
Builder
Joined January 2022
- Tweets 2,935
- Following 66
- Followers 245
- Likes 16,438
217 Photos and videos







Pinned Tweet

May 1
My Goal for this month is nothing more than covering this book as if I am prepping for an exam
2
197
One key technique to address tombstones is to understand how the autovacuum process actually works.
every UPDATE or DELETE on an existing tuple writes a new tuple version and sets t_xmax on the old tuple to the XID of the transaction performing the update.
If it's an UPDATE, the new tuple's t_xmin is set to that same XID. t_xmin, here is just the XID of the transaction that inserted (or, in this case, wrote) the tuple. t_xmax is the XID of the transaction that deleted or updated it, zero means no such transaction yet. the XID of the transaction performing the update.
Another concept that brings everything together is the Visibility Map. So, it is just one byte per heap page holding two bits: ALL_VISIBLE and ALL_FROZEN. ALL_VISIBLE set means every tuple on that page is visible to all current and future transactions, no dead tuples to clean. ALL_VISIBLE clear means the page might contain dead tuples or uncommitted rows and needs scanning. The VM's primary purpose is index-only scans: if the planner can answer a query from the index alone and the VM says the page is all-visible, it skips the heap fetch entirely. Without that bit set, every "index-only" scan degrades into index-scan-plus-heap-fetch.
The process of cleaning dead tuples is VACUUM. A naive VACUUM would scan every page sequentially. The visibility map lets it skip that work — pages marked ALL_VISIBLE have nothing to clean and are skipped; pages where the bit is clear get scanned and any dead tuples are reclaimed.
So how does this answer the original question? Autovacuum only runs once a trigger condition is met. To find that trigger, you need two parameters:
1. SHOW autovacuum_vacuum_threshold
2. SHOW autovacuum_vacuum_scale_factor
The trigger formular is,
trigger = autovacuum_vacuum_threshold (autovacuum_vacuum_scale_factor x n_live_tup)
Now, the catch is this by default, autovacuum_vacuum_threshold is always 50, and then imagine in a high-throughput system like a booking application where we have a large state-machine table, we are going to experience a high n_live_tup.
let say we have 50,000 tickets, we are going to be having 50,000 n_live_tup tuples
if SHOW autovacuum_vacuum_scale_factor = 0.2
It implies that auto vacuum will trigger at:
50 (0.2 * 50,000) = 10,050 dead tuples
So, in a high volume system, you have to adjust the 2 factors that triggers auto vacuum by doing this
ALTER TABLE tickets SET (
autovacuum_vacuum_scale_factor = 0.01,
autovacuum_vacuum_threshold = 50
);
so at a scale factor of 0.01 we will have:
trigger = 50 (0.01 x 50,000) = 550 dead tuples
In summary, to resolve these dead tuple issues, just tune based on autovacuum_vacuum_scale_factor, and
autovacuum_vacuum_threshold

Did you know that Postgres doesn't actually delete rows when you run DELETE?
It marks them as invisible to future transactions and leaves the physical row on disk.
That dead row sits there consuming space, bloating your indexes, and slowing down every sequential scan until autovacuum comes to clean it up.
At high delete volume, autovacuum can't keep up.
Your table grows forever, even though the data is "gone".
Run this right now and see how many dead rows are sitting in your most-written tables:
If n_dead_tup is close to or larger than n_live_tup on any table, you have a problem worth fixing today.

1
1
52
Jun 11
"You're allowed to think about the worst case scenario, but you gotta do something about it"
43
Victor retweeted

Jun 10
The World Cup begins tomorrow, and many will watch the matches. Soccer reminds us of something we must not forget: life is not a race to show off on our own, but a path we learn to walk together. Anyone who does not know how to pass the ball, even if they have talent, has not yet understood the game. Anyone who does not know how to live with and for others has not yet understood life. #ApostolicJourney
1,522
15,252
101,963
5,456,650
Victor retweeted

Jun 10
PostgreSQL 19 is dropping a massive quality-of-life feature that is going to kill off a lot of messy backend hacks: WAIT FOR LSN.
If you run asynchronous read replicas, this fixes your biggest consistency headache.
A quick breakdown on how it works: 👇
5
14
112
17,883
Victor retweeted

