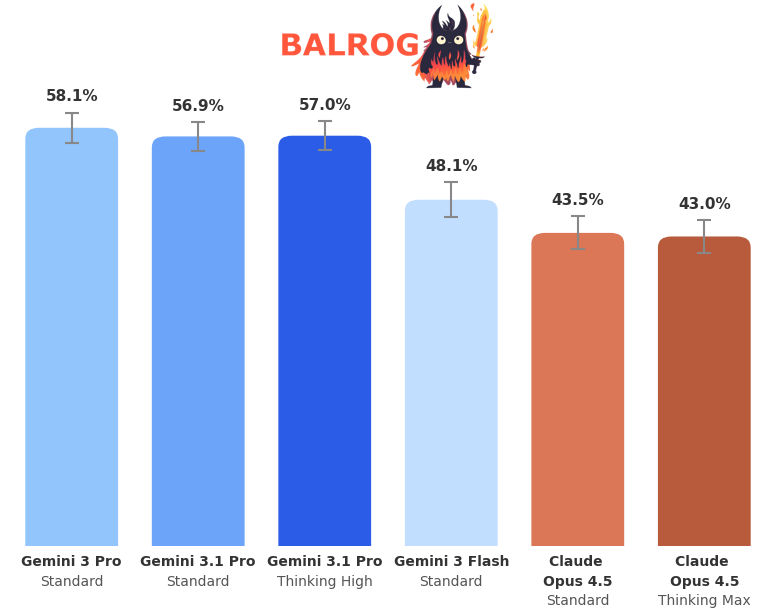
ARC-AGI 3 is about to drop soon. Turns out games were a great benchmark for intelligence all along? 👀
While we wait, BALROG has got you covered. Here are some new exciting results for Gemini 3 Pro, Gemini 3.1 Pro, and Claude 4.5 Opus 🔥
6
7
83
6,824
UCL DARK retweeted
Mar 2
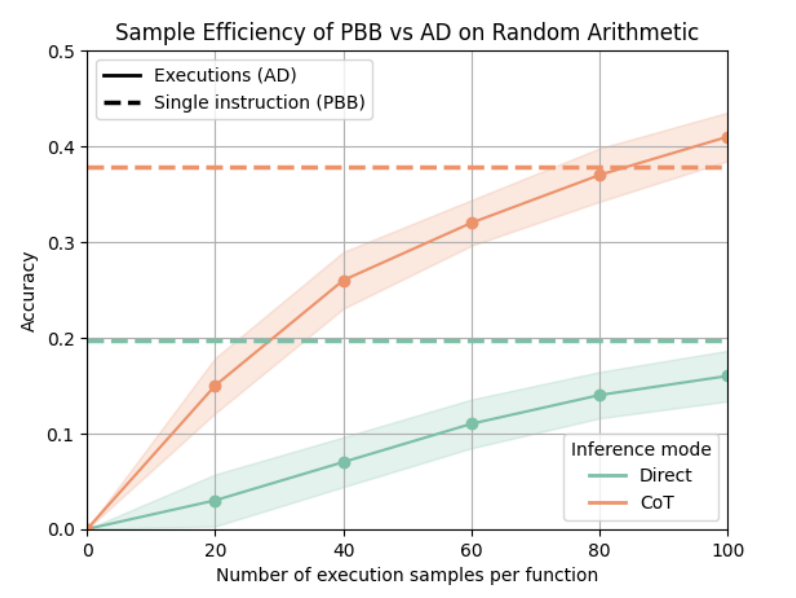
Training on a single piece of code can be as effective as training on 80 CoTs or 100 IO pairs.
PBB got accepted to #ICLR2026 🥳
We added a lot of new results since the preprint ⤵️🧵
Work led by the amazing @JonnyCoook @silviasapora
4
20
116
12,623
UCL DARK retweeted
Result: lightweight, reusable Persona Generators that
• Strongly outperform baselines (static persona datasets prompting baselines)
• Generalize to unseen contexts
• Reach high support coverage (e.g., >80% coverage on held-out test questionnaires in our setup)
We hope this helps enable richer simulations of human behavior and more robust evaluation of multi-agent AI systems.
arxiv: arxiv.org/pdf/2602.03545
Huge thanks to my collaborators and internship hosts @locross , @WilCunningham, @jzl86, Sasha Vezhnevets!
