
A game studio building on-chain games and autonomous worlds 🌎, with @LootRealms, on @ohayo_dojo & @Starknet. Makers of @LootUnderworld and @Pistols_gg
Joined February 2024
- Tweets 936
- Following 411
- Followers 534
- Likes 2,359
179 Photos and videos













Pinned Tweet

26 Sep 2024
The presentation @recipromancer gave at the @ohayo_dojo Demo Day yesterday in NYC. 🧵
We cover Underware, what we've been up to at the @ohayo_dojo residency the past 2 months, our games, and the evolution of @Pistols_gg to today.

4
5
33
3,509

Apr 7
Let's talk about @ParsaBolor. His country is under sanctions and he's still making gains. Imagine what he'd do with a full supply chain behind him.
He's so built that both sides should call a ceasefire just to ask for his program.
2
191
Apr 7
We've had blokes on-chain dodging lead for months and not one of them has worked out how to duck properly. Might have to bring in consultants.

1
1
6
353
Apr 5
Our love language is four stacked @obsdmd panels of unhinged notes. @Hallmark doesn't make a card for this, but they should.
(Ok who are we kidding, our love language is plausible deniability and an extra appendage.)

How it's going.
@karpathy posted about LLM knowledge-bases. Very similar to the LLM Obsidian Brain I'd been working on for a few weeks. Had already built or designed most of the components, and I'm ahead in a number of ways.
My approach is built around rich (but flexible) self-evolving data types (called "artefacts"), either living or temporal. Things like "Designs" and "Reports" that learn from, and document, the things that you do, and make them reusable. This is very powerful.
These artefacts had BEEN the graph. His approach made me realise I needed to rethink my approach to ingestion & graph compilation.
1. An ingestion/graph layer beneath artefacts:
raw input --> ingestion --> granular semantic graph --> THEN produce artefacts.
2. Process input in real time, turn by turn, comment by comment, not by batch. Data (universal, append only) Context & Meaning (subjective, maintained).
3. Artefacts become the layer for humans (and agents) to collaborate. Stuff like, research -> a report -> changes to a design -> an implementation plan.
Attachment:
plan | raw input | processing report | ingested output

