
A Ph.D. student @sgSMU. My research focuses on improving coding productivity with AI techniques.
Joined November 2016
- Tweets 121
- Following 311
- Followers 169
- Likes 399
3 Photos and videos
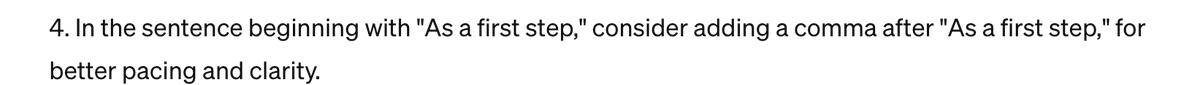





Feb 7
The conclusion of this paper is very interesting. Images may be a more friendly representation for AI to understand source code, since it can be easily compressed to reduce cost. 😃
Feb 4

today most interesting paper: CodeOCR
This work provides a good explanation of how code indentation and highlighting are designed to serve the human eye.
arxiv.org/pdf/2602.01785
1
4
227
22 Sep 2025
How could two ICSE reviewers think my paper is novel while the remaining one think the paper is incremental? It doesn't make sense😮💨
1
110
Zhensu Sun retweeted

25 Aug 2025
java is the most token-efficient language, let that sink in

77
84
3,266
234,755
Zhensu Sun retweeted

24 Aug 2025
Stripping code formatting cuts LLM token cost without hurting accuracy.
Average input tokens drop by 24.5%, with output quality basically unchanged.
The core issue is simple, indentation, spaces, and newlines help humans read but they inflate tokens that models pay to process.
They remove only cosmetic formatting while keeping program meaning identical, checked by matching the abstract syntax tree of the code.
They test Fill in the Middle code completion, where a model fills a missing block, across Java, C , C#, and Python.
Performance stays stable on unformatted input, big models barely move, smaller ones wobble a bit, Python sees less savings because its layout is part of the language.
One surprise, models still print nicely formatted code even when given smashed input, so output token savings are small.
To fix that, 2 cheap tactics work, explicit prompts that say output without formatting, and light fine tuning on unformatted samples.
With clear instructions or tiny training, output length shrinks by 25% to 36% while pass rate on the first try holds.
They also ship a tool that strips formatting before inference then restores it after, so humans read clean code while the model pays less.
----
Paper – arxiv. org/abs/2508.13666
Paper Title: "The Hidden Cost of Readability: How Code Formatting Silently Consumes Your LLM Budget"

8
36
206
13,808
21 Aug 2025
Want to save your LLM budget without sacrificing performance? Here's a useful trick: removing non-essential code formatting, like indentations, newlines, and extra whitespaces, cuts input tokens by an average of 24.5%!
Check out our full study: arxiv.org/abs/2508.13666
1
193
19 Apr 2025
A very interesting match
19 Apr 2025

The humanoid robot half-marathon in Beijing just started!
205
Zhensu Sun retweeted

15 Feb 2025
🚨 Big Announcement! 🚨 We’re thrilled to welcome two distinguished keynote speakers to #FORGE2025!
✨ Prem Devanbu @devanbu (@UCDavis Professor)
🔗 cs.ucdavis.edu/~devanbu/
✨ Graham Neubig @gneubig (@CarnegieMellon Associate Professor )
🔗 phontron.com/
1
3
6
2,326
24 Dec 2024
I'll ride a dog to lab in a near future.
23 Dec 2024

Unitree B2-W Talent Awakening! 🥳
One year after mass production kicked off, Unitree’s B2-W Industrial Wheel has been upgraded with more exciting capabilities.
Please always use robots safely and friendly.
#Unitree #Quadruped #Robotdog #Parkour #EmbodiedAI #IndustrialRobot #InspectionRobot #IntelligentRobot #FoundationModels #LeggedRobot #WheeledLegs
1
270


Zhensu Sun retweeted
10 Oct 2024
🎉 Exciting News! 🎉
We are thrilled to announce that ACM SIGSOFT has officially upgraded FORGE from an ICSE Special Event to an ICSE Co-Located Conference! 🚀 We can’t wait to see your submissions for FORGE 2025!
See more below👇
#FORGE #FORGE2025 @ICSEconf
1
8
22
1,541
Zhensu Sun retweeted

