
Joined November 2016
- Tweets 1,640
- Following 236
- Followers 4,712
- Likes 1,037
116 Photos and videos












Jun 12
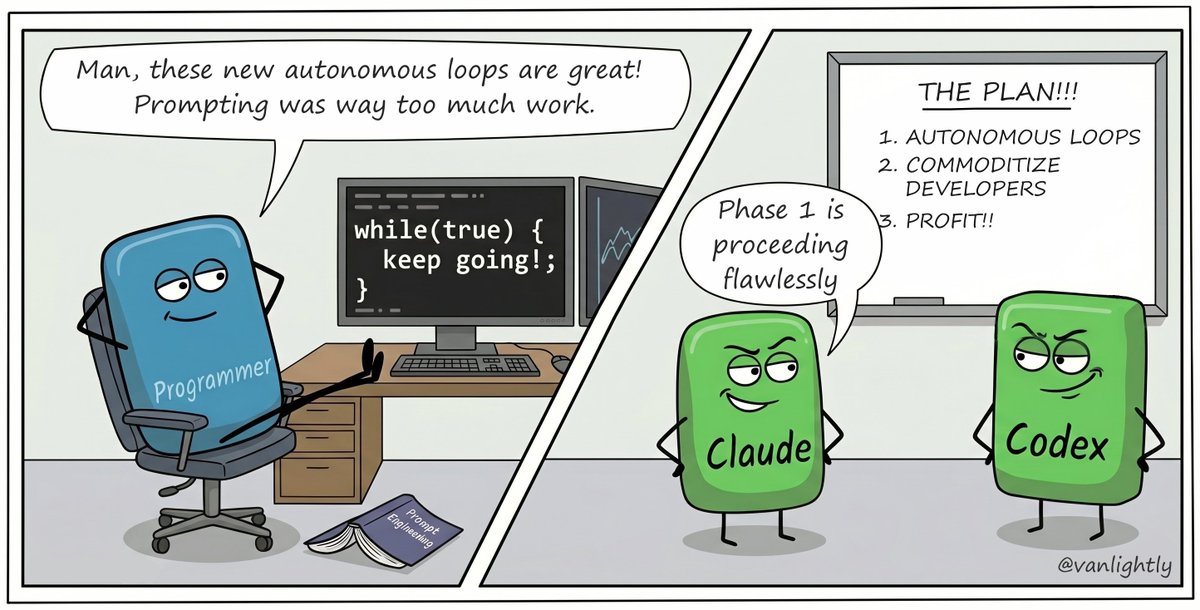
When I'm doing exploratory performance benchmarking work, I often get one puzzling result that doesn't seem to make sense. It's counter intuitive.
This morning: "Why was it significantly faster with one consumer than six?" Sometimes it's tempting just to ignore it as a weird outlier, but curiosity compels you to spend the next two hours pouring over logs and metrics until you find the cause. A mechanistic explanation that is completely logical, and sometimes an unexpected edge case that needs to be dealt with. It's such interesting work, if you're curious and persistent enough.
I'll be adding this morning's findings to my next share groups blog post!
14
1,072
Jun 11
Clever
Jun 10