2
7
380
Underware retweeted

Looking for usage tracking in @claudeai code?
Got your back:
I audited 12 popular options. Found runtime dependencies, shell injection surface, sloppy credential handling... features over trust.
Then stumbled on a niche 29-star TypeScript option by @canmustgo:
* No runtime dependencies
* Safe file handling (atomic writes, symlinks)
* Input validation
* Protection against shell injection, request hijacking, token leakage, credential leakage, malicious redirects, more
This thing was locked down tighter than a duck's arse (watertight).
The only gap was theming. So I forked it, added theming and 10 nice presets, published it.
You're welcome (with thanks to @canmustgo)
github.com/Rob-Morris/claude…
3
10
424
Mar 26
Our founder built a second brain and mass-produced himself. It ships features, writes content, does research, and remembers where his girlfriend wants to eat.
We just hope she doesn't pick the seafood
restaurant. 🐙
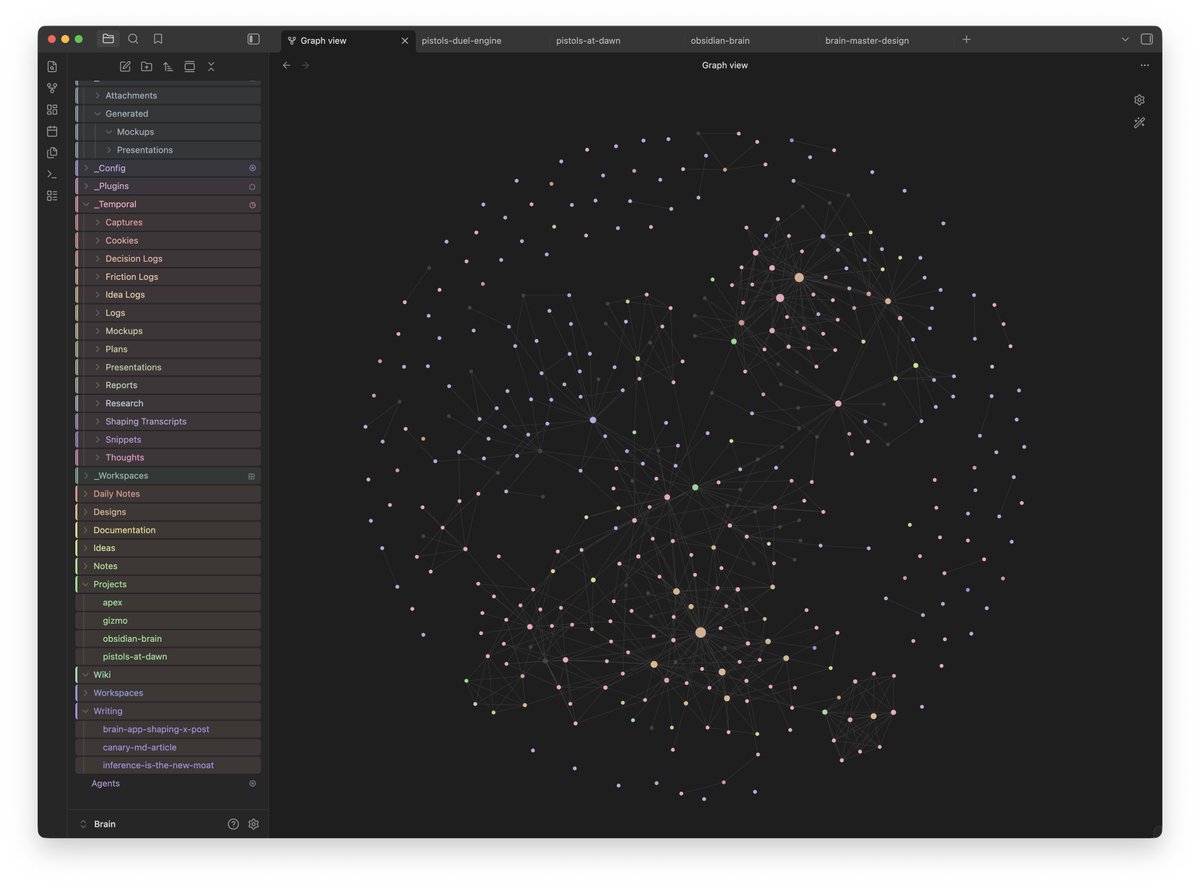
How it's going with my Obsidian second brain:
A lot of things are getting rapidly easier. The system self-extends, and increasingly knows exactly what I want with no explanation. Getting rapidly faster and more reliable.
I'm working on multiple projects simultaneously. On the brain, in the last week alone:
- 77 commits
- 12 major features fully shipped, 7 WIP
- 8 designs in refinement
- 10 major research spikes
Big improvements include:
- One-step agent bootstrap
- Agent context optimisation system
- MCP server & unified CLI
- Multi-vault sync
- Organising work (workspaces, contexts, sessions)
- Content auto-classification & ingestion
- Mockups, presentations; "output" capabilities
- Consumer-grade brain app (mockup & design)
1
172
Mar 21
This is what working in the age of inference looks like. A second brain that extends itself autonomously as you work. @recipromancer has been cooking.
3
186
Underware retweeted

Mar 16
bring the bitcoin economy into your app
in minutes, not months
wallets, gasless transactions, bitcoin yield, defi rails.
one sdk. no blockchain expertise required.
npm install starkzap
51 contributors 1,180 npm installs since Feb 2026.

8
9
55
3,293
Underware retweeted

Both this takedown and those brutal gut punches are about to be recorded onchain.
ONLY people who predicted he'd win are going to collect them, and soon they'll be able to play them as moves in a game.
@Medieval_Tech is changing the way we engage with sports, only on @Starknet
Just watched back Boogie Blake Johansen’s win from San Antonio last weekend.
Absolutely dominant performance. Pumped to get the highlights into the app and collect my Relic next week!