8
4
79
5,652
UCL DARK retweeted
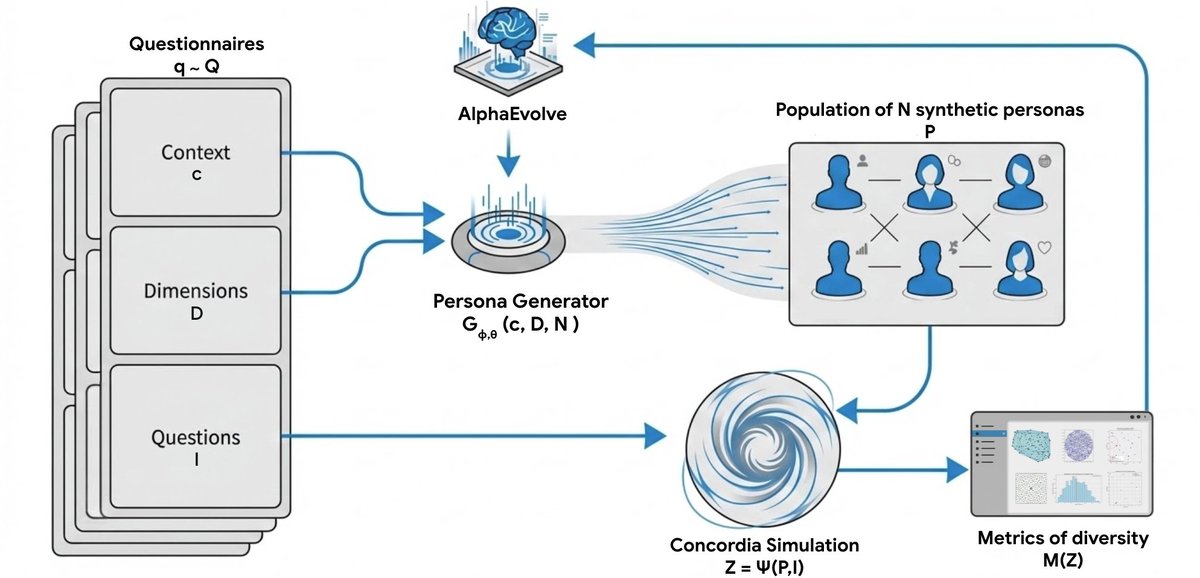
🧬 New paper from my internship at @GoogleDeepMind
We introduce Persona Generators: functions that generate diverse synthetic populations for arbitrary contexts.
We use AlphaEvolve to optimize the generator code, hill-climbing on diversity metrics — not just likelihood — counteracting the mode-seeking behavior of LLM sampling for agent-based simulations.
🧵👇1/
38
126
1,189
106,907
UCL DARK retweeted
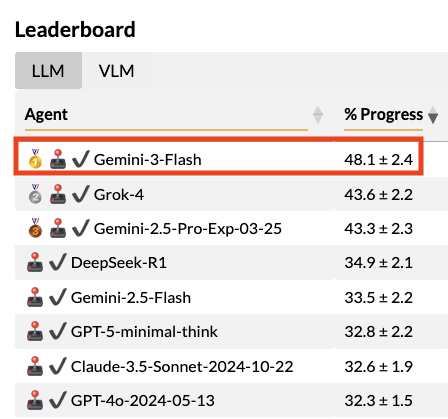
Gemini 3 Deep Think just crushed ARC-AGI-2.
Now its little brother Gemini 3 Flash is smashing competitors on BALROG, and is the new king 👑
A fast, cheap model beating heavyweight, high-cost systems released just last year. Impressive.
5
2
17
1,348
UCL DARK retweeted
Feb 4
My PhD thesis is out 🥳🎓
How do LLMs, trained on trillions of tokens, reason?
Can they generalise beyond their training data or are they constrained by what they've seen before?
My takeaway: they can generalise beyond training in interesting ways, showing genuine reasoning