Malcolm Gladwell explaining why some people succeed and some don't.
30
1,267
8,579
1,880,912
Jun 10
Little extra points:
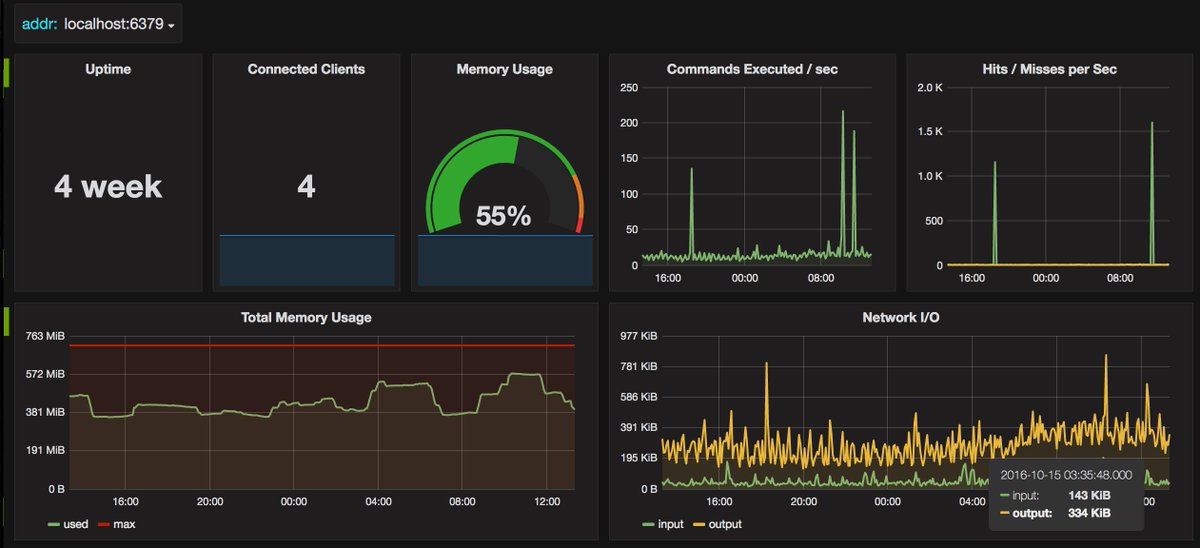
1. LRU eviction policy: Removes the least recently used keys.
2. LFU eviction policy: Keys with a lesser frequency are removed once the maxmemory is attained
3. AOF (Append-only File): It logs every write command to the Redis Internal log. Options that exist: appendfsync everysec logs every 1 sec; appendfsync on logs every write command synchronously to the Redis Log; appendfsync none basically does not log the write to Redis WAL
4. RDB (Redis Database): Another option for persistence that sets up a child process that carries out point-in-time snapshots (duration is mostly in minutes) of the data in Redis Memory.
Jun 10

Caching terms backend engineers mix up:
Cache Hit: data found in cache, DB not touched
Cache Miss: data not in cache, DB gets queried
Cache Eviction: old data removed to make space for new data
TTL: how long data lives in cache before expiring
Write-Through: write to cache and DB at the same time
Write-Behind: write to cache first, DB later
1
3
199
Victor retweeted

Jun 9
I have to push back on 2 things as i think one is categorically incorrect and the other is demonstrably incorrect.
1. Debugging:
Debugging is not a thing if coding is solved. You would produce correct behaviors. I don't understand how a solved problem could produce erroneous behavior.
2. Coding is the easy part:
setting hardware, capacity, talking to users, product planning agreed is in fact hard, but so is coding.
Example: If coding was in fact not hard then Claude Code having a flickering issue for well over 9 months, which is a purely software challenge, would have been solved almost immediately (immediately being on a shortened time scale comparatively to a human solve time scale).
For more trivial applications software approximation can largely work. I also love software approximation for exploring how things should feel.
76
76
2,030
84,267
Jun 9
Some key Docker commands I make use of daily
1. docker logs payment -f --tail=100
2. docker ps -a
3. docker ps --format "table {{.Names}}\t{{.Status}}" | sort
4. docker system prune -a --volumes
5. docker inspect auth --format='{{.State.Health.Status}}'
22





Victor retweeted

May 20
Fork your dependencies, trim them to only your use case, never update unless it breaks for your users. I’ve been vocal about this for 10 years. I’ve always said that updating is way riskier than latent bugs (which can be tracked and CVEs monitored).
If you are updating a dependency, it’s on you to analyze every single commit in the full transitive set of dependencies. If you dont see anything compelling, dont update!
I remember at HashiCorp once in awhile an engineer would try to update a dep or replace a DIY lib with an external one and id always ask “show me the commit we need.” Dont update for the sake of it.
Feeling pretty swell about this mentality with all the supply chain attacks happening.
292
776
8,955
1,184,601
Victor retweeted

May 17
"Until death, all defeat is psychological." - Marcus Aurelius
Refuse everything that would lead most people to give up.
Refuse it.
Rise from the dead 1000 times.
Commit to never stay down & never give up.
Everything you want is on the other side of struggle.
158
2,816
14,712
2,102,296
May 17
“A man on a thousand mile walk has to forget his goal and say to himself every morning, 'Today I'm going to cover twenty-five miles and then rest up and sleep.”
11
May 17
Istio's service mesh (also Envoy sidecar) is another layer I genuinely need to implement.
The way I am looking at it, it will definitely need me to spend some bucks
16