26 Aug 2024
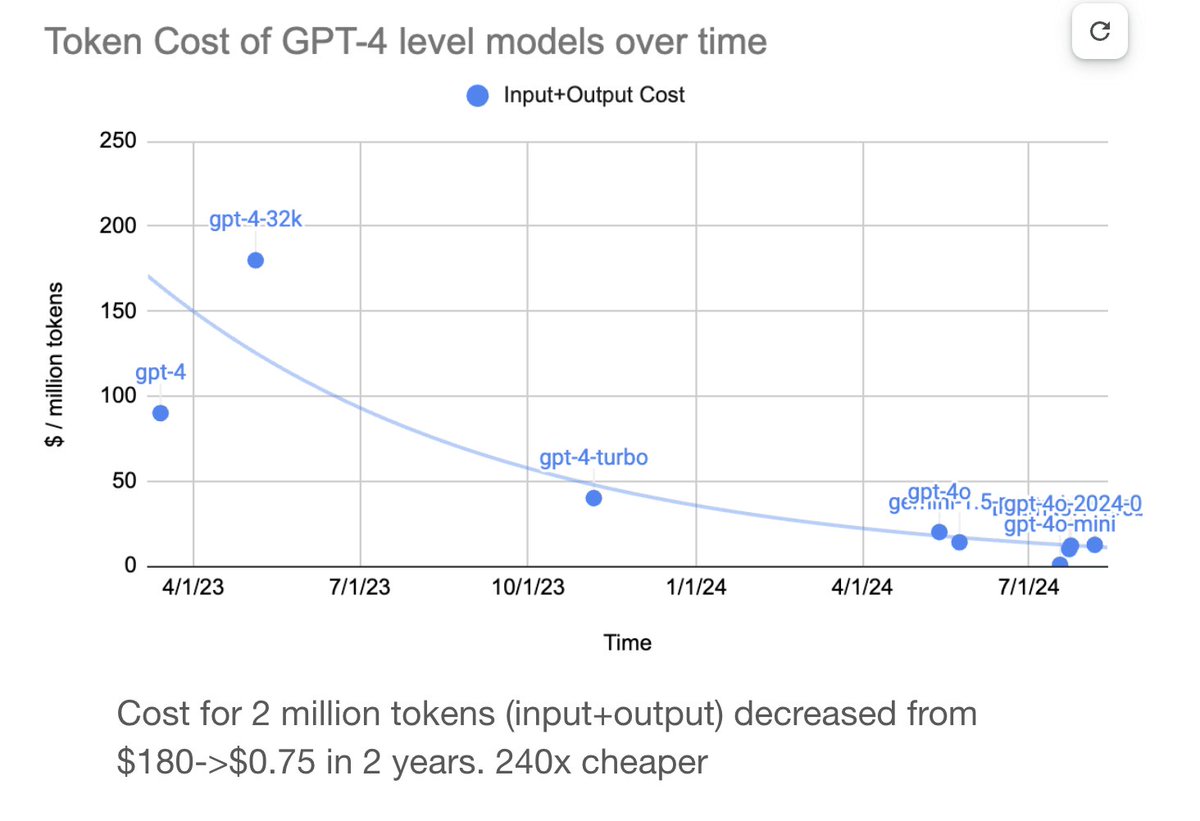
AI is not making any progress"? Look closer. 🙄 GPT-4 level models got 240x cheaper in just 2 years! AI progress isn't linear and is just about bigger models.
BERT -> DistilBERT
Llama 2 70B -> Llama 3 8B
GPT-4 -> GPT-4o-mini
Llama 3 405B → Llama 4 70B?? 🤔
Models get bigger, then smaller but equally powerful. It's a cycle of innovation. Today's quality per $ is the most expensive we'll see.
Making it cheaper will lead to more people using, learning, and building with AI, which might unlock more potential and “goodput” for everyone than yet another Foundation Model!
AI's real progress: Getting into more hands.🤗
[Image credits: @davidtsong]
12
50
248
29,822
6 Aug 2024
Our recent work on self-healing software systems is available at Arxiv now🥳:
[2408.01055] LLM as Runtime Error Handler: A Promising Pathway to Adaptive Self-Healing of Software Systems (arxiv.org)
1
1
197
26 Jul 2024
Impressive
26 Jul 2024

Wow.
@Jandodev just showed me a prompt humans can’t read but LLMs understand this language better.
The San Francisco AI people are designing a new language.
In stealth. You are first to see it.

