
🤡 SWE by day. 🤖 AI enthusiast by night.
Joined October 2011
- Tweets 2,312
- Following 847
- Followers 257
- Likes 2,632
92 Photos and videos






Vitou Phy retweeted

11 Sep 2025
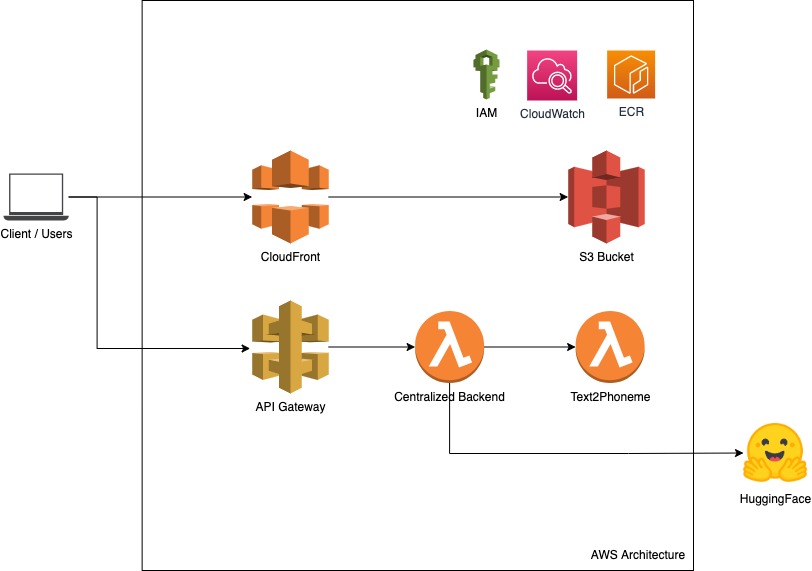
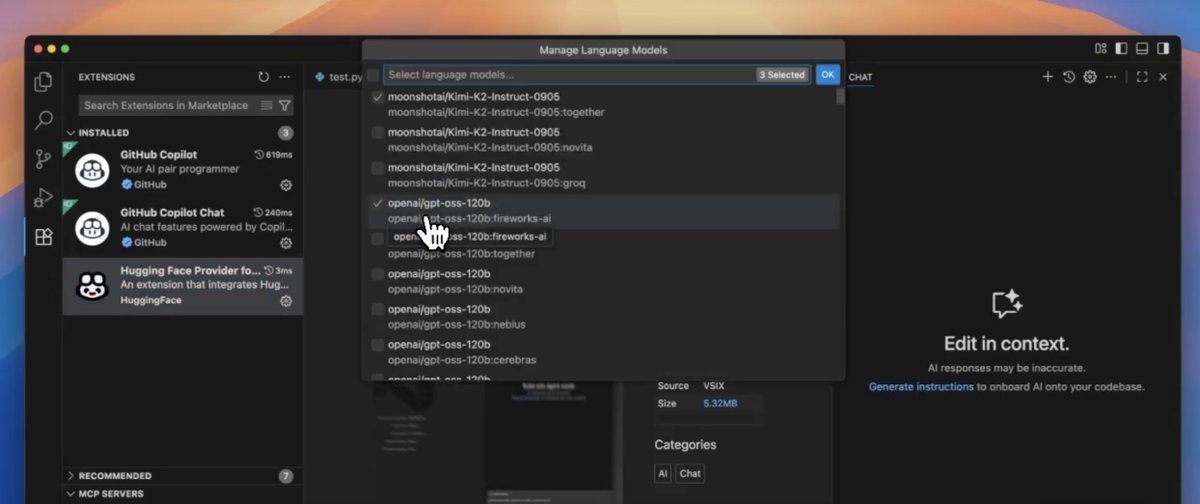
Super excited to bring hundreds of state-of-the-art open models (Kimi K2, Qwen3 Next, gpt-oss, Aya, GLM 4.5, Deepseek 3.1, Hermes 4, and dozens new ones every day) directly into @code & @Copilot, thanks to @huggingface inference providers!
This is powered by our amazing partners @cerebras, @FireworksAI_HQ, @Cohere_Labs, @GroqInc, @novita_labs, @togethercompute, and others who make this possible. 💪
Here’s why this is different than other APIs:
🧠 Open weights - models you can truly own, so they’ll never get nerfed or taken away from you
⚡ Multiple providers - automatically routing to get you the best speed, latency, and reliability
💸 Fair pricing - competitive rates with generous free tiers to experiment and build
🔁 Seamless switching - swap models on the fly without touching your code
🧩 Full transparency - know exactly what’s running and customize it however you want
The future of AI copilots is open and this is a big first step! 🚀
32
85
766
105,560
Vitou Phy retweeted

5 Sep 2025
The most important AI paper of 2025 might have just dropped.
NVIDIA lays out a framework for Small Language Model agents that could outcompete LLMs.
Here’s the full breakdown (and why it matters):

125
685
4,060
445,640
Vitou Phy retweeted

2 Sep 2025
What is this guy’s deal? Our favorite Thai general is suggesting taking Preah Vihear back through the courts or by force, despite the ICJ ruling it belongs to Cambodia.