NEW: malware developers added nuclear & biological weapons text to to their spyware.
Goal? To trigger LLM safety refusals... so that their spyware wouldn't be analyzed by an AI security scanner.
Cleanest practical example I can think of for why over-indexing on first order safety alignment is risky.
When closed (and open) models ship with aggressive refusals, they will be sprinkled with second-order blindspots that attackers will discover...and exploit.
We are only in the earliest days of attackers leveraging these features, and it wouldn't surprise me if users systems that need to handle complex cybersecurity issues demand that models be less safety-blunted.
In the weeds: @SocketSecurity's post also shows why intention matters in how you design a malware analysis pipeline to avoid prompt manipulation.
H/T to colleagues that shared this with me socket.dev/blog/mini-shai-hu…
1
5
988
Jun 11
I tend to write overly detailed blog posts, I can't help it, it's a compulsion. I might be more widely read if I wrote simpler posts, but I in my head "I have to tell all the nuances of what I have some to understand." I hate leaving things unsaid and I'm satisfied with that approach.
Many people may see all the detail and either not read it or skim it. But I bet AI agents read it all. It changes how I think about blogging. I write for myself as the primary beneficiary and others as the secondary. Now everyone just asks AI. AI will probably read my whole blog post (even though it might be too detailed), and use that info to help someone out. That's fine, I get linked as a source.
But it makes me think about marketing. How much in marketing needs now to change to market to AI directly and thus to humans indirectly? It is just like SEO but for agents? Is it just good reference docs? How do well organized reference docs stack up against blog posts written for humans? How are marketing departments in the tech space reacting to this change?
1
9
601
Jun 10
New blog post: Kafka Share Groups and Parallelizing Consumption - Part 3: Client-local parallelism
This post uses the Dimster benchmarking tool to compare consumer groups vs share groups with two parallel processing strategies:
* Blocking: Poll --> Parallel Process --> Commit --> repeat
* Continuous: Decoupled polling, parallel processing and committing
See the results in the post: jack-vanlightly.com/blog/202…
4
26
2,433
Jun 9
This comic is a silly rendition of taking Aiven's topic type idea too far 😁 aiven.io/blog/kafka-deserves…. I’m sympathetic to the idea, especially where the “type” reflects a fundamentally different backend or lifecycle. Moving a topic from classic replication to diskless storage, for example, implies a non-trivial migration with system-managed transition logic. It becomes easier to reason about changing from replication to S3 with a topic type than a collection of configs.
But the idea quickly runs into a boundary problem: which properties deserve to be part of the type? Replication mode, tiering, compaction, Iceberg integration, retention semantics, and backend layout may all be difficult or impossible to change in place. If topic types try to encode every such dimension, we end up with absurd combinatorial names like compacted-classic-tiered-iceberg. If they do not encode these difficult to change aspects, then the type name fails to capture many of the properties that actually constrain migration and operability.
The hard part is deciding whether a type is a semantic abstraction with real lifecycle implications, or merely a convenient bundle of configs. Without that distinction, Kafka risks either name proliferation or topic types that obscure the very operational complexity they are meant to clarify. I’d be very interested to hear opinions on this.
1
781
Jun 8
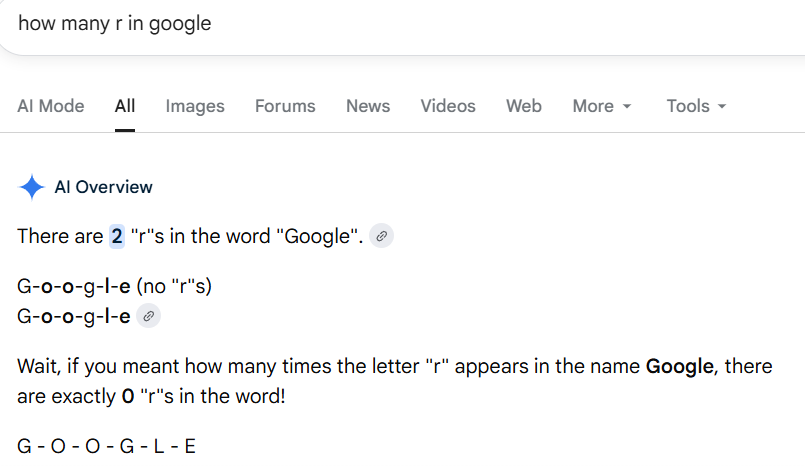
Google seems to now be able to count letters in words. But ChatGPT still has some work:
783
Jun 5

I don't really understand why
- AI systems can generate datasets
- AI systems can generate sophisticated code
- code can trivially count letters in data
- AI systems can compose all of the above
and yet we're still seeing AI systems generating these incredible self-dunks.
2
6
59
5,937
Jun 4
New blog post. Broker-Visible vs Client-Local Parallelism
In my benchmarking of share groups I've been focusing on parallel processing because it turns out that a few settings materially impact how effectively messages are distributed across consumers.
But share groups weren't created solely for the purpose of escaping the confines of the partition as the unit of parallelism. Share groups exist to add queue semantics, which naturally leads to the consumer as the unit of parallelism instead of the partition. But if you are considering share groups solely for escaping the confines of the partition, then this post might be worth a read.
jack-vanlightly.com/blog/202…
2
28
1,710
Jack Vanlightly retweeted

May 29
It May be time … for the May edition of Interesting Links in the Data & AI World!
rmoff.net/2026/05/28/interes…
Thanks to the folk continuing to publish great content that I have the pleasure to link to, including @vanlightly, @VictorRentea, @MichelTricot , @jthandy, @marklit82, @DataMozart, @pdrmnvd, @AMdatalakehouse, @teivah, @jamessewell, @BenjDicken, @shanselman, @croloris, @MikeMcQuaid, and many more :)

2
9
1,046
Jack Vanlightly retweeted

May 27
This is such a good post. orchidfiles.com/im-tired-of-…

82
433
3,158
101,179
May 28
I see a slight improvement

3
849
May 27
New post: Kafka Share Groups and Parallelizing Consumption - Part 2.
Kafka Share Groups make parallel consumption possible within a partition, but tuning them isn’t just about consumer count or max.poll.records (part 1).
In Part 2, I look at how producer batch size, consumer share.acquire.mode and max.poll.records interact to impact the effective parallelism of a workload. We'll take the final workload from part 1 but double the batch size, dropping the target consume rate from 60K msg/s to 37K, then look at options to fix the consumer parallelism.
jack-vanlightly.com/blog/202…
1
1
27
1,325