94
237
1,985
106,385
UCL DARK retweeted

19 Nov 2025
Great to see Gemini 3 improvement over Gemini 2.5 was so significant. Would love to test it on balrogai.com, will it take its crown back from?
If anybody is interested in sponsoring top models on BALROG, please reach out !
2
1
10
2,005
UCL DARK retweeted
5 Nov 2025
Excited to be giving a talk at Princeton this Friday titled *Reasoning in the Time of Scaling*. If you're at Princeton, come through! 👋
Link in thread ⤵️

4
6
130
12,269
UCL DARK retweeted

7 Oct 2025
🎮 How can agents learn to generalize from limited offline data?
We introduce iMac (Imagined Autocurricula) - training agents entirely in world models with emergent curricula!
1
19
75
14,993
UCL DARK retweeted

5 Sep 2025
Almost all agentic pipelines prompt LLMs to explicitly plan before every action (ReAct), but turns out this isn't optimal for Multi-Step RL 🤔 Why?
In our new work we highlight a crucial issue with ReAct and show that we should make and follow plans instead🧵

5
40
172
35,169

"Always reasoning" isn't the optimal strategy for LLM agents! 🧠
Our new work from UCL DARK identifies a "Goldilocks" effect: planning too frequently, or not enough, degrades performance. We show how to train agents to dynamically allocate test-time compute for best results. 👇
5 Sep 2025

Almost all agentic pipelines prompt LLMs to explicitly plan before every action (ReAct), but turns out this isn't optimal for Multi-Step RL 🤔 Why?
In our new work we highlight a crucial issue with ReAct and show that we should make and follow plans instead🧵
3
37
3,292
UCL DARK retweeted
5 Sep 2025
"Always reasoning" (ReAct) isn't optimal for LLM agents! 🧠
Our new paper identifies a "Goldilocks" effect: planning too frequently or not enough degrades performance. We show how to train agents to learn to dynamically allocate test-time compute when needed for best results. 👇
5 Sep 2025
Almost all agentic pipelines prompt LLMs to explicitly plan before every action (ReAct), but turns out this isn't optimal for Multi-Step RL 🤔 Why?
In our new work we highlight a crucial issue with ReAct and show that we should make and follow plans instead🧵
2
19
90
11,925
UCL DARK retweeted
19 Aug 2025
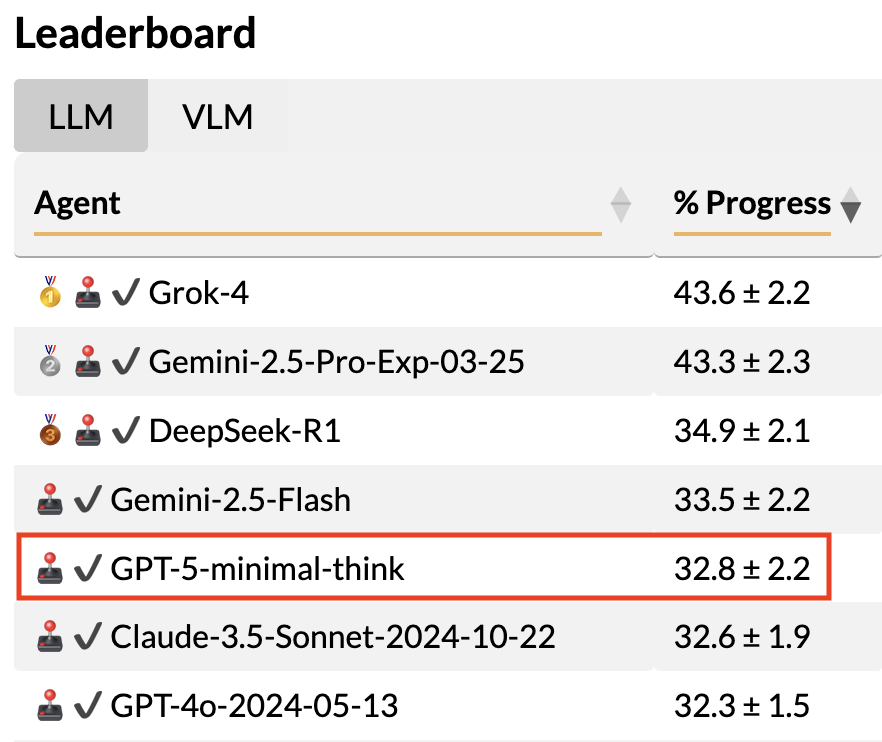
🔥 Oh boy, here we go — GPT-5 enters balrogai.com.
Like everyone, we had sky-high expectations for GPT-5; however, in minimal thinking mode (as close as possible to the base model), it achieves performance comparable to GPT-4o and Gemini-2.5-Flash 🤯
2
4
39
5,839
UCL DARK retweeted