4
4
14
858
Underware retweeted
Imagine a roguelike version of @Pistols_gg where you move around a world and you sometimes encounter opponents you can challenge them to a duel.
Some opponents might not know or care what a duel is and they might ignore you or attack you, obviously if you challenge a rat it’s probably not going to duel you.
But if they are duelists, when you sit Al they want a duel they might agree (or honourably refuse instead of just attacking etc).
If both agree to a duel you go to a duel scene, a platform view. You both walk towards each other, shake hands/tentacles/whatevers, then stand back to back.
You each have ~10 seconds to choose a strategy card that is a combination of tactics and blades (a tie breaker). Blades includes a Handshake option that if you both choose settles the duel peacefully (rendering you both neutral to each for now).
Then the duel begins.
Each duelist takes one step at a time away from each other, each can shoot once with their special antiquated flintlock dueling pistol, and each can dodge once.
For each step there is a visual timer that quickly counts down and if you tap/hit space once you twitch, twice you fire, three times you dodge, and when the timer runs out you both take a step. Actions all occur simultaneously on that step, not instantly.
The twitch - shoot - dodge animations are visible to your opponent.
Once both opponents have shot if you both survive we proceed to the blades round and tie break. If you both choose the same option you both lose, otherwise one wins.
Should @underware_gg build it?

6
8
26
1,153
Mar 18
We wrote am AI style guide for Underware. Sixty-nine rules about semicolons, innuendo budgets, and when it's acceptable to say "eat dirt, you bastard!" (always.)
It covers cheek levels. Yes, cheek levels. Every post requires exactly one exclamation. No, we will not be taking questions about what we were doing instead of shipping.
1
1
2
120
Underware retweeted

Mar 2
throwback to 2024 KBW: a spicy noodle onchain gaming debate.
"A lot of the games we're building now can probably be part of a bigger game later on". only on Starknet.
9
5
41
1,416
Underware retweeted
“And one tentacle to rule them all”
- The Lord of the Tentacles.
1
1
2
99
Feb 20
In order of increasing rarity.
F*ck off big spider: ✅
Nice view of Sydney harbour: ✅
Sword for pest control: ✅
@recipromancer in his @underware_gg: ✅
Ok who are we kidding, the last one is the most common.
Typical night in the @underware_gg Sydney office

5
253
Underware retweeted

Feb 20
Realms are made up of Lords.
Meet Lord @recipromancer 👑
This one ships @Pistols_gg
—
(02:27) First memory as a Lord
(06:40) Appreciation for Loot
(09:24) Becoming #1 $LORDS staker
(10:54) Why @Starknet = winning tech
(17:17) Using a NSFW logo for @underware_gg
7
20
34
1,833
Underware retweeted