58
168
412
39,159
Vitou Phy retweeted

19 Aug 2025
Let's Learn MCP with Python - Tutorial Series
Here's your comprehensive guide to understanding and building Model Context Protocol (MCP) Servers for Python developers through interactive learning experiences.
Repo readme: msft.it/6014sR9Pk

ALT illustration of github repo title screen. text reads: Microsoft/Let's Learn MCP: Python
3
280
1,474
188,046
Vitou Phy retweeted

30 Jul 2025
While I know that even our country’s news will be heard more and more, but I still hope that our people will deserve justice that we asked for because we endure this for too long. We hope internationally will continue the researching for our justice for our nation, and people.
#TruthForCambodia
#ExposeThailandLies

23
370
442
4,638

Actions speak louder than words. If you look at their actions, you’ll see through their lies. #ExposeThaiLies
30 Jul 2025

Cambodia Didn’t Break the Ceasefire — Where’s Thailand’s Proof? #Cambodia #ExposeThailandLies
2
145
Vitou Phy retweeted

20 Jun 2025
AI Engineering Hub just crossed 10k GitHub stars!
It’s 100% open-source and hosts 70 free hands-on demos.
Here are 10 MCP, RAG, and AI Agents projects for AI engineers:
27
253
1,666
287,348
Vitou Phy retweeted

28 May 2025
No API keys.
No hidden fees.
No feature gating.
Chatterbox is what open-source voice AI should look like.
→ Try it: resemble.ai/chatterbox
→ Clone it: github.com/resemble-ai/chatt…
→ Comparison: podonos.com/resembleai/chatt…
17
50
424
46,639
Vitou Phy retweeted

30 May 2025
o4 -mini, 30 minutes before it annihilates half of all entry-level white-collar jobs with its sheer brilliance.

8
14
93
7,724
Vitou Phy retweeted
21 May 2025
The only MCP server you'll ever need!
MindsDB lets you query data from 200 sources—Slack, Gmail, social platforms, and more—using both SQL or natural language.
A federated query engine that comes with a built-in MCP server.
100% open-source, 28k stars 🌟

46
311
2,243
189,817
Vitou Phy retweeted

29 Apr 2025
That’s a wrap on the LlamaCon 2025 keynote!
In just over two years, Llama has surpassed 1 billion downloads and established itself as the open ecosystem leader in AI.
We’re continuing to support the growth and development of the Llama ecosystem with today’s announcements:
The Llama API in Preview: The best features of closed-model APIs with the flexibility of open source.
The AI Defender Program: State-of-the-art tools to detect and prevent AI-generated threats.
Meet the Llama Impact Grant Winners driving transformative change with open-source AI.
Learn more about today’s announcements and how to apply for the Llama API Preview ➡️ go.fb.me/so7u4j