30 Jul 2025
Thrilled to announce Weco has raised an $8M seed led by @GoldenVentures to build self-evolving software!
Our technology has already been used by frontier labs like OpenAI, Meta, Google and Sakana AI.
We’re making every codebase a living experiment that learns to beat itself:

12
13
110
39,427
UCL DARK retweeted
24 Jul 2025
This claim is wrong, this is a screenshot of the balrogai.com benchmark leaderboard, not the IMO leaderboard. Grok 4 did not take part in the IMO competition and did not win the gold medal.

Yep, Grok 4 officially takes the gold! 🥇
Always the new champion, always on top
Grok won the gold medal in the IMO 🏆

1
1
22
3,145
UCL DARK retweeted
23 Jul 2025
Grok-4 barely snatches the podium from Gemini 2.5 Pro, their results being within standard error of each other.
One task where @grok still struggles, is NetHack, barely achieving 1.8% progression on BALROG's hardest task.
For comparison, Grok-4 got 66% on ARC and 15.9% on ARC-2
4
1
54
7,515
UCL DARK retweeted
23 Jul 2025
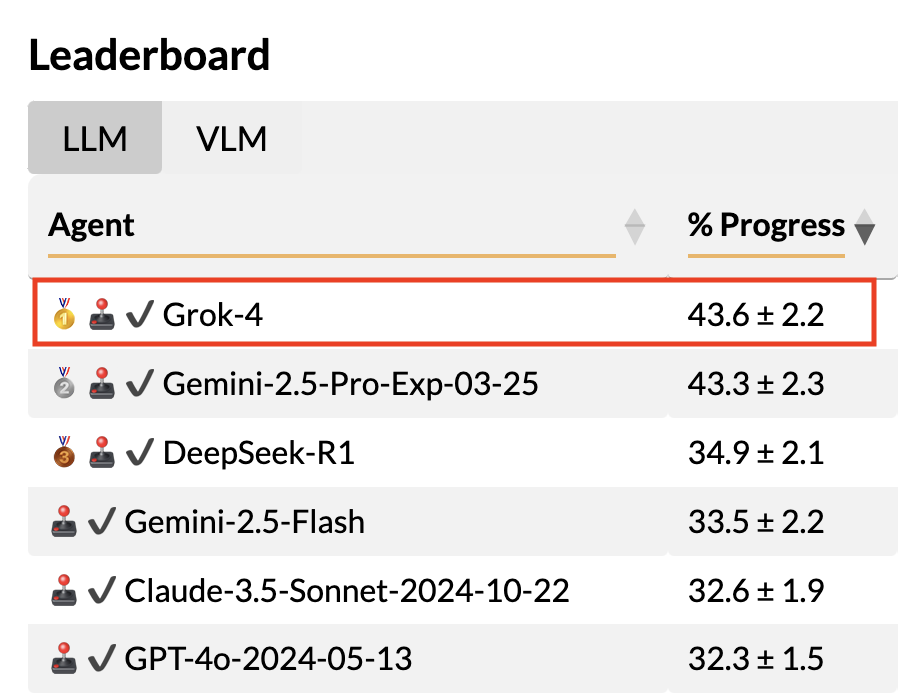
LLMs acing math olympiads? Cute.
But BALROG is where agents fight dragons (and actual Balrogs)🐉😈
And today, Grok-4 (@grok) takes the gold 🥇
Welcome to the podium, champion!
276
495
3,078
1,192,657
UCL DARK retweeted

2 Jul 2025
here is my thesis “Safe Automated Research”
i worked on 3 approaches to make sure we can trust the output of automated researchers as we reach this new era of science
it was a very fun PhD

9
13
212
19,076
UCL DARK retweeted

24 Jun 2025
🧵 Check out our latest preprint: "Programming by Backprop". What if LLMs could internalize algorithms just by reading code, with no input-output examples? This could reshape how we train models to reason algorithmically. Let's dive into our findings 👇
5
19
78
21,021