Jan 12
Lord Squirrelsworth knows...
Jan 9

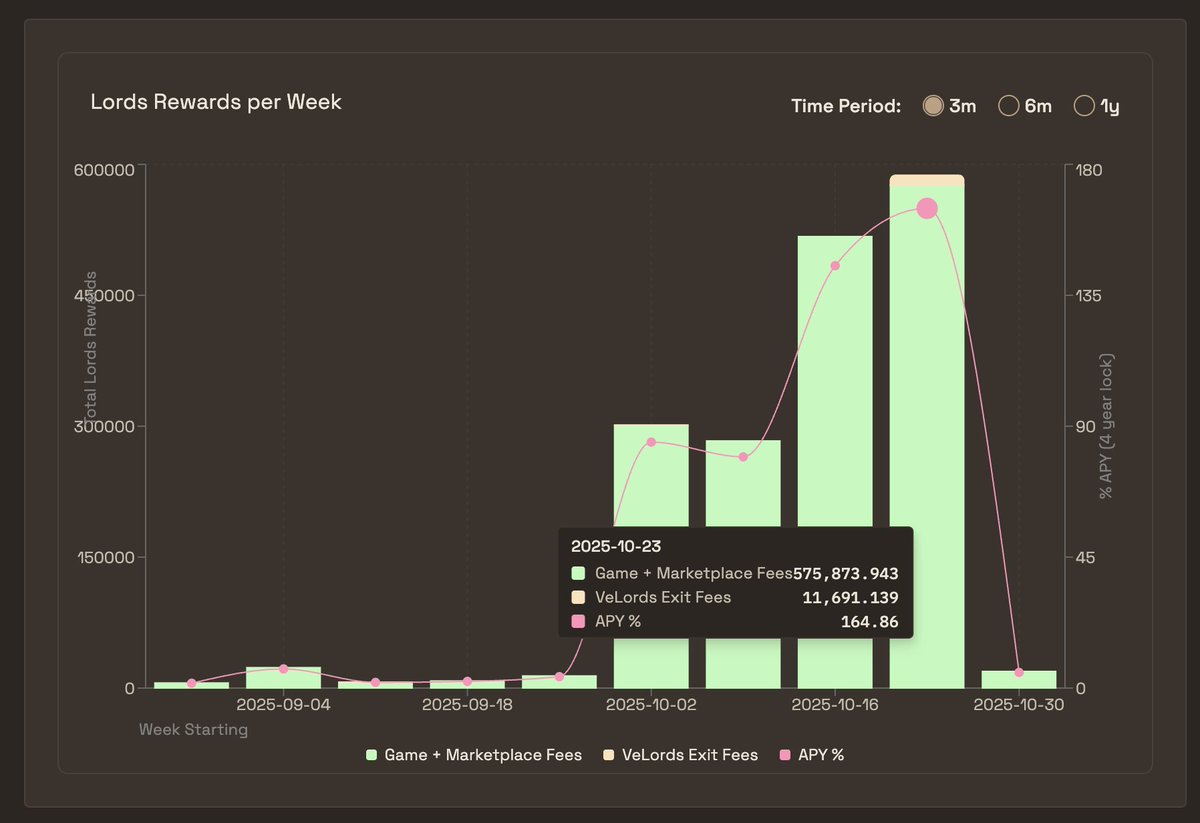
Lords, it's here 🌩️
Blitz S0: The Proving Grounds / Where Legends Rise
- 48 x 2h games (Warrior & Elite brackets)
- Trustless prediction markets
- Over 500k $LORDS 8k Loot Chest rewards
Full details below 🧵

30
26
69
9,616

Underware retweeted
Mood: leaving the @Pistols_gg tavern scene open in the background with the music playing, because I miss shooting you bastards in the back.
2
3
15
367
Underware retweeted
18 Dec 2025
- 1st ever onchain Pub Quiz ✅
- 26 teams/sponsors ✅
- 26 chances to win ✅
Meet the protocols that make @Starknet great and win over $1k worth of rewards, inc. $STRK, @ready_co Metal, $wBTC, $ETH, $USDC, merch, arcade tokens & more...
Set it 👇🏼
x.com/i/spaces/1mrGmBYLkrwJy…
19
26
75
14,601
19 Dec 2025
Not long to go until you mad lot descend on the Fool & Flintlock. We’ve hired extra imps.
17 Dec 2025

Friday plans? Sorted.
Starknet is running an onchain pub quiz Merry Quizmas 2025 🎄
Date: Dec 19
Time: 1:30 PM UTC (2:30 PM WAT)
Hosted by @LootRealms, @StarkWareLtd, @underware_gg, and friends from the ecosystem. Starknet trivia, protocol updates, and real prizes on the line: $STRK, $WBTC, $ETH, $LORDS, plus merch.
25 teams already in. Proper community vibes.
Set a reminder: twitter.com/i/spaces/1mrGmBY…
Tune in via X Spaces on @LootRealms

1
5
266