25
60
223
28,875

Too many people say that MCP is a game changer, and now, with MCP, LMs are real agents, hallucinations are no longer an issue, and more nonsense like that.
I wanted to first write an article on MCP, but really, there's no substance for an article, so a post will do.
What is MCP? You might have already heard that it's USB Type-C for LMs, a protocol for connecting LMs to tools and resources, etc. But what exactly does that mean? Why do so many people scream that it changes everything?
Let's answer the latter question: It doesn't change everything. LMs still hallucinate and agents based on them aren't agentic.
Now, let's see what it is.
As you likely know, LMs can be finetuned to "use tools." That simply means that they can be finetuned to print something like "USE TOOL: CALCULATOR" when the user input is like "what is 3 2?"
Let the LM's output be "USE TOOL: CALCULATOR, ADD 2, 3."
This output must be parsed, the tool name and the arguments extracted, and then submitted to an actual calculator API. This is done by a handcrafted parser script.
As the number of tools you want the LM to be able to use grows, this parser script will become more and more complex and hard to maintain when the LM output or the tool input API changes.
Here comes MCP. It says: the LM must be responsible for outputting the tool call request in a format that the tool API understands without needing a parser.
So, the process is as follows:
1. The user says "what is 3 2?"
2. The MCP client (coded by the chatbot creator) connects to one or several MCP servers (coded by the tool providers) and pulls the list of supported tools from the MCP servers.
2.1. Each tool comes with a verbal description of what the tool can do and what input format it accepts (written by the MCP server provider, so the quality can vary from one provider to another).
3. The MCP client submits all tools and their descriptions to the LM, together with the user's prompt "what is 3 2?"
4. The LM looks at the tools and decides that to answer "what is 3 2?" it needs the tool CALC that takes a specific JSON as input (the input JSON format for CALC is provided by the MCP server provider).
5. The LM outputs "TOOL: CALC, WORKLOAD: [JSON]"
5.1. "CALC" is the name of the tool, as provided by an MCP server, "JSON" is an actual JSON as expected by the tool, for example {"operation": "addition", "argument1": 3, "argument2": 2}
5.2. This JSON structure wasn't invented by the LM. It was taken by the LM from the information that came with the list of tools.
Now, what no one is talking about, the elephants in the room:
1. The LM must be finetuned to understand the list of available tools and all information about these tools that comes from the MCP server. So not all LMs can be used with MCP, but only those that were finetuned for this. Finetuning for effective tool usage is not a simple task, so different models will handle MCP with different levels of success.
2. Even if the LM was finetuned for understanding MCP tool specifications, the JSON structure it will generate isn't guaranteed to be as the MCP server expects because the LM wasn't finetuned for this specific MCP server and its tools.
2.1. Even if the chatbot creator uses JSON structure enforcing decoding (using Outlines, for example), there's no guarantee that the generated JSON structure with all good keys will also contain all good values.
3. Some tools might require a very complex input structure, with lists, lists of lists, lists of dictionaries, etc. The description of what a tool can do can be very complex too or just poorly written by the MCP server provider.
3.1. There's zero guarantee that the LM will be good enough in choosing the right tool and then generating the right JSON-formatted input for this tool.
4. It all looks nice when you code a small demo of MCP with one server and two tools on it. But to build a general-purpose chatbot, the number of tools needed to answer all possible user demands can grow to hundreds, thousands, or even millions.
4.1. Putting all of them in the conversation context all the time will consume the maximum context size very quickly, and the LM will not be able to choose the right tool or fill the JSON structure with the right values.
4.2. Not putting all of them in the context will require a classifier trained to select the right tools, or using some sort k-nearest neighbors in the embedding space.
So, again, agents look good when there's only one of them using 2-3 simple tools. Try to scale it to hundreds of agents using thousands of tools and fail miserably.
106
148
1,166
109,982
Vitou Phy retweeted

6 Apr 2025
If you want to build stuff with Gemini fast with AI help, you might want to put @strickvl's Gemini llms.txt in your LLM context -- it's pretty great! (As is his whole site, in fact.)
geminibyexample.com/llms.txt
15
97
1,066
182,534
Vitou Phy retweeted

24 Mar 2025
Registration for the Microsoft AI Skills Fest is now OPEN! 📢
Here's what to expect:
🎉 A kickoff celebration to set a world record title in 24 hours
💡 50 days of AI learning featuring deep dives, hackathons, challenges, and more
Sign up: msft.it/6012qeZPM #AISkillsFest

7
94
298
23,912
Vitou Phy retweeted

5 Mar 2025
It’s true. Stay tuned. 👀🌎🤫

144
133
976
487,071
Vitou Phy retweeted

31 Jan 2025
o3-mini is out!
smart, fast model.
available in ChatGPT and API.
it can search the web, and it shows its thinking.
available to free-tier users! click the "reason" button.
with ChatGPT plus, you can select "o3-mini-high", which thinks harder and gives better answers.
1,600
1,958
25,976
3,158,741
RT @nvidia: The open source DeepSeek-R1 model is now available as an NVIDIA NIM microservice preview on build.nvidia.com to help dev…
323
Vitou Phy retweeted