198
Zhensu Sun retweeted

26 Jul 2024
Wow.
@Jandodev just showed me a prompt humans can’t read but LLMs understand this language better.
The San Francisco AI people are designing a new language.
In stealth. You are first to see it.
366
284
2,575
617,653
Zhensu Sun retweeted

16 Jul 2024
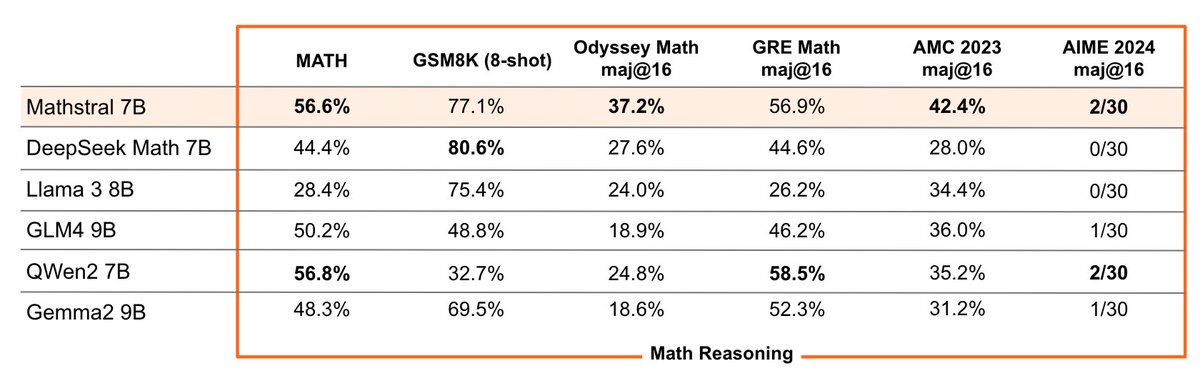
Today we are releasing two small models: Mathstral 7B and Codestral Mamba 7B.
On the MATH benchmark, Mathstral 7B obtains 56.6% pass@1, outperforming Minerva 540B by more than 20%. Mathstral scores 68.4% on MATH with majority voting@64, and 74.6% using a reward model.
Codestral Mamba is one of the first open source models with a Mamba 2 architecture. It is the best 7B code model available, and is trained with a context length of 256k tokens.
Both models are released under the Apache 2 license.
mistral.ai/news/mathstral/
mistral.ai/news/codestral-ma…
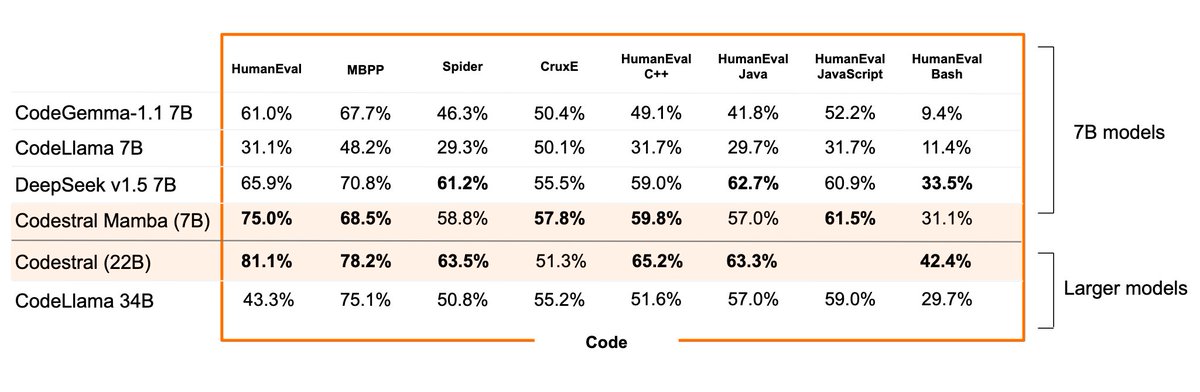

13
103
691
99,210
Zhensu Sun retweeted

6 Jul 2024
"Code is there to explain the comments to the computer." — Andy Harris
4
104
590
48,553
Zhensu Sun retweeted

24 Jun 2024
This is fast. Chrome running Gemini locally on my laptop. 2 lines of code.
269
1,822
20,419
3,046,555
14 May 2024
Every time an amazing AI product is released, I feel afraid and excited at the same time.
13 May 2024

This demo is insane.
A student shares their iPad screen with the new ChatGPT GPT-4o, and the AI speaks with them and helps them learn in *realtime*.
Imagine giving this to every student in the world.
The future is so, so bright.
1
2
365