24 Jan 2025
Nice job!
Open research / open source accelerates progress.
20 Jan 2025

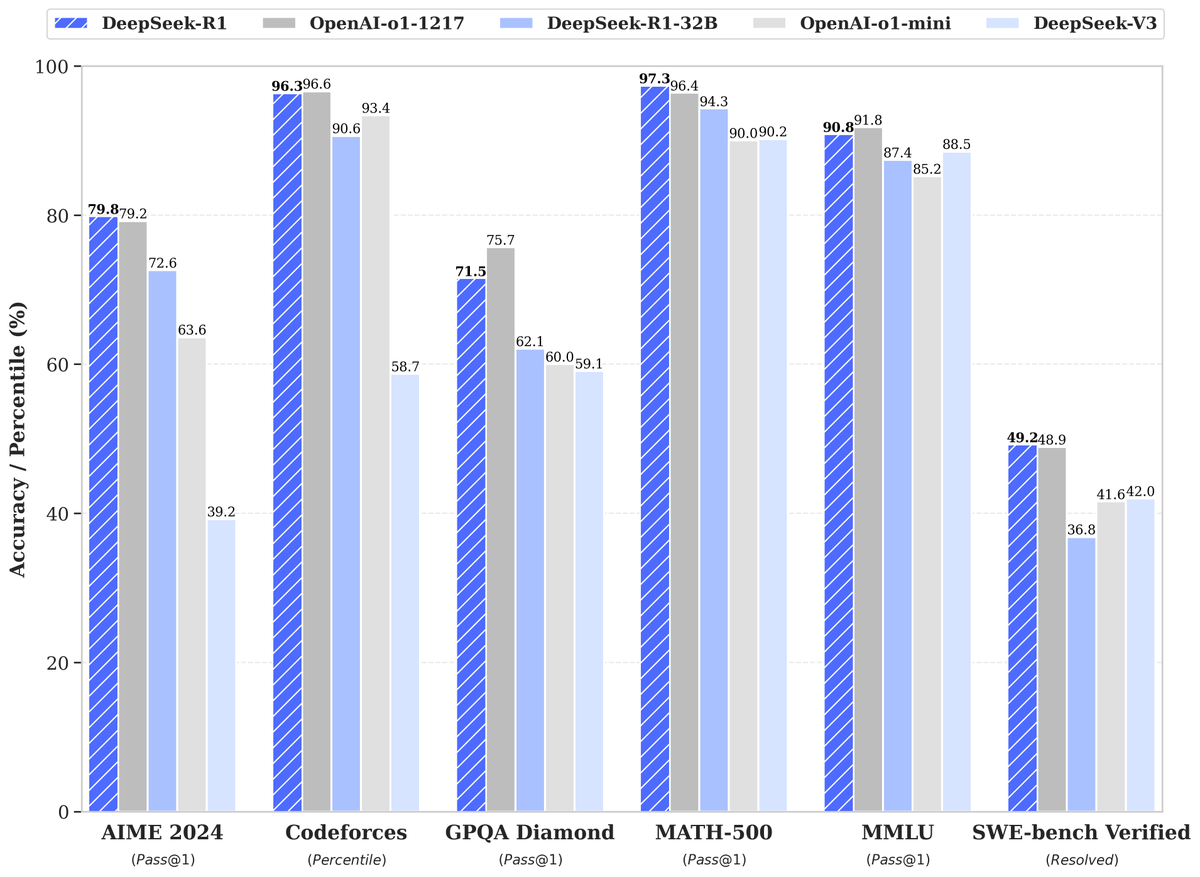
🚀 DeepSeek-R1 is here!
⚡ Performance on par with OpenAI-o1
📖 Fully open-source model & technical report
🏆 MIT licensed: Distill & commercialize freely!
🌐 Website & API are live now! Try DeepThink at chat.deepseek.com today!
🐋 1/n
354
739
9,748
1,030,495
Vitou Phy retweeted

15 Jan 2025
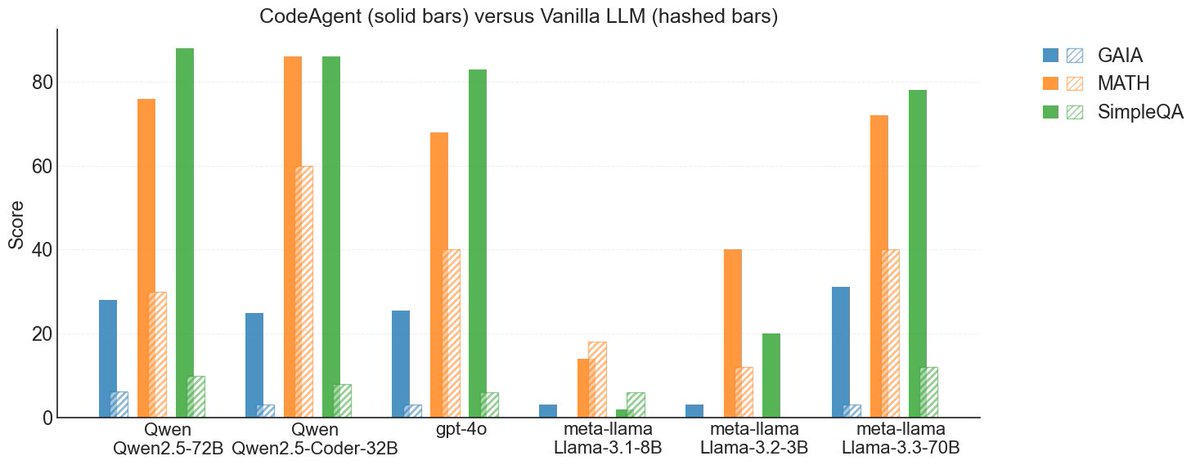
when people ask whether you need an agent framework at all - mind blown👇
all evals should move to agentic evals in 2025 imo
we’re just leaving so much capabilities of our models on the table…
13
23
198
23,400
Vitou Phy retweeted
13 Jan 2025
A request from an AI researcher to doctors:
Please don’t use a large language model to make novel treatment recommendations for cancer patients.
Thank you.

18
36
369
39,350